




🌸个人主页:https://blog.csdn.net/2301_80050796?spm=1000.2115.3001.5343
🏵️热门专栏:
🧊 Java基本语法(97平均质量分)https://blog.csdn.net/2301_80050796/category_12615970.html?spm=1001.2014.3001.5482
🍕 Collection与数据结构 (92平均质量分)https://blog.csdn.net/2301_80050796/category_12621348.html?spm=1001.2014.3001.5482
🧀线程与网络(96平均质量分) https://blog.csdn.net/2301_80050796/category_12643370.html?spm=1001.2014.3001.5482
🍭MySql数据库(93平均质量分)https://blog.csdn.net/2301_80050796/category_12629890.html?spm=1001.2014.3001.5482
🍬算法(97平均质量分)https://blog.csdn.net/2301_80050796/category_12676091.html?spm=1001.2014.3001.5482
🍃 Spring(97平均质量分)https://blog.csdn.net/2301_80050796/category_12724152.html?spm=1001.2014.3001.5482
🎃Redis(97平均质量分)https://blog.csdn.net/2301_80050796/category_12777129.html?spm=1001.2014.3001.5482
🐰RabbitMQ(97平均质量分) https://blog.csdn.net/2301_80050796/category_12792900.html?spm=1001.2014.3001.5482
感谢点赞与关注~~~

目录
1. 为何要使用Redis作为缓存
我们知道,Redis最主要的用途主要有三个方面,首先就是存储数据,也就是把它当做一种内存数据库,其次是缓存,这是Redis最常用的一种场景,然后就是消息队列,不过我们一般不使用Redis作为消息队列,市面上有很多现成的消息队列中间件,比Redis好用的多.
我们为什么要使用Redis作为缓存呢?
首先我们需要知道在计算机中,访问数据的速度CPU寄存器>内存>硬盘>网络,速度快的设备可以作为速度慢的设备的缓存.我们最常见的就是内存作为硬盘的缓存(这也是Redis的定位).当然我们前面也曾经谈到过,硬盘也可以作为网络的缓存.当访问到某个网站上的数据的时候,浏览器就会从服务器上获取数据并进行展示,如果某些数据的体积较大,变化频率又不是很高的时候,就可以通过网络直接存储数据到本地硬盘,当下一次打开页面的时候,就不必从通过网络从服务器上再次获取数据了.
缓存中存储的数据,一般都是我们经常需要访问的数据,这些数据虽然不多,但是却可以满足绝大部分的查询情况,满足的是二八定律,20%的数据可以应对80%的请求.
我们通常使用Redis作为数据库的缓存(MySQL),但是我们知道,数据库的性能并不是很高:
- 首先数据库是把数据存储在硬盘上的,硬盘的读写速度并不快,尤其是随机访问.
- 其次如果查询不能命中索引的话,就需要对表进行遍历,这就会大大增加硬盘读写的次数.
- 如果是一些复杂的查询,比如联合查询,就需要对表进行笛卡尔积的操作,效率更低.
就是因为MySQL这种关系型数据库效率比较低,所以可以承担的并发量比较有限,一旦请求多了,数据库的压力就会很大,甚至发生宕机.如果想要解决MySQL并发量的问题,我们有两种解决的策略,一种是开源,就是引入更多的机器,构成数据库集群,另一种就是节流,即引入缓存,这就是典型的方案,把一些频繁读取的热点数据,保存到缓存上,后续在查询数据的时候,如果缓存中已经存在了,就可以不再访问MySQL了.Redis也就相当于一个护盾一样,把MySQL给罩住了.

2. 缓存的更新策略
缓存更新是Redis为了节约内存而设计出来的一个东西,主要是因为内存数据宝贵,当我们向Redis插入太多数据,此时就可能导致缓存中的数据过多,所以Redis会对部分数据进行更新,或者把他叫做淘汰更合适.一共有三种方案可选:
- 内存淘汰: Redis自动进行,当Redis内存达到设定的max-Memery的时候,会自动触发淘汰机制,淘汰掉一些不重要的数据(可以自己设置策略方式)
常见的内存淘汰策略有以下几种:- FIFO(first in first out) 先进先出
把缓存中存在时间最久的(先进来的数据)数据淘汰掉. - LRU(least recently used) 淘汰最近未使用的
记录每个key的最近访问时间,把最近访问的时间最早的key淘汰掉. - LFU(least frequently used) 淘汰访问次数最少的
记录每个key最近一段时间的访问次数,把访问次数最少的淘汰掉. - Random 随机淘汰
随机抽取一名幸运儿淘汰掉
- FIFO(first in first out) 先进先出
- 超时剔除: 当我们给Redis设置了过期时间ttl之后,Redis会将超时的数据进行删除,方便继续使用缓存.
- 主动更新: 我们可以手动调用方法把缓存删除掉,通常用于解决缓存和数据库不一致的问题.
2.1 数据库缓存不一致的解决方案
由于我们的缓存的数据来源于数据库,而数据库的数据是会发生变化的,因此,如果当数据库中数据发生变化,而缓存却没有同步,此时就会有一致性问题,其后果是:
用户使用缓存中的过时数据,就会产生类似多线程数据安全问题,怎么解决呢?有如下几种方案
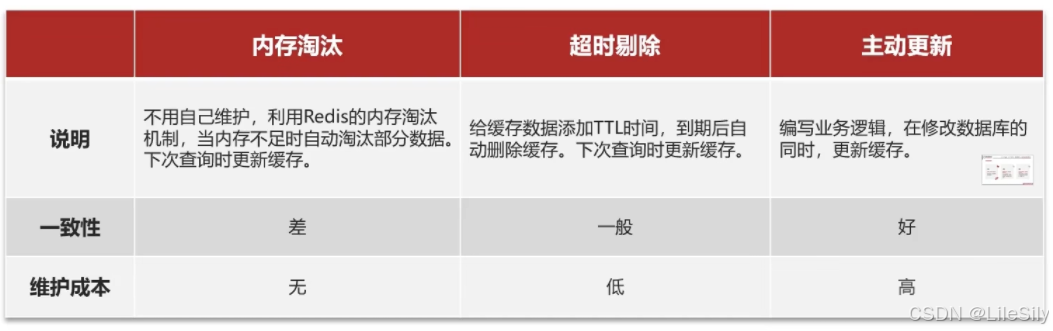
Cache Aside Pattern 人工编码方式:缓存调用者在更新完数据库后再去更新缓存,也称之为双写方案.
Read/Write Through Pattern : 由系统本身完成,数据库与缓存的问题交由系统本身去处理
Write Behind Caching Pattern :调用者只操作缓存,其他线程去异步处理数据库,实现最终一致
最终我们比较这几种方案,我们选择了方案一
- 删除缓存还是更新缓存?
- 更新缓存: 每次更新数据库都更新缓存,如果很少有人来读这个数据,即写多读少的场景,就会造成无效的写操作比较多.
- 删除缓存: 更新数据库的时候让缓存失效,查询的时候再更新缓存,假设我们每次操作数据库后,都操作缓存,但是中间如果没有人查询,那么这个更新动作实际上只有最后一次生效,中间的更新动作意义并不大,我们可以把缓存删除,等待再次查询时,将缓存中的数据加载出来.
- 如何保证缓存与数据库的操作同时成功还是失败?
-
单体系统,将缓存与数据库操作放在一个事务
-
分布式系统,利用TCC等分布式事务方案
应该具体操作缓存还是操作数据库,我们应当是先操作数据库,再删除缓存,原因在于,如果选择第一种方案,在两个线程并发来访问时,假设线程1先来,他先把缓存删了,此时线程2过来,他查询缓存数据并不存在,此时他查询数据库写入缓存,但是此时线程1还没有更新数据库的数据,写入缓存的实际上还是旧数据.
-
删除缓存重试,先删除缓存数据,如果删除失败,则把失败的key放到一个mq中,稍后进行重试.如果删除不成功,就会一直在mq中重试.

-
上述的操作看起来有些复杂,但是有一些大佬把这些操作已经封装好了.我们可以直接使用.
例如阿里巴巴提供了开源工具canal,可以比较方便的获取到mysql的binlog,并基于此实现上述逻辑.
3. 缓存预热,缓存穿透,缓存雪崩,缓存击穿,缓存降级(常考面试题)
3.1 缓存预热
我们上面提到,缓存中更新数据有两种策略,一种是定期生成,一种是实时生成.定期生成不涉及"预热",但是实时生成会涉及到.
Redis服务器在首次接入之后,服务器里是没有任何数据的,此时,所有的请求就都会答到数据库上,如果请求以下子太多,很容易导致数据库服务器宕机.缓存预热就是用来解决上述的问题的,首先通过离线的方式,通过一些统计途径,先把热点数据找到一批,导入到Redis中,此时导入的这批热点数据,就可以帮mysql承担很大的压力了.随着时间的推移,逐渐就会使用新的热点数据淘汰掉旧的热点数据.
3.2 缓存穿透
我们在Redis中查询某个key,在Redis中没有,在mysql中也没有,这个key肯定也不会被更新到Redis中.这次查询没有,下次查还没有,如果像这样的数据存在很多,并且还反复查询,一样会给mysql带来很大的压力.
为什么会有上面的这种情况呢?有以下的几种情况:
- 业务涉及不合理,比如缺少相关参数的校验,导致非法的key也被查询了.
- 开发/运维人员误删数据库上的数据.
- 黑客恶意攻击
那么如何解决上述内存穿透的问题呢?
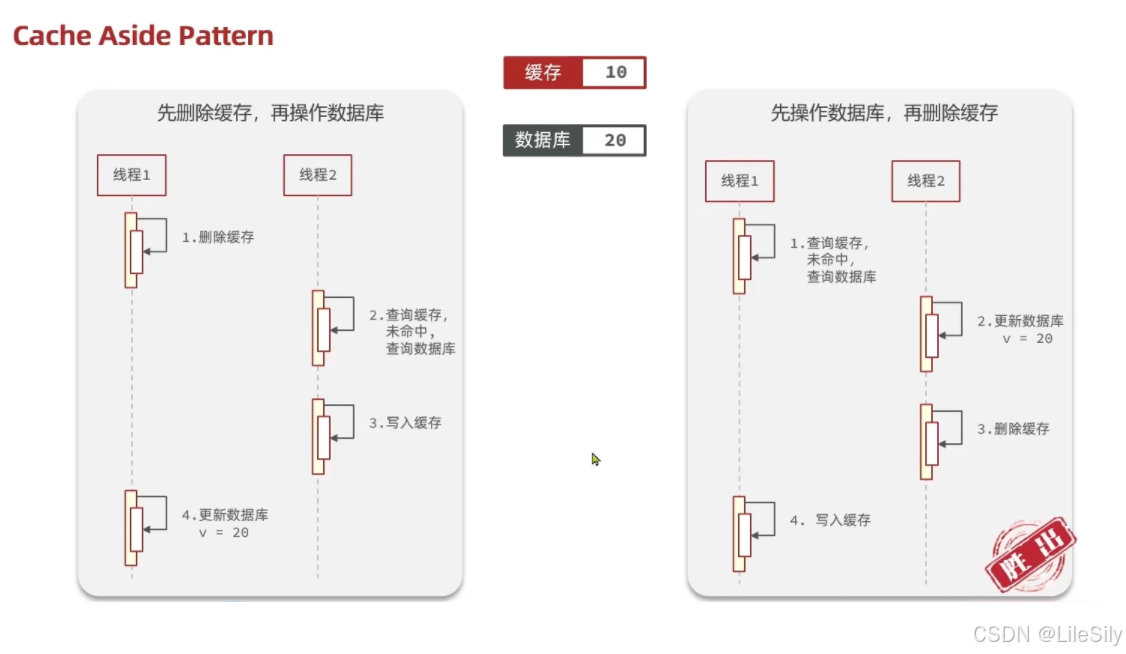
- 首先针对第一种场景,我们需要改进业务逻辑,加强监控报警机制,但是这也是一种亡羊补牢的一种方式.更加靠谱的方案,如果发现这个key在Redis中和mysql中都不存在,我们仍然把这个值写入到Redis中,value设置为一个非法的值(比如""),后续在访问非法数据的时候,就会返回设置好的非法的数据.当然我们还可以进入布隆过滤器.每次查询Redis/mysql之前,都判定一下key是否在布隆过滤器上存在.
- 之后就是第二种场景,我们就需要开发/运维人员介入,尽快回复数据.
- 第三种场景,需要安全团队的介入.
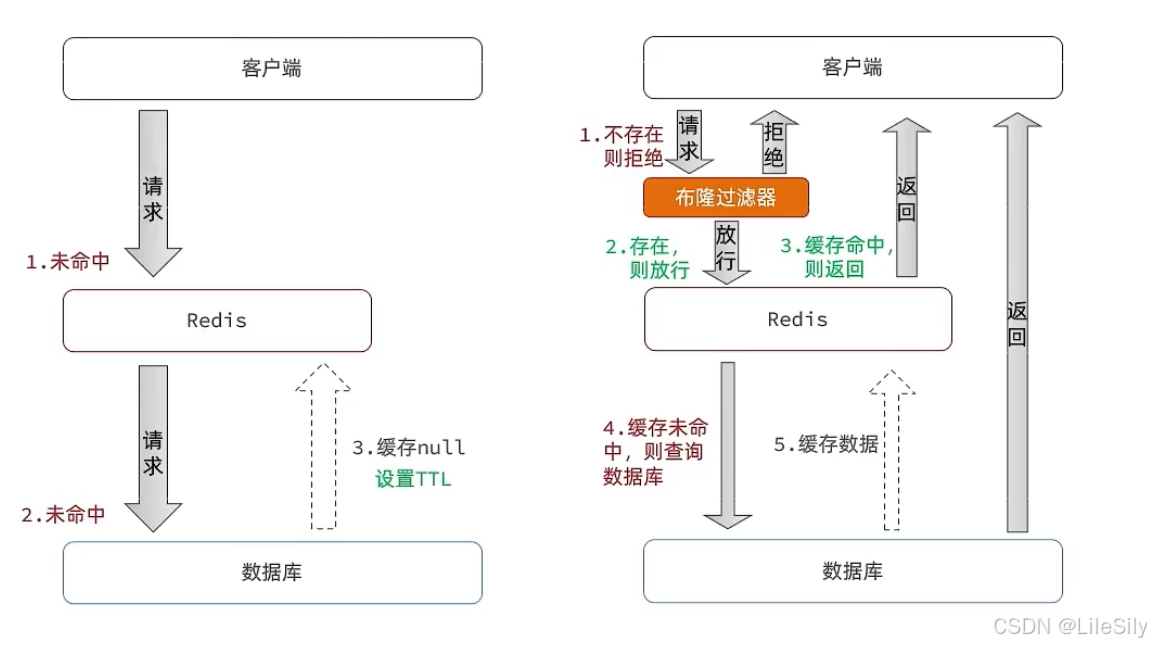
3.3 缓存雪崩
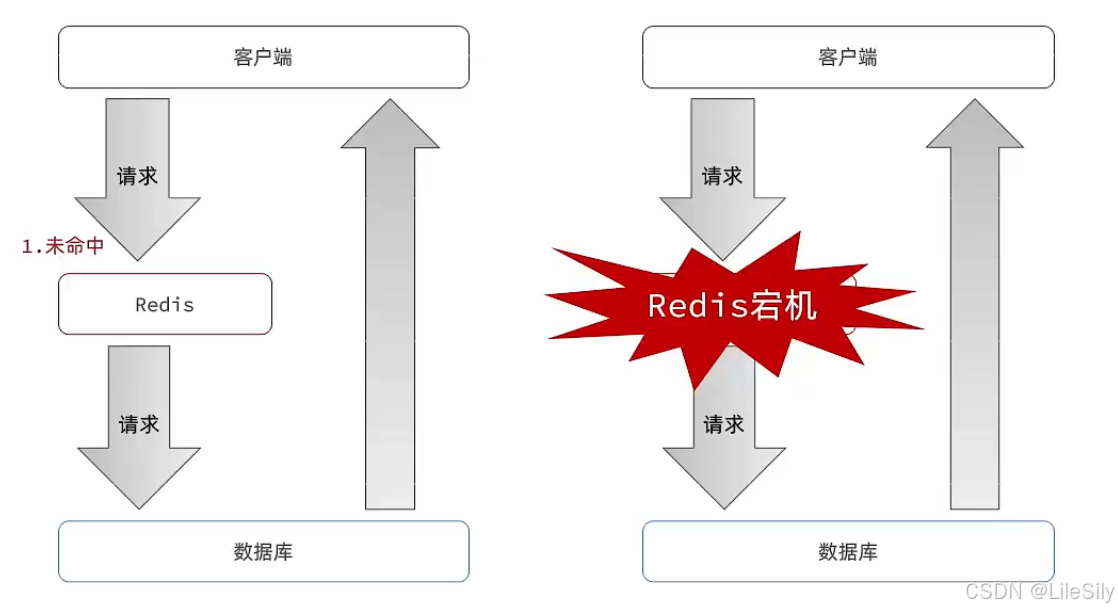
由于在短时间内,Redis上大规模的key失效,导致了缓存命中率陡然下降,让数据库的压力陡然上升,甚至发生宕机.
造成上述这种问题的一般有两种情况:
- Redis服务器宕机,或者是Redis的集群大量服务器宕机
- 短时间之内,设置了很多过期时间相同的key.过期的时候也正好是同一时间过期.
解决上述问题的主要方式是:
- 我们可以使用通过主从复制模式+哨兵模式,保证Redis集群的可用性.
- 我们可以选择不给Redis的数据设置过期时间或者是设置过期时间的时候,加入一些随机的因子(避免同一时间过期).
3.4 缓存击穿
缓存击穿相当于缓存雪崩的一种特殊情况,雪崩是大量的key发生了过期,但是穿透与雪崩的区别就是==只是热点数据突然发生了过期,==这就会使得大量的请求打在了数据库上,导致数据库发生宕机.相比雪崩,击穿过期的是热点数据,访问频率更高,影响更大.
逻辑分析: 假设线程1在查询缓存之后,本来应该去查询数据库,然后把这个数据重新加载到缓存的,此时只要线程1走完这个逻辑,其他线程就都能从缓存中加载这些数据了,但是假设在线程1没有走完的时候,后续的线程2,线程3,线程4同时过来访问当前这个方法, 那么这些线程都不能从缓存中查询到数据,那么他们就会同一时刻来访问查询缓存,都没查到,接着同一时间去访问数据库,同时的去执行数据库代码,对数据库访问压力过大
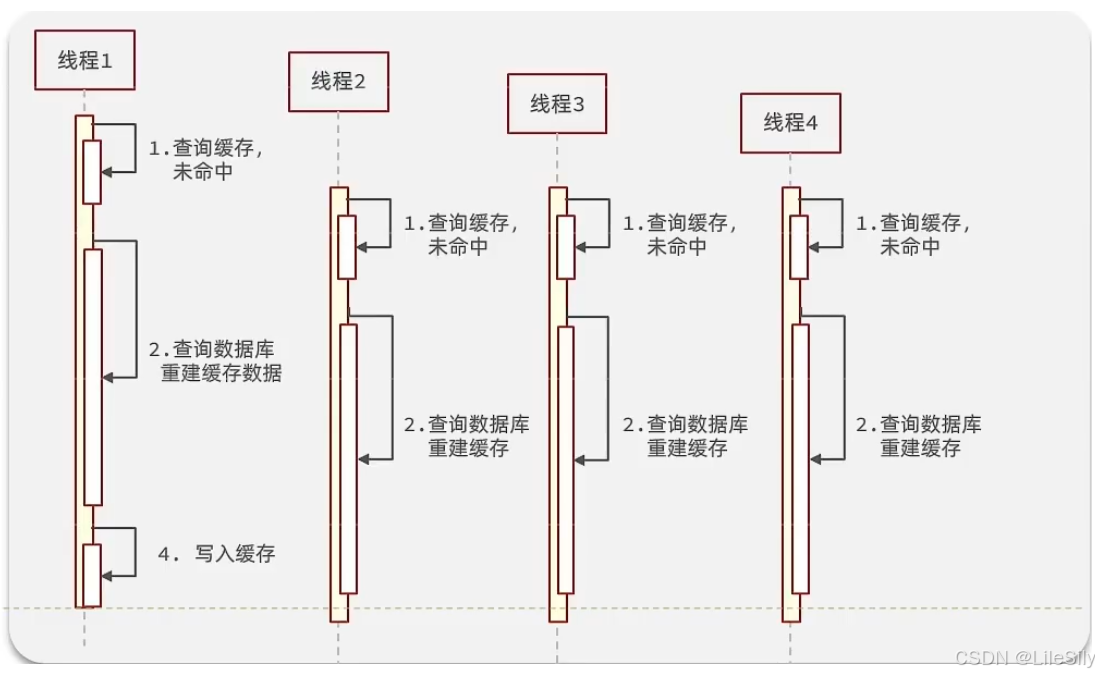
常见的解决方案有两种:
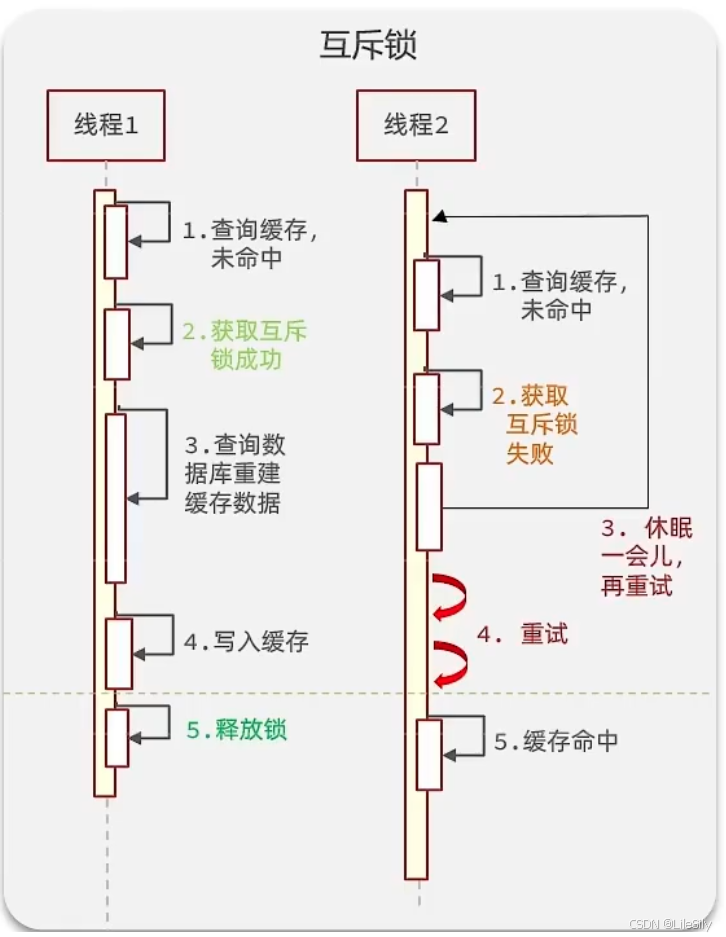
- 使用锁来解决
因为锁能实现互斥性,假设线程过来,只能一个人一个人的过来访问数据库,那么就会大大减小数据库的压力.我们可以采用tryLock的方法+double check来解决这样的问题.
假设现在线程1过来访问,它查询缓存没有命中,此时他得到了锁的资源,之后线程1就会执行接下来该执行的逻辑,假设现在线程2过来,线程2在执行过程中,并没有获得到锁,那么线程2就可以进行休眠,知道线程1把锁释放之后,线程2得到锁,然后来执行逻辑,此时就可以从缓存中拿到数据了.
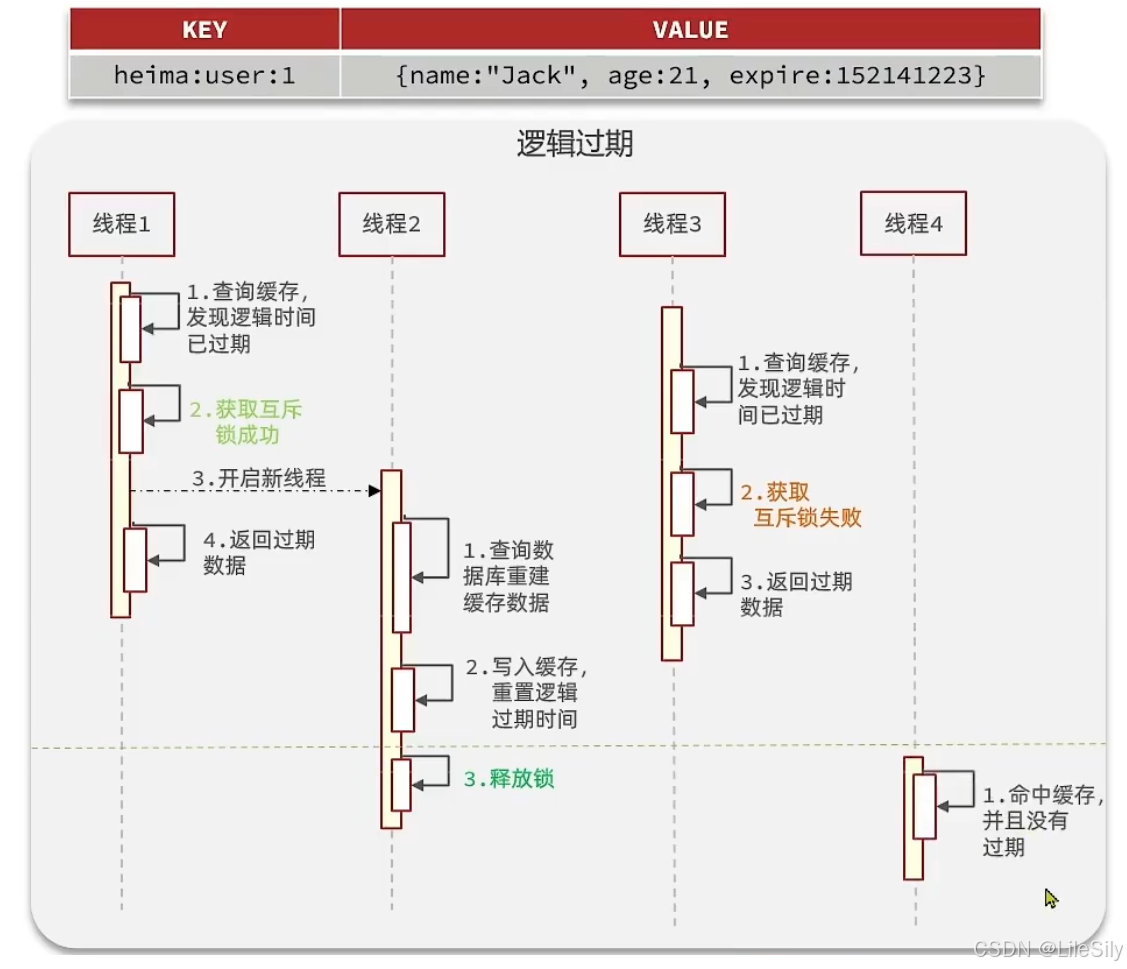
- 使用逻辑过期方案
我们之所以会出现这个缓存击穿问题,主要原因是在于我们对key设置了过期时间,假设我们不设置过期时间,其实就不会有缓存击穿问题,但是不设置过期时间,这样数据就会一直占用我们的内存,我们便可以采用逻辑过期的方式.
我们把过期时间设置在Redis的Value中,注意: 这个过期之间并不会直接作用于Redis,而是我们后续通过逻辑去处理,假设线程1去查询缓存,然后Value中判断出来当前的数据已经过期了,此时线程1去获得互斥锁,那么其他线程会进行阻塞,获得了锁的线程会开启一个新线程去进行以前的重构数据的逻辑,直到新开的线程完成这个逻辑之后,才释放锁.而线程1直接进行返回,假设现在线程3过来访问,由于线程2持有着锁,所以线程3无法获得锁,线程3也直接返回数据,只不过返回的过期的数据,只有等到新开的线程把2重建数据构建完之后,其他线程才能返回正确的数据.
这种方案巧妙在于,异步的构建缓存,缺点在于在构建完缓存之前,返回的都是脏数据.
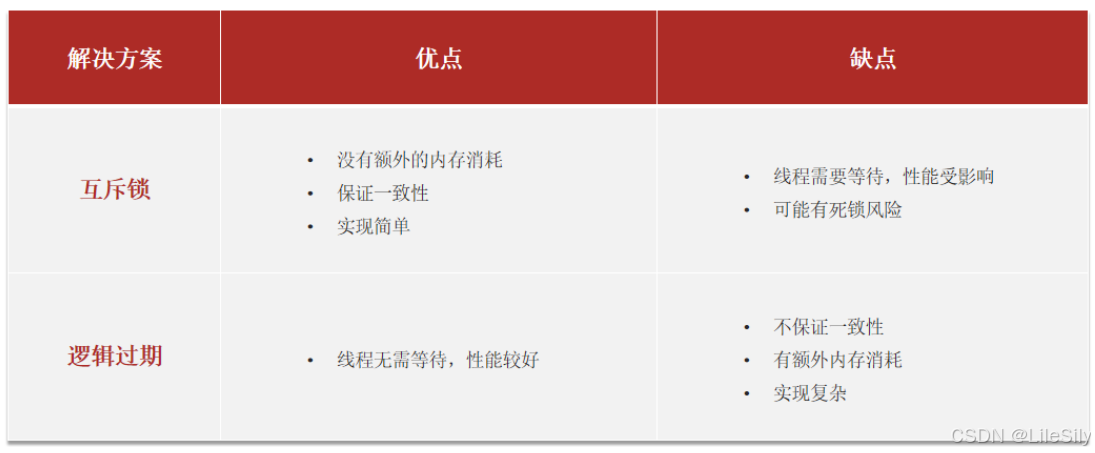
对比两种方案,互斥锁的方案虽然性能较差,但是会保证数据的一致性,逻辑过期的方案虽然性能较好,但是不保证数据的一致性.
3.5 缓存降级
当访问量剧增的时候(比如热key),服务出现了一定的问题,比如响应时间慢或者是不响应.我们任然需要保证我们的服务是可用的,即使是有损服务.
那么如何解决呢,缓存降级核心思想如下:
- 保证核心业务的运转,非核心功能可以暂时进行关闭或者是降级.
- 通过减少对缓存的依赖,直接让部分请求访问数据库.
- 当缓存失效或者是未命中的时候返回默认值来降低系统的压力.
- 限流降级,通过一些限流算法控制访问流量,对于部分请求直接返回降级结果,如请求拒绝,避免长时间阻塞等待.
4. 热key问题
热 Key 问题是指在 Redis 中某些 Key 被频繁访问,导致单个 Redis 实例负载过高,可能引发性能瓶颈甚至服务不可用。以下是几种有效的解决方案:
- 为当前的结点多加一些从结点,可以增大当前集群分片被读取的能力.
- 把这个key分散到不同的结点上,把压力分摊开,以缓解压力.
- 把当前的key可以保存到客户端本地的缓存中,以防止每次都从Redis中获取.
- 可以使用缓存降级的手段,可以将一部分的请求打到数据库上,以分散压力,也可以使用限流,对部分请求直接返回降级结果.

















 5467
5467

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









