









我本来不会Python,一边学一边试图以最简单方式来解释编程和Python,让各位理工男可以拿去教自己的女朋友。
上期我们把网址准备好了:
url = "http://cn.bing.com/images/search?q=" + name + "&first=" + str(first) +"&count=" + str(count)
其中,name、first、count是三个变量,接下来我们就应该从这个网址获取数据啦,还记得当name="胡歌",first=1,count=28时候得到的数据展示出来的网页有多丑嘛?
现在你们就要自己来获取啦!
然而,我知道此时的你肯定是一脸懵逼,WTF?我就知道一个网址,哪知道怎么获取数据?不用担心,Python已经为你准备好了,整个获取过程只需要两行代码,不过在我贴出代码之前,先说一点网页的基本知识,方便理解那两行代码。
我:我们是怎么访问网页的呢?
小白:O(∩_∩)O用360浏览器。
我:。。。。那用浏览器第一步呢?
小白:╮(╯▽╰)╭打开浏览器?
我:然后呢?
小白:o(* ̄▽ ̄*)o百度想要的东西
我:然后呢?
小白:打开搜索的结果。
我想大概大部分人都是这么用浏览器的吧,其实这里面隐藏了一个信息,就是,小白先得点击搜索,才会出搜索结果。小白要先点击搜索结果,才会跳转到某个网页。再抽象一点点,就是我先要操作一下浏览器,让浏览器去干了什么,浏览器才会给我想要的结果。那么浏览器干了什么呢?
浏览器去跟网页说,快到碗里来!具体过程如下:
小白:喂,浏览器,按这个电话(网址)给我叫个姑娘(网页)回来!
浏览器:喂,服务器么。
服务器:蘑菇,你哪路?什么价?(黑话接头,为了安全,服务器很多时候都需要验证)
浏览器:哈!想啥来啥,想吃奶来了妈妈,想娘家的人,孩子他舅舅来了!(也得用黑话接,不然不让进)
服务器:大爷您要什么样的姑娘随便挑!
浏览器:就要8号了,过来吧。
网页:打了个车(网络传输),走了大半夜(网速慢),到小白家。
浏览器:小白君,美人给您带回来了。
小白一看:这特么是谁呀,长得跟鬼一样?(就是我们在第三期里说的那些数据)
浏览器:小白君别急,现在扫黄打非严,为了怕被抓到,易容了的,我来捯饬捯饬(把数据渲染成网页)。
小白:噢噢噢,这么一看,真是天香国色呀o(* ̄3 ̄)oo(* ̄3 ̄)o。
网页:o(* ̄3 ̄)oo(* ̄3 ̄)o。
嗯,访问网站的过程,跟这个差不多,首先,用户给浏览器一个网址,让浏览器去找服务器要数据,服务器通过之后把数据传给浏览器,浏览器将数据渲染成网页,呈现给用户。现在,我们不需要呈现成网页,只需要从数据里面得到照片就可以了,所以我们只需要通过url获取数据就OK了。
那么再看下面的两行代码就容易了:
了解了上述过程,来理解这个代码是不是就很简单了。首先,我们通过request网址url创建了一个变量response,然后从response中读取数据。
那么现问题来了,request我们可没有定义过,从哪冒出来的?他是什么东西?后面跟个.urlopen()是什么意思?response是我们自己定义的一个变量,后来也跟了一个.read(),这又是什么鬼,是不是所有的变量都可以跟呢?
除了第一个问题,全部不解释!为什么?因为现在就解释了,以后就没得写了。而且只有两行代码,看着眼熟就行,现在先记着,以后说到相关的知识点了解释。
request从哪来的呢?从urllib模块里面来的!urllib从哪来的?python自带的!模块是什么?随着项目越来越大,代码越来越多,就需要分组进行维护管理,这就是模块的来由,在python中,一个.py文件就是一个模块!怎么使用别人写的模块?引用进来,比如我们要引用urllib整个模块,就需要在文件开头加入import urllib;如果只引用urllib模块中的requset这一部分,就在文件开头加from urllib import request。
好了,现在轮到我提问题了,假设,我要同时获取三个不同url的数据,怎么办?
答案:
轻松自在,可以实现,满分!如果阿里的程序员靠代码行数来算工资,你能写到马云爸爸破产!
但是这特么也太蠢了。还记得我们上期说的函数么,f(x)=3x + 111。当x有很多的时候,使用f(x1),f(x2)。。。f(xn)比使用3x1+111。。。。3xn+111是不是清爽很多。所以到了编程里面,会把一段需要经常重复的代码封装在一起,构成一个函数,比如我们的那一段代码,是为了获得某个网址的数据(HTML)的,我们就取一个名字叫
但是,这么写,是数学里面的做法,在python里面,是这样的:
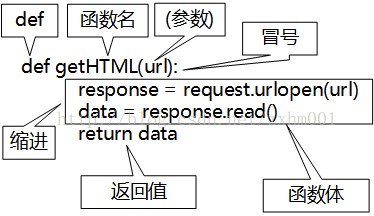
一个个来说:
def,固定的,不变。
函数名:跟变量名一样,随便自己取,不过,最好是能表明他的功能的。
参数:用括号阔起来,函数可以没有参数,也可以有多个参数。至于python里面的默认参数,可变参数,关键字参数,命名关键字参数傻的,本文全部不讲,为什么,因为本项目用不着。
冒号:固定的,英文字符,不要打成了中文字符的冒号。
缩进:还记得上期说过,python里面用缩进表示代码之间的逻辑关系。现在看就比较明显了吧,下面的函数体和返回值都是这个函数的内容,所以缩在他的羽翼之下。至于缩进多少,看心情,没有规定,但是同一逻辑层级的代码缩进一定要一样。不过习惯上是一个tab键。
函数体:就是我们要执行的任务了
返回值:比如上文说的数学上的函数,a=f(3),编程的函数也是一样,只不过用return标记。想返回data,就return data。如果返回值为None,可以简写为return。
上期我们把网址准备好了:
url = "http://cn.bing.com/images/search?q=" + name + "&first=" + str(first) +"&count=" + str(count)
其中,name、first、count是三个变量,接下来我们就应该从这个网址获取数据啦,还记得当name="胡歌",first=1,count=28时候得到的数据展示出来的网页有多丑嘛?
现在你们就要自己来获取啦!
然而,我知道此时的你肯定是一脸懵逼,WTF?我就知道一个网址,哪知道怎么获取数据?不用担心,Python已经为你准备好了,整个获取过程只需要两行代码,不过在我贴出代码之前,先说一点网页的基本知识,方便理解那两行代码。
我:我们是怎么访问网页的呢?
小白:O(∩_∩)O用360浏览器。
我:。。。。那用浏览器第一步呢?
小白:╮(╯▽╰)╭打开浏览器?
我:然后呢?
小白:o(* ̄▽ ̄*)o百度想要的东西
我:然后呢?
小白:打开搜索的结果。
我想大概大部分人都是这么用浏览器的吧,其实这里面隐藏了一个信息,就是,小白先得点击搜索,才会出搜索结果。小白要先点击搜索结果,才会跳转到某个网页。再抽象一点点,就是我先要操作一下浏览器,让浏览器去干了什么,浏览器才会给我想要的结果。那么浏览器干了什么呢?
浏览器去跟网页说,快到碗里来!具体过程如下:
小白:喂,浏览器,按这个电话(网址)给我叫个姑娘(网页)回来!
浏览器:喂,服务器么。
服务器:蘑菇,你哪路?什么价?(黑话接头,为了安全,服务器很多时候都需要验证)
浏览器:哈!想啥来啥,想吃奶来了妈妈,想娘家的人,孩子他舅舅来了!(也得用黑话接,不然不让进)
服务器:大爷您要什么样的姑娘随便挑!
浏览器:就要8号了,过来吧。
网页:打了个车(网络传输),走了大半夜(网速慢),到小白家。
浏览器:小白君,美人给您带回来了。
小白一看:这特么是谁呀,长得跟鬼一样?(就是我们在第三期里说的那些数据)
浏览器:小白君别急,现在扫黄打非严,为了怕被抓到,易容了的,我来捯饬捯饬(把数据渲染成网页)。
小白:噢噢噢,这么一看,真是天香国色呀o(* ̄3 ̄)oo(* ̄3 ̄)o。
网页:o(* ̄3 ̄)oo(* ̄3 ̄)o。
嗯,访问网站的过程,跟这个差不多,首先,用户给浏览器一个网址,让浏览器去找服务器要数据,服务器通过之后把数据传给浏览器,浏览器将数据渲染成网页,呈现给用户。现在,我们不需要呈现成网页,只需要从数据里面得到照片就可以了,所以我们只需要通过url获取数据就OK了。
那么再看下面的两行代码就容易了:
response = request.urlopen(url)
data = response.read()了解了上述过程,来理解这个代码是不是就很简单了。首先,我们通过request网址url创建了一个变量response,然后从response中读取数据。
那么现问题来了,request我们可没有定义过,从哪冒出来的?他是什么东西?后面跟个.urlopen()是什么意思?response是我们自己定义的一个变量,后来也跟了一个.read(),这又是什么鬼,是不是所有的变量都可以跟呢?
除了第一个问题,全部不解释!为什么?因为现在就解释了,以后就没得写了。而且只有两行代码,看着眼熟就行,现在先记着,以后说到相关的知识点了解释。
request从哪来的呢?从urllib模块里面来的!urllib从哪来的?python自带的!模块是什么?随着项目越来越大,代码越来越多,就需要分组进行维护管理,这就是模块的来由,在python中,一个.py文件就是一个模块!怎么使用别人写的模块?引用进来,比如我们要引用urllib整个模块,就需要在文件开头加入import urllib;如果只引用urllib模块中的requset这一部分,就在文件开头加from urllib import request。
好了,现在轮到我提问题了,假设,我要同时获取三个不同url的数据,怎么办?
答案:
response1 = request.urlopen(url1)
data1 = response.read()
response2 = request.urlopen(url2)
data2 = response.read()
response3 = request.urlopen(url3)
data 3= response.read()轻松自在,可以实现,满分!如果阿里的程序员靠代码行数来算工资,你能写到马云爸爸破产!
但是这特么也太蠢了。还记得我们上期说的函数么,f(x)=3x + 111。当x有很多的时候,使用f(x1),f(x2)。。。f(xn)比使用3x1+111。。。。3xn+111是不是清爽很多。所以到了编程里面,会把一段需要经常重复的代码封装在一起,构成一个函数,比如我们的那一段代码,是为了获得某个网址的数据(HTML)的,我们就取一个名字叫
getHTML(url)={
response = request.urlopen(url)
data = response.read()}
但是,这么写,是数学里面的做法,在python里面,是这样的:
一个个来说:
def,固定的,不变。
函数名:跟变量名一样,随便自己取,不过,最好是能表明他的功能的。
参数:用括号阔起来,函数可以没有参数,也可以有多个参数。至于python里面的默认参数,可变参数,关键字参数,命名关键字参数傻的,本文全部不讲,为什么,因为本项目用不着。
冒号:固定的,英文字符,不要打成了中文字符的冒号。
缩进:还记得上期说过,python里面用缩进表示代码之间的逻辑关系。现在看就比较明显了吧,下面的函数体和返回值都是这个函数的内容,所以缩在他的羽翼之下。至于缩进多少,看心情,没有规定,但是同一逻辑层级的代码缩进一定要一样。不过习惯上是一个tab键。
函数体:就是我们要执行的任务了
返回值:比如上文说的数学上的函数,a=f(3),编程的函数也是一样,只不过用return标记。想返回data,就return data。如果返回值为None,可以简写为return。
所以我们的代码就改版啦:
from urllib import request
name = "胡歌"
first = 1
count = 28
url = "http://cn.bing.com/images/search?q=" +name + "&first=" + str(first) +"&count=" + str(count)
def getHTML(url):
response = request.urlopen(url)
data = response.read()
return data
html = getHTML(url)好了,函数已经讲完了。但是有没有同学发现,我这期一点动图都没有,从头到尾没有运行?有没有勤学苦练的同学自己运行了?哈哈,因为运行不成功的,为什么呢?下期继续。
欢迎关注我的微信公众号获取最新文章:















 1046
1046











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









