








前面讲到了如何用MapReduce进行数据分析。当业务比较复杂的时候,使用MapReduce将会是一个很复杂的事情,比如你需要对数据进行很多预处理或转换,以便能够适应MapReduce的处理模式。另一方面,编写MapReduce程序,发布及运行作业都将是一个比较耗时的事情。
Pig的出现很好的弥补了这一不足。Pig能够让你专心于数据及业务本身,而不是纠结于数据的格式转换以及MapReduce程序的编写。本质是上来说,当你使用Pig进行处理时,Pig本身会在后台生成一系列的MapReduce操作来执行任务,但是这个过程对用户来说是透明的。
Pig的安装
Pig作为客户端程序运行,即使你准备在Hadoop集群上使用Pig,你也不需要在集群上做任何安装。Pig从本地提交作业,并和Hadoop进行交互。
1)下载Pig
前往http://mirror.bit.edu.cn/apache/pig/ 下载合适的版本,比如Pig 0.12.0
2)解压文件到合适的目录
tar –xzf pig-0.12.0
3)设置环境变量
export PIG_INSTALL=/opt/pig-0.12.0
export PATH=$PATH:$PIG_INSTALL/bin
如果没有设置JAVA环境变量,此时还需要设置JAVA_HOME,比如:
export JAVA_HOME=/usr/lib/jvm/java-6-sun
4)验证
执行以下命令,查看Pig是否可用:
pig –help
Pig执行模式
Pig有两种执行模式,分别为:
1) 本地模式(Local)
本地模式下,Pig运行在单一的JVM中,可访问本地文件。该模式适用于处理小规模数据或学习之用。
运行以下命名设置为本地模式:
pig –x local
2) MapReduce模式
在MapReduce模式下,Pig将查询转换为MapReduce作业提交给Hadoop(可以说群集 ,也可以说伪分布式)。
应该检查当前Pig版本是否支持你当前所用的Hadoop版本。某一版本的Pig仅支持特定版本的Hadoop,你可以通过访问Pig官网获取版本支持信息。
Pig会用到HADOOP_HOME环境变量。如果该变量没有设置,Pig也可以利用自带的Hadoop库,但是这样就无法保证其自带肯定库和你实际使用的HADOOP版本是否兼容,所以建议显式设置HADOOP_HOME变量。且还需要设置如下变量:
下一步,需要告诉Pig它所用Hadoop集群的Namenode和Jobtracker。一般情况下,正确安装配置Hadoop后,这些配置信息就已经可用了,不需要做额外的配置。
Pig默认模式是mapreduce,你也可以用以下命令进行设置:
pig –x mapreduce
运行Pig程序
Pig程序执行方式有三种:
1) 脚本方式
直接运行包含Pig脚本的文件,比如以下命令将运行本地scripts.pig文件中的所有命令:
pig scripts.pig
2) Grunt方式
Grunt提供了交互式运行环境,可以在命令行编辑执行命令。
Grund同时支持命令的历史记录,通过上下方向键访问。
Grund支持命令的自动补全功能。比如当你输入a = foreach b g时,按下Tab键,则命令行自动变成a = foreach b generate。你甚至可以自定义命令自动补全功能的详细方式。具体请参阅相关文档。
3) 嵌入式方式
可以在java中运行Pig程序,类似于使用JDBC运行SQL程序。
Pig Latin编辑器
PigPen是一个Ecliipse插件,它提供了在Eclipse中开发运行Pig程序的常用功能,比如脚本编辑、运行等。下载地址:http://wiki.apache.org/pig/PigPen
其他一些编辑器也提供了编辑Pig脚本的功能,比如vim等。
简单示例
我们以查找最高气温为例,演示如何利用Pig统计每年的最高气温。假设数据文件内容如下(每行一个记录,tab分割):
1990 21
1990 18
1991 21
1992 30
1992 999
1990 23
以local模式进入pig,依次输入以下命令(注意以分号结束语句):
records = load ‘/home/user/input/temperature1.txt’ as (year: chararray,temperature: int);
dump records;
describe records;
valid_records = filter records by temperature!=999;
grouped_records = group valid_records by year;
dump grouped_records;
describe grouped_records;
max_temperature = foreach grouped_records generate group,MAX(valid_records.temperature);
--备注:valid_records是字段名,在上一语句的describe命令结果中可以查看到group_records 的具体结构。
dump max_temperature;
Pig的出现很好的弥补了这一不足。Pig能够让你专心于数据及业务本身,而不是纠结于数据的格式转换以及MapReduce程序的编写。本质是上来说,当你使用Pig进行处理时,Pig本身会在后台生成一系列的MapReduce操作来执行任务,但是这个过程对用户来说是透明的。
Pig的安装
Pig作为客户端程序运行,即使你准备在Hadoop集群上使用Pig,你也不需要在集群上做任何安装。Pig从本地提交作业,并和Hadoop进行交互。
1)下载Pig
前往http://mirror.bit.edu.cn/apache/pig/ 下载合适的版本,比如Pig 0.12.0
2)解压文件到合适的目录
tar –xzf pig-0.12.0
3)设置环境变量
export PIG_INSTALL=/opt/pig-0.12.0
export PATH=$PATH:$PIG_INSTALL/bin
如果没有设置JAVA环境变量,此时还需要设置JAVA_HOME,比如:
export JAVA_HOME=/usr/lib/jvm/java-6-sun
4)验证
执行以下命令,查看Pig是否可用:
pig –help
Pig执行模式
Pig有两种执行模式,分别为:
1) 本地模式(Local)
本地模式下,Pig运行在单一的JVM中,可访问本地文件。该模式适用于处理小规模数据或学习之用。
运行以下命名设置为本地模式:
pig –x local
2) MapReduce模式
在MapReduce模式下,Pig将查询转换为MapReduce作业提交给Hadoop(可以说群集 ,也可以说伪分布式)。
应该检查当前Pig版本是否支持你当前所用的Hadoop版本。某一版本的Pig仅支持特定版本的Hadoop,你可以通过访问Pig官网获取版本支持信息。
Pig会用到HADOOP_HOME环境变量。如果该变量没有设置,Pig也可以利用自带的Hadoop库,但是这样就无法保证其自带肯定库和你实际使用的HADOOP版本是否兼容,所以建议显式设置HADOOP_HOME变量。且还需要设置如下变量:
export PIG_CLASSPATH=$HADOOP_HOME/etc/hadoop
下一步,需要告诉Pig它所用Hadoop集群的Namenode和Jobtracker。一般情况下,正确安装配置Hadoop后,这些配置信息就已经可用了,不需要做额外的配置。
Pig默认模式是mapreduce,你也可以用以下命令进行设置:
pig –x mapreduce
运行Pig程序
Pig程序执行方式有三种:
1) 脚本方式
直接运行包含Pig脚本的文件,比如以下命令将运行本地scripts.pig文件中的所有命令:
pig scripts.pig
2) Grunt方式
Grunt提供了交互式运行环境,可以在命令行编辑执行命令。
Grund同时支持命令的历史记录,通过上下方向键访问。
Grund支持命令的自动补全功能。比如当你输入a = foreach b g时,按下Tab键,则命令行自动变成a = foreach b generate。你甚至可以自定义命令自动补全功能的详细方式。具体请参阅相关文档。
3) 嵌入式方式
可以在java中运行Pig程序,类似于使用JDBC运行SQL程序。
Pig Latin编辑器
PigPen是一个Ecliipse插件,它提供了在Eclipse中开发运行Pig程序的常用功能,比如脚本编辑、运行等。下载地址:http://wiki.apache.org/pig/PigPen
其他一些编辑器也提供了编辑Pig脚本的功能,比如vim等。
简单示例
我们以查找最高气温为例,演示如何利用Pig统计每年的最高气温。假设数据文件内容如下(每行一个记录,tab分割):
1990 21
1990 18
1991 21
1992 30
1992 999
1990 23
以local模式进入pig,依次输入以下命令(注意以分号结束语句):
records = load ‘/home/user/input/temperature1.txt’ as (year: chararray,temperature: int);
dump records;
describe records;
valid_records = filter records by temperature!=999;
grouped_records = group valid_records by year;
dump grouped_records;
describe grouped_records;
max_temperature = foreach grouped_records generate group,MAX(valid_records.temperature);
--备注:valid_records是字段名,在上一语句的describe命令结果中可以查看到group_records 的具体结构。
dump max_temperature;
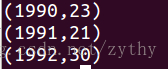
最终结果为:
注意:
1)如果你运行Pig命令后报错,且错误消息中包含如下信息:
WARN org.apache.pig.backend.hadoop20.PigJobControl- falling back to default JobControl (not using hadoop 0.20 ?)
java.lang.NoSuchFieldException:runnerState
则可能你的Pig版本和Hadoop版本不兼容。此时可重新针对特定Hadoop版本进行编辑。下载源代码后,进入源代码根目录,执行以下命令:
ant clean jar-withouthadoop-Dhadoopversion=23
注意:版本号是根据具体Hadoop而定,此处23可用于Hadoop2.2.0。
也可到以下网址下载:
http://download.csdn.net/detail/zythy/6843681
(因为文件太大,分成了3个压缩包)
2)Pig同一时间只能工作在一种模式下,比如以MapReduce模式进入后,只能读取HDFS文件,如果此时你用load 读取本地文件,将会报错。














 356
356











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









