






至于为什么用DM642和mpeg-2就不说了。。。虽然这是十年前的东西,但是只能说依然有人在做。。。写在这里也是为自己梳理下思路
首先先讲一下MPEG-2的编码,在MPEG-2编码中将视频分为了六个层次,依次为序列,GOP,图像,像条(slice),宏块,块。每一个块为8*8,每一个宏块包括六个块,为16*16的包含亮度值的块和两个8*8的包含色度值的块,一个slice为一行的块,可以从字面上理解,像条:一条图像。。。;图像就是指一帧图像;gop是一组图像,一个gop包含多少帧图像时自己定的;而序列就是指你压缩编码的整个序列,可以包含多个GOP。为什么要介绍这六个层次,因为每一部分都含有数据头,解码的时候就要依据这些数据头来判断这一段数据是什么数据,再用来解码。下面附上MPEG-2编码的原理图
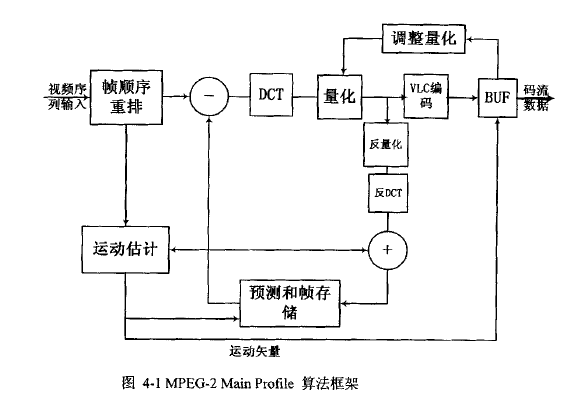
首先视频序列输入后要进行帧重排,为什么要重排,为什么说编码顺序和显示顺序是不一样的?因为比如说我们正常的显示顺序为I B P B P ……但是我们编码的时候B帧是由I帧和P帧预测编码得来的,所以解码的时候需要I帧和P帧都传过来才能将B帧解码,这就需要我们编码的时候要先将I帧和P帧编码,再编码B帧,所以编码的顺序就变成了I P B P B ……。然后I帧不进行运动估计直接进行DCT 量化 和编码的过程,所以I帧所需要的存储空间是最大的。而P帧和B帧要经过运动估计,利用快匹配,在参考图像中搜索到与当前块最接近的块,得到运动矢量,但是即便是最接近的块之间也还是有误差,所以我们需要将编码图像和参考图像之间求差值,也就是运动补偿。运动矢量直接进行编码输出,而运动补偿得到的差值要经过DCT 量化和编码再输出。而参考图像是I帧或者P帧经过DCT 量化->反量化 反DCT,为什么要绕这么一大圈,这和原始图像难道不一样吗?事实告诉我们这是不一样的,因为我们解码的时候得到的参考图像都是经过DCT 量化后的啊,所以我们重建图像的时候,是不可能得到原始图像的,也就是这一步就产生误差了,所以我们编码的时候考虑到解码的时候是用的经过DCT 量化 反量化 反DCT的图像,所以编码的时候为了消除这种误差,就也用这种经过DCT 量化 反量化 反DCT的重建图像(ps:好绕,不知道说清楚了没)。
恩,根据原理图貌似说完了,但是程序可没这么简单。。。我们是将pc上的MPEG-2编码移植到dm642,除了一些数据类型的改变,还有存储空间的变化,比如我们要提前存储一帧来进行帧重排,保证编码的正常顺序 ,还有一些其他地方的改变,之后再介绍,咱们继续说编码。
编码中很重要的一个参数是码率,码率控制的是什么呢?这里有两点1、码率和质量成正比,但是文件体积也和码率成正比,2、码率超过一定数值,对图像的质量没多大影响 。 码率就是数据传输时间传送的数据位数,一般我们用的单位是kbps即千位/秒,也就是取样率(并不等同于采样率,采样率的单位是hz,表示每秒采样的次数),单位时间内取样率越大,精度就越高,处理出来的文件就越接近原始文件,但是文件体积与取样率是成正比的,所以几乎所有的编码格式重视的都是如何利用最低的码率达到最少的失真。 最最重要的:码率实际控制的是量化精度。这是我从程序中得出的,不知道适不适用与所有的,下面是介绍量化精度的:量化过程在不断降低视觉效果的前提下,减少图像的编码长度,减少视觉恢复中不必要的信息,在量化和反量化过程中,量化步长QP决定量化器的编码压缩率及图像精度。如果QP比较大,则量化值FQ(FQ=round(y/QP))动态范围较小,其相应的编码长度较小,但反量化时损失较多的图像细节信息,如果QP比较小,则FQ动态范围比较大,相应的编码长度也比较大,但是图像细节信息损失较少。量化因子是动态的,就是说对于不同的宏块,量化因子是不一样的。
下一篇介绍量化因子的生成和可变长编码过程,而对于DCT 和反DCT用的库函数IMG_dct_8x8。运动估计部分核心是快匹配,网上有很多介绍,我们采用的是优化过的钻石搜索法,运动补偿即是将编码图像-重建图像得到的差值。















 2172
2172

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









