




目录
上篇:【自学笔记】Redis 快速入门(上篇)_键值存储数据库redis-CSDN博客
二、实战篇
4.基于Set实现点赞功能
需求:
对于点赞功能,同一个用户只能点赞依次,再次点击则取消点赞,且如果当前用户已经点赞,则点赞按钮高亮显示。
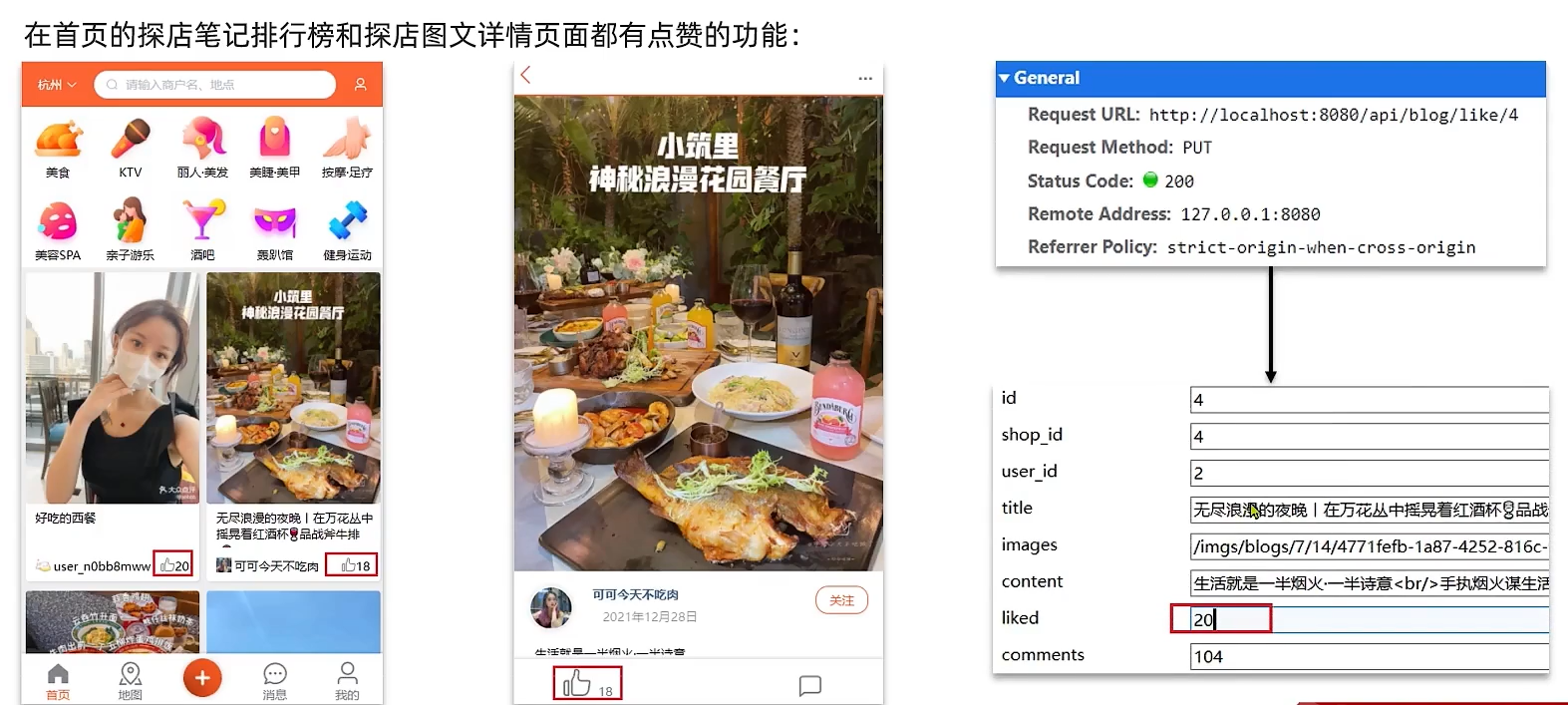
解决方案:
利用Redis的set集合判断是否点赞过,未点赞过则点赞数+1,已点赞过则点赞数-1,对于根据id查询Blog的业务,判断当前登录用户是否点赞过,赋值给isLike字段;对于分页查询Blog业务,判断当前登录用户是否点赞过,赋值给isLike字段
核心代码:
BlogServiceImpl
/**
* 对当前博客点赞
*/
@Override
public Result likeBlog(Long id) {
// 1.获取登录用户
Long userId = UserHolder.getUser().getId();
// 2.判断当前登录用户是否已经点赞
String key = BLOG_LIKED_KEY + id;
Boolean isMember = stringRedisTemplate.opsForSet().isMember(key, userId.toString());
if (score == null) {
//3.如果未点赞,可以点赞
//3.1 数据库点赞数+1
boolean isSuccess = update().setSql("liked=liked+1").eq("id", id).update();
//3.2 保存用户到Redis的set集合
if (isSuccess) {
stringRedisTemplate.opsForSet().add(key, userId.toString(), System.currentTimeMillis());
}
} else {
//4.如果已点赞,取消点赞
//4.1 数据库点赞数-1
boolean isSuccess = update().setSql("liked=liked-1").eq("id", id).update();
//4.2 把用户从Redis的set集合移除
if (isSuccess) {
stringRedisTemplate.opsForSet().remove(key, userId.toString());
}
}
return Result.ok();
}5.基于ZSet实现点赞排行榜
需求:
在探店笔记的详情页面,应该把给该笔记点赞的人显示出来,比如最早点赞的TOP5,形成点赞排行榜
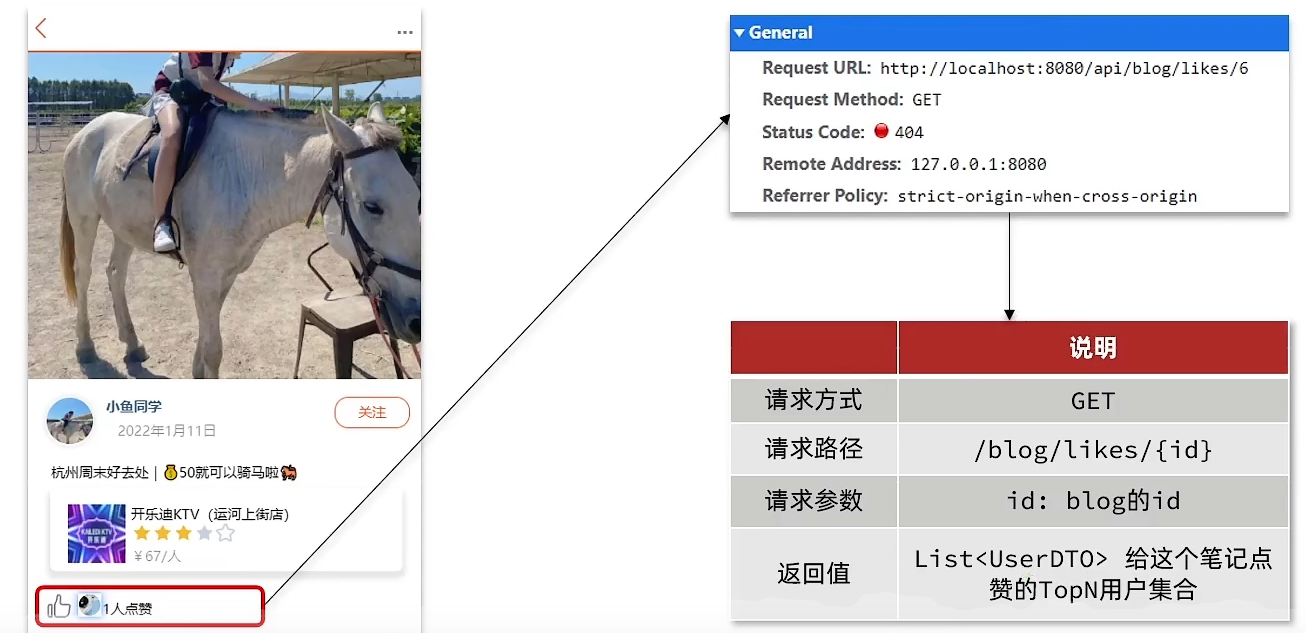
解决方案:
之前的点赞是放到set集合,但是set集合是不能排序的,所以这个时候,咱们可以采用一个可以排序的set集合,就是咱们的sortedSet(即ZSet)
核心代码:
BlogServiceImpl
修改点赞代码逻辑,改为使用ZSet
/**
* 对当前博客点赞
*/
@Override
public Result likeBlog(Long id) {
// 1.获取登录用户
Long userId = UserHolder.getUser().getId();
// 2.判断当前登录用户是否已经点赞
String key = BLOG_LIKED_KEY + id;
// 不仅要保证点赞唯一,还要将点赞先后进行排行
// 获取 Sorted Set(有序集合)中指定成员的分数(score)
Double score = stringRedisTemplate.opsForZSet().score(key, userId.toString());
if (score == null) {
//3.如果未点赞,可以点赞
//3.1 数据库点赞数+1
boolean isSuccess = update().setSql("liked=liked+1").eq("id", id).update();
//3.2 保存用户到Redis的set集合
if (isSuccess) {
stringRedisTemplate.opsForZSet().add(key, userId.toString(), System.currentTimeMillis());
}
} else {
//4.如果已点赞,取消点赞
//4.1 数据库点赞数-1
boolean isSuccess = update().setSql("liked=liked-1").eq("id", id).update();
//4.2 把用户从Redis的set集合移除
if (isSuccess) {
stringRedisTemplate.opsForZSet().remove(key, userId.toString());
}
}
return Result.ok();
}查询对当前博客的点赞用户
/**
* 查询对当前博客的点赞用户
*/
@Override
public Result queryBlogLikes(Long id) {
// 1.查询top5的点赞用户 zrange key 0 4
String key = BLOG_LIKED_KEY + id;
Set<String> top5 = stringRedisTemplate.opsForZSet().range(key, 0, 4);
if (top5 == null || top5.isEmpty()) {
return Result.ok(Collections.emptyList());
}
// 2.解析出其中的用户id
List<Long> ids = top5.stream()
.map(Long::valueOf)
.collect(Collectors.toList());
String idStr = StrUtil.join(",", ids);
// 3.根据用户id查询用户 WHERE id IN ( 5 , 1 ) ORDER BY FIELD(id, 5, 1)
List<User> userList = userService.query()
.in("id", ids)
.last("ORDER BY FIELD(id," + idStr + ")")
.list();
//脱敏
List<UserDTO> userDTOS = userList.stream()
.map(user -> BeanUtil.copyProperties(user, UserDTO.class))
.collect(Collectors.toList());
// 4.返回结果
return Result.ok(userDTOS);
}6.基于Set实现用户共同关注
需求:
点进用户的主页,可以展示出当前用户与博主的共同关注的博主
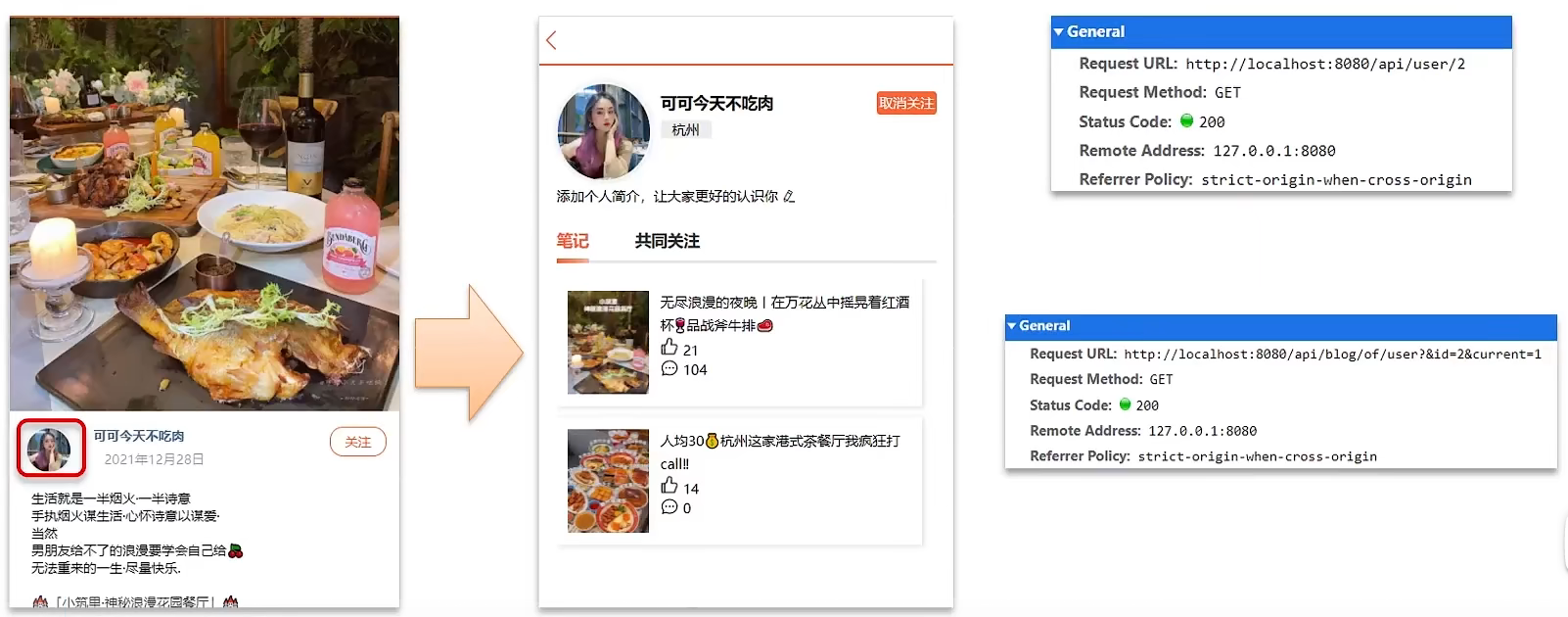
解决方案:
使用Redis的Set结构,在set集合中,有交集并集补集的api,我们可以把两人的关注的人分别放入到一个set集合中,然后再通过api去查看这两个set集合中的交集数据。
核心代码:
FollowServiceImpl
关注/取关用户
/**
* 关注/取关用户
*/
@Override
public Result follow(Long followUserId, Boolean isFollow) {
// 1.获取登录用户
Long userId = UserHolder.getUser().getId();
String key = FOLLOWS_KEY + userId;
// 2.判断到底是关注还是取关
if (isFollow) {
// 2.关注,新增数据
Follow follow = new Follow();
follow.setUserId(userId);
follow.setFollowUserId(followUserId);
boolean isSuccess = save(follow);
if(isSuccess){
// 把关注用户的id,放入redis的set集合
// sadd userId followerUserId
stringRedisTemplate.opsForSet().add(key,followUserId.toString());
}
} else {
// 3.取关,删除数据
// delete from tb_follow where user_id = ? and follow_user_id = ?
boolean isSuccess = remove(new QueryWrapper<Follow>()
.eq("user_id", userId).eq("follow_user_id", followUserId));
if(isSuccess){
// 把关注用户的id从Redis集合中移除
stringRedisTemplate.opsForSet().remove(key,followUserId.toString());
}
}
return Result.ok();
}查看两个用户的关注列表的交集(共同关注)
/**
* 查看两个用户的关注列表的交集
*/
@Override
public Result followCommons(Long id) {
// 1.获取当前用户id
Long userId = UserHolder.getUser().getId();
String key=FOLLOWS_KEY+userId;
String key2=FOLLOWS_KEY+id;
// 2.求交集
//intersect(K key, K otherKey)返回两个集合的交集
Set<String> intersect = stringRedisTemplate.opsForSet().intersect(key, key2);
if(intersect==null||intersect.isEmpty()){
//返回一个不可变的空列表。
return Result.ok(Collections.emptyList());
}
// 3.解析id集合
List<Long> ids = intersect.stream()
.map(Long::valueOf)
.collect(Collectors.toList());
// 4.查询用户
List<UserDTO> userDTOS = userService.listByIds(ids).stream()
.map(user -> BeanUtil.copyProperties(user, UserDTO.class))
.collect(Collectors.toList());
return Result.ok(userDTOS);
}7.基于ZSet实现Feed流
需求:
关注推送也叫做Feed流,直译为投喂,当我们关注了用户后,这个用户发了动态,那么我们应该把这些数据推送给用户,为用户持续的提供“沉浸式”的体验,通过无限下拉刷新获取新的信息。
解决方案:
这里我们不做内容筛选,简单的按照内容发布时间排序,也就是Timeline 模式
该模式有三种实现方案:
1)拉模式:也叫读扩散。如当张三和李四和王五发了消息后,都会保存在自己的邮箱中,假设赵六要读取信息,那么他会从读取他自己的收件箱,此时系统会从他关注的人群中,把他关注人的信息全部都进行拉取,然后在进行排序
2)推模式:也叫做写扩散。推模式是没有写邮箱的,当张三写了一个内容,此时会主动的把张三写的内容发送到他的粉丝收件箱中去,假设此时李四再来读取,就不用再去临时拉取了
3)推拉结合模式:也叫做读写混合,兼具推和拉两种模式的优点。如果是个普通的人,那么我们采用写扩散的方式,直接把数据写入到他的粉丝中去,因为普通的人他的粉丝关注量比较小,所以这样做没有压力;如果是大V,那么他是直接将数据先写入到一份到发件箱里边去,然后再直接写一份到活跃粉丝收件箱里边去,现在站在收件人这端来看;如果是活跃粉丝,那么大V和普通的人发的都会直接写入到自己收件箱里边来;而如果是普通的粉丝,由于他们上线不是很频繁,所以等他们上线时,再从发件箱里边去拉信息。
衍生问题:
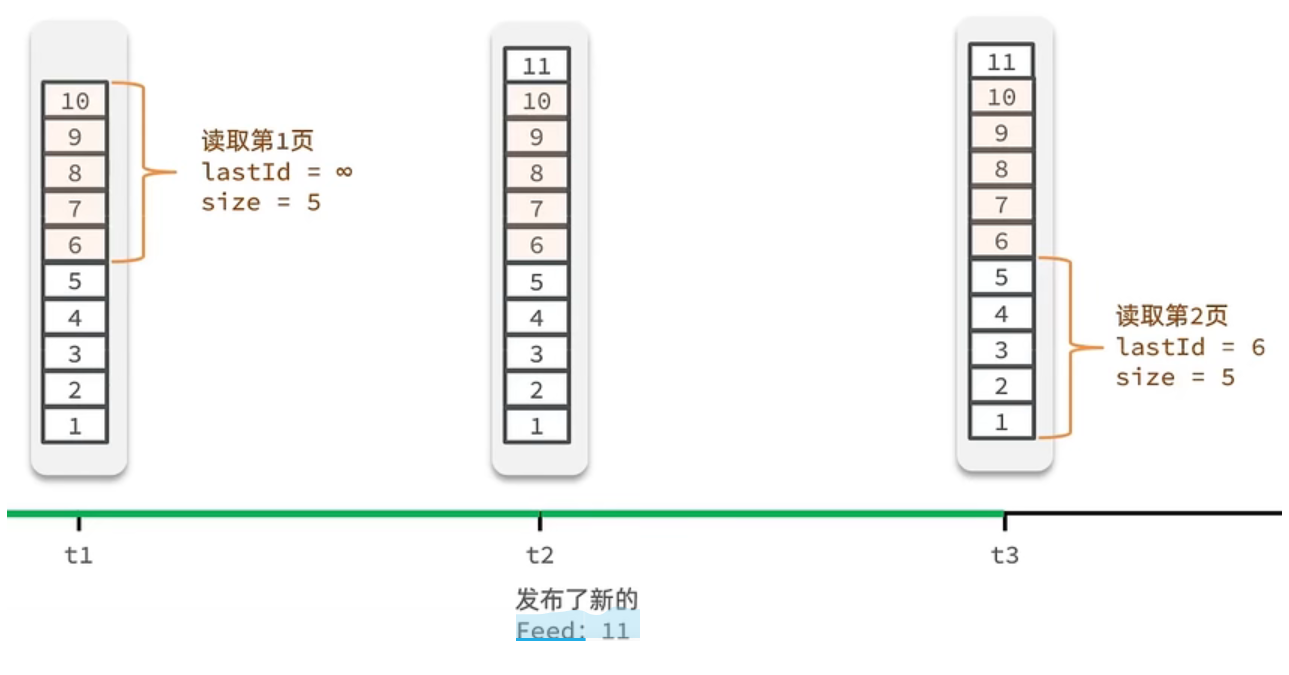
传统了分页在feed流是不适用的,因为我们的数据会随时发生变化
假设在t1 时刻,我们去读取第一页,此时page = 1 ,size = 5 ,那么我们拿到的就是10~6 这几条记录,假设现在t2时候又发布了一条记录,此时t3 时刻,我们来读取第二页,读取第二页传入的参数是page=2 ,size=5 ,那么此时读取到的第二页实际上是从6 开始,然后是6~2 ,那么我们就读取到了重复的数据,所以feed流的分页,不能采用原始方案来做。
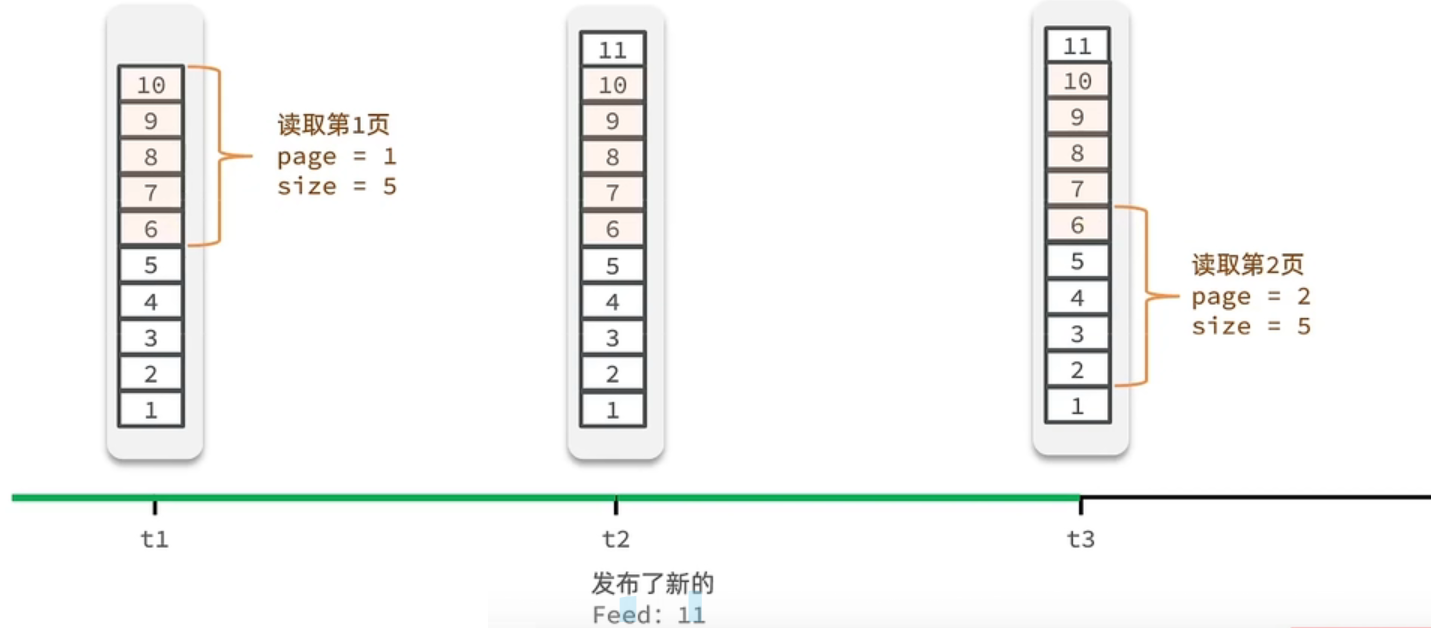
解决方案:
我们需要记录每次操作的最后一条,然后从这个位置开始去读取数据
举个例子:我们从t1时刻开始,拿第一页数据,拿到了10~6,然后记录下当前最后一次拿取的记录,就是6,t2时刻发布了新的记录,此时这个11放到最顶上,但是不会影响我们之前记录的6,此时t3时刻来拿第二页,第二页这个时候拿数据,还是从6后一点的5去拿,就拿到了5-1的记录。我们这个地方可以采用sortedSet来做,可以进行范围查询,并且还可以记录当前获取数据时间戳最小值,就可以实现滚动分页了
核心代码:
BlogServiceImpl
我们在保存完探店笔记后,获得到当前博主的粉丝,然后把数据推送到粉丝的redis中去,发到谁的邮箱,谁就是key,这样才能对他收到的邮件进行按时间排序
/**
* 保存博文
* 同时将博文推送到粉丝的redis中去
*/
@Override
public Result saveBlog(Blog blog) {
// 1.获取登录用户
UserDTO user = UserHolder.getUser();
blog.setUserId(user.getId());
// 2.保存探店笔记
boolean isSuccess = save(blog);
if (!isSuccess) {
return Result.fail("新增笔记失败!");
}
// 3.查询笔记作者的所有粉丝
// select * from tb_follow where follow_user_id = ?
List<Follow> follows = followService.query()
.eq("follow_user_id", user.getId())
.list();
// 4.推送笔记id给所有粉丝
for (Follow follow : follows) {
// 4.1.获取粉丝id
Long userId = follow.getUserId();
// 4.2.推送
// (发到谁的邮箱,谁就是key,这样才能对他收到的邮件进行按时间排序)
String key = FEED_KEY + userId;
stringRedisTemplate.opsForZSet().add(key, blog.getId().toString(), System.currentTimeMillis());
}
// 5.返回id
return Result.ok(blog.getId());
}定义出来具体的返回值实体类
@Data
public class ScrollResult {
private List<?> list;//小于指定时间戳的博客列表
private Long minTime;//最小时间戳,作为下一次查询的条件
private Integer offset;//与上一次查询相同的查询个数作为偏移量
}用户从自己邮箱中取邮件,每次查询完成后,我们要分析出查询出数据的最小时间戳,这个值会作为下一次查询的条件,同时需要找到与上一次查询相同的查询个数作为偏移量,下次查询时,跳过这些查询过的数据,拿到我们需要的数据
/**
* 查看被推送的博客
* (取出已关注的人新发布的博客)
*/
@Override
public Result queryBlogOfFollow(Long max, Integer offset) {
// 1.获取当前用户
Long userId = UserHolder.getUser().getId();
// 2.查询收件箱
// ZREVRANGEBYSCORE key Max Min LIMIT offset count
String key=FEED_KEY+userId;
//reverseRangeByScoreWithScores():按照分数从高到低获取指定分数范围内的元素及其对应的分数。
//参数:有序集合的键名、分数范围的最小值(包含)、分数范围的最大值(包含)、结果集的偏移量(从第几条开始)、 返回结果的数量
Set<ZSetOperations.TypedTuple<String>> typedTuples =
stringRedisTemplate.opsForZSet().reverseRangeByScoreWithScores(key, 0, max, offset, 2);
// 3.非空判断
if(typedTuples==null||typedTuples.isEmpty()){
return Result.ok();
}
// 4.解析数据:blogId、minTime(时间戳)、offset
List<Long> ids = new ArrayList<>(typedTuples.size());
long minTime=0;
int os=1;
for(ZSetOperations.TypedTuple<String> tuple:typedTuples){
// 4.1.获取id
ids.add(Long.valueOf(tuple.getValue()));
// 4.2.获取分数(时间戳)
long time=tuple.getScore().longValue();
if(time == minTime){
os++; // 相同时间戳计数增加
}else{
minTime = time; // 更新最小时间
os = 1; // 重置计数
}
}
os = minTime == max ? os : os + offset;// 计算最终偏移量
// 5.根据id查询blog
String idStr=StrUtil.join(",",ids);
List<Blog> blogs =
query().in("id", ids).last("ORDER.BY FIELD(id," + idStr + ")").list();
for(Blog blog: blogs){
// 5.1.查询blog有关的用户
queryBlogUser(blog);
// 5.2.查询blog是否被当前用户点赞
isBlogLiked(blog);
}
// 6.封装并返回
ScrollResult r=new ScrollResult();
r.setList(blogs); // 博客列表
r.setOffset(os); // 下一次查询的偏移量
r.setMinTime(minTime); // 下一次查询的最大时间戳
return Result.ok(r);
}8.基于GEO实现查看附近商户
需求:
当我们点击美食之后,会出现一系列的商家,商家中可以按照多种排序方式,我们此时关注的是距离,实现按距离远近来推荐附近商户
解决方案:
使用Redis的GEO结构来存储地理坐标信息,帮助我们根据经纬度来检索数据。
常见的命令有:
-
GEOADD:添加一个地理空间信息,包含:经度(longitude)、纬度(latitude)、值(member)
-
GEODIST:计算指定的两个点之间的距离并返回
-
GEOHASH:将指定member的坐标转为hash字符串形式并返回
-
GEOPOS:返回指定member的坐标
-
GEORADIUS:指定圆心、半径,找到该圆内包含的所有member,并按照与圆心之间的距离排序后返回。6.以后已废弃
-
GEOSEARCH:在指定范围内搜索member,并按照与指定点之间的距离排序后返回。范围可以是圆形或矩形。6.2.新功能
-
GEOSEARCHSTORE:与GEOSEARCH功能一致,不过可以把结果存储到一个指定的key。 6.2.新功能
向后台传入当前app收集的地址(我们此处是写死的) ,以当前坐标作为圆心,同时绑定相同的店家类型type,以及分页信息,把这几个条件传入后台,后台查询出对应的数据再返回。
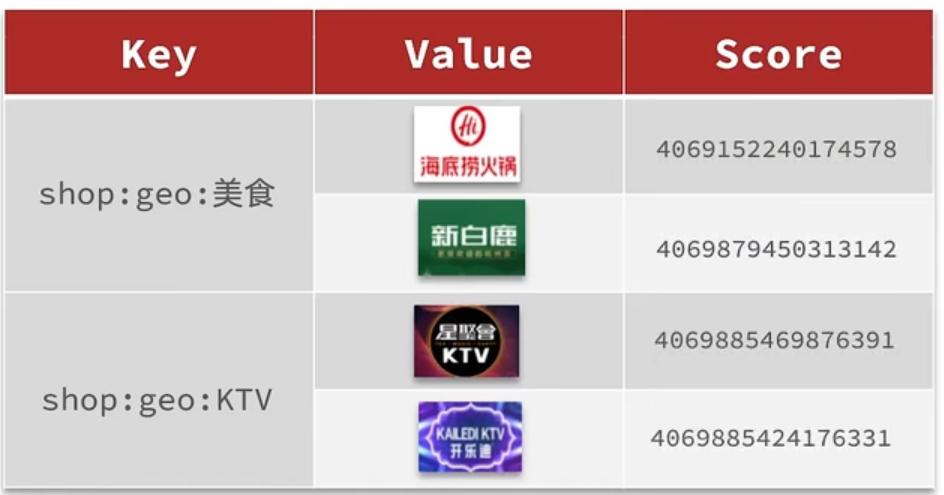
将数据库表中的数据导入到redis中去,GEO在redis中就一个menber和一个经纬度,我们把x和y轴传入到redis做的经纬度位置去,但我们不能把所有的数据都放入到menber中去,毕竟作为redis是一个内存级数据库,如果存海量数据,redis还是力不从心,所以我们在这个地方存储他的id即可。
但是redis中并没有存储type,所以我们无法根据type来对数据进行筛选,所以我们可以按照商户类型做分组,类型相同的商户作为同一组,以typeId为key存入同一个GEO集合中即可
核心代码:
ShopServiceImpl
跟据类型和坐标分页查询商户
/**
* 跟据类型和坐标分页查询商户
*/
@Override
public Result queryShopByType(Integer typeId, Integer current, Double x, Double y) {
// 1.判断是否需要根据坐标查询
if (x == null || y == null) {
// 不需要坐标查询,按类型id查询
Page<Shop> page = query()
.eq("type_id", typeId)
.page(new Page<>(current, SystemConstants.DEFAULT_PAGE_SIZE));
return Result.ok(page.getRecords());
}
// 2.计算分页参数
int from = (current - 1) * SystemConstants.DEFAULT_PAGE_SIZE;//跳过的元素数量(偏移量)
int end = current * SystemConstants.DEFAULT_PAGE_SIZE;//要获取的元素数量上限
// 3.查询redis、按照距离排序、分页。结果:shopId、distance
String key = SHOP_GEO_KEY + typeId;
GeoResults<RedisGeoCommands.GeoLocation<String>> results =
stringRedisTemplate.opsForGeo().search(
key,
GeoReference.fromCoordinate(x, y),// 以用户位置为中心
new Distance(5000),// 搜索半径5公里
RedisGeoCommands.GeoRadiusCommandArgs.newGeoSearchArgs()
.includeDistance()// 包含距离信息
.limit(end)// 获取前end个结果
);
// 4.解析出id
if (results == null) {
return Result.ok(Collections.emptyList());
}
List<GeoResult<RedisGeoCommands.GeoLocation<String>>> list = results.getContent();
// 检查是否还有数据可获取
if (list.size() <= from) {
// 没有下一页了,结束
return Result.ok(Collections.emptyList());
}
// 4.1.截取 from ~ end的部分
List<Long> ids = new ArrayList<>(list.size());
Map<String, Distance> distanceMap = new HashMap<>(list.size());
list.stream().skip(from).forEach(result -> {
// 4.2.获取店铺id
String shopIdStr = result.getContent().getName();
ids.add(Long.valueOf(shopIdStr));
// 4.3.获取到每个店铺的距离
Distance distance = result.getDistance();
distanceMap.put(shopIdStr, distance);
});
// 5.根据店铺id查询Shop
String idStr = StrUtil.join(",", ids);
List<Shop> shops = query()
.in("id", idStr)
.last("ORDER BY FIELD(id," + idStr + ")")//确保查询结果顺序与Redis返回的顺序一致
.list();
for (Shop shop : shops) {
shop.setDistance(distanceMap.get(shop.getId().toString()).getValue());
}
// 6.返回
return Result.ok(shops);
}9.基于BitMap实现用户签到统计
需求:
实现用户签到功能和签到统计功能(包括连续签到天数和本月签到天数)
解决方案:
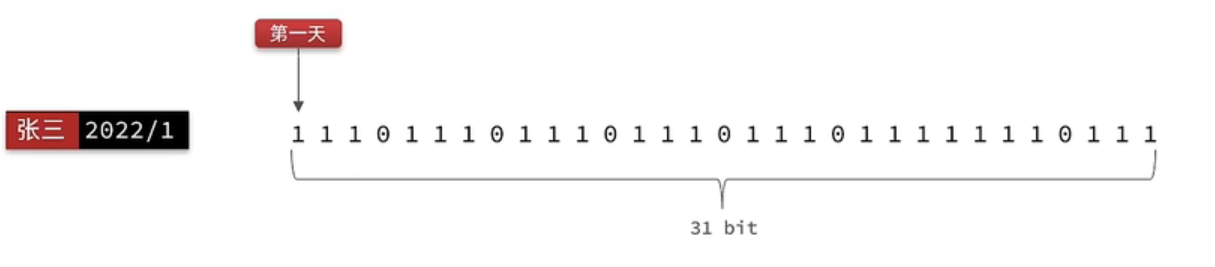
我们按月来统计用户签到信息,签到记录为1,未签到则记录为0,把每一个bit位对应当月的每一天,形成了映射关系。用0和1标示业务状态,这种思路就称为位图(BitMap)。这样我们就用极小的空间,来实现了大量数据的表示
Redis中是利用string类型数据结构实现BitMap,因此最大上限是512M,转换为bit则是 2^32个bit位。允许你将 Redis 的字符串值当作一个巨大的位数组来处理,可以对其中特定位进行置 1 或置 0 的操作
BitMap的操作命令有:
-
SETBIT:向指定位置(offset)存入一个0或1
-
GETBIT :获取指定位置(offset)的bit值
-
BITCOUNT :统计BitMap中值为1的bit位的数量
-
BITFIELD :操作(查询、修改、自增)BitMap中bit数组中的指定位置(offset)的值
-
BITFIELD_RO :获取BitMap中bit数组,并以十进制形式返回
-
BITOP :将多个BitMap的结果做位运算(与 、或、异或)
-
BITPOS :查找bit数组中指定范围内第一个0或1出现的位置
签到功能:我们可以把年和月作为bitMap的key,然后保存到一个bitMap中,每次签到就到对应的位上把数字从0变成1,只要对应是1,就表明说明这一天已经签到了,反之则没有签到。
签到统计功能:
1)连续签到天数:
我们先规定从最后一次签到开始向前统计,直到遇到第一次未签到为止,计算总的签到次数,就是连续签到天数。
Java逻辑代码:获得当前这个月的最后一次签到数据,定义一个计数器,然后不停的向前统计,直到获得第一个非0的数字即可,每得到一个非0的数字计数器+1,直到遍历完所有的数据,就可以获得当前月的签到总天数了
如何从后往前遍历?bitMap返回的数据是10进制,哪假如说返回一个数字8,那么我哪儿知道到底哪些是0,哪些是1呢?我们只需要让得到的10进制数字和1做与运算就可以了,因为1只有遇见1 才是1,其他数字都是0 ,我们把签到结果和1进行与操作,每与一次,就把签到结果向右移动一位,依次内推,我们就能完成逐个遍历的效果了。
2)本月签到天数:
假设今天是10号,那么我们就可以从当前月的第一天开始,获得到当前这一天的位数,是10号,那么就是10位,去拿这段时间的数据,就能拿到所有的数据了,那么这10天里边签到了多少次呢?统计有多少个1即可。(如何统计?跟上面的如何从后往前遍历一样的思路)
核心代码:
UserServiceImpl
本月签到天数
/**
* 统计每月签到
*/
@Override
public Result signCount() {
// 1.获取当前登录用户
Long userId = UserHolder.getUser().getId();
// 2.获取日期
LocalDateTime now = LocalDateTime.now();
// 3.拼接key
String keySuffix = now.format(DateTimeFormatter.ofPattern(":yyyyMM"));
String key = USER_SIGN_KEY + userId + keySuffix;//如:sign:user:1001:202408
// 4.获取今天是本月的第几天
int dayOfMonth = now.getDayOfMonth();
// 5.获取本月截止今天为止的所有的签到记录,返回的是一个十进制的数字
// BITFIELD sign:5:202203 GET u14 0
// bitField() 方法是对 Redis BITFIELD 命令的封装。它允许你在一个 Redis 字符串(位图)上执行多个连续的位操作,这些操作在一次原子命令中完成。
List<Long> result=stringRedisTemplate.opsForValue().bitField(key,
BitFieldSubCommands.create().get(BitFieldSubCommands.BitFieldType.unsigned(dayOfMonth)).valueAt(0));
if(result==null||result.isEmpty()){
// 没有任何签到结果
return Result.ok(0);
}
Long num=result.get(0);
if(num==null||num==0){
return Result.ok(0);
}
// 6.循环遍历
//bitMap返回的数据是10进制,哪假如说返回一个数字8,签到数不一定是8,要看1的个数
int count=0;
while (true){
// 6.1.让这个数字与1做与运算,得到数字的最后一个bit位
if((num&1)==0){
// 如果为0,说明未签到,结束
break;
}else{
// 如果不为0,说明已签到,计数器+1
count++;
}
// 把数字右移一位,抛弃最后一个bit位,继续下一个bit位
num>>>=1;
}
return Result.ok(count);
}这里没写统计连续签到天数。。。不过逻辑已经讲清楚了,大同小异
拓展
关于使用bitmap来解决缓存穿透的方案,也就是布隆过滤器
问题:
发起了一个数据库不存在的,redis里边也不存在的数据,通常你可以把他看成一个攻击
解决方案:
1)判断id<0
2)如果数据库是空,那么就可以直接往redis里边把这个空数据缓存起来
衍生问题:
1)如果用户访问的是id不存在的数据,则此时就无法生效
2)如果是不同的id那就可以防止下次过来直击数据
解决方案:
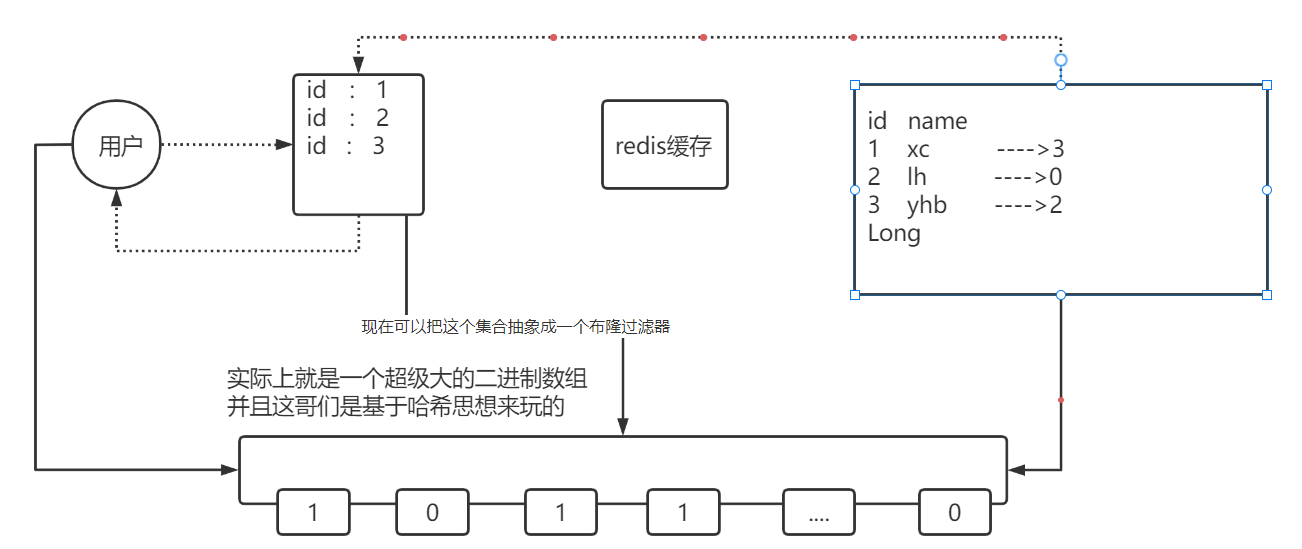
我们可以将数据库的数据,所对应的id写入到一个list集合中,当用户过来访问的时候,我们直接去判断list中是否包含当前的要查询的数据,如果说用户要查询的id数据并不在list集合中,则直接返回,如果list中包含对应查询的id数据,则说明不是一次缓存穿透数据,则直接放行。
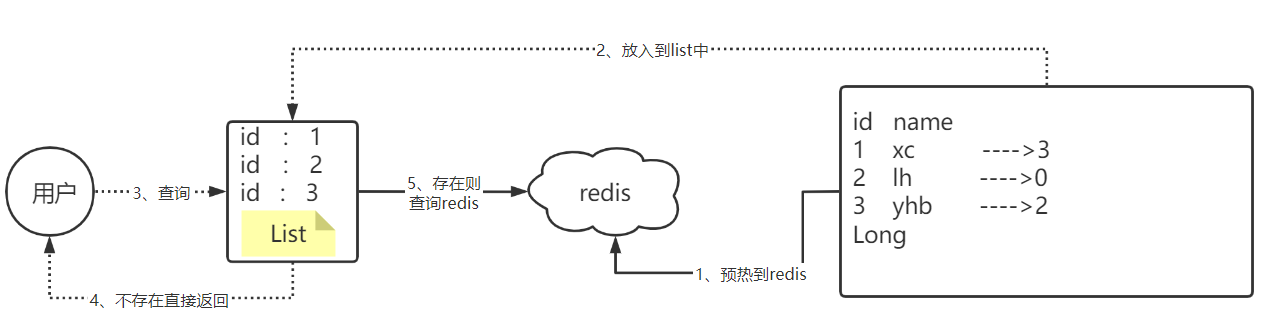
衍生问题:
现在的问题是这个主键其实并没有那么短,而是很长的一个主键,如果采用以上方案,这个list也会很大
解决方案:
我们可以把list数据抽象成一个非常大的bitmap,我们不再使用list,而是将db中的id数据利用哈希思想:(本质就是利用模运算计算出桶的位置,即id对应应该落在哪个桶)
id % bitmap.size = 算出当前这个id对应应该落在bitmap的哪个索引上,然后将这个值从0变成1,然后当用户来查询数据时,此时已经没有了list,让用户用他查询的id去用相同的哈希算法, 算出来当前这个id应当落在bitmap的哪一位,然后判断这一位是0,还是1,如果是0则表明这一位上的数据一定不存在, 采用这种方式来处理,需要重点考虑一个事情,就是误差率,所谓的误差率就是指当发生哈希冲突的时候,产生的误差。
10.UV统计
两个概念:
-
UV:全称Unique Visitor,也叫独立访客量,是指通过互联网访问、浏览这个网页的自然人。1天内同一个用户多次访问该网站,只记录1次。
-
PV:全称Page View,也叫页面访问量或点击量,用户每访问网站的一个页面,记录1次PV,用户多次打开页面,则记录多次PV。往往用来衡量网站的流量。
通常来说UV会比PV大很多,所以衡量同一个网站的访问量,我们需要综合考虑很多因素,所以我们只是单纯的把这两个值作为一个参考值
问题:
UV统计在服务端做会比较麻烦,因为要判断该用户是否已经统计过了,需要将统计过的用户信息保存。但是如果每个访问的用户都保存到Redis中,数据量会非常恐怖
解决方案:
Hyperloglog(HLL)是从Loglog算法派生的概率算法,用于确定非常大的集合的基数,而不需要存储其所有值。相关算法原理大家可以参考:https://juejin.cn/post/6844903785744056333#heading-0
Redis中的HLL是基于string结构实现的,单个HLL的内存永远小于16kb,内存占用低的令人发指!作为代价,其测量结果是概率性的,有小于0.81%的误差。不过对于UV统计来说,这完全可以忽略。
测试:
测试百万数据的统计,我们直接利用单元测试,向HyperLogLog中添加100万条数据,看看内存占用和统计效果如何
@Test
void testHyperLogLog() {
// 准备数组,装用户数据
String[] users = new String[1000];
// 数组角标
int index = 0;
for (int i = 1; i <= 1000000; i++) {
// 赋值
users[index++] = "user_" + i;
// 每1000条发送一次
if (i % 1000 == 0) {
index = 0;
stringRedisTemplate.opsForHyperLogLog().add("hll1", users);
}
}
// 统计数量
Long size = stringRedisTemplate.opsForHyperLogLog().size("hll1");
System.out.println("size = " + size);
}我们会发生他的误差是在允许范围内,并且内存占用极小(偷懒了。。。)
本文到此结束,如果对你有帮助,可以点个赞~
后续会在合集里持续更新 Redis 相关的知识,欢迎关注~


















 10万+
10万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











