







我是从word文档复制过来的,复制过来格式有点乱,仔细看还是能够看明白的
U-Net:Convolutional Networks for Biomedica Image Segmentation
一、背景:
其实神经网络已经存在了很多年,不过受限于数据集大小和网络小。Krizhevsky等人用一个包含百万级参数的大的
神经网络和100万的训练集,这是一个很大的突破。过去两年神经网络在视觉识别的任务中的表现比较突出。
神经网络往往在图像分类的任务中比较多。而对于图像分割不仅需要给像素分类还需要定位,而且分割任务中的数
据集往往不大。Ciresan等人,取以图像中每个像素点为中心的局部区域(patch),进行训练,相对于单张图片增
大了数据集,但是有两个缺点,patch太大,会导致需要pooling层增多(为什么?因为你是对以这个像素为中心的点进行分类,如果patch太大,最后经过全连接层的前一层大小肯定是不变的,如果你patch大就需要更多的pooling达到这个大小),因为Pooling层会降低分辨率,丢失信息,
降低分割准确度,patch太小,包含的背景信息不够。本文提出了以下的u-net网络方法。还有一个缺点就是,patch虽然增大了训练集,但是由于训练图片的数量大,会降低速度,另外不同patch之间的重叠的地方,造成了多余的冗余。冗余会造成什么影响呢?卷积核里面的W,就是提取特征的权重,两个块如果重叠的部分太多,这个权重会被同一些特征训练两次,造成资源的浪费,减慢训练时间和效率。
那patch多不好吗,相当于增大了训练集啊,虽然说会有一些冗余,训练集大了,准确率不就高了吗?可是你这个是相同 的图片啊,重叠的东西都是相同的,举个例子,我用一张相同的图片训练20次,按照这个意思也是增大了训练集啊,可是会出现什么结果呢,很显然,会导致过拟合,也就是对你这个图片识别很准,别的图片就不一定了。
训练代码下载:http://lmb.informatik.uni-freiburg.de/people/ronneber/u-net.
二、方法及网络结构:
2.1方法:
2.1.1网络结构方面:
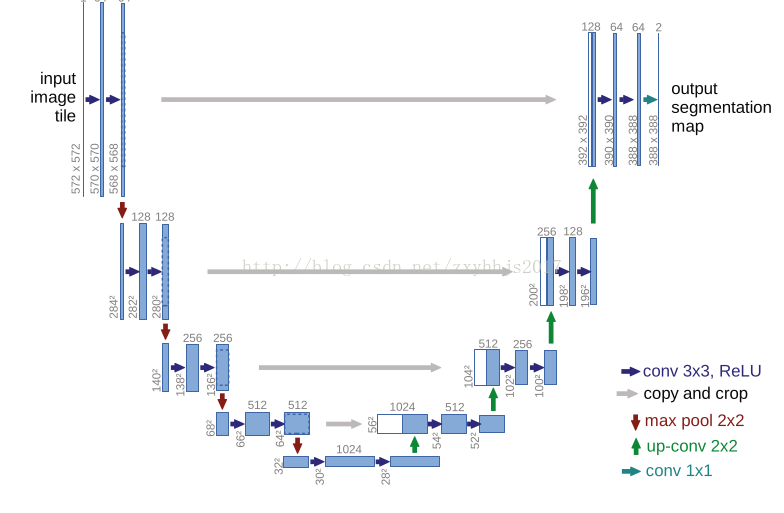
(1)使用全卷积神经网络。(全卷积神经网络就是卷积取代了全连接层,全连接层必须固定图像大小而卷积不用,所
以这个策略使得,你可以输入任意尺寸的图片,而且输出也是图片,所以这是一个端到端的网络。)
(2)左边的网络contractingpath:使用卷积和maxpooling。
(3)右边的网络expansivepath:使用上采样与左侧contracting path ,pooling层的featuremap相结合,然后逐层上
采样到392X392的大小heatmap。(pooling层会丢失图像信息和降低图像分辨率且是不可逆的操作,对图像分割任务
有一些影响,对图像分类任务的影响不大,为什么要做上采样?:因为上采样可以补足一些图片的信息,但是信息
补充的肯 定不完全,所以还需要与左边的分辨率比较高的图片相连接起来(直接复制过来再裁剪到与上采样图片一
样大小),这就相当于在高分辨率和更抽象特征当中做一个折衷,因为随着卷积次数增多,提取的特征也更加有
效,更加抽象,上采样的图片是经历多次卷积后的图片,肯定是比较高效和抽象的图片,然后把它与左边不怎么抽
象但更高分辨率的特征图片进行连接)
(4)最后再经过两次卷积,达到最后的heatmap,再用一个1X1的卷积做分类,这里是分成两类,所以用的是两个神经
元做卷积,得到最后的两张heatmap,例如第一张表示的是第一类的得分(即每个像素点对应第一类都有一个得
分),第二张表示第二类的得分heatmap,然后作为softmax函数的输入,算出概率比较大的softmax类,选择它作为
输入给交叉熵进行反向传播训练
2.2.2训练:
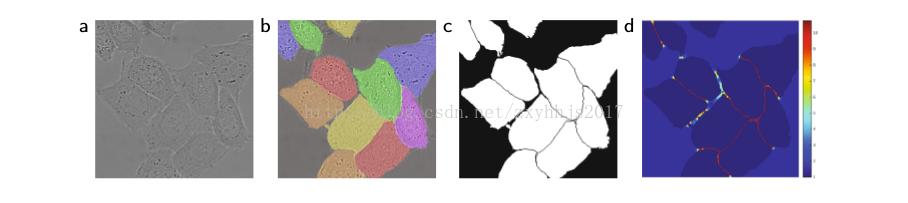
图(2)
损失函数构造:
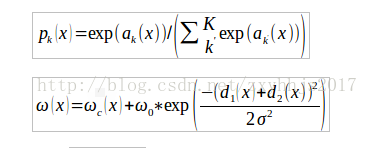
公式pk(x)1:(这是softmax函数,ak(x)表示每一像素点对应类的得分,)
公式w(x)2:(如图2C所示,给像素分配权重然后进行加权,d1(x)表示图中某一背景像
素点到离这个点最近的细胞边界的距离,d2(x)表示离这个像素点第二近的细胞的距离,
你们可以举一下特例算一下这个权重公式会发现(带入数字算很简单,我就不举例子
了),即在细胞边界附近的像素点给的权重会大一些,离细胞比较远的像素点的权重会
小一些,为什么这么做呢?因为,如果同类细胞贴的比较近,可能就会增大训练的难
度,减少准确率,毕竟卷积会考虑该像素点周围的一些特征,而两个相同的类的细胞贴
在一起,就容易误判,所以对这种两个相同类贴在一起的细胞边界,给予较大的权重,
使的训练之后分类分割更准确,这里面的2德尔塔的平方里的德尔塔取5,w0取10)
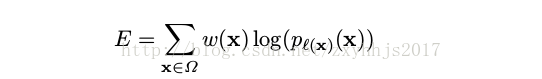
这时候,再将所取得的权重与softmax函数构成一个交叉熵训练,这里相当于最大似然
估计,求最大值,这里的损失函数是求最大值,也就是无限接近于0的值,因为p(x)值
是大于0小于1的,这里的log肯定就是小于0 的,所以0就是它的最大值,与逻辑回归
里面的损失函数不同的是这里是求最大值,而逻辑回归是求最小值,如果在这个式子
前面加一个负号就是求最小值了,那这里就是最大似然函数的最优化问题为什么不使
用导数为0的点呢?详细看这里 机器学习---之损失函数求最小值为什么不用导数为0的
2.2.3数据增强:
数据增强在训练样本比较少的时候,能够让神经网络学习一些不变性,弹性变换是本文使用的方法。(因为弹性形
变是实际细胞中比较常见的一种形变,如果我们能采取数据增强的算法去使网络学习这种形变的不变性,就可以在
分割数据集很小的情况下,使网络具有遇见弹性形变还是可以准确的检测出,相当于就是把原图,做了下弹性变
形,然后,就相当于扩大了数据集嘛,自然网络就能适应这种弹性变化了,在遇见弹性变形的时候一样可以正确的
分类分割)
三、实验:
该文章将U-net网络应用到3个不同的分割任务:
3.1电子显微镜记录下的神经元结构的分割:
数据集来源:ISBS2012年以来的EM分割挑战
训练集:30张512x512的VNC(Drosophilafirst instar larva ventral nerve cord,果蝇龄期幼虫腹侧神经索)图
像。
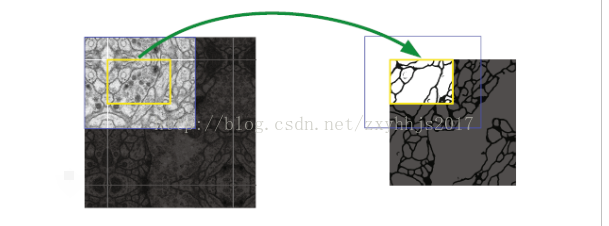
图3
标注:细胞用白色标注,细胞膜用黑色标注.
测试集:公开
分割图:不公开
评估途径:你把预测的细胞膜概率图发给组织方
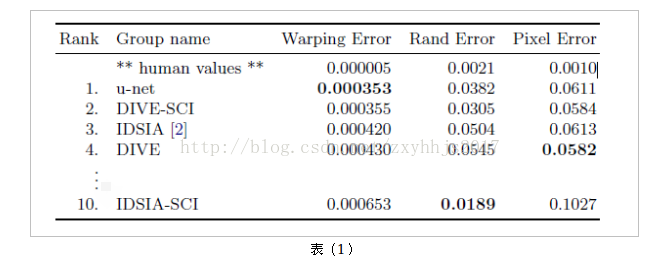
评估方法:通过10个层次的阈值化和计算得到的:
(1)warpingerror(2)Rand error(3)pixel error”
结果如下表(1):
3.2细胞分割:

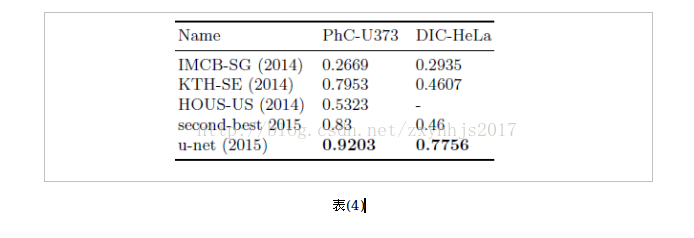
(1)PhC-U373胶质瘤和星形瘤细胞
训练集:35个部分标注的图片
(2)DIC-HeLa细胞
训练集:20个部分标注的图片
结果如表(4)
表(4)
纯属原创,欢迎批评指正,谢谢!














 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









