






距离python的学习已经过去了三个星期,在这三个星期里,我已经充分学习了python的基础语法知识,接下来,我将从头到尾依次介绍总结学习知识的内容与感受。
python基础语法篇
一、字面量
定义:在代码中,被写下来的固定的值。
字面量以我的理解,就是不被任何变量接受的值,也就是说“孤零零”地在代码中,字面量包括:数字(number)、字符串(string)、列表(list)、元组(tuple)、集合(set)、字典(dictionary)等,例如:
1 # 数字
"python" # 字符串
[1, 2, 3] # 列表
(4, 5, 6) # 元组
{7, 8, 9} # 集合
{a = 1, b = 2, c = 3} # 字典以上皆为字面量。
二、注释
定义:对代码进行解释说明的文字,不会被执行。
如定义所示,注释的意义就是向其他人解释自己代码的意义,在python中常见的注释类型有两种,第一种单行注释,以“#”开头,后跟注释内容;第二种多行注释,一对三个双引号"""注释内容""",例如:
# 单行注释
"""
我是
多行注释
!
"""三、变量
定义:程序运行时记录数据所用。
这个就不多说了,定义方式为: 变量名称 = 变量值。
这里要注意几点,每一个变量都有自己的名称,称为变量名,或者标识符,而在python中变量名的命名格式可以为:
①字母、数字(不能放在开头)、下划线以及中文 # (虽然我没用过中文定义,但是这里就能体现出py比c先进的一方面了(嘻嘻))。
②大小写敏感,python中变量名是区分大小写的。
③不可使用关键字(例如:int input等等)
在命名时,应该尽量做到如下原则:
①见名知意,命名简洁
②多个单词间要用下划线分隔
③英文字母全小写
而变量的值可以为字面量的任意一个类型,这里就不做演示了。
四、数据类型
所谓数据类型,就是python可以表示哪些类型的数据,针对数据来说,数据类型包含:整型int、浮点型float、布尔型bool、复数型complex,但是除此之外,还有许多其它的数据类型,而想要查看这一数据的类型,就要用到type()这个功能,例如:
a = 3
print(f"变量a的数据类型为:{type(a)}")
# 变量a的数据类型为:<class 'int'>
b = [1, 2]
print(f"变量b的数据类型为:{type(b)}")
# 变量b的数据类型为:<class 'list'>
这样就说明了变量a是整型,变量b是列表。
五、数据类型的转换
在python中,不同的数据类型大部分是可以相互转换的,转化的语句即为数据类型(变量名),这些运算都是带有结果的,顺带一提,我们在使用input输入数据时,不论你输入的是数字还是字符,python一律视作字符串,所以,想要正常使用你输入的数据(尤其是数据为数字的时候),我们必须要把input的类型转换,因而一般会用到int(input())这样的语句。
例如:
a = input()
# 我们输入数字3
print(type(a))
# 可得输出结果为:<class 'str'>
a = int(input())
# 我们再次输入数字3
print(type(a))
# 这次的输出结果就变成了:<class 'int'>六、运算符
运算符可分为算数运算符和逻辑运算符。
算数运算符包括:+加法 -减法 *乘法 /除法 //整除 %求余 **指数 =赋值 +=加等于 -=减等于等
逻辑运算符有:and逻辑于(对应c语言中的&&)、or逻辑或(对应c语言中的||)、not逻辑非(对应c语言中的!)
比较运算符:==等于、!=不等于、>大于、<小于、>=大于等于、<=小于等于
这里值得注意的是,比较运算符中的==和赋值=是两个完全不同的概念,前者是比较两者是否相等,后者是将变量值赋予标识符。
通过这些运算符,我们就可以对数字和逻辑进行一些基本的运算。
python判断语句篇
一、布尔类型
布尔类型即bool,是判断真与假的语句,在python中,真为True,为1;假为False,为0,在定义时,可以直接定义为:变量名称 = 布尔类型字面量
在python的判断语句和循环语句中,一切都是基于bool所运算的。
二、if elif else语句
if语句在定义是,语法如下:
if 判断条件:
条件成立时要做的事情。
例如:
if 3>2:
print("right")
# right而在通常情况下,我们也要考虑到2<3的状况,此刻就要运用到else
if 判断条件:
条件成立时要做的事情。
else:
条件不成立时要做的事。
例如:
if 3<2:
print("right")
else:
print("wrong")
# wrong而又有时,我们要判断的条件不只有一个,这时就要用到elif:
if 判断条件1:
条件1成立时要做的事。
elif 判断条件2:
条件2成立时要做的事。
······
elif 判断条件n:
条件n成立时要做的事。
else:
条件全都不成立时要做的事。
这里要注意的是,判断是互斥且有序的,上一个满足后面就不会再判断了。
例如:
a = int(input())
b = int(input())
if a > b:
print(f"{a}比{b}大")
elif a < b:
print(f"{a}比{b}小")
else:
print(f"{a}和{b}一样大")三、嵌套
所谓嵌套,意思就是一个if语句里套着另外一个if语句,只有第一个if语句满足条件,才会继续执行第二个if语句。嵌套的关键点在于空格缩进,通过空格缩进,就可以决定语句间的层级关系。
例如:我要将a,b,c按从小到大的顺序输出,就可以用嵌套的语句
a = int(input())
b = int(input())
c = int(input())
if a > b:
if b > c:
print(f"{a}>{b}>{c}")
elif c > b:
if c > a:
print(f"{c}>{a}>{b}")
else:
print(f"{a}>{c}>{b}")
else:
if a > c:
print(f"{b}>{a}>{c}")
elif c > a:
if c > b:
print(f"{c}>{b}>{a}")
else:
print(f"{b}>{c}>{a}")
# 输入1 2 3
# 可得3>2>1python循环语句
一、while循环
while循环有如下语法:
while 条件:
条件满足时执行的代码。
在这里,只要while后跟的条件满足,就会无限执行循环
例如:
i = 0
while i <= 5:
print(i)
i += 1
"""
运行结果:
0
1
2
3
4
5
"""同if,while也是可以嵌套的,这里不做演示。
二、for循环
①语法:
for 临时变量 in 待处理的数据集:
循环满足条件时执行的代码。
首先,for和while循环是有区别的,while循环的循环条件是自定义的,自行控制循环条件,而for循环是一种“轮询”机制,他是对一批内容进行“逐个处理”的,本质上是一种遍历循环。
②range语句:
range语句往往用于for循环的待处理的数据集中,其有三个语法:
Ⅰ.range(num)范围:[0,num)
Ⅱ.range(num1,num2)范围:[num1,num2)
Ⅲ.range(num1,num2,step)这里举个例子range(5,10,2)对应的范围就是[5,7,9]意为从5开始依次跳过2个步长到下一个数字。
例:
for i in range(1,5):
print(i)
"""
输出结果:
1
2
3
4
"""同if和while,for语句也是可以嵌套的,而除此之外,判断语句和循环语句之间也是支持嵌套的,循环语句之间的嵌套即是完成九九乘法表的方式。
三、break、continue语句
break语句的作用是直接结束本次循环
continue语句的作用是中断本次循环,进入下一次循环
举个例子(这里就只举break的例子):
i = 0
while i <= 5:
print(i)
if i == 3:
break
i += 1
"""
运行结果:
0
1
2
3
"""函数篇
一、函数
函数:组织好的,可重复利用的,用于实现特定功能的代码段
定义函数有如下语句:
def 函数名(传入参数):
函数体
return 返回值
其中,传入参数和返回值可以省略。
而调用函数时可以:
函数名(参数)
在python中,往往是先定义函数,再调用函数。
例如:
def add(a, b):
c = a + b
return c
c = add(3, 2)
print(c)
# 5在以上的函数中,我就用到了传入参数和返回值
所以,我们来说一说这两个东西
①传入参数
定义:在函数进行计算时,接受外部(调用时)提供的数据,例如在本次举例中,就接受了外部的3和2,这里要注意,在定义的时候,是定义的形式参数,也就是说在“def add(a,b)”这一句中,a和b只是形式参数,是无法在实际运行的代码中直接拿过来使用的,而在调用时,传入的是实际参数,所以在“add(3,2)”中,这里的3和2才是实际的参数。
另外,就是每个参数之间要用逗号隔开。
②返回值
return这句话的意思是可返回返回值,即可被变量接受,如“c = add(3, 2)”这句代码中,因为有了在函数定义时的“return c”,所以才可以被下面的变量c接收,即把add(3,2)的值赋给了c。
这里也要注意,在函数中写了return后,其后面的所有代码将不再执行;如果没有return时,系统固定返回None
三、函数说明文档
同注释的作用一样,函数也是可以进行解释说明的,方法就是用多行注释应用于函数体之前
在打出多行注释后,会给你蹦出“:param”和“:return”两个语句,前者是让你解释参数,后者是解释返回值,在调用函数是,将鼠标移到函数名上时,便可以查看所写的注释。
例如
def add(a, b):
"""
:param a: 解释参数1
:param b: 解释参数2
:return: 解释返回值
"""
c = a + b
return c四、嵌套调用
即一个函数里又调用了另一个函数,如果函数A中调用了另外一个函数B,则先把B中任务都执行完毕后才会回到上次函数A执行的位置。
五、变量作用域
变量作用域的意思是定义的变量哪可用,哪不可用,可分为:
①局部变量:定义在函数体内部变量,即只在函数体内部生效。
②全局变量:函数体内、外都能生效的变量
③global语句:可在函数内部声明变量为全局变量,语法为:global 变量
例如还是在上面add函数中,形式参数a和b就属于局部变量,而c就属于全局变量。
六、函数多返回值
如题,一个函数是可以有多个返回值的,语法形式为:
return 返回值1,返回值2
在接收时,可以用如下语句:
变量1,变量2 = 函数名
以上构成的意义就是:
变量1 = 返回值1
变量2 = 返回值2
七、函数多种传参方式
①位置参数:调用函数时根据函数定义的参数位置来传递参数,要求是顺序、个数必须一致。
②关键词参数:函数调用时通过“键 = 值”形式传递,要求位置参数在关键词参数之前,关键词参数间无先后顺序。
③缺省参数:用于定义函数时,为函数提供默认值,调用时不传参数则用默认值,默认值统一在最后。
④不定长参数:用于不确定调用时会传递多少参数。
这里举几个例子:
def student(name, age, gender = "女"):
print(f"姓名:{name}")
print(f"年龄:{age}")
print(f"性别:{gender}")
# 位置参数:
student("a", 10)
"""
输出结果:
姓名:a
年龄:10
性别:女
"""
#关键字参数
student(age = 20, name = "b", gender = "男")
"""
输出结果:
姓名:b
年龄:20
性别:男
"""这里可以看到,在最初的定义函数中,我们把gender固定为女,即缺省参数,因而在调用函数如果对此不进行任何改变的话那么gender固定为女,在位置参数中,name和age的顺序都是与定义函数参数位置一致的,而在关键字参数中,我们将三个关键字都传入了相应的值,因而有了以下的输出结果,在这里,不定长参数就不做演示。
八、匿名函数
①函数作为参数传递,即函数自身也可以作为参数传入另一个函数,他的作用是传入计算逻辑而非传入数据
②lambda匿名函数:定义无名称函数,只可临时使用一次
语法:lambda 传入参数:函数体(一行代码)
数据容器
数据容器的作用是容纳多份数据,类似于c语言中的数组,而在python的数据容器下,分为:列表(list)、元组(tuple)、字符串(string)、集合(set)、字典(dictionary),而通过是否支持下标索引、是否支持重复元素、是否可以修改,将其分为不同的大类。
一、列表(list)
定义方式:
①字面量:[元素1,元素2······]
②变量:变量名称 = [元素1,元素2······]
③定义空列表:Ⅰ.变量名称 = [ ] Ⅱ.变量名称 = list()
这里注意,列表内的每个数据称为元素,以“[ ]”为标识,列表内每个元素用“,”隔开;列表可一次存储多个数据,且可以为不同的数据类型,支持嵌套。
下标索引(取出特定位置的元素):
左→右:从0开始,依次递增/右→左:-1开始,依次递减
索引语句:列表[下标]
例如:
list_1 = [[0, 1, 4], 2.333, "py"]
a = list_1[0][2] # 这里是指第一个元素里的第三个元素
b = list_1[1]
c = list_1[2]
print(a)
# 4
print(b)
# 2.333
print(c)
# py常用操作:
①查找某元素坐标:列表.index(元素)
②修改元素值:列表[下标] = 值
③插入元素:列表.insert(下标,元素) # 在指定下标位置插入指定元素
④追加元素:Ⅰ 列表.append(元素) # 将指定元素追加到列表尾部
Ⅱ 列表.extend(其它数据容器) # 将其它容器内容取出,依次追加到尾部
⑤删除元素:Ⅰ del列表[下标] # 直接通过下标删除
Ⅱ 列表.pop(下标) # 拿出作为返回值得到
Ⅲ 列表.remove(元素) # 删除第一个匹配项
⑥清空列表内容:列表.clear()
⑦统计某元素在列表内的数量:列表.count(元素)
⑧统计列表内有多少元素:len(列表)
列表的遍历:
列表的遍历意思就是把列表内所有元素都处理一遍,一般有while和for两种方式
①while:
index = 0
while index < len(列表):
元素 = 列表[index]
处理元素
index += 1
②for:
for 临时变量 in 数据容器:
处理元素
这里注意为什么for的待处理数据集要写数据容器呢,是因为任何数据容器都可以用for遍历,不只有列表。
二、元组(tuple)
元组无法被篡改,属于是一个只读的列表。
定义方式:
①字面量:(元素1,元素2······)
②变量:变量名称 = (元素1,元素2······)
③定义空元组:Ⅰ.变量名称 = () Ⅱ.变量名称 = tuple()
这里唯一要注意的是,当元组只有一个数据时,这个数据后要添逗号。
由于元组内的数据不可被更改,所以元组只支持查找(index)、统计(count、len)操作,其意义与列表常用操作相同,同理,元组的遍历也同列表。
三、字符串(string)
字符串是字符的容器,同样不可被修改并且支持下标。
另,字符串有如下常规操作:
①查找:index()
②替换:字符串.replace(字符串1,字符串2) # 将字符串内全部的字符串1替换为字符串 2,来得到一个新的字符串。
③分割:字符串.split(分隔符字符串) # 按照指定的分隔符字符串,将字符串划分为多个 字符串,存入列表对象,字符串本身不变,而是得到一个列表对象。
④规整:Ⅰ 字符串.strip() # 去掉前后空格
Ⅱ 字符串.strip(字符串) # 去掉前后指定字符串
⑤统计:count、len函数(同list)
四、序列
序列的定义:内容连续、有序、可使用下标索引的一类数据容器,在如上我们介绍的列表、元组和字符串都属于序列。
序列的切片:从一个序列中取出一个子序列。
语法:序列[起始下标:结束下标:步长],表示在序列中,从指定位置开始依次取出元素,到指定位置结束,得到一个新的序列。
此外如果起始下标为空,则视作从头开始;结束下标为空视作取到结尾;步长表示依次取元素的间隔。
例如:
list_1 = [1, 2, 3, 4, 5, 6, 7, 8, 9, 10]
a = list_1[0:7:2]
print(a)
# [1, 3, 5, 7]五、集合(set)
集合不支持元素重复,且不支持下标索引(即无序)。
定义:
①字面量:{元素1,元素2······}
②变量:变量名称 = {元素1,元素2······}
③定义空元组:变量名称 = set()
集合有以下操作:
①添加新元素:集合.add(元素)
②移除元素:集合.remove(元素)
③随机取出元素:集合.pop()
④清空集合:集合.clear()
⑤取差集:集合1.different(集合2) # 集合1有集合2没有,并生成新集合。
⑥消差集:集合1.different_update(集合2)# 集合1内删除与集合2相同元素,集合1被修改
⑦合并:集合1.union(集合2) # 将集合1、集合2组合成新集合
⑧统计:len()
⑨遍历:由于集合无法用下标索引,所以只能用for循环遍历。
六、字典(dictionary)
字典不可重复,不可用下标索引。
定义:
①字面量:{key1:value1,key2 = value2······}
②变量:变量名称 = {key1:value1,key2 = value2······}
③定义空元组:Ⅰ 变量名称 = { } Ⅱ 变量名称 = dict()
可通过key值来取出value:字典[key]。
其中,key和value可为任意数据类型,但是key不可为字典,同列表,字典在定义时可以嵌套。
字典有如下操作:
①新增元素:字典[key] = value # 字典被修改,新增了元素
②更改元素:字典[key] = value # 字典被修改,元素更新
③删除元素:字典.pop(key) # 获得指定key的value,指定key数据删除
④清空字典:字典.clear() # 字典被修改,元素清空
⑤获取全部key:字典.keys() # 得到字典中全部的key
⑥字典遍历:Ⅰ for key in 字典.keys(): Ⅱ for key in 字典:
⑦统计元素数量:len(字典)
七、总结
如开头所说,在数据容器中,我们通过是否支持下标索引、是否支持重复元素、是否可以被修改,将数据容器分成不同的类。
那么,根据是否支持下标索引,有:
支持下标索引:列表、元组、字符串
不支持下标索引:集合、字典
是否支持重复元素:
支持重复元素:列表、元组、字符串
不支持重复元素:集合、字典
是否可以被修改:
可以被修改:列表、集合、字典
不可以被修改:元组、字符串
转换:
转为列表:list(容器) 转字符串:str(容器)
转为元组:tuple(容器) 转集合:set(容器)
排序:
sorted(容器):将给定容器进行正向排序→结果变为列表。
sorted(容器,[reverse = True]):将给定容器进行反向排序→结果变为列表。
文件操作篇
我们知道,在敲代码的时候,我们的代码先被计算机翻译为二进制编码,然后再被执行,执行后再被翻译回来,供我们阅读,而UTF-8是目前全球通用的编码格式。
一、文件读取
文件读取的基本操作:①打开文件、②读写文件、③关闭文件
open打开:可打开一个已存在文件或者创建一个新文件。
语法:open(name,mode,encoding),其中,name表示要打开的目标文件名的字符串(可包含文件所在的具体路径);mode:设置打开文件模式(访问模式):只读(r)、写入(w)、追加(a);encoding:编码格式(推荐使用UTF-8)。
例如:
f = open("python.txt", "r", encoding = "UTF-8")
# 意为打开一个名为“python.txt”的文档read读取:文件对象.read(num),num表示要从文件中读取的数据长度(单位是字节),如果没有传入num,则表示要读取文件中所有数据。
readlines()方法:可以按照行的方式把整个文件中的内容进行一次性读取,并返回一个列表,每一个数据为一个元素。
readline()方法:一次只读取一行。
for循环读取文件行:
for line in open(name,mode):
print(line)
例如我有一个txt文件:

那么我运行如下代码:
f = open("py.txt", "r", encoding = "UTF-8")
print(f.read())
"""
输出结果:
hi
今天天气
很不错
耶!
"""
print(f.readlines())
# ['hi\n', '今天天气\n', '很不错\n', '耶!']
print(f.readline())
# hi
for line in open("py.txt", "r", encoding = "UTF-8"):
print(line)
"""
输出结果:
hi
今天天气
很不错
耶!
"""需要注意的是,这三段代码都是分别单独运行的,如果放在一起运行的话是无法输出这个结果的,因为在python的read语句中,你每使用read读一句,再用read去读的话会从上一个read结束的地方继续读,如果想要避免这个问题,就要用到close语句
close关闭:文件对象.close(),通过close关闭文件对象,也就是关闭对文件的占用,如果不调用close,同时程序没有停止运行,则该文件将一直被python占用。
with open语句:
with open(name,mode)as 文件对象:
这个可以通过在with open的语句块中对文件进行操作,并且操作完成后自动关闭close文件。
二、文件的写入
①打开:文件对象 = open(name,“w”,encoding = “UTF-8”)
②写入:文件对象.write(写入语句)
③刷新:文件对象.flush()
该处w为写入模式,文件不存在会创建文件,文件存在则会清空原有内容并写入新内容,写完后必须要有刷新语句,才能使写入的语句加到文件中!!!
例如:
f = open("py.txt", "w", encoding="UTF-8")
f.write("good day!")
f.flush()
便可见原来的txt文件变成了:
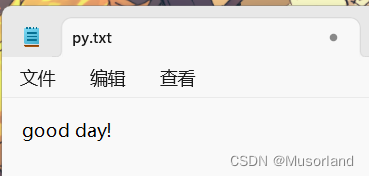
三、文件的追加
①打开:文件对象 = open(name,“a”,encoding = “UTF-8”)
②写入:文件对象.write(写入语句)
③刷新:文件对象.flush()
在a模式下,文件不存在会创建文件,文件存在会在最后追加写入新内容
例如执行如下代码:
f = open("py.txt", "a", encoding="UTF-8")
f.write("Nice to meet you!!")
f.flush()
文件就会变成:
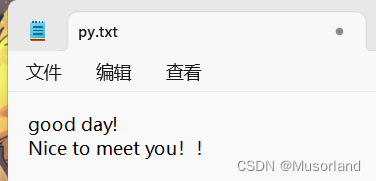
异常篇
异常的意思是,当程序在检测到一个错误时,python解释器无法继续执行,从而出现一些错误提示,即异常(BUG)
一、异常的捕获
捕获的意思是:对可能的bug进行提前准备、处理。
语法:
①捕获常规异常
try:
可能发生错误的代码。
except:
如果出现异常执行的代码。
②捕获指定异常
try:
可能发生错误的代码。
except NameError as 变量名:
如果出现异常执行的代码。
③捕获多个异常
try:
可能发生错误的代码。
except (NameError1,NameError2) as 变量名:
如果出现异常执行的代码。
④捕获全部异常
try:
可能发生错误的代码。
except Exception as 变量名:
如果出现异常执行的代码。
⑤else:
表示若没有异常要执行的代码。
⑥finally:
无论是否异常都执行的代码。
举个例子:
# 捕获常规异常
try:
1 / 0
except:
print("发生错误")
# 发生错误
#捕获指定异常
try:
print(a)
except NameError as e:
print("a变量名称未定义")
# a变量名称未定义
# 捕获多个异常、全部异常同理,这里不做演示
# else、finally用法
try:
1 / 1
except:
print("发生错误")
else:
print("没有错误")
# 没有错误
try:
1 / 0
except:
print("发生错误")
else:
print("没有错误")
finally:
print("演示结束")
# 发生错误
# 演示结束二、异常的传递
python中的异常是能够传递下去的,举个例子,当函数fun1发生异常,并且没有捕获处理这个异常时,异常会被传递到函数fun2,当函数fun2也未捕获处理这个异常时,会一直传递到最后捕获异常或者抛出异常。
def fun1():
print(a)
def fun2():
fun1()
def main():
fun2()
print(main())
"""
会有如下输出结果:
Traceback (most recent call last):
File "C:\Users\33622\PycharmProjects\pythonProject2\2.py", line 16, in <module>
print(main())
^^^^^^
File "C:\Users\33622\PycharmProjects\pythonProject2\2.py", line 12, in main
fun2()
File "C:\Users\33622\PycharmProjects\pythonProject2\2.py", line 7, in fun2
fun1()
File "C:\Users\33622\PycharmProjects\pythonProject2\2.py", line 2, in fun1
print(a)
^
NameError: name 'a' is not defined
"""可见,异常会一直追溯到一开始未定义的a中,并一直传递下去。
类篇
Python中,类(Class)和对象(Object)是面向对象编程(OOP)的两个核心概念。面向对象编程是一种程序设计模式,它使用对象来设计软件,模拟现实世界中的实体和关系;类是对象的模板或蓝图,而对象是类的实例。
一、类的定义
类是创建对象的模板。它定义了一个对象的属性和方法。属性是在对象中存储的数据,而方法是可以在对象上执行的操作。
定义方式:
class MyClass:
def __init__(self): # 构造函数,在创建新对象时自动调用
self.attribute = "Hello" # 属性定义
def method(self): # 方法定义
print("This is a method")
二、对象
1、对象的属性
对象是类的实例,它具有类定义的属性和方法。在Python中,可以使用.操作符来访问对象的属性。
2、对象的方法
对象的方法也是由类定义的。在Python中,可以使用.操作符来调用对象的方法。
三、类和对象的继承性和多态性
继承:
一个类可以继承另一个类的属性和方法。在Python中,使用关键字extends来实现继承。
多态:
多态性是指使用不同的对象调用相同的方法,产生不同的结果。这是通过方法的重写(Overriding)实现
四、类和对象的封装性
封装:
封装是面向对象编程的三大特性之一,它隐藏了对象的内部状态和实现细节,只对外提供必要的接口。这样可以提高软件的安全性和可维护性。
实现:
class MyClass:
def __init__(self):
self.__private_attribute = "Hello" # 私有属性,不能在类的外部直接访问
def get_private_attribute(self): # 提供公开的接口来获取私有属性的值
return self.__private_attribute总结
第一次写博客,不知道具体格式和流程,就只是把自己学的知识都写出来了,写的可能不太好,请学长学姐多多见谅!!!!
以上就是这一个月所学的python知识。















 3219
3219

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









