






150.逆波兰表达式求值
题目:150. 逆波兰表达式求值 - 力扣(LeetCode)
其实就是后缀表达式,
逆波兰表达式主要有以下两个优点:
-
去掉括号后表达式无歧义,上式即便写成 1 2 + 3 4 + * 也可以依据次序计算出正确结果。
- 适合用栈操作运算:遇到数字则入栈;遇到运算符则取出栈顶两个数字进行计算,并将结果压入栈中
动图理解:
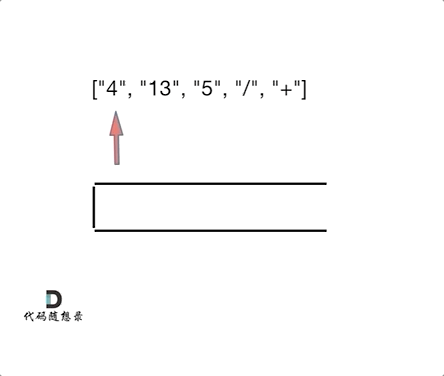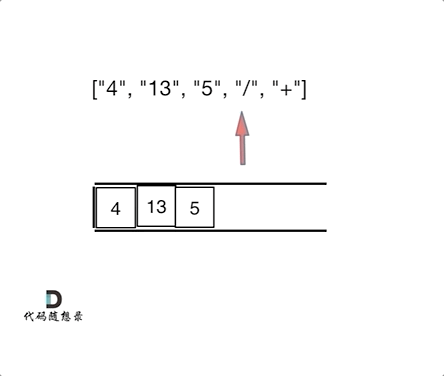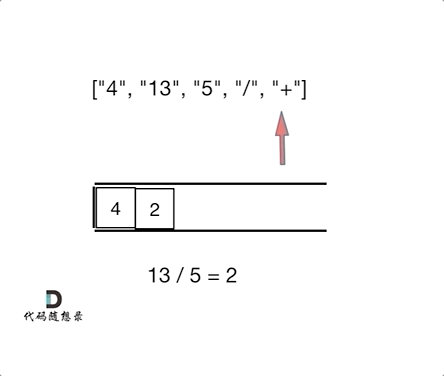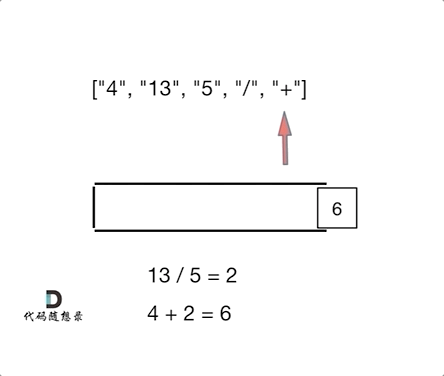
一些犯错的点
在 C++ 中,
"和'的使用有不同的含义:
"用于字符串字面量(string),比如"+"表示一个字符串。'用于字符字面量(char),比如'+'表示一个单一字符。
num1取得是第二个操作数,num2取得是第一个操作数,所以在减法和除法运算是要写清楚运算顺序。
代码
class Solution {
public:
int evalRPN(vector<string>& tokens) {
stack<long long>st;
for(int i=0;i<tokens.size();i++)
{
if(tokens[i]=="+"||tokens[i]=="-"||tokens[i]=="*"||tokens[i]=="/")
{
long long num1=st.top();//如果遇到运算符,就是获取栈顶两个元素,并且弹出来
st.pop();
long long num2=st.top();
st.pop();
if(tokens[i]=="+")st.push(num1+num2);
if(tokens[i]=="-")st.push(num2-num1);
if(tokens[i]=="*")st.push(num1*num2);
if(tokens[i]=="/")st.push(num2/num1);
}
//如果当前 token 不是运算符,而是一个数字,我们需要将它转换为 long long 类型,并将其压入栈中。stoll 是一个函数,用来将字符串转换为长整型(long long)。
else st.push(stoll(tokens[i]));
}
int result=st.top();
st.pop();
return result;
}
};239.滑动窗口最大值
题目:239. 滑动窗口最大值 - 力扣(LeetCode)
给定一个数组 nums,有一个大小为 k 的滑动窗口从数组的最左侧移动到数组的最右侧。你只可以看到在滑动窗口内的 k 个数字。滑动窗口每次只向右移动一位。
返回滑动窗口中的最大值。
单调队列的经典应用。

暴力解法时间复杂度太高了,o(n*k).
本题其实就是要我们自己定义单调队列的功能实现。
就是我们只要维护滑动窗口的最大值就行了,保证最大的元素在出口处。同时队列的元素是从大到小的。
动图理解
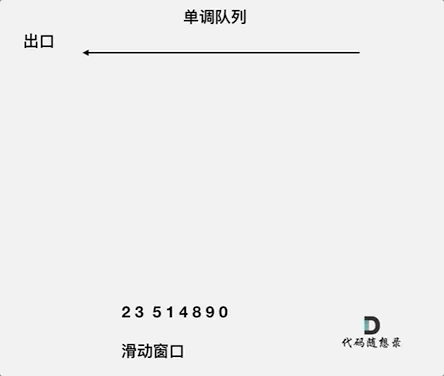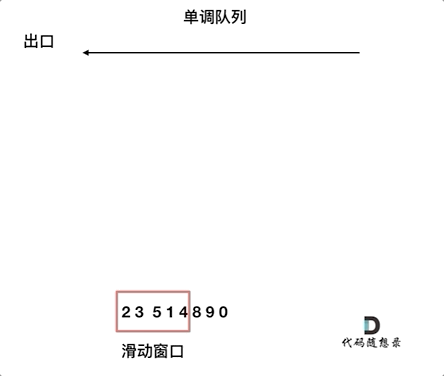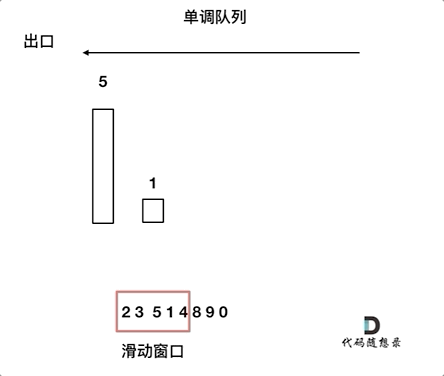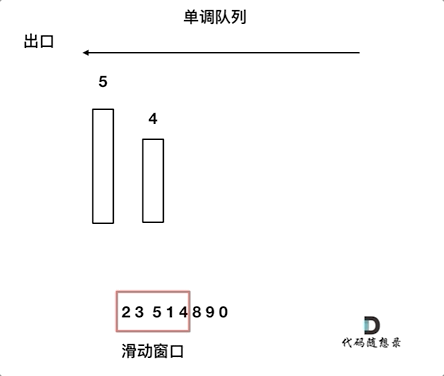
再进一步解释就是,如果当前数组元素(其实就是窗口新的元素)比队列出口的元素大,就pop掉队列的所有元素直到小于队列入口元素,只有比前一个数小的元素才入队列且不用pop元素。
具体pop和push规则如下
- pop(value):如果窗口移除的元素value等于单调队列的出口元素,那么队列弹出元素,否则不用任何操作
- push(value):如果push的元素value大于入口元素的数值,那么就将队列入口的元素弹出,直到push元素的数值小于等于队列入口元素的数值为止
然后每次移动,只要que.front()就可以获取最大元素
动图如下
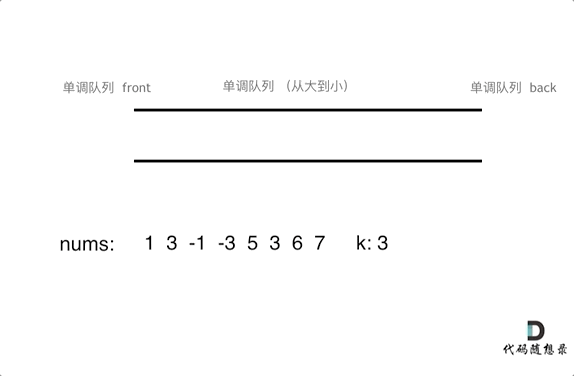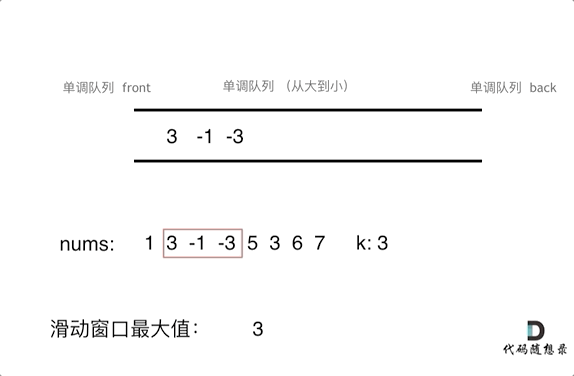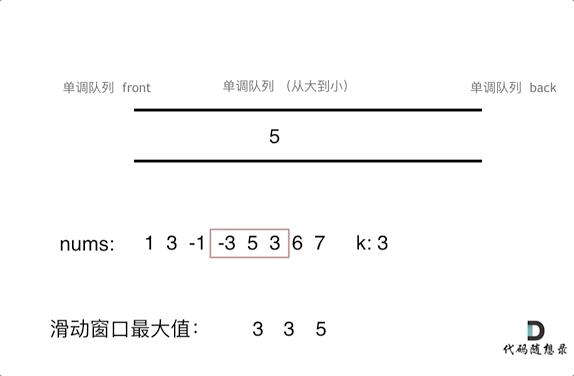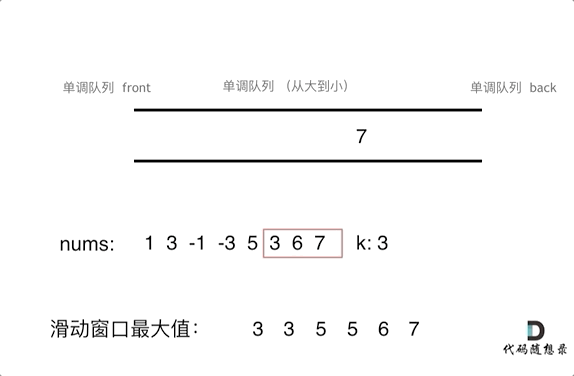
代码
class Solution {
private:
class MyQueue
{
public:
deque<int>que;//使用deque来实现单调队列
void pop(int value)
{
if(!que.empty()&&value==que.front())
que.pop_front();//只有当队列不为空并且队列的前端(front)元素等于当前要移除的值时,才将它从队列中移除。这样可以保证滑动窗口滑动时,窗口外的值被正确移除。
}
void push(int value)
{
while(!que.empty()&&value>que.back())//在插入元素时,首先检查当前元素是否比队列后端的元素更大。如果是,则将队列后端的元素弹出(因为这些较小的元素在未来永远不会再作为窗口的最大值)。然后再把当前元素插入队列末尾。
{
que.pop_back();
}
que.push_back(value);
}
int front()
{
return que.front();
}
};
public:
vector<int> maxSlidingWindow(vector<int>& nums, int k) {
MyQueue que;//注意这是一个类对象!!!
vector<int>result;
for(int i=0;i<k;i++)//先把前k个元素按顺序入栈,并保留最大值在队列出口就行,其实就是定了个k长度的滑动窗口。
{
que.push(nums[i]);//调用push函数
}
//第一次记录出口元素(最大值)
result.push_back(que.front());
for(int i=k;i<nums.size();i++)//开始滑动
{
que.pop(nums[i-k]);//窗口向右滑动一位,移除窗口最前面的元素。这里的 nums[i - k] 表示已经不在窗口中的元素。
que.push(nums[i]);//将新的元素(当前窗口的最后一个元素)插入到队列中,保持队列单调递减。
result.push_back(que.front());//记录最大值
}
return result;
}
};再补充一个比较难理解的点,就是pop函数那里,为什么一定要比较当前要移除的元素是否等于队列开头元素才能移除呢,因为如果是比开头元素小的数,而恰好后面才要把它从窗口移除出去(虽然它不等于队列开头元素),但是,它在push进去的时候恰好已经pop掉了,因为比较小嘛,所以不用维护。
另一种写法,直接用c++的multiset函数。
知识普及:
在 C++ 中,
multiset是一个标准模板库(STL)提供的关联容器,它允许多个相同的元素存储在同一个集合中。与set容器不同的是,multiset不要求存储的元素是唯一的。换句话说,multiset可以存储相同值的多个实例。
multiset的特性:
- 自动排序:
multiset内部自动对元素按升序(默认)排列,或者根据用户提供的比较函数进行排序。- 允许重复元素:
multiset允许插入相同值的多个元素。- 底层实现:
multiset通常由平衡的二叉搜索树(例如红黑树)实现,因此查找、插入和删除的时间复杂度平均为 O(log n)。- 迭代顺序:由于
multiset是有序的,因此迭代时元素会按照升序顺序遍历。常用操作:
- 插入元素:
insert方法可以插入元素,重复的元素也会被存储。- 删除元素:可以使用
erase方法来删除某个元素,或者删除某个范围的元素。- 查找元素:
find、count、lower_bound和upper_bound可以用来查找某个元素或者范围。- 元素个数:
size和empty用于获取multiset中的元素数量和判断是否为空。
class Solution { public: vector<int> maxSlidingWindow(vector<int>& nums, int k) { multiset<int> st; vector<int> ans; for (int i = 0; i < nums.size(); i++) { if (i >= k) st.erase(st.find(nums[i - k])); st.insert(nums[i]); if (i >= k - 1) ans.push_back(*st.rbegin()); } return ans; } };
347.前k个高频数字
题目: 347. 前 K 个高频元素 - 力扣(LeetCode)
给定一个非空的整数数组,返回其中出现频率前 k 高的元素。
示例 1:
- 输入: nums = [1,1,1,2,2,3], k = 2
- 输出: [1,2]
示例 2:
- 输入: nums = [1], k = 1
- 输出: [1]
提示:
- 你可以假设给定的 k 总是合理的,且 1 ≤ k ≤ 数组中不相同的元素的个数。
- 你的算法的时间复杂度必须优于 $O(n \log n)$ , n 是数组的大小。
- 题目数据保证答案唯一,换句话说,数组中前 k 个高频元素的集合是唯一的。
- 你可以按任意顺序返回答案。
本题学会运用优先队列,还有大小顶堆的用法,上一题是自定义队列的运用。
知识补充:
- 优先队列是一个具有优先级的队列,通常通过堆来实现。
- 大小顶堆是实现优先队列的具体数据结构,最大堆保证每个父节点大于或等于子节点,最小堆则相反。
- 堆的底层逻辑依赖于完全二叉树的结构,通过插入和删除操作维护堆的性质,以保证在 O(log n) 时间内访问优先级最高的元素。
思路
- 要统计元素出现频率
- 对频率排序
- 找出前K个高频元素
图解:

所以我们要用小顶堆,因为要统计最大前k个元素,只有小顶堆每次将最小的元素弹出,最后小顶堆里积累的才是前k个最大元素。
代码
class Solution {
public:
class mycoparison{
public:
//operator() 函数比较两个 pair<int, int> 对象(这里的 pair 存储的是元素和它们的频率),使得堆根据频率(第二个元素)进行排序。
//由于 lhs.second > rhs.second,堆中的频率较小的元素会被优先弹出,从而形成小顶堆的特性。
bool operator()(const pair<int,int>& lhs,const pair<int,int>& rhs)
{
return lhs.second>rhs.second;
}
};
vector<int> topKFrequent(vector<int>& nums, int k) {
//1.统计元素出现频率,用哈希表map来存储每个元素即出现频率
unordered_map<int,int>map;
for(int i=0;i<nums.size();i++)
{
map[nums[i]]++;//map<nums[i],元素出现的次数>
}
//2.对频率进行排序
//定义一个小顶堆 pri_que,存储 pair<int, int> 类型的元素(元素及其频率)。使用 mycomparison 作为比较器,使堆按频率从小到大排列。
priority_queue<pair<int,int>,vector<pair<int,int>>,mycoparison> pri_que;
// 遍历频率映射 map,将每个元素及其频率推入小顶堆。
//如果堆的大小超过 k,则弹出堆顶元素(频率最低的元素),保持堆的大小为 k。
//这样在遍历结束时,堆中就只保留了频率最高的 k 个元素。
for(unordered_map<int,int>::iterator it =map.begin();it!=map.end();it++)
{
pri_que.push(*it);
if(pri_que.size()>k)
{
pri_que.pop();
}
}
//3. 找出前K个高频元素,因为小顶堆先弹出的是最小的,所以倒序来输出到数组
vector<int>result(k);
for(int i=k-1;i>=0;i--)
{
result[i]=pri_que.top().first;
pri_que.pop();
}
return result;
}
};知识盲点进一步解释
这句代码
result[i] = pri_que.top().first;的含义是从小顶堆中获取频率最高的元素,并将其存储到结果数组result中。1.
pri_que.top()
pri_que是一个小顶堆,存储的是pair<int, int>类型的元素,每个pair中包含两个整数:
first:表示元素的值。second:表示该元素的频率。调用
pri_que.top()返回堆顶元素,也就是当前频率最低的元素(在小顶堆中,堆顶总是频率最小的元素)。2.
.first
top()方法返回的是一个pair<int, int>,因此我们可以通过.first访问这个pair的第一个元素,即元素的值(而不是频率)。
总结,后面两题尤其倒数第二题好难了,耗费了一下午的时间,还逐字逐句弄懂每一行的意思。写完收工!!















 958
958

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









