










博主介绍:✌全网粉丝10W+,前互联网大厂软件研发、集结硕博英豪成立工作室。专注于计算机相关专业毕业设计项目实战6年之久,选择我们就是选择放心、选择安心毕业✌感兴趣的可以先收藏起来,点赞、关注不迷路✌
毕业设计:2023-2024年计算机毕业设计1000套(建议收藏)
毕业设计:2023-2024年最新最全计算机专业毕业设计选题汇总
1、项目介绍
技术栈:
Django框架、requests爬虫、ARIMA 时序预测模型 【销量预测】、MySQL数据库、淘宝数据
2、项目界面
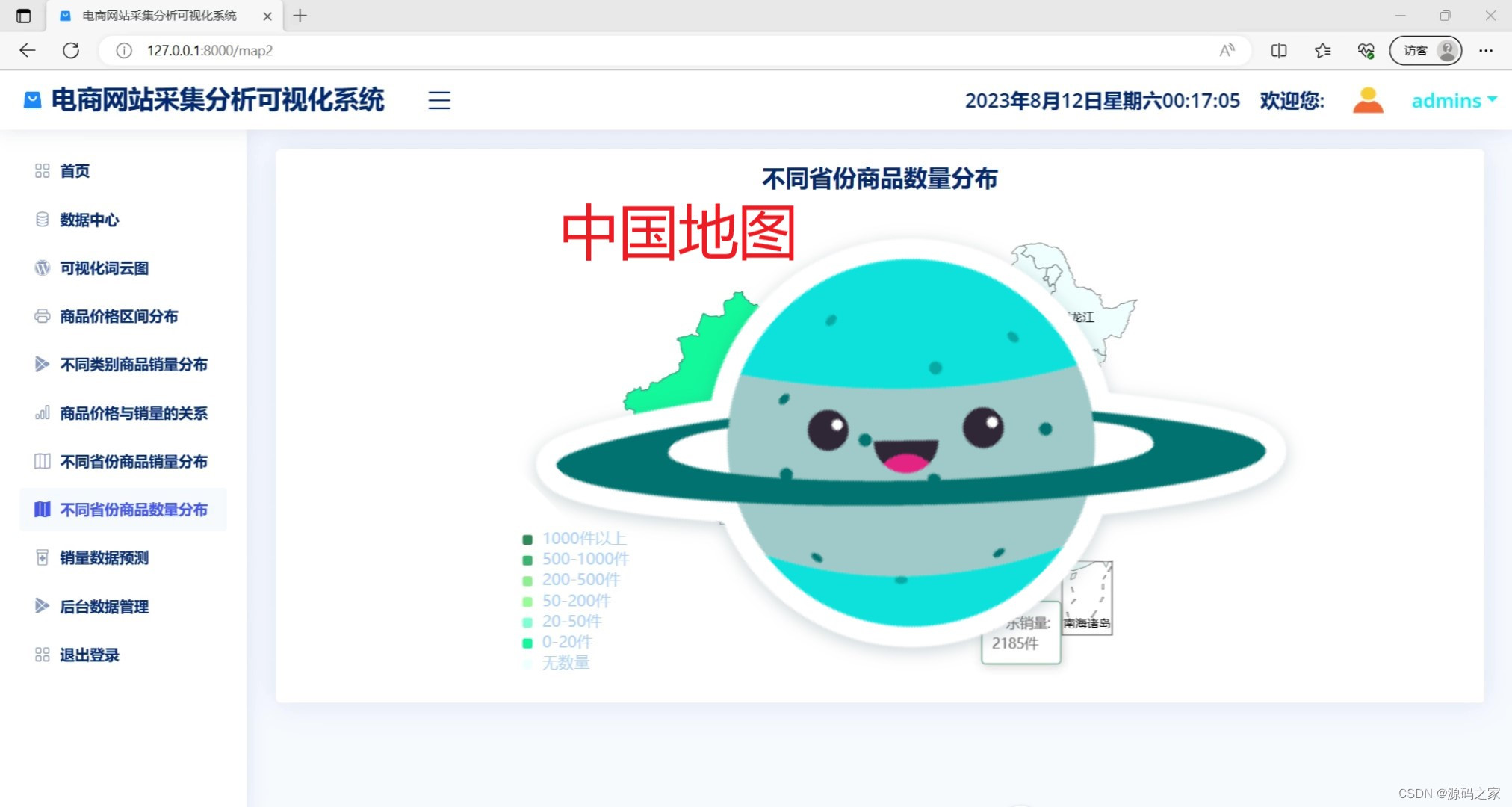
(1)不同省份商品数量分布地图
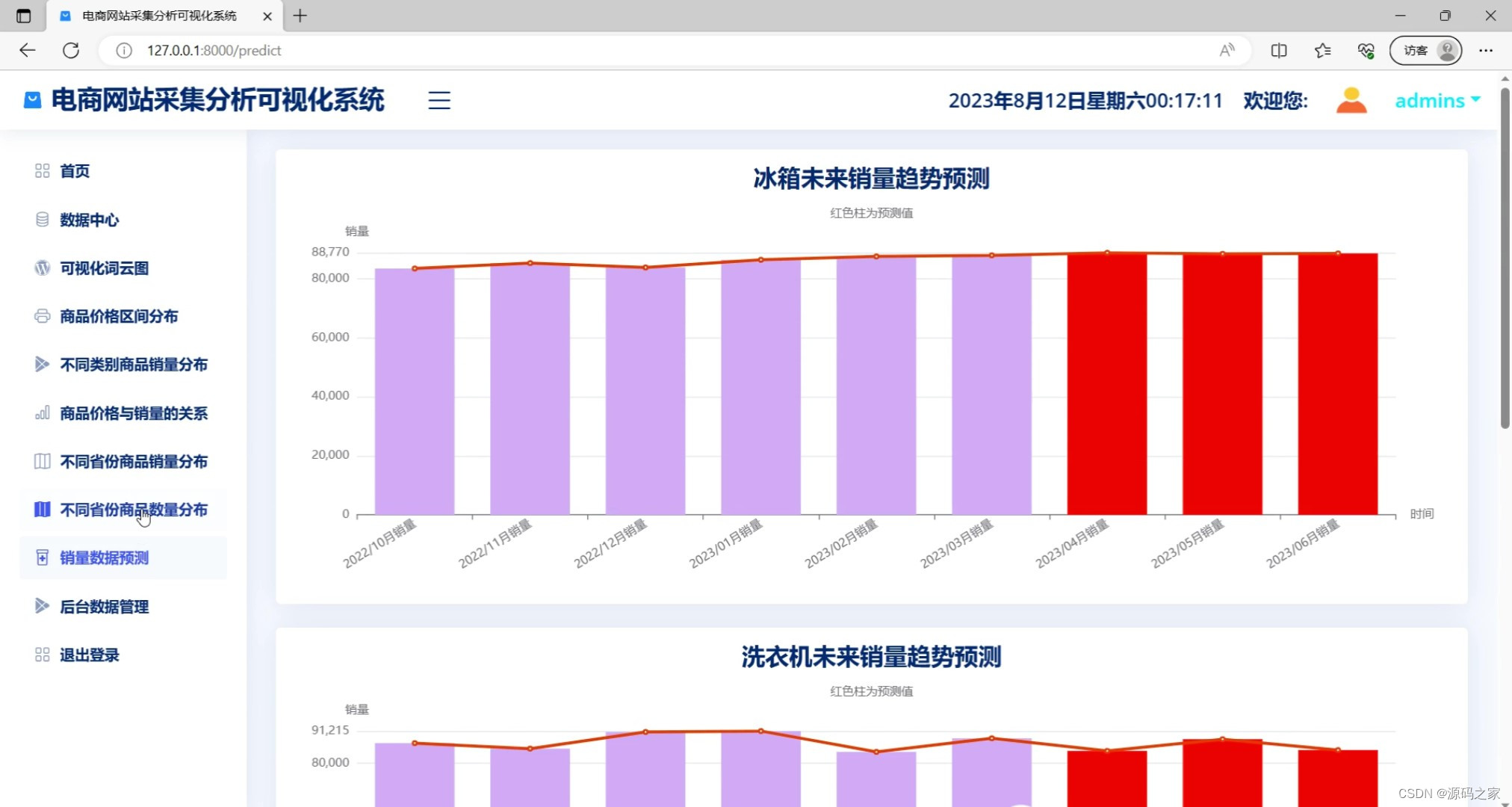
(2)销量预测------ARIMA 时序预测模型 【销量预测】
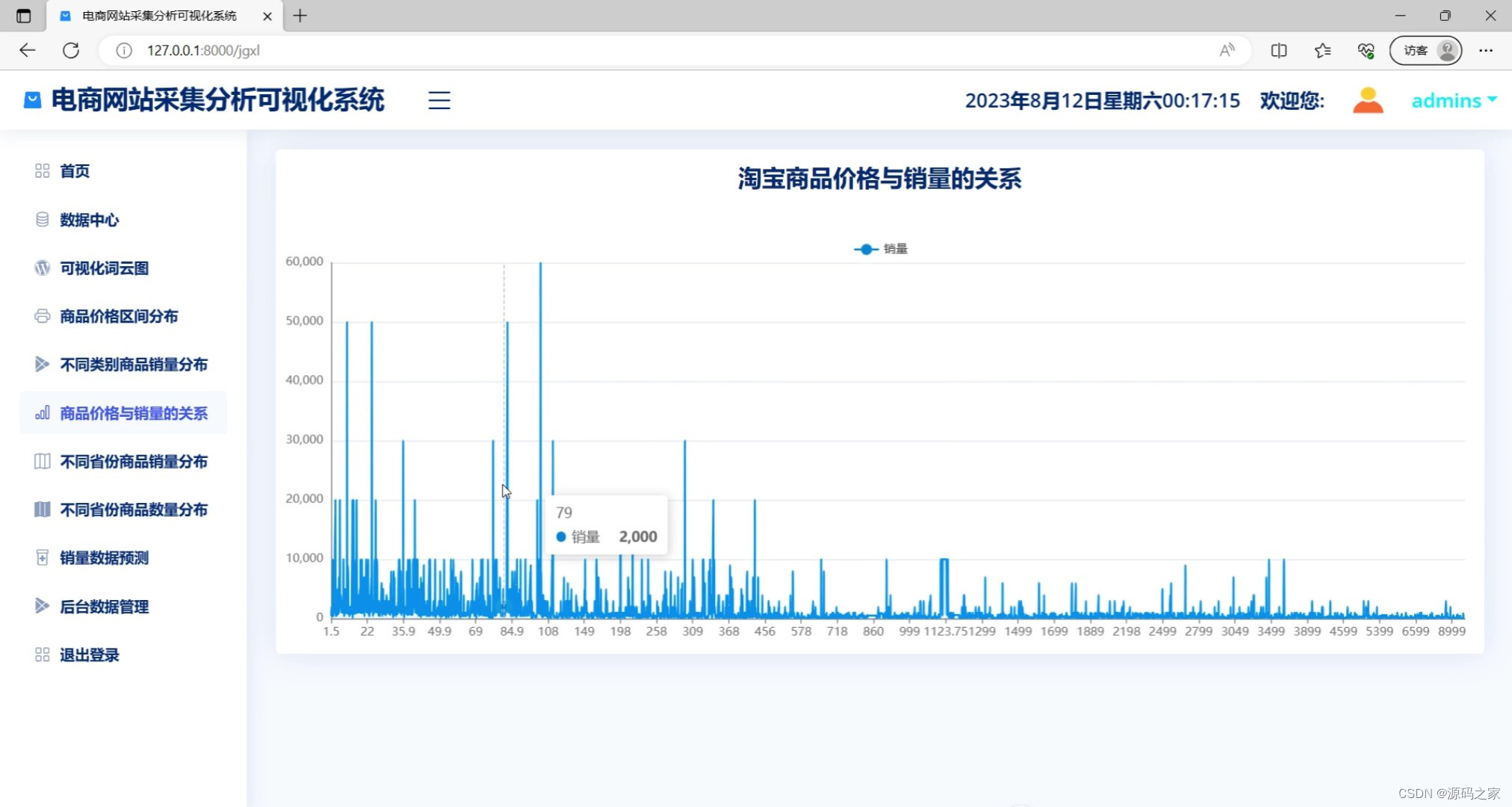
(3)商品价格与销量的关系
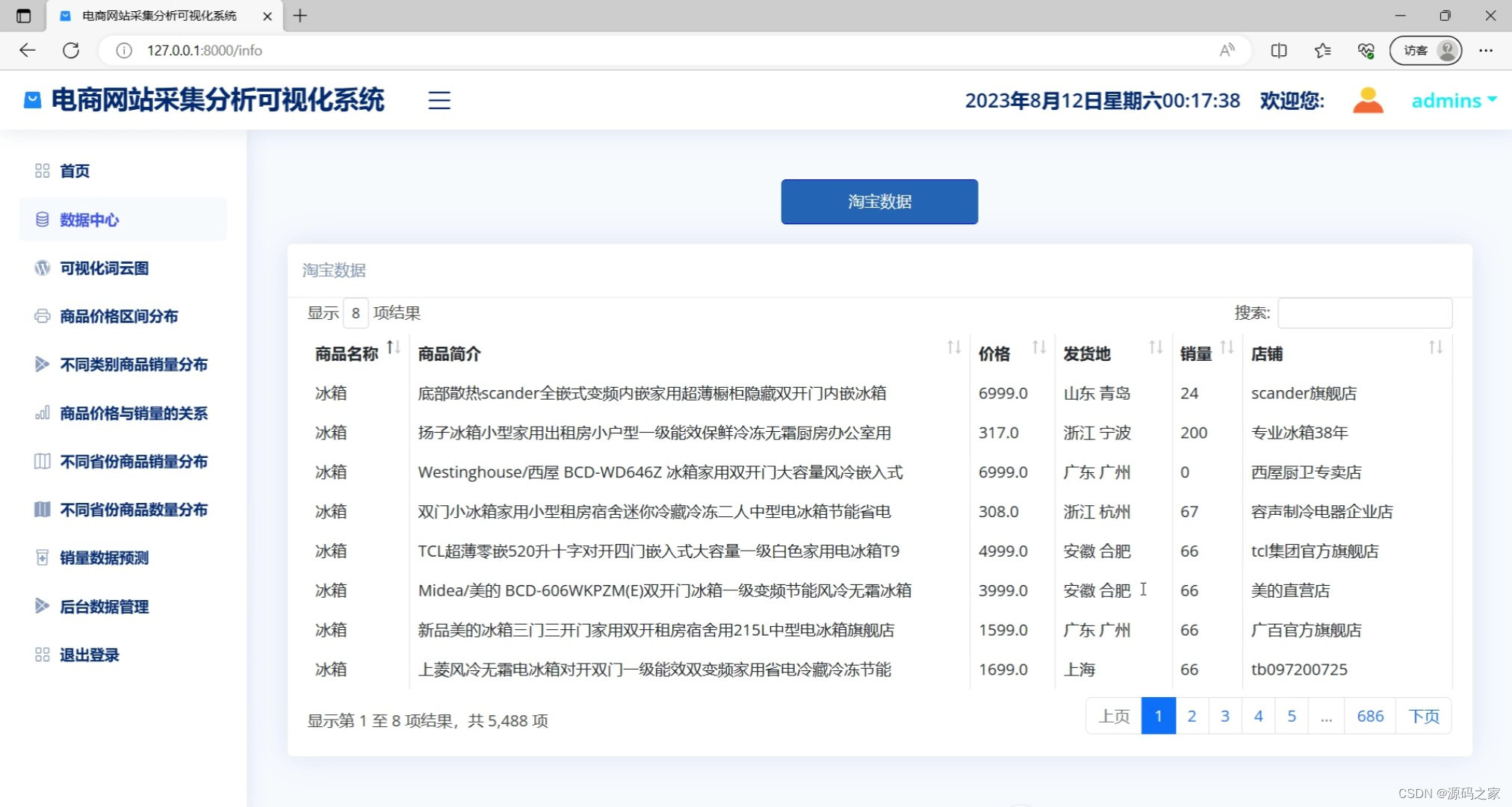
(4)商品数据
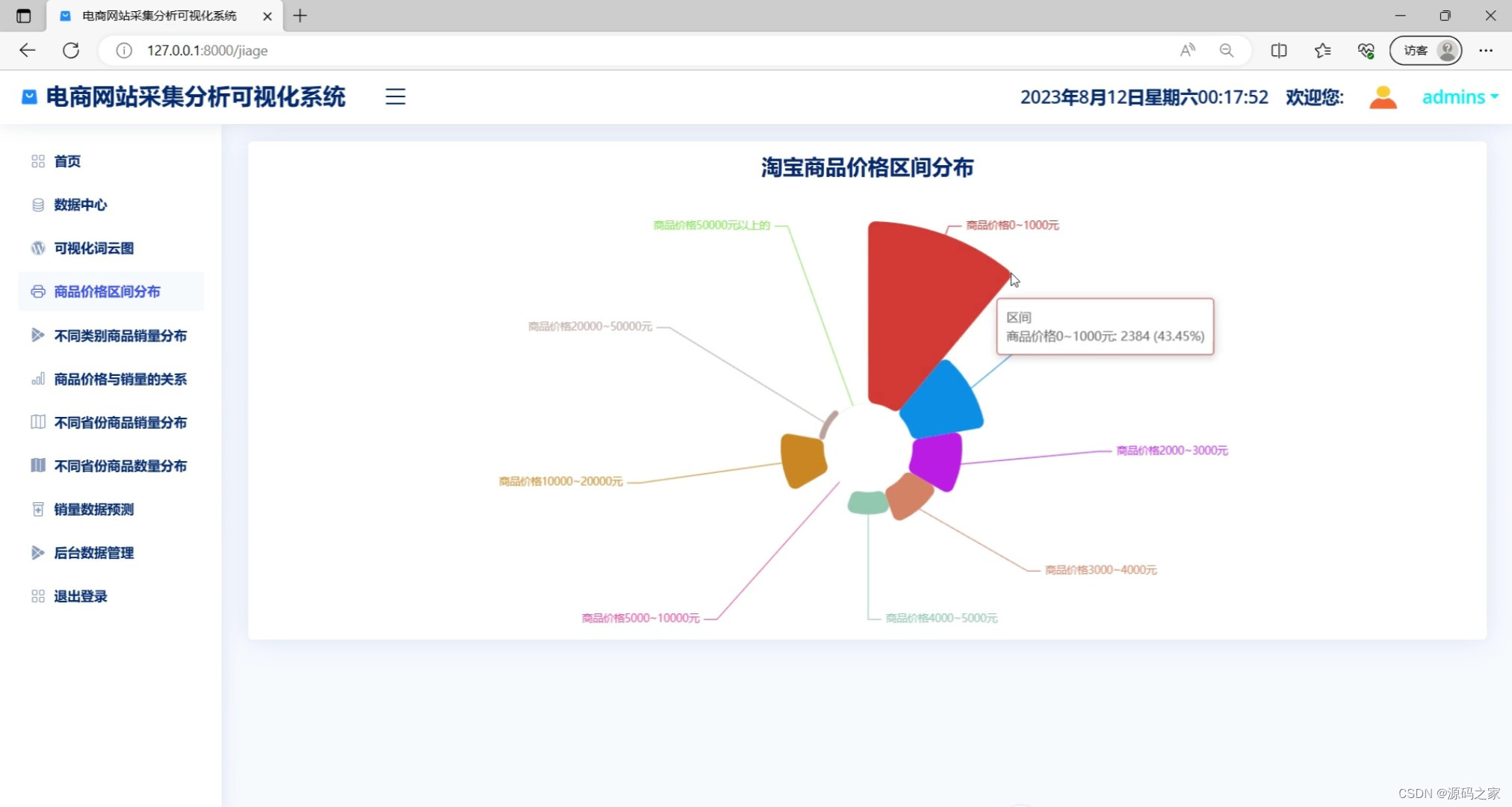
(5)商品价格区间分布
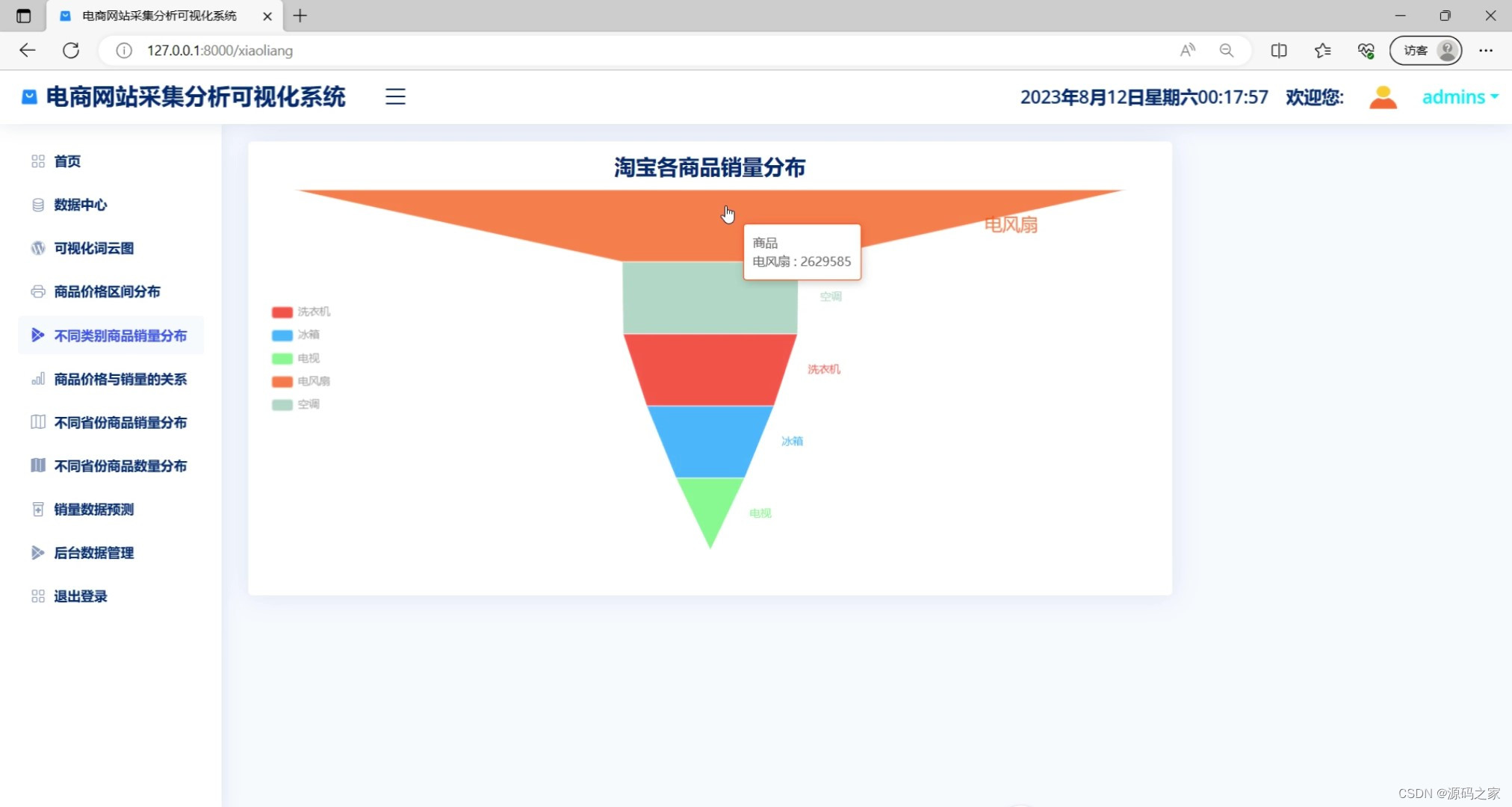
(6)各类商品销量分布
(7)首页
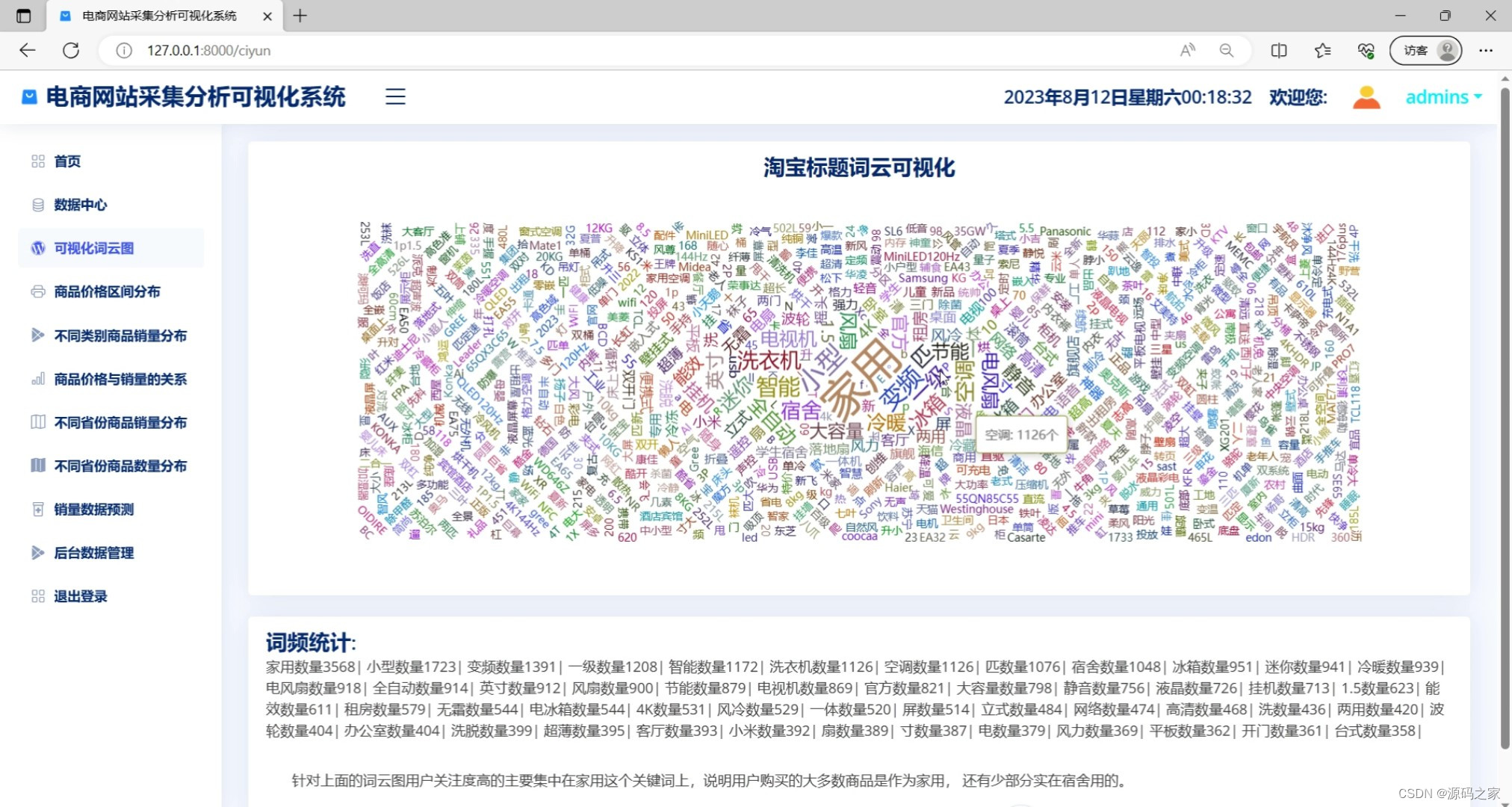
(8)词云图分析
(9)后台数据管理
3、项目说明
在当今的数字化时代,数据分析与预测在各行各业都发挥着至关重要的作用。特别是在电子商务领域,如淘宝这样的平台,数据分析与预测更是其核心竞争力之一。本文将详细介绍如何使用Django框架、ARIMA时序预测模型(销量预测)以及MySQL数据库构建一个淘宝商品数据分析预测系统。
首先,Django框架是一个高级的Python Web框架,它能够帮助开发者快速开发安全、可维护的网站。在构建淘宝商品数据分析预测系统时,Django框架的MVC(或MTV)设计模式能够使得系统的结构更加清晰,便于后期维护和扩展。此外,Django框架还提供了丰富的模板和视图功能,使得开发者可以更加专注于业务逻辑的实现,而无需过多关注底层的技术细节。
接下来,ARIMA时序预测模型(销量预测)是构建淘宝商品数据分析预测系统的核心部分。ARIMA模型是一种基于时间序列数据的预测方法,它能够将非平稳的时间序列转化为平稳的时间序列,并通过分析历史数据来预测未来的销量。在淘宝商品数据分析预测系统中,ARIMA模型可以根据商品的历史销量数据,预测出未来一段时间内的销量趋势,为商家提供重要的决策支持。
MySQL数据库则是存储和管理淘宝商品数据的重要工具。MySQL是一种关系型数据库管理系统,具有高效、稳定、可靠的特点。在淘宝商品数据分析预测系统中,MySQL数据库可以存储商品的基本信息、历史销量数据以及其他相关数据。同时,MySQL数据库还提供了强大的查询和分析功能,使得开发者可以轻松地对数据进行提取和分析。
最后,淘宝商品数据分析预测系统是一个集成了Django框架、ARIMA时序预测模型和MySQL数据库的综合系统。该系统可以从淘宝平台上获取商品数据,并使用ARIMA模型进行销量预测。同时,该系统还可以将预测结果以图表、报表等形式展示给商家,帮助商家更好地了解市场趋势和商品表现。此外,该系统还支持数据导出和自定义查询等功能,使得商家可以更加灵活地利用数据进行决策分析。
总之,Django框架、ARIMA时序预测模型和MySQL数据库是构建淘宝商品数据分析预测系统的重要工具。通过将这些工具进行有效的整合和应用,我们可以为商家提供一个功能强大、易于使用的数据分析预测系统,帮助商家更好地把握市场机遇和应对挑战。
4、核心代码
def login(request):
if request.method == "GET":
return render(request, 'login.html')
if request.method == 'POST':
# 验证表单数据
username = request.POST['username']
password = request.POST['password']
login_type = request.POST.get('login_type', 'frontend')
# 认证用户
user = auth.authenticate(request, username=username, password=password)
if user is not None:
if user.is_active:
# 登录用户并跳转到相应页面
auth.login(request, user)
if login_type == 'admin':
return redirect('admin:index')
else:
return redirect('index')
else:
error_msg = '用户名或密码错误'
return render(request, 'login.html', context={'error_msg': error_msg})
def logout(request):
auth.logout(request)
return redirect('login') # 重定向到登录
def query_database(query, args=()):
conn = sqlite3.connect(BASE_DIR + '/db.sqlite3')
cursor = conn.cursor()
cursor.execute(query, args)
result = cursor.fetchall()
headers = [i[0] for i in cursor.description]
conn.commit()
conn.close()
data = [headers] + list(result)
df = pd.DataFrame(data[1:], columns=data[0])
# print(df)
return df
@login_required
def home(request):
return redirect('index')
@login_required
def index(request):
return render(request, 'index.html')
@login_required
def info(request):
query1 = 'select * from 淘宝数据'
df1 = query_database(query1)
rows1 = df1.values
return render(request, 'info.html', locals())
@login_required
def ciyun(request):
query1 = 'select * from 淘宝数据'
df1 = query_database(query1)
def cy(df):
# 词云图数据处理
titles = df['标题'].tolist()
# 加载停用词表
stopwords = set()
with open(BASE_DIR + r'./app/StopWords.txt', 'r', encoding='utf-8') as f:
for line in f:
stopwords.add(line.strip())
# 将数据进行分词并计算词频
words = []
for item in titles:
if item:
words += jieba.lcut(item.replace(' ', ''))
word_counts = Counter([w for w in words if w not in stopwords])
# 获取词频最高的词汇
top20_words = word_counts.most_common()
words_data = []
for word in top20_words:
words_data.append({'name': word[0], 'value': word[1]})
return words_data
word1 = cy(df1)
return render(request, 'ciyun.html', locals())
@login_required
def jiage(request):
query1 = 'select * from 淘宝数据'
df1 = query_database(query1)
def cy(df):
# 商品价格区间分布
data_res = [[], [], [], [], [], [], [], [], [], []]
for data in df['价格'].values.tolist():
print(data)
if data <= 1000:
data_res[0].append(data)
if 1000 < data <= 2000:
data_res[1].append(data)
if 2000 < data <= 3000:
data_res[2].append(data)
if 3000 < data <= 4000:
data_res[3].append(data)
if 4000 < data <= 5000:
data_res[4].append(data)
if 5000 < data <= 10000:
data_res[6].append(data)
if 10000 < data <= 20000:
data_res[7].append(data)
if 20000 < data <= 50000:
data_res[8].append(data)
if 50000 < data:
data_res[9].append(data)
data_col = [f'商品价格0~1000元',
f'商品价格1000~2000元',
f'商品价格2000~3000元',
f'商品价格3000~4000元',
f'商品价格4000~5000元',
f'商品价格5000~10000元',
f'商品价格10000~20000元',
f'商品价格20000~50000元',
f'商品价格50000元以上的', ]
data_num = [len(i) for i in data_res]
data_price_interval = []
for key, value in zip(data_col, data_num):
data_price_interval.append({'name': key, 'value': value})
return data_price_interval
word1 = cy(df1)
return render(request, 'jiage.html', locals())
@login_required
def xiaoliang(request):
query1 = 'select * from 淘宝数据'
df1 = query_database(query1)
def cy(sales_df):
# 商品销量分布情况
data_dict = {}
for i in sales_df:
print(i)
key = i[0]
value = '0'
if i[1]:
value = str(i[1]).replace('万', '0000').replace('+', '').replace('评价', '').replace('.', '')
if data_dict.get(key):
data_dict[key] += int(value)
else:
data_dict[key] = int(value)
sales_data = []
sales_key = []
for key, value in data_dict.items():
sales_key.append(key)
sales_data.append({'name': key, 'value': value})
return sales_key, sales_data
sales_key1, sales_data1 = cy(df1[['word', '销量']].values.tolist())
return render(request, 'xiaoliang.html', locals())
@login_required
def map(request):
query1 = 'select * from 淘宝数据'
df1 = query_database(query1)
# 地图销量数据处理
addr = df1[['发货地', '销量']]
addr_data = addr.groupby('发货地')['销量'].sum()
map_data = []
addr_dict = {}
for key, value in addr_data.to_dict().items():
key = key.split(' ')[0]
if addr_dict.get(key):
addr_dict[key] += value
else:
addr_dict[key] = value
for key, value in addr_dict.items():
map_data.append({'name': key, 'value': value})
return render(request, 'map.html', locals())
@login_required
def map2(request):
query1 = 'select * from 淘宝数据'
df1 = query_database(query1)
# 地图销量数据处理
addr = df1['发货地'].value_counts()
map_data = []
addr_dict = {}
for key, value in addr.to_dict().items():
key = key.split(' ')[0]
if addr_dict.get(key):
addr_dict[key] += value
else:
addr_dict[key] = value
for key, value in addr_dict.items():
map_data.append({'name': key, 'value': value})
return render(request, 'map2.html', locals())
@login_required
def jgxl(request):
query1 = 'select * from 淘宝数据'
df1 = query_database(query1)
df1 = df1[['价格', '销量']]
# 按价格升序排序
df1 = df1.sort_values(by=['价格'])
# 使用布尔索引选择需要删除的行
rows_to_drop = df1['销量'] < 100
# 使用 drop() 方法删除行
df1 = df1.drop(df1[rows_to_drop].index)
df1_data = [df1['价格'].tolist(), df1['销量'].tolist()]
return render(request, 'jgxl.html', locals())
# ARIMA 时序预测模型 【销量预测】
@login_required
def predict(request):
def arima_model_train_eval(history):
# 构造 ARIMA 模型
model = ARIMA(history, order=(1, 1, 1))
# 基于历史数据训练
model_fit = model.fit()
# 预测接下来的3个时间步的值
output = model_fit.forecast(steps=3)
yhat = output
return yhat
query1 = 'select * from 预测数据'
df = query_database(query1)
df = df[['名称', '2022/10月销量', '2022/11月销量', '2022/12月销量', '2023/01月销量', '2023/02月销量', '2023/03月销量']]
df = df.groupby('名称').sum()
df = df.reset_index()
print(df)
year_data = ['2022/10月销量', '2022/11月销量', '2022/12月销量', '2023/01月销量', '2023/02月销量', '2023/03月销量', '2023/04月销量',
'2023/05月销量', '2023/06月销量']
data = df.iloc[:, 1:].values.tolist()
bingxiang = data[0] + arima_model_train_eval(data[0]).tolist()
xiyiji = data[1] + arima_model_train_eval(data[1]).tolist()
dianshi = data[2] + arima_model_train_eval(data[2]).tolist()
return render(request, 'predict.html', locals())
🍅✌感兴趣的可以先收藏起来,点赞关注不迷路,想学习更多项目可以查看主页,大家在毕设选题,项目代码以及论文编写等相关问题都可以给我留言咨询,希望可以帮助同学们顺利毕业!🍅✌
5、源码获取方式
🍅由于篇幅限制,获取完整文章或源码、代做项目的,拉到文章底部即可看到个人联系方式。🍅
点赞、收藏、关注,不迷路,下方查看👇🏻获取联系方式👇🏻


















 6145
6145

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









