






1.1 入门
张量:张量表示一个由数值组成的数组,这个数组可能有多个维度。 具有一个轴的张量对应数学上的向量(vector); 具有两个轴的张量对应数学上的矩阵(matrix); 具有两个轴以上的张量没有特殊的数学名称。
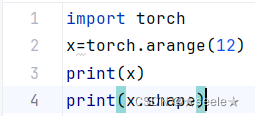
我们可以通过arange创建一个有12个元素的行向量:
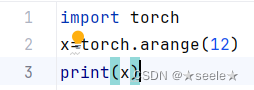
结果:
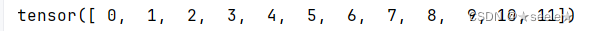
可以通过张量的shape属性来访问张量(沿每个轴的长度)的形状:
结果:
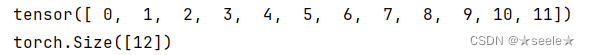
可以通过numel查看张量中的元素总数:
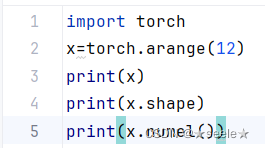
结果:
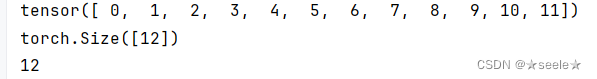
可以通过reshape函数改变一个张量的形状而不改变里面的元素:

结果:
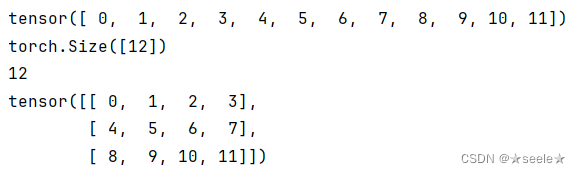
其中reshape(-1,4) ,reshape(3,-1)
和reshape(3,4) 都能得到相同的结果。这是因为在知道该张量的高度或宽度的其中之一后,另外一个会通过'-1'被自动计算得出。
全零、全一和全随机数阵:
 结果 :
结果 :

这个随机数阵从是标准正态分布中随机采样得到的。
1.2 运算
张量的四则运算:
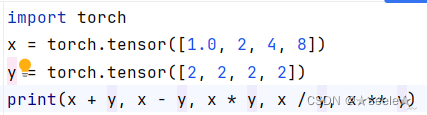
结果:
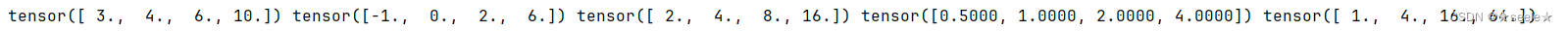
张量的连接:

结果:
 1.3 广播机制
1.3 广播机制
广播机制(Broadcast)是一种允许对不同形状的张量执行逐元素操作的机制,而无需显式地复制数据。这一机制使得编写代码更加简洁和高效。广播机制遵循一定的规则来扩展较小的张量,使其与较大的张量具有相同的形状,从而能够执行逐元素操作,如加减乘除等。
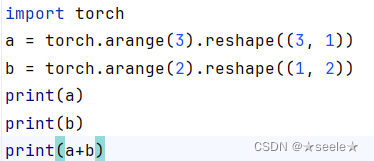
结果:

可以发现,形状不同的两个张量仍然能相加,对于张量a, 第一列被复制粘贴到了第二列,形成了3行2列的张量,而对于张量b,第一行被复制粘贴到了第二行和第三行,同样形成了3行2列的张量,然后他们再相加便得到结果。
1.4 索引和切片
首先要明白一个概念,我们所认为的第一行第一列和计算机所认为的第一行第一列是不一样的,因为计算机是从0开始计数的。除此之外,还有一些元素访问方式。如下图:
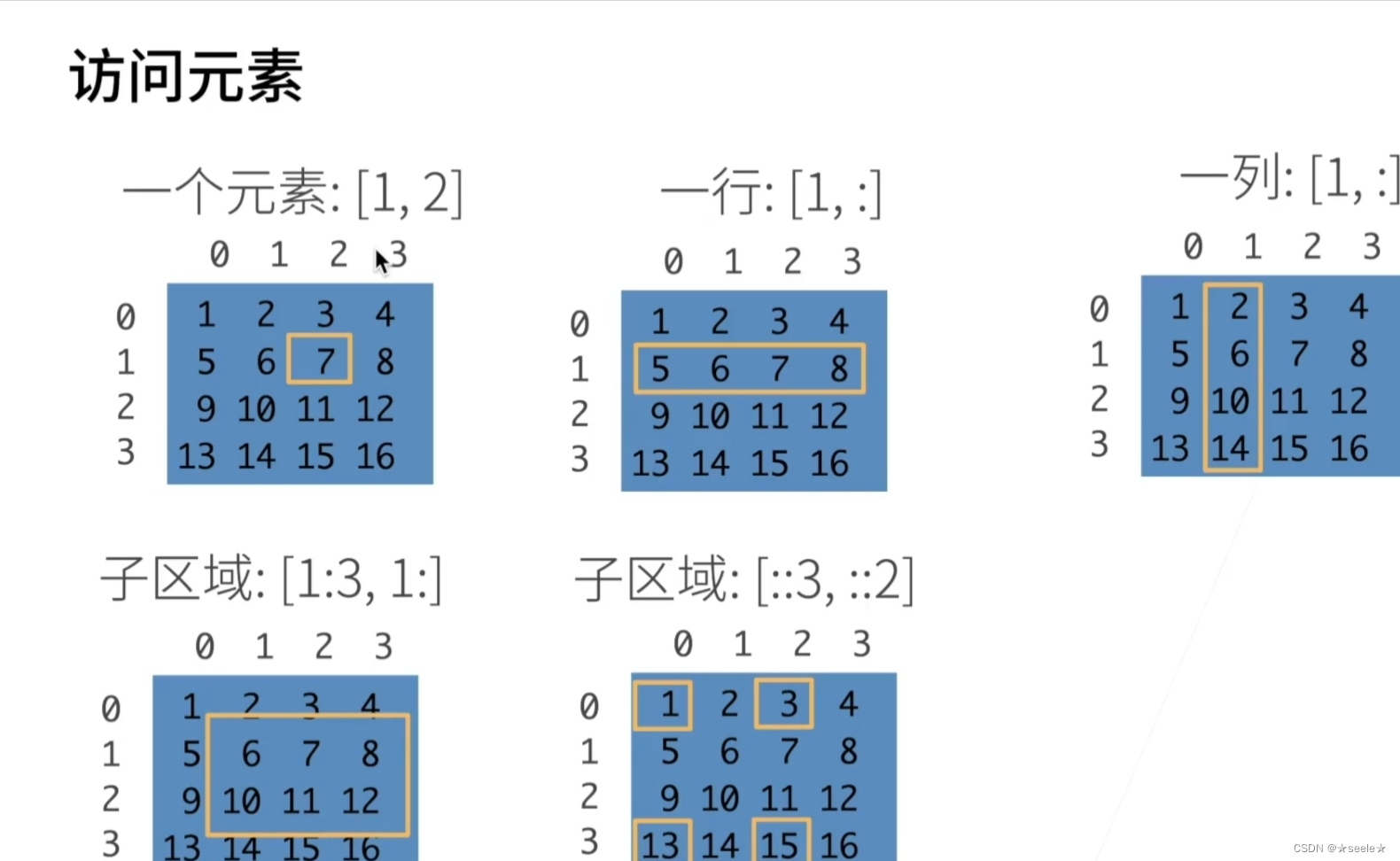
明白之后我们便可以对元素进行选中与赋值。
1.5 数据预处理
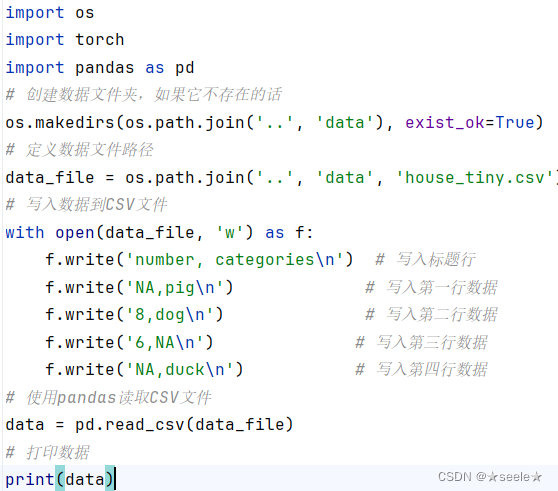
这段代码首先创建了一个名为`house_tiny.csv`的CSV文件,并在其中写入了一些数据。然后使用pandas库读取这个CSV文件,并打印出来,其中NA代表缺失值。
结果:

可以通过位置索引iloc,将data分成inputs和outputs, 其中前者为data的前两列,而后者为data的最后一列。 对于inputs中缺少的数值,我们用同一列的均值替换“NaN”项。
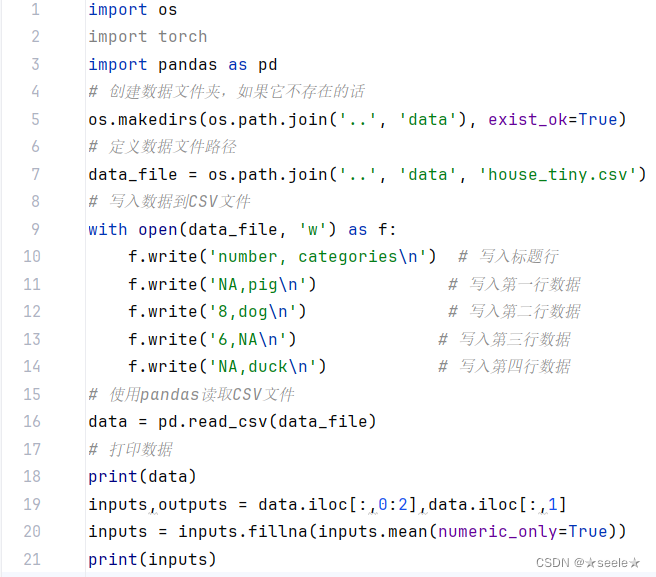
结果:
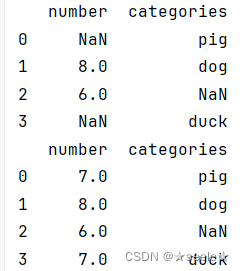
可见,第一列的缺失值已经补齐,且补的值为补齐前这一列元素的平均值。
1.6 张量算法的基本性质
从按元素操作的定义中可以注意到,任何按元素的一元运算都不会改变其操作数的形状。 同样,给定具有相同形状的任意两个张量,任何按元素二元运算的结果都将是相同形状的张量。
例如,将两个相同形状的矩阵相加,会在这两个矩阵上执行元素加法。两个矩阵的按元素乘法称为Hadamard积(Hadamard product)(数学符号⊙)。将张量乘以或加上一个标量不会改变张量的形状,其中张量的每个元素都将与标量相加或相乘。
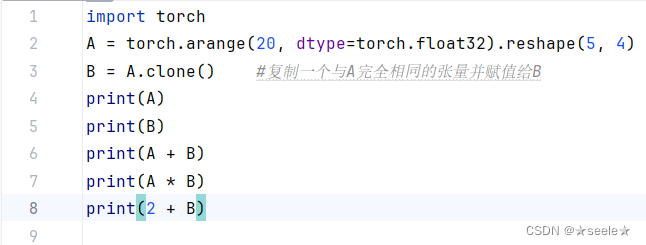
结果:

1.7 求和
我们可以对任意张量进行的一个有用的操作是计算其元素的和。 数学表示法使用符号∑表示求和。 为了表示长度为的向量中元素的总和,可以记为。在代码中可以调用计算求和的函数sum()。

结果:

默认情况下,调用求和函数会沿所有的轴降低张量的维度,使它变为一个标量。 我们还可以指定张量沿哪一个轴来通过求和降低维度。 以矩阵为例,为了通过求和所有行的元素来降维(轴1),可以在调用函数时指定axis=1。 由于输入矩阵沿1轴降维以生成输出向量,因此输入轴1的维数在输出形状中消失。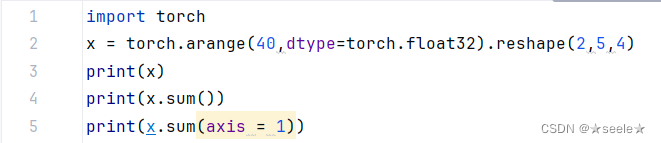
结果:
 一个与求和相关的量是平均值(mean或average)。 我们通过将总和除以元素总数来计算平均值。 在代码中,我们可以调用函数来计算任意形状张量的平均值。
一个与求和相关的量是平均值(mean或average)。 我们通过将总和除以元素总数来计算平均值。 在代码中,我们可以调用函数来计算任意形状张量的平均值。
结果:
 同样,计算平均值的函数也可以沿指定轴降低张量的维度。
同样,计算平均值的函数也可以沿指定轴降低张量的维度。
结果:

如果我们想沿某个轴计算A元素的累积总和, 比如axis=0(按行计算),可以调用cumsum函数。 此函数不会沿任何轴降低输入张量的维度。
结果:
 1.8 矩阵–向量积和矩阵–矩阵乘法
1.8 矩阵–向量积和矩阵–矩阵乘法
在代码中使用张量表示矩阵-向量积,我们使用mv函数。 当我们为矩阵A和向量x调用torch.mv(A, x)时,会执行矩阵-向量积。 注意,A的列维数(沿轴1的长度)必须与x的维数(其长度)相同。

结果:
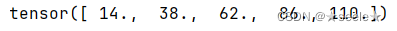 在下面的代码中,我们在A和B上执行矩阵乘法。 这里的A是一个5行4列的矩阵,B是一个4行3列的矩阵。 两者相乘后,我们得到了一个5行3列的矩阵。
在下面的代码中,我们在A和B上执行矩阵乘法。 这里的A是一个5行4列的矩阵,B是一个4行3列的矩阵。 两者相乘后,我们得到了一个5行3列的矩阵。

结果:

矩阵-矩阵乘法可以简单地称为矩阵乘法,不要与“Hadamard积”混淆。















 1016
1016

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









