



当我们使用 Redis 的主从模式时,就需要保证主节点与从节点之间的数据一致性,这时就需要使用主从复制,即将主节点中的数据同步给从节点一份。
复制过程
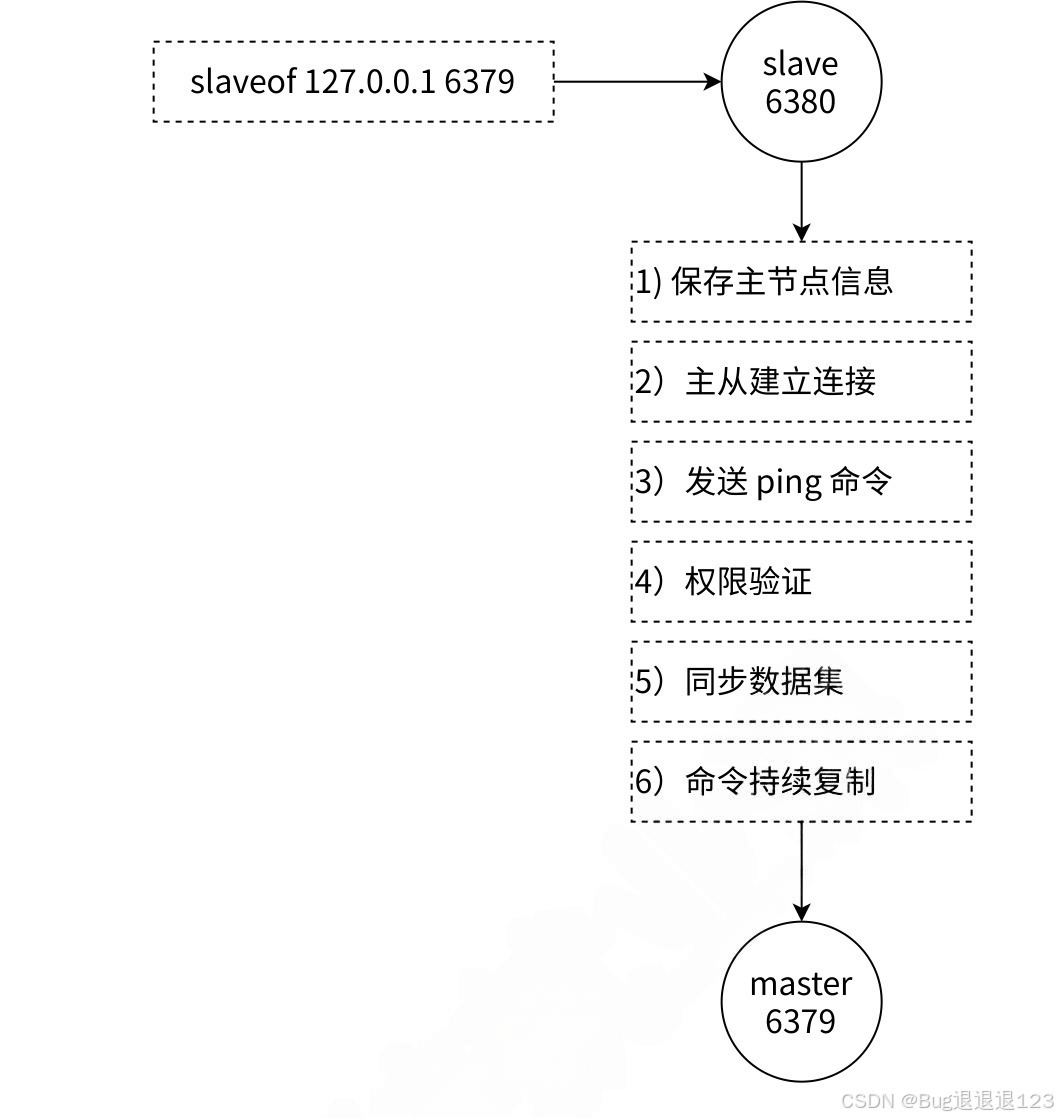
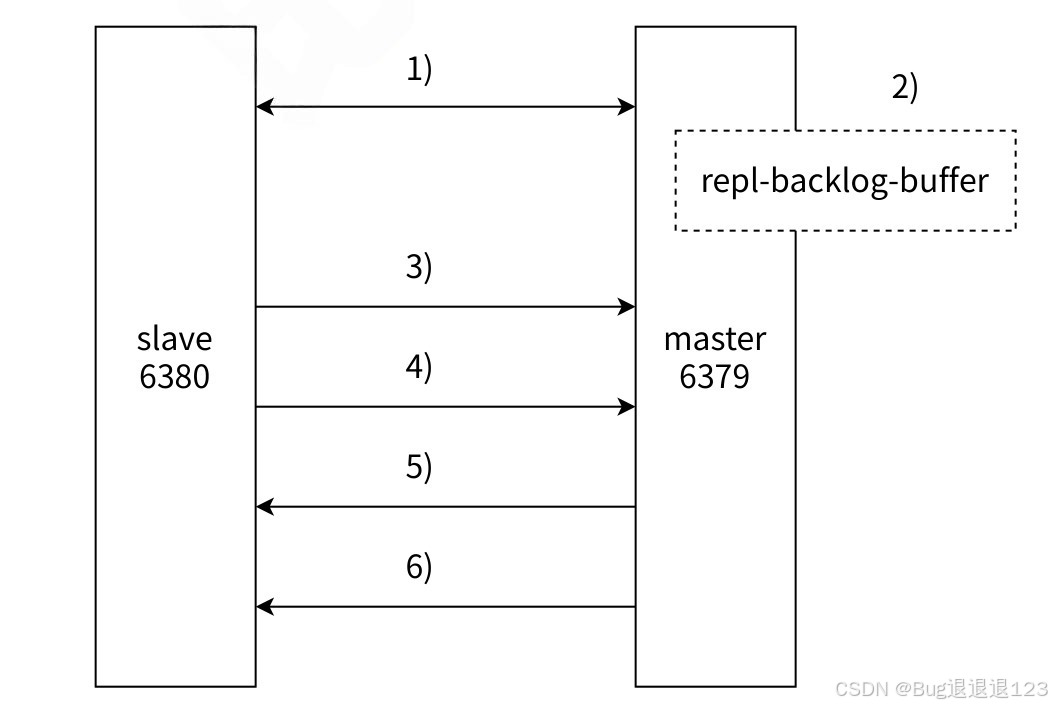
如上图所示,6379 为主节点,6380 为从节点。
- 当我们配置完主从关系后,从节点后先保存主节点的 ip 和 端口号
- 接下来从节点会尝试与主节点建立 TCP 连接,即三次握手,保证从节点与主节点之间是否能传输数据
- 连接建立完成后,从节点会向主节点发送 ping 命令,若主机点返回 pong,就表示主节点能够正常工作;若主节点没有返回 pong,从节点就会断开连接,等待下次重新建立连接
- 如果主节点设置了 requirepass 参数,则需要密码验证,从节点通过配置 masterauth 参数来设置密码。如果验证失败,则从节点的复制将会停⽌。
- 当从节点与主节点建立连接后,会将主节点中的数据同步一份,保证主节点与从节点之间的数据一致性,这里的同步分为全量同步和部分同步
- 后续主节点会收到修改数据的操作,就需要将修改操作实时同步给从节点,从而保证主节点与从节点之间的数据一致性、
PSYNC 命令
当主从关系建立完成后,从节点主动执行 PSYNC 命令,以同步主节点中的数据,命令格式如下:
PSYNC replicationid offset
replicationid / replid
主节点每次启动时,都会生成一个 replicationid,并且每次启动时生成的 replicationid 都不一样。
主从关系建立完成后,从节点会获取到其主节点的 replicationid,并且在每次进行主从复制时,都会带上这个 replicationid,表示要从哪个主节点获取数据。
通过下面这个命令可以获取到 replicationid:
info replication
获取到的数据如下:
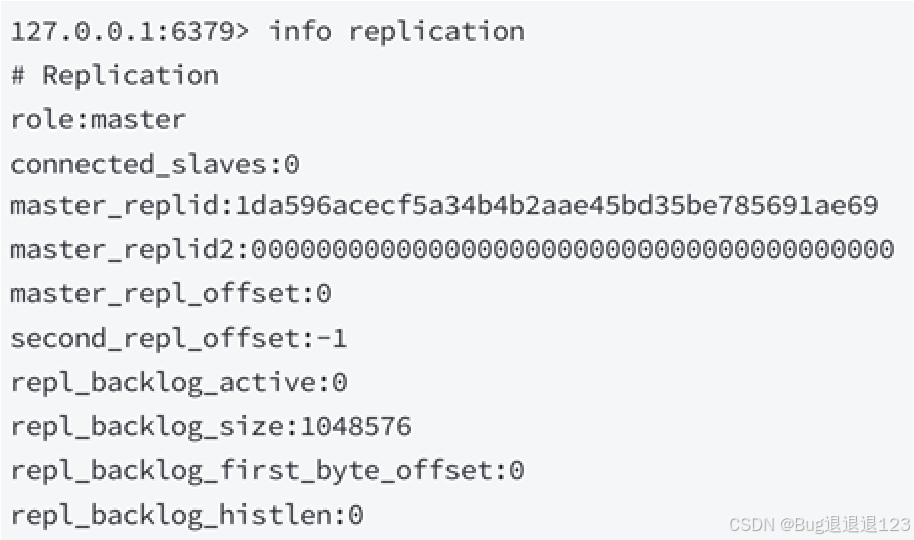
我们可以看到,有两个 replid
- master_replid 表示当前主节点的 replicationid
- master_replid2 表示在从节点与主节点的通信过程中发生网络抖动,此时从节点就会认为主节点宕机了,此时从节点就会成为主节点,也就会生成一个 replid,同时将之前主节点的 replid 保存在 master_replid2 中,这样当网络稳定后,从节点就会根据 master_replid2 找到之前的主节点,继而保持原来的主从关系(需要手动干预,哨兵机制可以自动完成)
offset
offset 表示偏移量,主节点与从节点都会维护这个变量。
- 主节点的 offset:主节点会收到很多的修改数据的操作,每个操作都会占若干字节,主节点会将这些命令的字节数相加,结果即为 offset
- 从节点的 offset:从节点在同步主节点数据的过程中,offset 表示当前同步数据的位置
当主节点的 offset 和从节点的 offset 一致时,就表示从节点已经同步完主节点的数据,二者的数据就是一致的。
当两个从节点的 replid 和 offset 都是一致时,表示二者保存的数据就是相同的。
当 offset 为 -1 时,表示的就是全量复制,当 offset 大于 0 时,表示的是部分复制。
PSYNC 执行流程
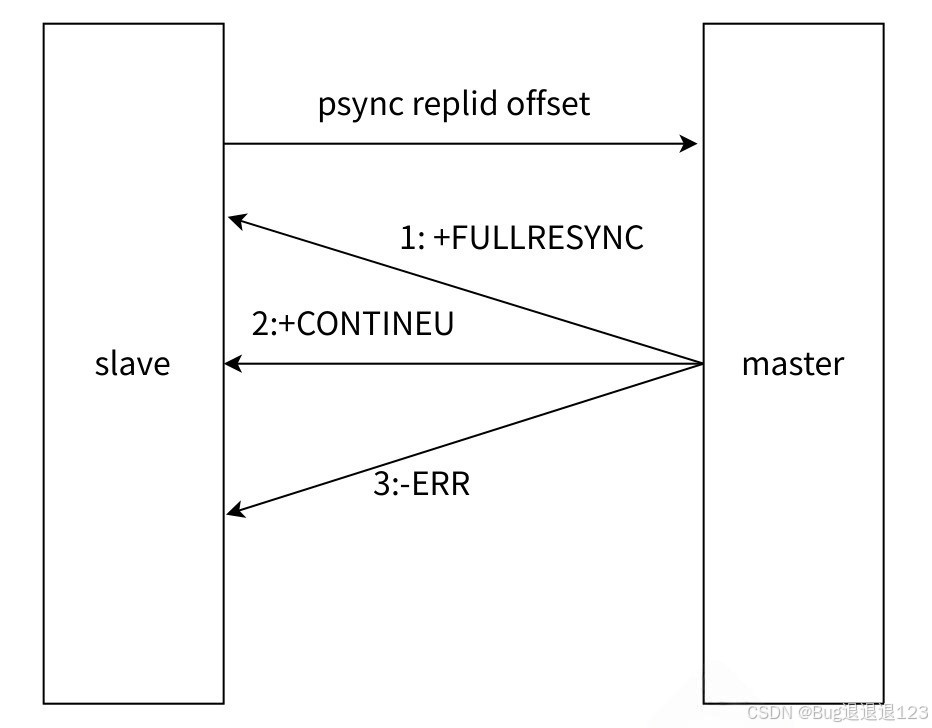
当从节点给主节点发送 PSYNC replicationid offset 命令时,主节点就会根据 offset 判断进行全量复制还是增量复制。
- + FULLRESYNC:表示全量复制
- + CONTINEU:表示增量复制
- - ERR:表示当前 Redis 版本不支持 PSYNC 命令,可以使用 SYNC 代替。SYNC 会阻塞 Redis 服务的其他请求,PSYNC 不会阻塞
全量复制
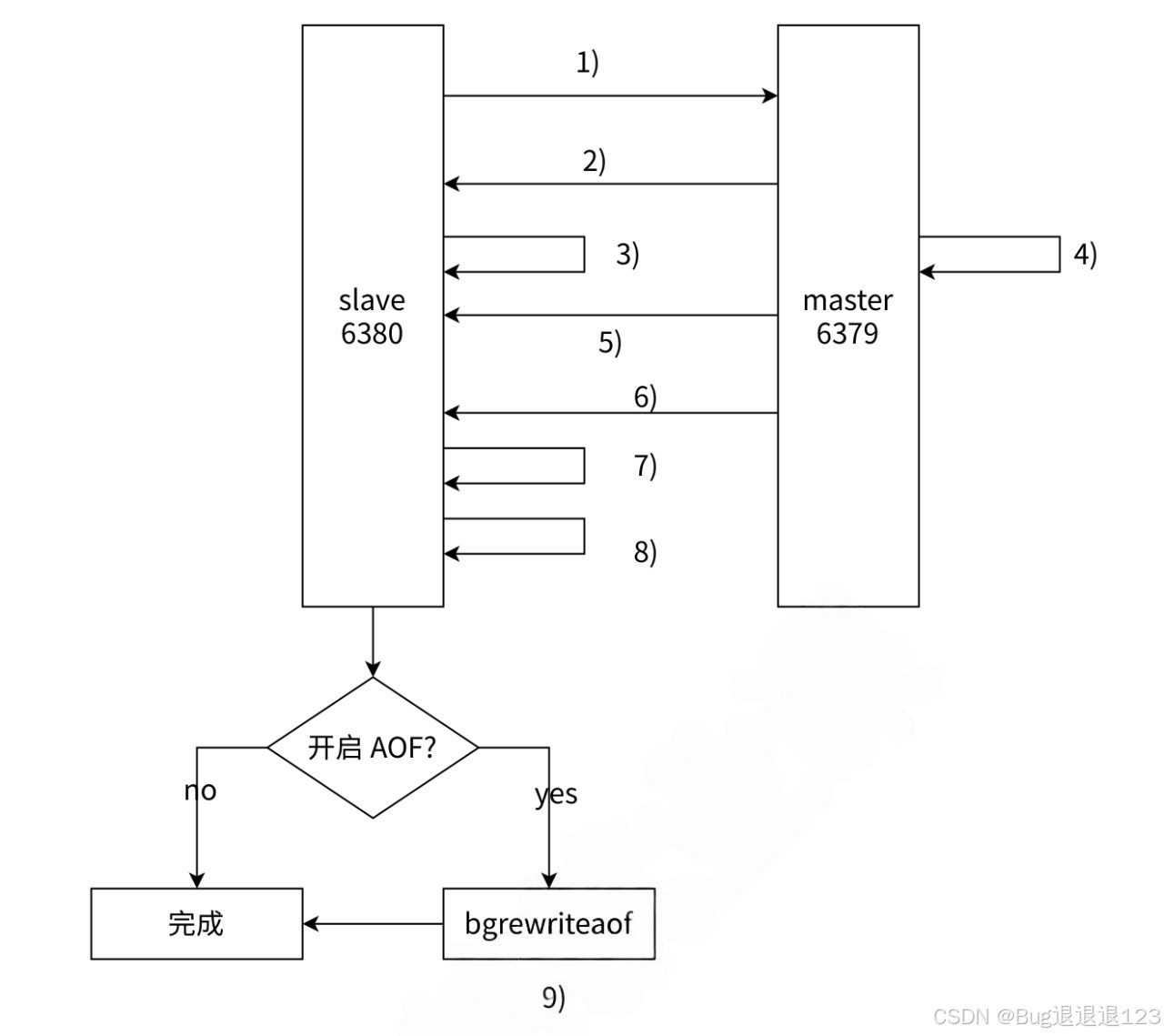
- 从节点给主节点发送同步数据的指令,由于是第一次同步,此时从节点没有主节点的 replid 和 offset ,就会发送 PSYNC ? -1,-1 即表示进行全量复制
- 主节点接收到 PSYNC 指令后,由于是全量复制,就会返回 + FULLRESYNC 响应
- 从节点保存主节点的 replid 等信息
- 主节点执行 BGSAVE,生成一份 RDB 文件,将数据保存至 RDB 文件中。此处没有生成 AOF 文件,是因为 RDB 文件是二进制的,在进行网络传输时消耗的带宽较少,更节省资源
- 主节点将 RDB 文件传输给从节点,从节点将 RDB 文件保存至硬盘中
- 由于主节点在生成 RDB 文件的同时,可能会有修改数据的请求,那么此时就需要将新修改的数据写入缓冲区中,然后主节点将缓冲区中的数据传给从节点,从节点将新收到的数据追加到 RDB 文件中,从而保存主从一致性
- 从节点清空自身原有的数据
- 从节点加载 RDB 文件中的数据,保持主节点与从节点的数据一致性
- 若从节点开启了 AOF,那么在加载数据的过程中,就会产生很多 AOF 日志,会包含冗余信息,这是就需要执行 bgrewriteaof,对 AOF 文件进行整理
在上面的执行过程中,存在可以优化的地方:
在主节点生成 RDB 文件时,这个 RDB 文件会保存在硬盘中,并且从节点接收到 RDB 文件时,也会将 RDB 文件保存在硬盘中,这样就多出了一系列读硬盘与写硬盘的操作,会消耗一定的资源。
针对上面的情况,推出了无硬盘模式。主节点生成的 RDB 数据直接通过网络传输至从节点,并且从节点接收到数据后直接加载,这样就省下了一系列读写硬盘的操作。
部分复制
- 当主节点与从节点之间发生网络波动时,若时间超过repl-timeout,主节点就会认为从节点故障并中断连接
- 主节点与从节点连接中断的过程中,依然会接收到修改数据的操作,此时由于不能将数据发送给从节点,主节点就会将命令滞留在复制积压缓冲区中。但是该缓冲区的大小是有限的,当其中保存的数据达到其最大限度时,这时若依然有新的数据,就会将最早的数据进行丢弃,将新数据存入缓冲区中。但是这样一来,就会造成数据丢失。
- 当网络恢复后,主节点与从节点之间会再次建立连接
- 从节点发送 PSYNC replid offset 命令至主节点,请求部分复制
- 然后主节点就根据 offset 判断是全量复制还是部分复制。若 offset 在缓冲区范围内,就进行部分复制,若 offset 超过了 缓冲区,那就证明从节点落下的数据过多,只能进行全量复制
- 主节点将数据发送给从节点,从节点进行数据同步,保持主从数据一致性
应用场景
- 全量复制应用与从节点第一次与主节点建立连接,需要同步全量数据
- 部分复制是全量复制的优化版,由于全量复制一次需要同步的数据较多,对资源的消耗较大,此时就需要部分复制,每次同步的数据较少,对资源的消耗也较少
实时复制
主从节点在建立复制连接后,主节点会把自己收到的修改操作,通过 TCP 长连接的⽅式,源源不断的传输给从节点。从节点就会根据这些请求来同时修改自身的数据,从而保持和主节点数据的一致性.

















 658
658

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









