









前言
本文介绍怎样执行Neural-Style算法。Neural-Style或者叫做Neural-Transfer,将一个内容图像和一个风格图像作为输入,返回一个按照所选择的风格图像加工的内容图像。
原理是非常简单的:我们定义两个距离,一个用于内容(Dc),另一个用于(Ds)。Dc测量两个图像的内容有多像,Ds测量两个图像的风格有多像。然后我们采用一个新图像(例如一个噪声图像),对它进行变化,同时最小化与内容图像的距离和与风格图像的距离。
数学推导
参考官网的教程 http://pytorch.org/tutorials/advanced/neural_style_tutorial.html
PyTorch中的实现
Packages
from __future__ import print_function
import torch
import torch.nn as nn
from torch.autograd import Variable
import torch.optim as optim
from PIL import Image
import matplotlib.pyplot as plt
import torchvision.transforms as transforms
import torchvision.models as models
import copyCuda
use_cuda = torch.cuda.is_available()
dtype = torch.cuda.FloatTensor if use_cuda else torch.FloatTensorLoad images
将下面两个图像picasso.jpg和dancing.jpg下载下来,放到images文件夹中。Images文件夹要在程序执行的当前目录。


# desired size of the output image
imsize = 512 if use_cuda else 128 # use small size if no gpu
loader = transforms.Compose([
transforms.Scale(imsize), # scale imported image
transforms.ToTensor()]) # transform it into a torch tensor
def image_loader(image_name):
image = Image.open(image_name)
image = Variable(loader(image))
# fake batch dimension required to fit network's input dimensions
image = image.unsqueeze(0)
return image
style_img = image_loader("images/picasso.jpg").type(dtype)
content_img = image_loader("images/dancing.jpg").type(dtype)
assert style_img.size() == content_img.size(), \
"we need to import style and content images of the same size"Display images
unloader = transforms.ToPILImage() # reconvert into PIL image
plt.ion()
def imshow(tensor, title=None):
image = tensor.clone().cpu() # we clone the tensor to not do changes on it
image = image.view(3, imsize, imsize) # remove the fake batch dimension
image = unloader(image)
plt.imshow(image)
if title is not None:
plt.title(title)
plt.pause(0.001) # pause a bit so that plots are updated
plt.figure()
imshow(style_img.data, title='Style Image')
plt.figure()
imshow(content_img.data, title='Content Image')运行效果:

Content loss
class ContentLoss(nn.Module):
def __init__(self, target, weight):
super(ContentLoss, self).__init__()
# we 'detach' the target content from the tree used
self.target = target.detach() * weight
# to dynamically compute the gradient: this is a stated value,
# not a variable. Otherwise the forward method of the criterion
# will throw an error.
self.weight = weight
self.criterion = nn.MSELoss()
def forward(self, input):
self.loss = self.criterion(input * self.weight, self.target)
self.output = input
return self.output
def backward(self, retain_graph=True):
self.loss.backward(retain_graph=retain_graph)
return self.lossStyle loss
class GramMatrix(nn.Module):
def forward(self, input):
a, b, c, d = input.size() # a=batch size(=1)
# b=number of feature maps
# (c,d)=dimensions of a f. map (N=c*d)
features = input.view(a * b, c * d) # resise F_XL into \hat F_XL
G = torch.mm(features, features.t()) # compute the gram product
# we 'normalize' the values of the gram matrix
# by dividing by the number of element in each feature maps.
return G.div(a * b * c * d)class StyleLoss(nn.Module):
def __init__(self, target, weight):
super(StyleLoss, self).__init__()
self.target = target.detach() * weight
self.weight = weight
self.gram = GramMatrix()
self.criterion = nn.MSELoss()
def forward(self, input):
self.output = input.clone()
self.G = self.gram(input)
self.G.mul_(self.weight)
self.loss = self.criterion(self.G, self.target)
return self.output
def backward(self, retain_graph=True):
self.loss.backward(retain_graph=retain_graph)
return self.lossLoad the neural network
cnn = models.vgg19(pretrained=True).features
# move it to the GPU if possible:
if use_cuda:
cnn = cnn.cuda()# desired depth layers to compute style/content losses :
content_layers_default = ['conv_4']
style_layers_default = ['conv_1', 'conv_2', 'conv_3', 'conv_4', 'conv_5']
def get_style_model_and_losses(cnn, style_img, content_img,
style_weight=1000, content_weight=1,
content_layers=content_layers_default,
style_layers=style_layers_default):
cnn = copy.deepcopy(cnn)
# just in order to have an iterable access to or list of content/syle
# losses
content_losses = []
style_losses = []
model = nn.Sequential() # the new Sequential module network
gram = GramMatrix() # we need a gram module in order to compute style targets
# move these modules to the GPU if possible:
if use_cuda:
model = model.cuda()
gram = gram.cuda()
i = 1
for layer in list(cnn):
if isinstance(layer, nn.Conv2d):
name = "conv_" + str(i)
model.add_module(name, layer)
if name in content_layers:
# add content loss:
target = model(content_img).clone()
content_loss = ContentLoss(target, content_weight)
model.add_module("content_loss_" + str(i), content_loss)
content_losses.append(content_loss)
if name in style_layers:
# add style loss:
target_feature = model(style_img).clone()
target_feature_gram = gram(target_feature)
style_loss = StyleLoss(target_feature_gram, style_weight)
model.add_module("style_loss_" + str(i), style_loss)
style_losses.append(style_loss)
if isinstance(layer, nn.ReLU):
name = "relu_" + str(i)
model.add_module(name, layer)
if name in content_layers:
# add content loss:
target = model(content_img).clone()
content_loss = ContentLoss(target, content_weight)
model.add_module("content_loss_" + str(i), content_loss)
content_losses.append(content_loss)
if name in style_layers:
# add style loss:
target_feature = model(style_img).clone()
target_feature_gram = gram(target_feature)
style_loss = StyleLoss(target_feature_gram, style_weight)
model.add_module("style_loss_" + str(i), style_loss)
style_losses.append(style_loss)
i += 1
if isinstance(layer, nn.MaxPool2d):
name = "pool_" + str(i)
model.add_module(name, layer) # ***
return model, style_losses, content_lossesInput image
input_img = content_img.clone()
# if you want to use a white noise instead uncomment the below line:
# input_img = Variable(torch.randn(content_img.data.size())).type(dtype)
# add the original input image to the figure:
plt.figure()
imshow(input_img.data, title='Input Image')运行效果:

Gradient descent
def get_input_param_optimizer(input_img):
# this line to show that input is a parameter that requires a gradient
input_param = nn.Parameter(input_img.data)
optimizer = optim.LBFGS([input_param])
return input_param, optimizer定义算法并运行
def run_style_transfer(cnn, content_img, style_img, input_img, num_steps=300,
style_weight=1000, content_weight=1):
"""Run the style transfer."""
print('Building the style transfer model..')
model, style_losses, content_losses = get_style_model_and_losses(cnn,
style_img, content_img, style_weight, content_weight)
input_param, optimizer = get_input_param_optimizer(input_img)
print('Optimizing..')
run = [0]
while run[0] <= num_steps:
def closure():
# correct the values of updated input image
input_param.data.clamp_(0, 1)
optimizer.zero_grad()
model(input_param)
style_score = 0
content_score = 0
for sl in style_losses:
style_score += sl.backward()
for cl in content_losses:
content_score += cl.backward()
run[0] += 1
if run[0] % 50 == 0:
print("run {}:".format(run))
print('Style Loss : {:4f} Content Loss: {:4f}'.format(
style_score.data[0], content_score.data[0]))
print()
return style_score + content_score
optimizer.step(closure)
# a last correction...
input_param.data.clamp_(0, 1)
return input_param.dataoutput = run_style_transfer(cnn, content_img, style_img, input_img)
plt.figure()
imshow(output, title='Output Image')
# sphinx_gallery_thumbnail_number = 4
plt.ioff()
plt.show()运行结果:

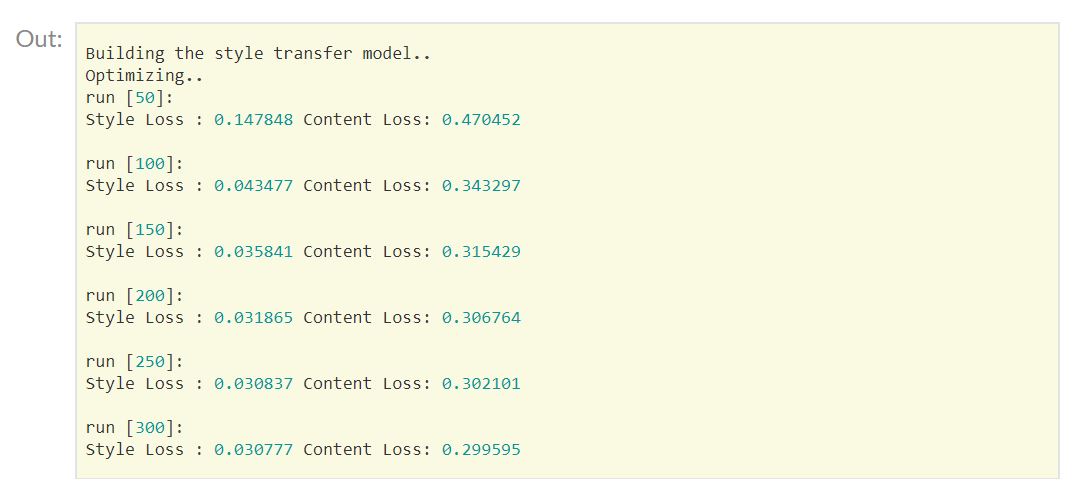
完整脚本下载:
链接: https://pan.baidu.com/s/1miHyz3M 密码: 95q4














 2094
2094











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









