







视图
创建视图
create view v_emp AS select t.name, t.age, t.addr from t_emp;删除视图
drop view if exists v_emp;
索引
创建索引
create index t_emp_index
on table t_emp (name)
as ‘org.apache.hadoop.hive.ql.index.compact.CompactIndexHandler’
with deferred rebuild in table t_index;
显示索引
重建索引
alter index t_emp_index on t_emp rebuild;删除索引
drop index if exists t_emp_index on t_emp ;

普通装载数据(分区需指定)
从文件中装载数据
hive>LOAD DATA [LOCAL] INPATH ‘…’ [OVERWRITE] INTO TABLE t_employee [PARTITION (…)];
通过查询表装载数据
hive>INSERT OVERWRITE TABLE t_emp PARTITION (…) SELECT * FROM xxx WHERE xxx
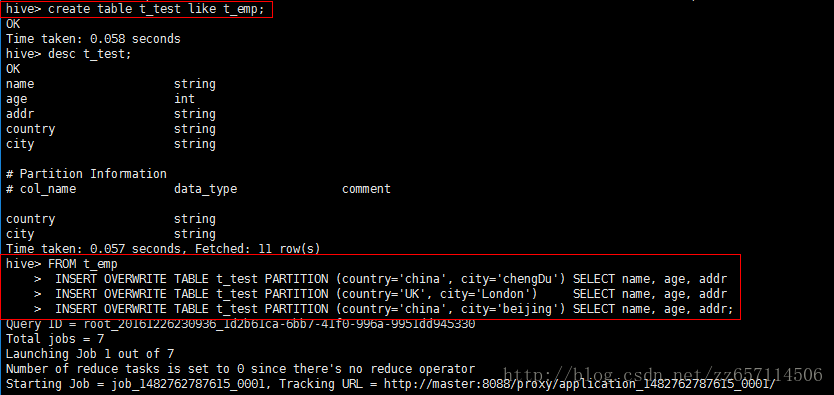
批量插入
hive>FROM t_emp
INSERT OVERWRITE TABLE t_test PARTITION (…) SELECT … WHERE …
INSERT OVERWRITE TABLE t_test PARTITION (…) SELECT … WHERE …
INSERT OVERWRITE TABLE t_test PARTITION (…) SELECT … WHERE …
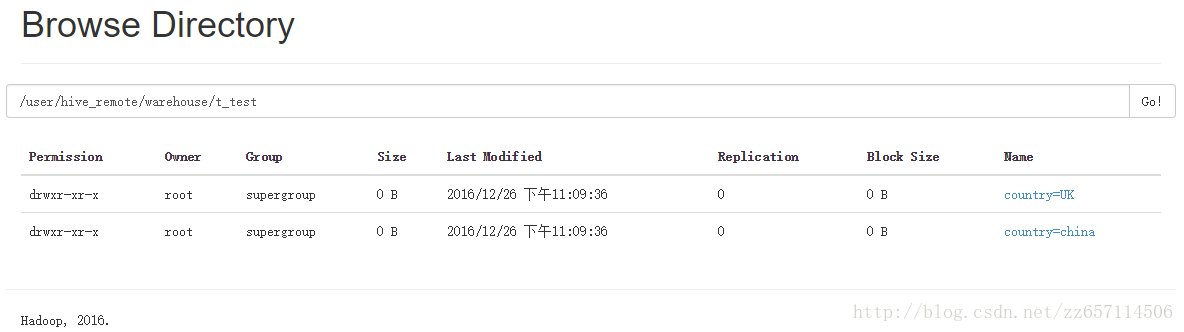
动态分区装载数据(分区不需指定)
若没有开启动态分区只支持以下写法
hive>INSERT OVERWRITE TABLE t_test PARTITION (country=’china’, city=’chengDu’)
SELECT name, age, addr
FROM t_emp
WHERE t_emp.country = ‘china’
AND t_emp.city = ‘chengDu’;
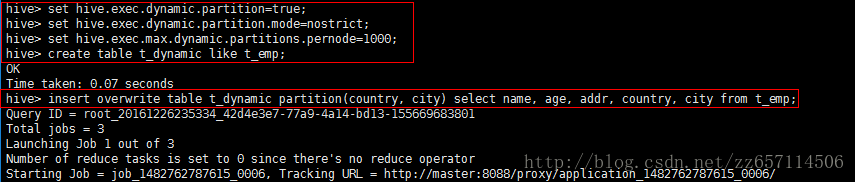
开启动态分区支持
hive>set hive.exec.dynamic.partition=true; // 开启动态分区
hive>set hive.exec.dynamic.partition.mode=nostrict; // 设置为非严格模式
hive>set hive.exec.max.dynamic.partitions.pernode=1000; // 最大动态可分区数
hive> insert overwrite table t_dynamic partition(country, city) select name, age, addr, country, city from t_emp;
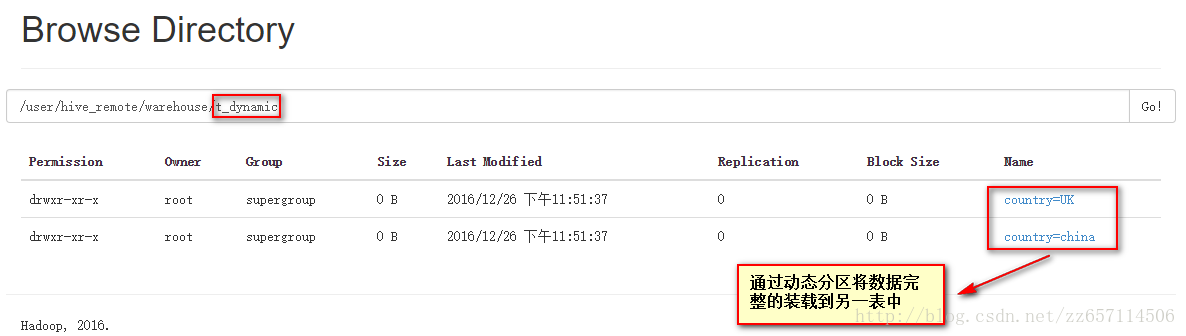
数据导出
通过hdfs方式导出
到本地
hive> dfs -copyToLocal /user/hive_remote/warehouse/t_dynamic /home/tt;
或
hive> dfs -get /user/hive_remote/warehouse/t_dynamic /home/t_dynamic;
到hdfs
hive> dfs -cp /user/hive_remote/warehouse/t_dynamic /tmp/t_dynamic;
使用DIRECTORY
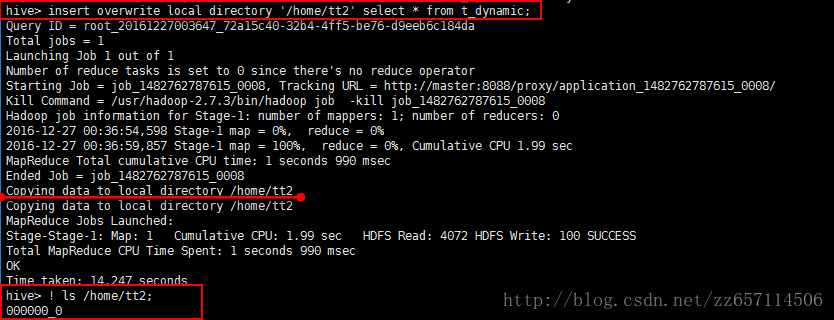
hive> insert overwrite [local] directory ‘/home/tt2’ select * from t_dynamic;
加local到本地/默认到hdfs
















 1313
1313











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









