




本文为个人学习笔记整理,仅供交流参考,非专业教学资料,内容请自行甄别。
概述
在Kafka的客户端中,无论是消费者还是生产者,都有很多的参数,无论是通过Properties去put,还是整合Spring Boot在配置文件中配置,都需要对重要的参数进行理解。
一、生产者消息缓存机制
Kafka的设计,本来就是应对高吞吐量的场景,所以为了提高效率,消息是不会一条一条地往服务器发的,而是类似于Redis的pipeline和MySQL的批量操作的思想,引入了生产者消息缓存机制
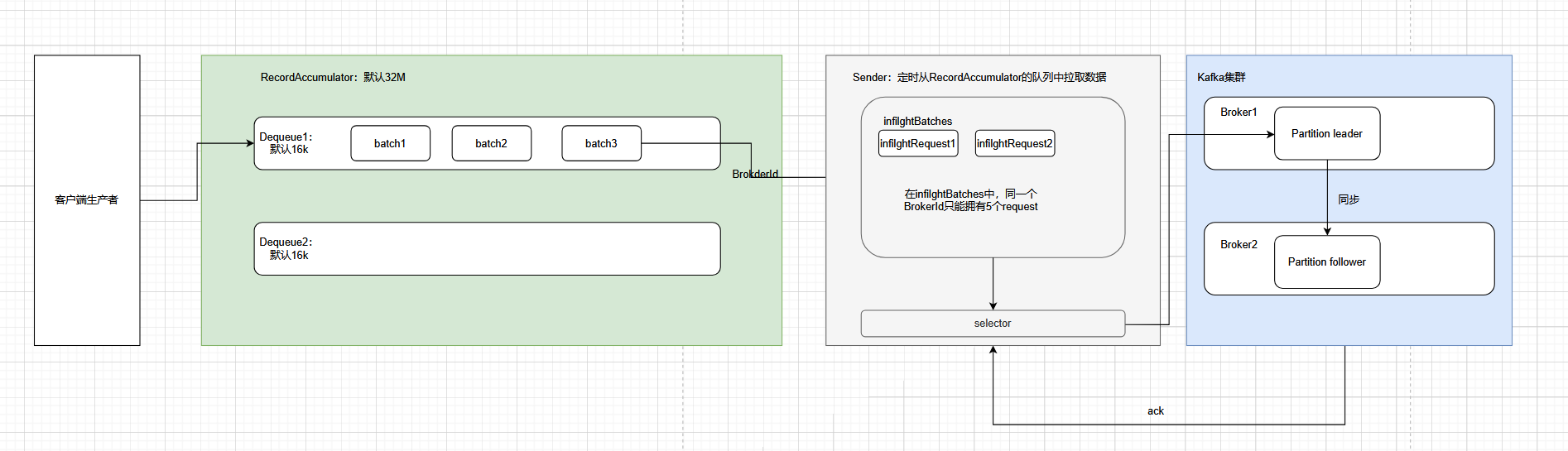
在生产者消息缓存机制中,有两个重要的组件:RecordAccumulator和Sender,前者是作为队列,将消息累计成MemoryRecords发送到服务器。

后者是真正将MemoryRecords中的消息发送到服务器的执行者。

在RecordAccumulator中会针对每一个Partition维护一个Dequeue,每个队列中存储的是 ProducerBatch(批量消息单元),而非单条消息。

Sender是一个独立的后台线程,负责从RecordAccumulator中拉取满足条件的ProducerBatch,批量发送到服务器。
整体的工作流程:
- 生产者调用
send方法发送消息。 - 消息写入
RecordAccumulator中,首先根据其中的Partitioner分区器组件,判断该条消息应该放在哪一个Topic-Partition对应的队列中,并且尝试将消息写入当前队列的最后一个ProducerBatch。如果当前Batch剩余空间不足,则创建新的ProducerBatch,在写入消息。 - 消息并非直接发送,而是当满足以下的条件时,触发发送条件:
- Batch 大小达到阈值
- 等待时间达到阈值
- 生产者调用 flush() 方法(强制刷新缓存)
- 缓存总内存达到上限,需释放内存。
- 后台Sender线程批量发送(底层通过NIO)
- 缓存清理和回调
- 如果服务器ACK返回成功,则释放该
ProducerBatch的缓存,触发Callback回调 通知业务线程 “发送成功”; - 如果服务器NACK返回失败,则根据重试配置决定是否重试,重试失败则触发
Callback通知 “发送失败”。
- 如果服务器ACK返回成功,则释放该
其中涉及到的参数:BUFFER_MEMORY_CONFIG代表了RecordAccumulator缓冲区的大小,默认是32M。

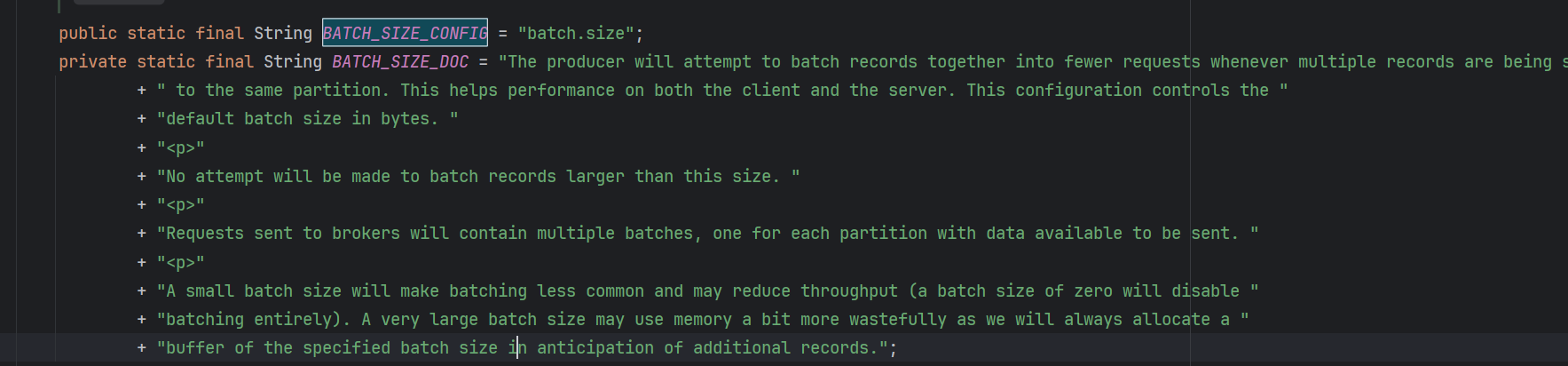
以及BATCH_SIZE_CONFIG代表了RecordAccumulator中每一个batch的大小,默认16k。
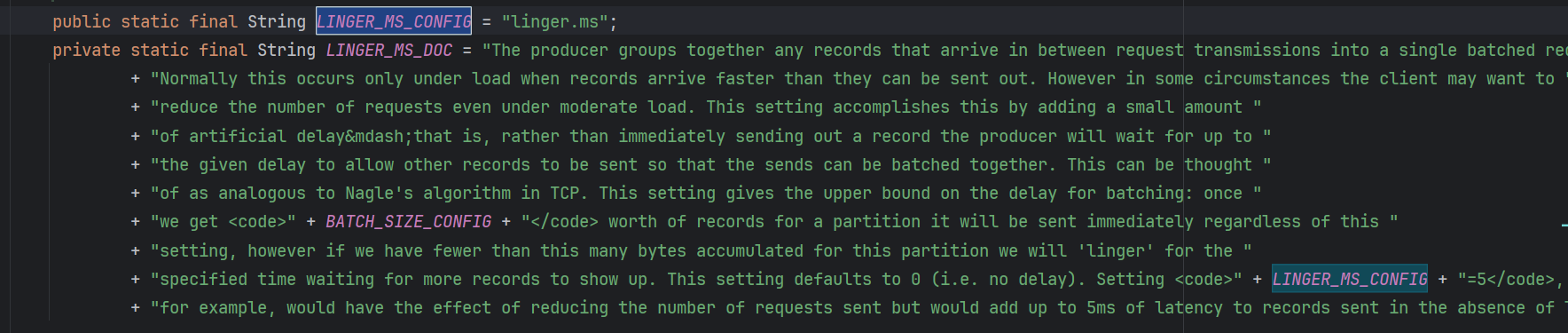
Sender会在batch中的消息达到最大长度后去发送,但是如果batch中的消息一直都没能放满呢?那么就会在达到超时时间LINGER_MS_CONFIG后进行发送,防止某个batch的消息一直无法发出。
基于此可以有一些优化策略,但是总体思想是基于尽可能地将消息批量发送,以减少网络 I/O 次数,但同时要避免为了凑批次而引入不可接受的延迟。
- 吞吐量优先,需要将
batch.size,linger.ms,buffer.memory调大。batch.size增大,可以让同一批次发送更多的消息。linger.ms适当增大,可以让同一批次的队列有时间填满消息。buffer.memory增大,是为了防止batch.size增大后造成的生产者阻塞或者超时。
- 追求低延迟,需要将
batch.size减少或保持默认,linger.ms减小,buffer.memory默认即可batch.size减小,队列可以尽快被占满,进行消息发送。linger.ms减小,则发送的频次增大。buffer.memory默认,因为每个批次的数据都能被及时发送,基本不会有缓冲区被占满的场景。
二、发送应答机制
这里的应答机制,不是类似于Rabbit MQ的消费者到交换机的确认,而是Kafka服务器给客户端生产者批量发送消息的确认。涉及到的参数是ACKS_CONFIG:
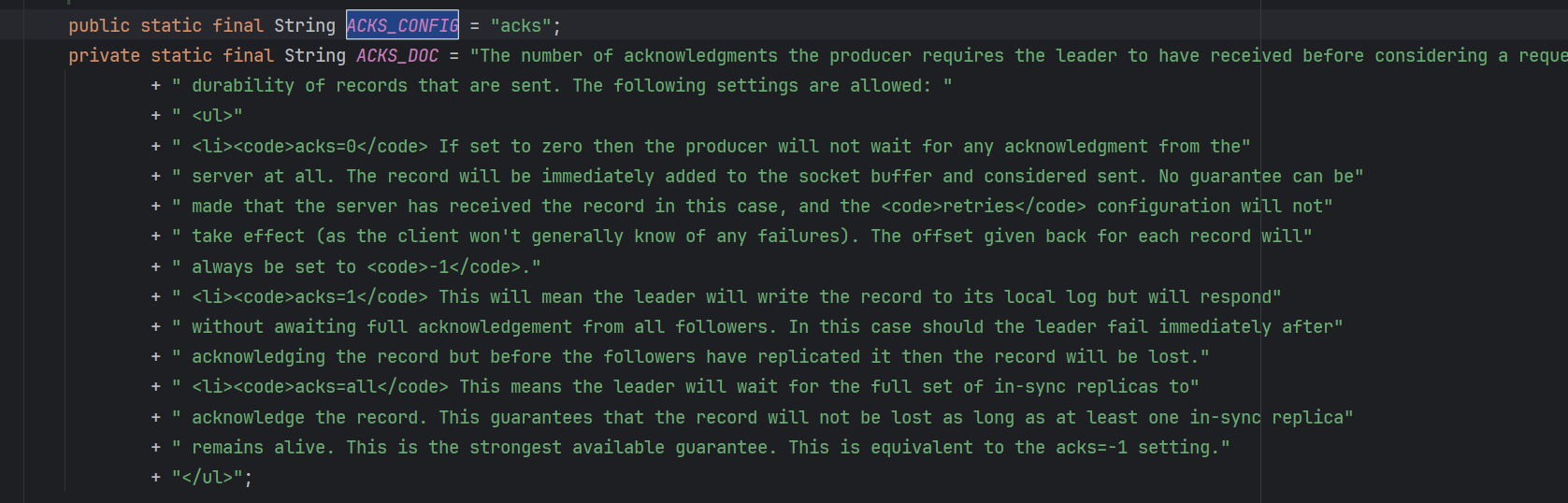
该参数有三个值:
- acks = 0 :生产者的Sender组件发送完成消息之后,不关心Kafka服务器是否将消息正常写入,依旧继续执行自己的功能。这样的效率最高,但是可能会丢数据。
- acks = 1 : 生产者的Sender组件发送完成消息之后,Kafka服务器负责处理消息的
leader Partition节点,确认消息收到并且写入成功后,就返回ack给生产者 - acks = -1 或者 all : 生产者的Sender组件发送完成消息之后,Kafka服务器负责处理消息的
leader Partiton节点及所有从节点,确认消息收到并且写入成功后,再返回ack给生产者,这样的效率不高,但是消息完整性是最高的。
但是当acks = -1 的场景,还可以调整设置,在Kafka服务器的配置中,可以指定min.insync.replicas = n,该参数的含义是,在同一个分区的 ISR 集合中(对于某个特定的 Partition,ISR 集合包含了所有与该 Partition 的 Leader 副本 保持着实时数据同步的副本。这个集合始终包括 Leader 副本本身),有n个节点写入或同步成功,就返回ack给客户端的生产者。
三、生产者消息幂等性
基于上述的ACK机制,可以引出一个关于生产者消息幂等性的问题。既然是Kafka服务器需要给客户端的生产者ACK,那么ACK消息是不是也有可能会丢失,导致生产者重复发送消息?应对这种情况,Kafka在生产者端有关于重试次数的配置,默认是Integer的最大值,也就是可以理解为无限重试。这样明显是不合理的,服务器会保存大量重复的消息,也就最终造成了消费者重复消费的问题。

关于消息幂等性,也有相关的配置:


首先需要补充一个概念,在分布式系统中一致性,有三个语义:
- 至少一次(At-Least-Once):用户转账,系统错误或者有延迟,没有正确给用户返回结果,用户多次点击转账。
- 最多一次(At-Most-Once):银行系统接收到用户重复的转账,但是只能接受一笔,剩下的原路退回。
- 精确一次(Exactly-Once): 用户转账时没有发生系统故障,一次性成功将金额转出到银行系统。
如果需要保证最多一次,那么直接把acks参数调整为0即可。这种情况是不存在消息重试的问题的,因为客户端生产者默认消息全部发送成功。如果需要保证至少一次,那么需要将acks调整为all,-1或者1,但是这样也没有解决幂等性的问题。如果需要支持精确一次,那么就需要开启幂等性的配置。当开启了配置后,为了保证幂等性,Kafka会:
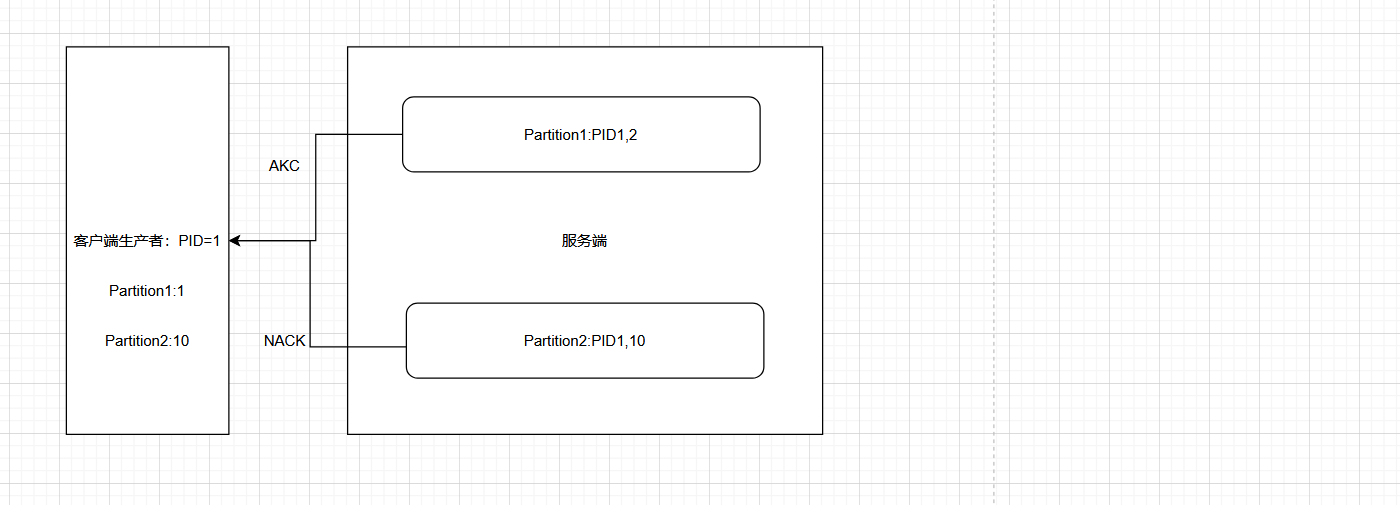
- 每个新的生产者在初始化时,都会分配一个唯一的PID,用户是不可见的。
- 对于该PID,生产者会以
Partition的维度,维护一个序列。如果往相同的Partition发送消息时,该序列值会递增,并且和消息一起发到Kafka服务器。 - Kafka服务器端,也会针对
每个PID和Partition的维度,维护一个序列号。只有当客户端的序列值 = 服务端的序列号 + 1 时,服务端才会接收消息,并且将自己的序列号 + 1。否则就认为是重复发送。
四、生产者事务消息
上述的幂等性,只能解决生产者消息写入单个Partition的情况。如果同一批消息自己指定了key,发送到了多个不同的Partition,并且这些Partition位于不同的服务器上,如何同时保证消息的幂等性?这就是类似于分布式事务的问题了。
补充:为何这种场景无法使用幂等性配置。
假设我消费者A,同一批消息:第一条消息发送到了分区一,第二条消息发送到了分区二。因为幂等性的配置,是单生产者 + 单分区的场景下的,也就是对「同一 PID + 同一 Partition」,只接受序列号递增的消息。Broker 无法判断这两批消息是 “同一批业务相关消息”
那么对于多分区的场景,各个分区只能在自己的范围内保证消息的幂等性,而无法全局保证。就相当于订单服务和库存服务,都使用本地事务,则只能控制自己服务内发生异常情况的回滚,而做不到全局回滚。所以幂等性可以理解为单体项目的事务控制(@Transcational),事务消息可以理解为微服务项目的分布式事务。(seata的@GlobalTranscational)
涉及到几个生产者的api:
// 1 初始化事务
void initTransactions();
// 2 开启事务
void beginTransaction() throws ProducerFencedException;
// 3 提交事务
void commitTransaction() throws ProducerFencedException;
// 4 放弃事务(类似于回滚事务的操作)
void abortTransaction() throws ProducerFencedException;
但是无论是事务消息,还是幂等性判断,都是只能保证客户端生产者发送消息的可靠性,并不能保证消费者是否从Kafka服务器接收到该条消息,就如同Rabbit MQ 生产者也无法直接知道消费者是否成功消费该条消息一样。
总结
生产者消息缓存机制
生产者消息幂等性

















 892
892

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









