修改标签将yolo txt转为coco json文件,转化的为str格式,代码如下
import os
import json
import cv2
import random
import time
from PIL import Image
# 部分同学都用的autodl, 用antodl举例
# 使用绝对路径
# 数据集 txt格式-labels标签文件夹
txt_labels_path = r'C:\Users'
# 数据集图片images文件夹
datasets_img_path = r'C:\Users'
# 这里 voc 为数据集文件名字,可以改成自己的路径
# xx.json生成之后存放的地址
save_path = r'C:\Users\wang/' # 指定生成的json文件的存放路径
classes_txt = r'C:\Users\wang\'
with open(classes_txt, 'r') as fr:
lines1 = fr.readlines()
categories = []
for j, label in enumerate(lines1):
label = label.strip()
categories.append({'id': j, 'name': label, 'supercategory': 'None'})
print(categories)
write_json_context = dict()
write_json_context['info'] = {'description': 'For object detection', 'url': '', 'version': '', 'year': 2021,
'contributor': '', 'date_created': '2021'}
write_json_context['licenses'] = [{'id': 1, 'name': None, 'url': None}]
write_json_context['categories'] = categories
write_json_context['images'] = []
write_json_context['annotations'] = []
imageFileList = os.listdir(datasets_img_path)
for i, imageFile in enumerate(imageFileList):
imagePath = os.path.join(datasets_img_path, imageFile)
image = Image.open(imagePath)
W, H = image.size
img_context = {}
img_context['file_name'] = imageFile
img_context['height'] = H
img_context['width'] = W
print(f"Before conversion: {imageFile[:-4]}")
img_context['id'] = imageFile[:-4]
int_id = str(img_context['id'])
print(f"After conversion: {img_context['id']}")
img_context['license'] = 1
img_context['color_url'] = ''
img_context['flickr_url'] = ''
write_json_context['images'].append(img_context)
# txtFile = str(imageFile[:-4]) + '.txt'
txtFile = str(img_context['id']) + '.txt'
with open(os.path.join(txt_labels_path, txtFile), 'r') as fr:
lines = fr.readlines()
for j, line in enumerate(lines):
bbox_dict = {}
class_id, x, y, w, h = line.strip().split(' ')
class_id, x, y, w, h = int(class_id), float(x), float(y), float(w), float(h)
xmin = (x - w / 2) * W
ymin = (y - h / 2) * H
xmax = (x + w / 2) * W
ymax = (y + h / 2) * H
w = w * W
h = h * H
bbox_dict['id'] = i * 10000 + j
# bbox_dict['image_id'] = str(imageFile[:-
bbox_dict['image_id'] = str(img_context['id'])
bbox_dict['category_id'] = class_id
bbox_dict['iscrowd'] = 0
height, width = abs(ymax - ymin), abs(xmax - xmin)
bbox_dict['area'] = height * width
bbox_dict['bbox'] = [xmin, ymin, w, h]
bbox_dict['segmentation'] = [[xmin, ymin, xmax, ymin, xmax, ymax, xmin, ymax]]
write_json_context['annotations'].append(bbox_dict)
name = os.path.join(save_path, "instances_val2017.json")
with open(name, 'w') as fw:
json.dump(write_json_context, fw, indent=2)
print("ok")
然后使用coco评价指标代码如下
import argparse
import pickle, json
import numpy as np
from pycocotools.coco import COCO
from pycocotools.cocoeval import COCOeval
from terminaltables import AsciiTable
parser = argparse.ArgumentParser(description='Calculating metrics (AR, Recall) in every class')
parser.add_argument('--det_json', default=r'D:\xia\best_predictions.json', type=str,
help='inference detection json file path')
parser.add_argument('--gt_json', default=r'C:\Users\wang\Desktop\geshi\\instances_val2017.json', type=str,
help='ground truth json file path')
parser.add_argument('--classes', default=(
填写自己标签 'person', 'wind-mill'), type=tuple,
help='every class name with str type in a tuple')
def read_pickle(pkl):
with open(pkl, 'rb') as f:
data = pickle.load(f)
return data
def read_json(json_pth):
with open(json_pth, 'r') as f:
data = json.load(f)
return data
def process(det_json, gt_json, CLASSES):
cocoGt = COCO(gt_json)
# 获取类别(单类)对应的所有图片id
catIds = cocoGt.getCatIds(catNms=list(CLASSES))
# 获取多个类别对应的所有图片的id
imgid_list = []
for id_c in catIds:
imgIds = cocoGt.getImgIds(catIds=id_c)
imgid_list.extend(imgIds)
# 通过gt的json文件和pred的json文件计算map
class_num = len(CLASSES)
cocoGt = COCO(gt_json)
cocoDt = cocoGt.loadRes(det_json)
cocoEval = COCOeval(cocoGt, cocoDt, "bbox")
cocoEval.params.iouThrs = np.linspace(0.5, 0.95, int(np.round((0.95 - .5) / .05)) + 1, endpoint=True)
cocoEval.params.maxDets = list((100, 300, 1000))
cocoEval.evaluate()
cocoEval.accumulate()
cocoEval.summarize()
# 计算每个类别的recall
precisions = cocoEval.eval['precision'] # [TxRxKxAxM],TP/(TP+FP) right/detection
recalls = cocoEval.eval['recall'] # [TxKxAxM],TP/(TP+FN) right/gt
# 打印COCO API的总体AP
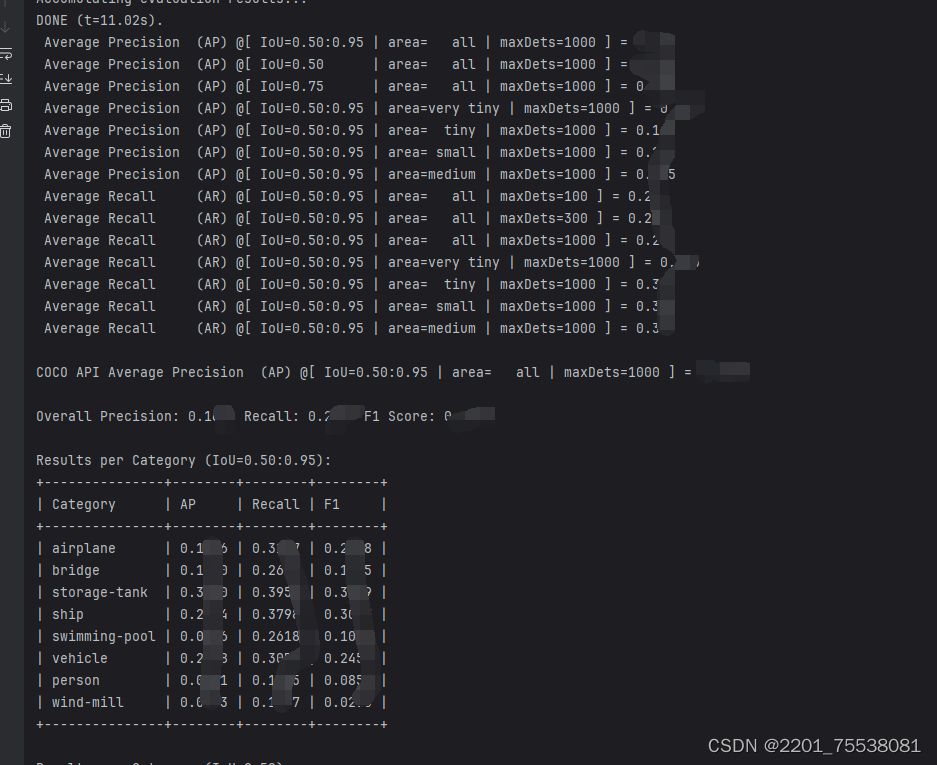
overall_ap = cocoEval.stats[0] # AP @[ IoU=0.50:0.95 | area= all | maxDets=1000 ]
print(
'\nCOCO API Average Precision (AP) @[ IoU=0.50:0.95 | area= all | maxDets=1000 ] = {:.4f}'.format(overall_ap))
# 计算总体指标
overall_precision = np.mean(precisions[precisions > -1])
overall_recall = np.mean(recalls[recalls > -1])
overall_f1 = 2 * (overall_precision * overall_recall) / (overall_precision + overall_recall)
print('\nOverall Precision: {:.4f} Recall: {:.4f} F1 Score: {:.4f}'.format(overall_precision, overall_recall,
overall_f1))
# Compute per-category AP and Recall, and F1 score
results_per_category = []
results_per_category_iou50 = []
results_per_category_iou75 = []
res_item = []
ap_list = []
for idx, catId in enumerate(catIds):
name = CLASSES[idx]
precision = precisions[:, :, idx, 0, -1]
precision_50 = precisions[0, :, idx, 0, -1]
precision_75 = precisions[5, :, idx, 0, -1] # IoU = 0.75 corresponds to the 6th index (0-based index)
precision = precision[precision > -1]
recall = recalls[:, idx, 0, -1]
recall_50 = recalls[0, idx, 0, -1]
recall_75 = recalls[5, idx, 0, -1] # IoU = 0.75 corresponds to the 6th index (0-based index)
recall = recall[recall > -1]
if precision.size:
ap = np.mean(precision)
ap_50 = np.mean(precision_50)
ap_75 = np.mean(precision_75)
rec = np.mean(recall)
rec_50 = np.mean(recall_50)
rec_75 = np.mean(recall_75)
f1 = 2 * (ap * rec) / (ap + rec) if (ap + rec) > 0 else 0
f1_50 = 2 * (ap_50 * rec_50) / (ap_50 + rec_50) if (ap_50 + rec_50) > 0 else 0
f1_75 = 2 * (ap_75 * rec_75) / (ap_75 + rec_75) if (ap_75 + rec_75) > 0 else 0
else:
ap = float('nan')
ap_50 = float('nan')
ap_75 = float('nan')
rec = float('nan')
rec_50 = float('nan')
rec_75 = float('nan')
f1 = float('nan')
f1_50 = float('nan')
f1_75 = float('nan')
ap_list.append(ap)
res_item = [f'{name}', f'{float(ap):0.4f}', f'{float(rec):0.4f}', f'{float(f1):0.4f}']
results_per_category.append(res_item)
res_item_50 = [f'{name}', f'{float(ap_50):0.4f}', f'{float(rec_50):0.4f}', f'{float(f1_50):0.4f}']
results_per_category_iou50.append(res_item_50)
res_item_75 = [f'{name}', f'{float(ap_75):0.4f}', f'{float(rec_75):0.4f}', f'{float(f1_75):0.4f}']
results_per_category_iou75.append(res_item_75)
# 打印每个类别的结果
headers = ['Category', 'AP', 'Recall', 'F1']
table_data = [headers] + results_per_category
table = AsciiTable(table_data)
print('\nResults per Category (IoU=0.50:0.95):\n' + table.table)
headers_50 = ['Category','AP_50', 'Recall_50', 'F1_50']
table_data_50 = [headers_50] + results_per_category_iou50
table_50 = AsciiTable(table_data_50)
print('\nResults per Category (IoU=0.50):\n' + table_50.table)
headers_75 = ['Category', 'AP_75', 'Recall_75', 'F1_75']
table_data_75 = [headers_75] + results_per_category_iou75
table_75 = AsciiTable(table_data_75)
print('\nResults per Category (IoU=0.75):\n' + table_75.table)
# 计算每个类别的平均AP
mean_ap = np.nanmean(ap_list)
print('\nMean AP (average over all categories): {:.4f}'.format(mean_ap))
if __name__ == '__main__':
args = parser.parse_args()
process(det_json=args.det_json, gt_json=args.gt_json, CLASSES=args.classes)






















 2807
2807

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









