






一 环境免密完全分布式搭建
1 前置环境设置
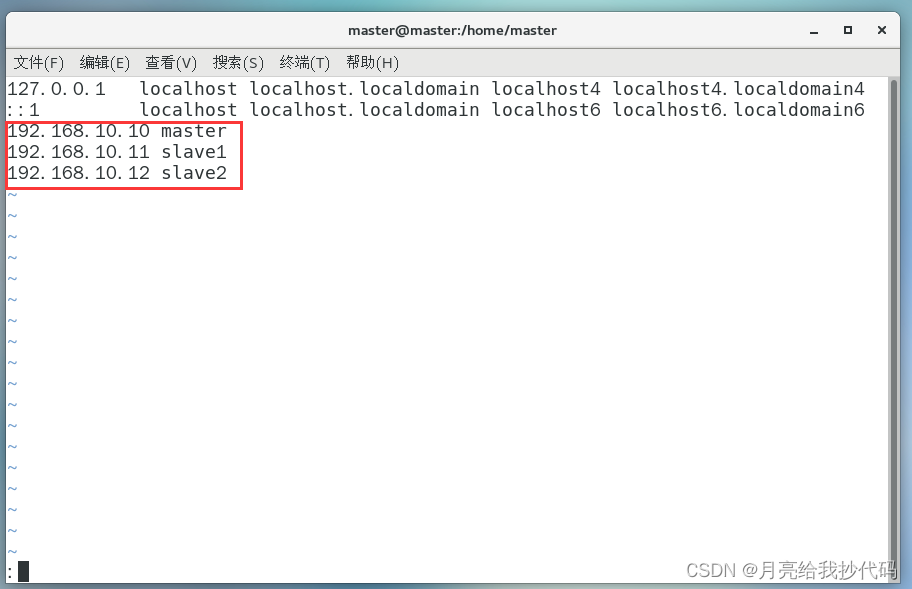
1.修改主机名称为 “master” (你可以取其它的名字)与 hosts 文件,方便后续进行集群之间的映射。
# 修改主机名称
vi /etc/hostname
# 或者
hostnamectl set-hostname master修改 hosts 文件,(三台主机的IP要对应且遵循顺序)提前添加映射,注意保存退出。
2.关闭防火墙
# 临时关闭防火墙
systemctl stop firewalld
# 永久关闭防火墙
systemctl disable firewalld3 卸载原生 JDK,最小化安装的无需操作。
rpm -qa | grep -i java | xargs -n1 rpm -e --nodeps2 免密登录设置
# 生成公钥与私钥(三次回车)
ssh-keygen
# 向目标主机发送公钥(输入密码)
ssh-copy-id slave1
ssh-copy-id slave2
# 也需要对自己设置免密哦
ssh-copy-id master
# 免密登录,输入 exit 退出登录
ssh slave1
...3 集群安装规划
为了合理的分配资源,我们需要对集群进行节点规划。
master slave1 slave2
HDFS NameNode DataNode DataNode SecondaryNameNode DataNode
YARN NodeManager ResourceManager NodeManager
节点解析
名称 作用
NameNode 也称为 nn,管理文件系统的命名空间,维护文件系统树以及整个树上所有文件和目录,负责协调集群中的数据存储。
SecondaryNameNode 帮助 NameNode 缓解压力,合并编辑日志,减少 NameNode 启动时间。
ResourceManager 一个仲裁整个集群可用资源的主节点,帮助 YARN 系统管理其上的分布式应用。
NodeManager YARN 中单节点的代理,它管理 Hadoop 集群中单个计算节点。
DataNode 负责真正存储数据的节点,提供来自文件系统客户端的读写请求。
二 安装Hadoop完全分布式
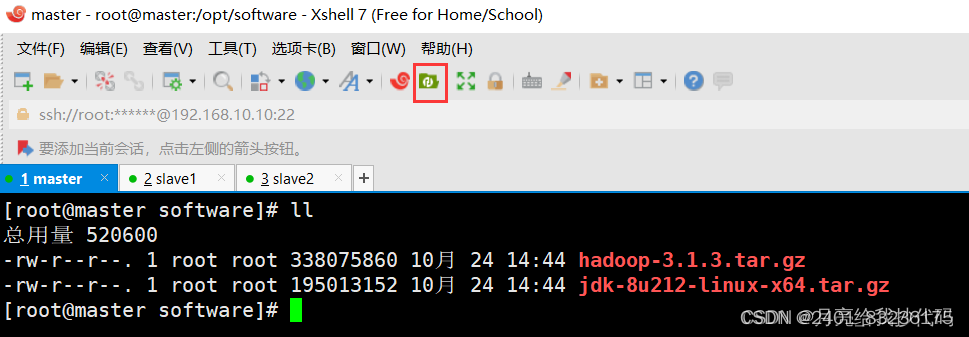
1上传安装包和JDK1.8
使用xtfp工具将Hadoop和jdk包上传到software文件夹,以便于后期使用。
2解压文件
解压文件要用以下命令:
tar -zxvf hadoop-3.1.3.tar.gz -C /opt/module/
tar -zxvf jdk-8u212-linux-x64.tar.gz -C /opt/module/3配置环境变量
vi /etc/profile
# 在文件末尾添加,将路径更改为你的安装路径
#JAVA_HOME
export JAVA_HOME=/opt/module/jdk1.8.0_212
export PATH=$PATH:$JAVA_HOME/bin
#HADOOP_HOME
export HADOOP_HOME=/opt/module/hadoop-3.1.3
export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
存退出后执行命令 source /etc/profile ,使用配置的环境变量立即生效。
输入命令 java -version 验证 JDK 是否安装成功:
4配置Hadoopenv.sh文件
在 Hadoop 中有四个重要的配置文件,位于 $HADOOP_HOME/etc/hadoop 目录下,分别是:
1 核心配置文件 —— core-site.xml
- core-site.xml
-
<configuration> <!-- 指定 NameNode 的地址 --> <property> <name>fs.defaultFS</name> <value>hdfs://master:8020</value> </property> <!-- 指定 Hadoop 数据的存储目录 --> <property> <name>hadoop.tmp.dir</name> <value>/opt/module/hadoop-3.1.3/data</value> </property> <!-- 配置 HDFS 网页登录使用的静态用户为 master --> <property> <name>hadoop.http.staticuser.user</name> <value>master</value> </property> </configuration>
2 HDFS 配置文件 —— hdfs-site.xml
- hdfs-site.xml
-
<configuration> <!-- nn(NameNode) web 端访问地址--> <property> <name>dfs.namenode.http-address</name> <value>master:9870</value> </property> <!-- 2nn(SecondaryNameNode) web 端访问地址--> <property> <name>dfs.namenode.secondary.http-address</name> <value>slave2:9868</value> </property> </configuration>
3 YARN 配置文件 —— yarn-site.xml
- yarn-site.xml
-
<configuration> <!-- 指定 MR 走 shuffle --> <property> <name>yarn.nodemanager.aux-services</name> <value>mapreduce_shuffle</value> </property> <!-- 指定 ResourceManager 的地址--> <property> <name>yarn.resourcemanager.hostname</name> <value>slave1</value> </property> <!-- 环境变量的继承 --> <property> <name>yarn.nodemanager.env-whitelist</name> <value>JAVA_HOME,HADOOP_COMMON_HOME,HADOOP_HDFS_HOME,HADOOP_CONF_DIR,CLASSPATH_PREPEND_DISTCACHE,HADOOP_YARN_HOME,HADOOP_MAPRED_HOME</value> </property> <!-- 开启日志聚集功能 --> <property> <name>yarn.log-aggregation-enable</name> <value>true</value> </property> <!-- 设置日志聚集服务器地址 --> <property> <name>yarn.log.server.url</name> <value>http://master:19888/jobhistory/logs</value> </property> <!-- 设置日志保留时间为 7 天 --> <property> <name>yarn.log-aggregation.retain-seconds</name> <value>604800</value> </property> </configuration>
4 MapReduce 配置文件 —— mapred-site.xml
- mapred-site.xml
-
<configuration> <!-- 指定 MapReduce 程序运行在 Yarn 上 --> <property> <name>mapreduce.framework.name</name> <value>yarn</value> </property> <!-- 历史服务器端地址 --> <property> <name>mapreduce.jobhistory.address</name> <value>master:10020</value> </property> <!-- 历史服务器 web 端地址 --> <property> <name>mapreduce.jobhistory.webapp.address</name> <value>master:19888</value> </property> </configuration>
5配置slaves文件
在 Hadoop 的 2.x 版本中 workers 文件叫 slaves。
该文件位于 $HADOOP_HOME/etc/hadoop 目录下,用于指定集群运行的所有主机
vi $HADOOP_HOME/etc/hadoop/workers
# 添加你的主机
master
slave1
slave2
6文件分发
我们上面的操作都只是在主节点 master 中进行,现在我们需要把所有文件分发给从机 slave1 和 slave2。
# 分发环境变量
rsync -r /etc/profile slave1:/etc/profile
rsync -r /etc/profile slave2:/etc/profile
# 分发 JDK 和 Hadoop
scp -r /opt/module slave1:/opt
scp -r /opt/module slave2:/opt
分发完成后,进入两台从机,刷新分发的环境变量,立即生效。
source /etc/profile7启动集群
如果集群是第一次启动,则需要先格式化 NameNode 节点。
hdfs namenode -format接着启动所有集群
# 在主节点中运行
start-dfs.sh
# 在 ResourceManager 节点中运行
start-yarn.sh
# 或者
# 在主节点中运行
start-all.sh
# 在 ResourceManager 节点中运行
start-yarn.sh
# 在主节点中启动历史服务器
mr-jobhistory-daemon.sh start historyserver
启动完成后,输入 jps 命令检查各节点是否正常:
master 主节点

slave1 节点

slave2 节点

在本地浏览器中查看 Hadoop web 界面:192.168.10.10:9870(这里请修改为你的主机IP)
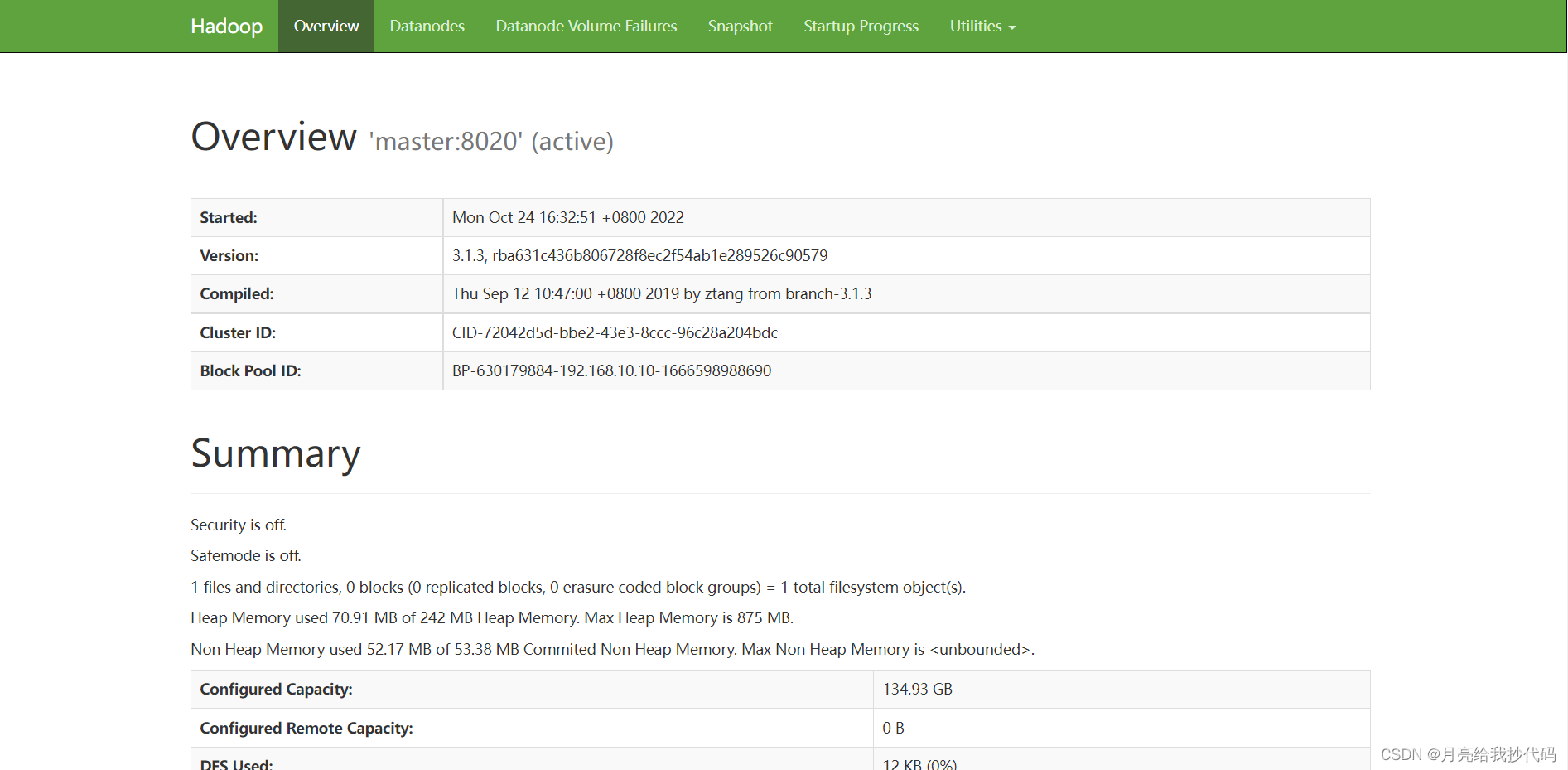
如上图,hadoop完全分布式搭建成功。















 3万+
3万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









