








A Step by Step guide to Caffe
- 原文
- Caffe
- Caffe Model Zoo
- NVIDIA DIGITS - A Web GUI for deep learning
Step1 - GPU 选择
Step2 - Caffe 安装
- Caffe - Ubuntu 安装及问题解决
- Caffe官方安装指南
- Caffe在Ubuntu平台安装
- 利用 apt-get install 命令,可以有效的安装大部分依赖项. 不过,Caffe 包需要手动编译,因此需要了解一些关于make的知识.
Step3 - 数据准备 Data Preparation
Caffe 是一个高效计算的框架,为了更好的体现其惊人的GPU加速计算能力,为例避免文件I/O读写率影响训练效率,需要采用有效的数据格式。推荐使用 lmdb 格式.
如果对数据格式不太了解,数据处理后的 lmdb 会比较大的文件。 采用脚本语言可以访问该 lmdb 文件,从其中读取大规模数据的速度比直接读取文件快很多。
Caffe 提供了 convert_imageset 工具来对图像集建立 lmdb 格式文件,Caffe安装后,该 convert_imageset 的二值文件位于 /build/tools 文件夹内. 在 /caffe/examples/imagenet文件夹内也有一个 bash 脚本,说明了如何使用 convert_imageset.
采用Python将图像写入 lmdb 的方法参考博客.
数据转换后,可得到两个文件夹,其中,data.mdb 文件会非常大,保存着图像数据.
train_lmdb/
-- data.mdb
-- lock.mdb
val_lmdb/
-- data.mdb
-- lock.mdbStep4 - 设置Model和Solver
Caffe 具有一种非常友好的抽象,可以将神经网络定义(models)和优化(optimizers, solvers)分离. 其中,Model 定义了网络的结构,Solver定义了梯度下降求解的所有信息.
例如:
model 的定义形式如下:(注:假设 lmdb数据已经得到.)
#train_val.prototxt
name: "MyModel"
layer {
name: "data"
type: "Data"
top: "data"
top: "label"
include {
phase: TRAIN
}
transform_param {
mirror: false
crop_size: 227
mean_file: "data/train_mean.binaryproto" # 训练数据均值文件
}
data_param {
source: "data/train_lmdb" # 训练样本路径
batch_size: 128
backend: LMDB
}
}
layer {
name: "data"
type: "Data"
top: "data"
top: "label"
include {
phase: TEST
}
transform_param {
mirror: false
crop_size: 227
mean_file: "data/train_mean.binaryproto"
}
data_param {
source: "data/val_lmdb" # 验证数据路径
batch_size: 50
backend: LMDB
}
}
layer {
name: "conv1"
type: "Convolution"
bottom: "data"
top: "conv1"
param {
lr_mult: 0.01
decay_mult: 1
}
param {
lr_mult: 0.01
decay_mult: 0
}
convolution_param {
num_output: 96
kernel_size: 11
stride: 4
weight_filler {
type: "gaussian"
std: 0.01
}
bias_filler {
type: "constant"
value: 0
}
}
}
...
...
layer {
name: "accuracy"
type: "Accuracy"
bottom: "fc8"
bottom: "label"
top: "accuracy"
include {
phase: TEST
}
}
layer {
name: "loss"
type: "SoftmaxWithLoss"
bottom: "fc8"
bottom: "label"
top: "loss"
}该 Model 是 AlexNet 网络模型的一部分,可以在 caffe/models/bvlc_alexnet 查看完整版.
网络结构定义后,需要再定义 solver 文件,来指定网络训练参数:
net: "models/train_val.prototxt" #网络定义文件的路径
test_iter: 200 #测试阶段进行迭代的次数
test_interval: 500 #多久进行一次测试
base_lr: 1e-5 #基础学习率
lr_policy: "step" #学习率衰减的策略
gamma: 0.1 #ratio of decrement in each step
stepsize: 5000 #how often do we step (should be called step_interval)
display: 20 #显示 training loss
max_iter: 450000
momentum: 0.9
weight_decay: 0.0005 #正则化
snapshot: 2000 #多少次迭代保存一次训练模型
snapshot_prefix: "models/model3_train_0422" #模型保存路径
solver_mode: GPUStep5 - 网络结构可视化
Caffe 官方提供了基于 Python 的网络结构可视化工具 caffe/python/draw_net.py ,以便于检查网络定义. 如图:

也可采用一个在线工具进行网络可视化 —— Netscope.
Step6 - 开始训练
Model 和 Solver准备完毕,即可开始采用命令行来进行训练:
caffe train \
-gpu 0 \
-solver my_model/solver.prototxt这里仅指定了 Solver, Model 网络结构已经在 solver.prototxt 文件中定义,data 在 Model 中定义.
另外,也可以从 snapshot恢复训练:
caffe train \
-gpu 0 \
-solver my_model/solver.prototxt \
-snapshot my_model/my_model_iter_6000.solverstate 2>&1 | tee log/my_model.log或者从一个训练好的网络进行微调(fine tune):
caffe train \
-gpu 0 \
-solver my_model/solver.prototxt \
-weights my_model/bvlc_reference_caffenet.caffemodel 2>&1 | tee -a log/my_model.log其中,* … 2>&1 | tee -a log/my_model.log* 记录了网络初始化、网络训练过程的信息.
Step7 - 训练日志分析
Caffe 提供了网络训练日志分析的 python 脚本 —— caffe/tools/extra/parse_log.py,以得到两种格式化的文件:
#my_model.log.train
NumIters,Seconds,LearningRate,loss
6000.0,10.468114,1e-06,0.0476156
6020.0,17.372427,1e-06,0.0195639
6040.0,24.237645,1e-06,0.0556274
6060.0,31.084703,1e-06,0.0244656
6080.0,37.927866,1e-06,0.0325582
6100.0,44.778659,1e-06,0.0131274
6120.0,51.62342,1e-06,0.0607449
#my_model.log.test
NumIters,Seconds,LearningRate,accuracy,loss
6000.0,10.33778,1e-06,0.9944,0.0205859
6500.0,191.054363,1e-06,0.9948,0.0191656
7000.0,372.292923,1e-06,0.9951,0.0186095
7500.0,583.508988,1e-06,0.9947,0.0211263
8000.0,806.678746,1e-06,0.9947,0.0192824
8500.0,1027.549856,1e-06,0.9953,0.0183917
9000.0,1209.650574,1e-06,0.9949,0.0194651采用下面的 shell 脚本可以实现训练日志的自动分析并可视化loss曲线:
# visualize_log.sh
python ~/caffe/tools/extra/parse_log.py my_model.log .
gnuplot -persist gnuplot_commands其中, gnuplot_commands 是 gnuplot 命令文件:
# gnuplot_commands
set datafile separator ','
set term x11 0
plot '../my_model.log.train' using 1:4 with line,\
'../my_model.log.test' using 1:5 with line
set term x11 1
plot '../my_model.log.test' using 1:4 with line即可得到类似于下面的结果.
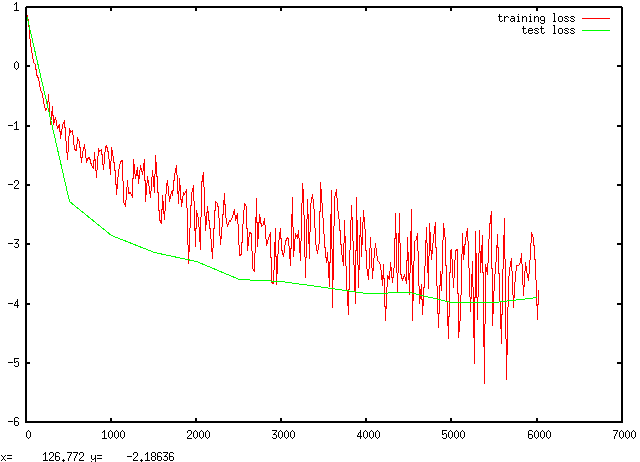
Step8 - 模型部署
网络训练结束后,需要创建 deploy.prototxt, 即可进行部署.
deploy.prototxt 是由 训练 Model 定义得到的,只需移除其数据层,添加输入层即可:
input: "data"
input_shape {
dim: 10 # batch size
dim: 3
dim: 227
dim: 227
}Python 模型部署代码示例如:
import numpy as np
import matplotlib.pyplot as plt
import sys
import caffe
#
MODEL_FILE = 'models/deploy.prototxt' # 部署网络定义文件路径
PRETRAINED = 'models/my_model_iter_10000.caffemodel' # 预训练的模型参数
#模型加载
caffe.set_mode_gpu()
caffe.set_device(0)
net = caffe.Classifier(MODEL_FILE, PRETRAINED,
mean=np.load('data/train_mean.npy').mean(1).mean(1),
channel_swap=(2,1,0),
raw_scale=255,
image_dims=(256, 256))
print "successfully loaded classifier"
#图片分类测试
IMAGE_FILE = 'path/to/image/img.png' # 待测试图片
input_image = caffe.io.load_image(IMAGE_FILE)
#预测任意数量的图片
#自动将图片转化为 Caffe Net 要求的数据形式
#得到预测结果
pred = net.predict([input_image])













 1207
1207











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









