



数据库概念
- 关系数据库:建立在关系模型基础上的数据库
数据库的另外一种区分方式:
基于存储介质
存储介质分为两种:磁盘和内存
关系型数据库:存储在磁盘中
非关系型数据库:存储在内存中
- 关系模型:由关系数据结构、关系操作集合、关系完整性约束三部分组成
关系数据结构:指数据以什么方式存储,是一种二维表的形式存储
关系操作集合:如何来关联和管理对应的存储数据,SQL指令
关系完整性约束:数据内部有对应的关联关系,以及数据与数据之间也有表内约束:每列只能放对应数据
表间约束:外键??
SQL
-
基本介绍:
结构化查询语言,是一种特殊目的的编程语言 -
分类
- 数据查询语言:专门用于查询数据(select/show)
- 数据操作语言:专门用于写数据(insert/update/delete)
- 事务处理:用于事务安全处理(transaction)
- 数据控制:用于权限管理(grant/revoke)
- 数据定义语言:用于结构管理(表结构/数据库)(create/drop(alert))
MySQL
- MySQL是关系型数据库管理系统,用到的操作指令就是SQL指令。
- MySQL是一种C/S结构:客户端和服务端
1. 命令行开启服务
开启 net start MySQL80(我安装的是mysql server 8.0)
暂停net stop MySQL80
2. 建立连接mysql服务器
基本语法:Myssql.exe/mysql -h[IP地址/域名] -P 端口号 -u 用户名 -p 密码
-h——host,服务器地址,默认:本地主机上127.0.01/localhost
-P——port,服务器中Mysql监听的端口:默认是3306
所以可以省略,-p也可以先不行,再用密文方式输入密码
3. 退出
断开与服务器的连接:exit;、\q、Quit
4. Mysql服务端架构
DBMS(数据库管理系统):专门管理服务端的所有内容【如:MySQL、Oracle】(最外层)DB(数据库):专门用于存储数据的仓库,可有多个【如:财务数据库、人事数据库】(第二层)Table(二维数据表):专门用于存储具体实体的数据【如:员工表、工资表】(第三层)Field(字段):具体存储某种类型的数据【如:ID、姓名】(第四层)
简单来说,使用DBMS创建和管理DB,在数据库当中可以创建多个Table表来存放数据,每张表都有不同的Filed字段来定义该地方存储的数据类型
数据库基本操作
数据库是数据存储的最外层(最大单元),所有需要从外到内的接触到字段
1. 创建数据库
create database 数据库名字 [库选项]
库选项:数据库相关属性 charset字符集/collate校对集
charset字符集——代表当前数据库下所有表存储数据的默认的字符集(DBMS默认的)
如格式:create database 数据库名字 charset gbk;
2. 显示数据库
show databases;查看所有show create database 数据库名字;查看某个创建的数据库show databases like '匹配模式';显示部分
_:匹配当前位置单个字符
%:匹配指定位置多个字符
例如:显示my开头的全部数据库:show databases like 'my%';
显示某个不确定如m后面一个字符不确定:show databases like 'm_databases';
3. 选择数据库
数据存储在数据表里,表存储在数据库下,操作数据就需要选择某个数据库
use 数据库名;选择使用的数据库
4. 修改数据库
只能修改数据库字符集(库选项):字符集和校对集
alter database 数据库名字 charset = 字符集;等号可写可不写
5. 删除数据库
drop database 数据库名字;单个删除
数据表操作
1. 创建
create table 表名 (字段名 字段类型[字段属性],字段名 字段类型[字段属性]) [表选项];
create table student( name varchar(10));
注意:创建数据表是在数据库下
数据表如何挂到数据库上 :数据库.数据表
create table mydatabase.student(name varchar(10));
或者在create前使用数据库:use 数据库名;
表选项:与数据库使用一样
Engine:存储引擎,mysql提供的具体存储数据的方式(默认innobd)
charset:字符集,只对当前创建的表有效(级别高于数据库)
collate:校对集
2. 复制表的结构
create table 新表名 like 表名;只复制表的结构,不复制其中的数据
当需要将其他数据库的表复制到不同的数据库下的表,使用
数据库.数据表
mysql> use test;
Database changed
mysql> create table teacher(name varchar(10)) charset utf8;
Query OK, 0 rows affected, 1 warning (0.04 sec)
mysql> use mydatabase;
Database changed
mysql> create table teacher like test.teacher;
Query OK, 0 rows affected (0.04 sec)
3. 显示数据表
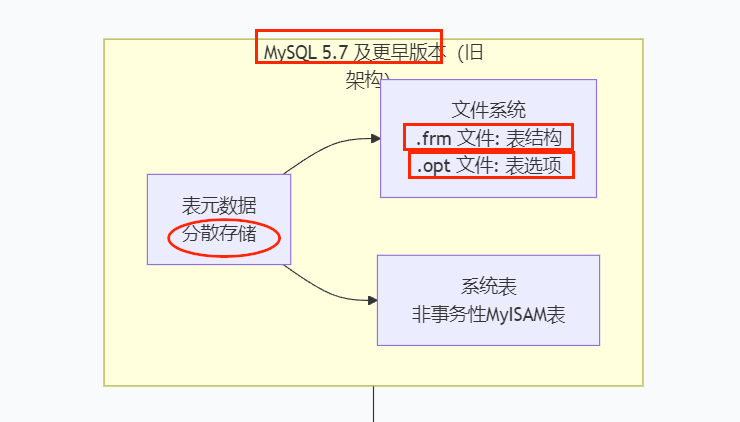
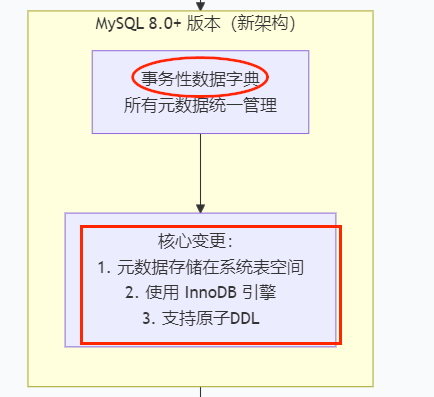
- 原子性 DDL (Atomic DDL)
旧问题:在 5.7 中,执行一个 DROP TABLE 操作,服务器需要删除 .frm 文件、.ibd 文件,还要更新 mysql 数据库中的系统表。如果在这个过程中服务器崩溃,可能会导致元数据不一致(例如,系统表里记录表不存在了,但 .frm 文件还在)。
新方案:在 8.0 中,DDL 操作(如 CREATE, ALTER, DROP) 被封装成一个原子事务。要么全部成功,要么全部失败回滚。服务器崩溃后重启,数据字典会自动恢复到一致的状态,极大地增强了数据库的崩溃安全性和可靠性。- 统一性和一致性
所有元数据存储在一个地方(数据字典表),管理更简单,避免了分散存储可能带来的不一致问题。- 性能提升
直接访问 InnoDB 表来获取元数据信息,比解析 .frm 文件更快。信息缓存也变得更高效。- 增强的安全性和可管理性
系统表被隐藏和保护起来,用户无法直接像操作普通表一样去修改 mysql 系统库中的底层表,降低了误操作的风险。
show tables;显示所有show tables like '匹配模式';部分显示(和数据库一致)、show create table 表名;查看创建表的语句
显示某个表的结构:
describe 表名;或者desc 表名;show columns from 表名;
Field:字段名 type:字段类型 Null:值是否允许为空
Key:索引 Default:默认值 Extra:额外属性
mysql> desc student;
+-------+-------------+------+-----+-------- -+-------+
| Field | Type | Null | Key | Default | Extra |
+-------+-------------+------+-----+---------+-------+
| name | varchar(10) | YES | | NULL | |
+-------+-------------+------+-----+---------+-------+
1 row in set (0.00 sec)
mysql> show columns from student;
+-------+-------------+------+-----+---------+-------+
| Field | Type | Null | Key | Default | Extra |
+-------+-------------+------+-----+---------+-------+
| name | varchar(10) | YES | | NULL | |
+-------+-------------+------+-----+---------+-------+
1 row in set (0.00 sec)
语句结束标识:
;和\g字段在上排横着显示,结果在下
\G字段在左侧竖着显示,结果在右侧,显示更加直观
4. 设置表的属性
alter table 表名 charset gbk;修改字符集
- 修改表的结构
rename table 表名 to 新表名;修改表名alter table 表名 add [column] 新字段名 列类型 [列属性] [位置first/after 字段名];新增字段alter table 表名 change 旧字段名 新字段名 字段类型 [列属性] [位置];修改字段名alter table 表名 modify 字段名 新类型 [新属性] [新位置];修改字段属性(类型)alert table 表名 drop 字段名;
注意:add/change/modify的操作不可以省略字段类型
- 删除表
drop table 表名 [表名2];删除表(可同时删除多个)
数据基础操作
1. 插入
将数据以SQL的形式存储到指定的数据表(字段)中
insert into 表名 [(字段列表)] values(字段值列表);可部分字段插入
字段列表和字段值列表必须对齐,而字段列表不需要包含表内所有字段,也不需要按照表内字段的顺序
mysql> insert into teacher (age) values(21);
Query OK, 1 row affected (0.02 sec)
mysql> insert into teacher (age,name) values(21,'stella');
Query OK, 1 row affected (0.01 sec)
insert into 表名 values (对应表结果);向表中所有字段插入数据(这里必须按照表的字段结构进行插入)
mysql> insert into teacher values('Karry',26);
Query OK, 1 row affected (0.01 sec)
desc teacher;命令显示的并不是表中的数据内容,而是表的结构定义(Schema Definition)。所以看不到数据的改变,需要通过select
2. 查询数据
select * from 表名;查看表中所有字段数据select 字段名 from 表名;查看部分字段select 字段名/* from 表名 where 字段名 = 值;简单条件查询
- 删除数据
- delete from 表名 [where 条件]
如果没有where 条件,则系统会自动删除表中所有数据
where name = ‘stella’ 会不顾大小写,name='Stella’也会删掉
3. 更新数据
- update 表名 set 字段名=新值 [where 条件];
字符集
1. 概念
- 字符:文字和符合的总称,计算机中所看到任何内容都是字符构成的
- 字符编码:字符对应的二进制码就叫做字符编码
- 字符集:多个字符的集合,对于不同字符的归类
2. 常见字符集
ASCII:美国标准交换码,英文字母、数字和控制符号
GB2312:中文
Unicode:这是一个全球通用的标准,它像一个巨大的表格,为世界上几乎所有语言的每个字符都分配了一个唯一的编号
BIG5:繁体字
GB8030:大符号
计算机需要通过字符集来进行字符编码,从而可以识别字符
MySQL 8.0 的默认字符集为utf8mb4
这是 MySQL 中对 Unicode 字符集的完整实现,支持所有 Unicode 字符,包括表情符号(如 😊)和许多不常见的汉字。在 MySQL 历史上,有一个名为 utf8 的字符集,但它最多只支持 3 个字节的编码,无法存储完整的 Unicode 字符(比如表情符号),实际上是一个“阉割版”。utf8mb4 才是真正意义上的 UTF-8。
因此可以直接插入中文字符,不需要额外set name 字符集
mysql> insert into student (name, age) values('小凯',26);
Query OK, 1 row affected (0.02 sec)
mysql> select name from student;
+------+
| name |
+------+
| 小凯 |
+------+
1 row in set (0.00 sec)
3. Mysql.exe与Mysqld.exe之间的处理关系
Mysql.exe与Mysqld.exe之间的处理关系分为三层:
客户端传入数据给服务端(client):character_set_client
服务端返回数据给客户端(server):character_set_server
服务端与客户端之间的连接(connection):character_set_connection
show variables like 'character_set%';查看系统保存的三种关系处理字符集
character_set_client | gbk -- 客户端发送的SQL语句使用GBK编码
character_set_connection | gbk -- 服务器处理SQL时使用GBK编码
character_set_database | utf8mb4 -- 当前数据库的默认字符集是UTF8MB4 ✅
character_set_server | utf8mb4 -- 服务器默认字符集是UTF8MB4 ✅
character_set_results | gbk -- 返回给客户端的结果使用GBK编码
MySQL会自动检测你的操作系统终端编码,并将连接字符集设置为匹配的编码。Windows命令行终端(CMD或PowerShell)正在使用 GBK 编码,MySQL客户端检测到了这一点并自动适配
MySQL会在底层自动进行编码转换:
你输入的中文(GBK)→ 存储时转换为UTF8MB4
查询出的中文(UTF8MB4)→ 返回时转换为GBK显示
字段类型
1. 整数类型
Tinyint(一个字节[8位11111111]) 、Smallint(两个字节保存)、Mediumint(三字节)、Int(四字节)、Bigint
注意:位数其中还包含负数,Tinyint可以放255位,但255放不进去,因为增加了负数,实际区间-128~127
mysql> create table my_int(int_1 tinyint,int_2 smallint,int_3 mediumint,int_4 int,int_5 bigint);
Query OK, 0 rows affected (0.06 sec)
mysql> insert into my_int values(10,10000,1000000,22074401,2207440115);
Query OK, 1 row affected (0.01 sec)
mysql> select * from my_int;
+-------+-------+---------+----------+------------+
| int_1 | int_2 | int_3 | int_4 | int_5 |
+-------+-------+---------+----------+------------+
| 10 | 10000 | 1000000 | 22074401 | 2207440115 |
+-------+-------+---------+----------+------------+
1 row in set (0.00 sec)
一般运用tinyint和int,偶尔用到bigint
无符号标识设定:unsigned ——表示存储的数据在当前字段中没有负数,只有整数(如 tinyint unsigned 时,可放255)
显示字段值的长度,如tinyint最长可显示四位,当存入数据1,它显示的还是1,如何自动满足到指定长度——字段增加zerofill属性
一旦添加zerofill属性则会自动加上unsigned属性,因为zerofill是从左侧添加0(不会改变数值大小),但如果是负数就不能使用zerofill
2. 小数类型
在MySQL中将小数类型分为浮点型和定点型
- 浮点型:
又称精度类型,是一种可能丢失精度的数据类型,尤其是在超出范围时可能不那么准确
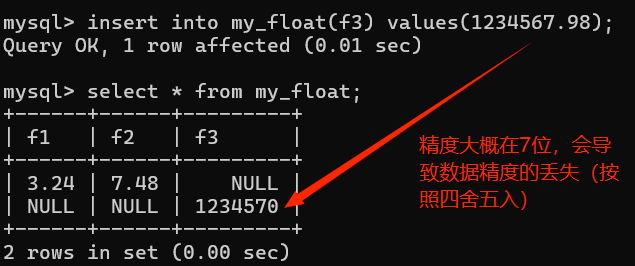
Float:又称单精度类型,系统提供4个字节来存储数据。保证大概7个左右的精度(7位数)
基本语法:
Float:表示不知道小数位的浮点数
Float(M,D):表示一共存储M位有效数字,其中小数部分站D位
mysql> create table my_float(f1 float, f2 float(5,2));
Query OK, 0 rows affected, 1 warning (0.06 sec)
mysql> desc my_float;
+-------+------------+------+-----+---------+-------+
| Field | Type | Null | Key | Default | Extra |
+-------+------------+------+-----+---------+-------+
| f1 | float | YES | | NULL | |
| f2 | float(5,2) | YES | | NULL | |
+-------+------------+------+-----+---------+-------+
2 rows in set (0.01 sec)
mysql> insert into my_float values(3.24,7.483);
Query OK, 1 row affected (0.02 sec)
mysql> select * from my_float;
+------+------+
| f1 | f2 |
+------+------+
| 3.24 | 7.48 |
+------+------+
1 row in set (0.00 sec)
-
Double:又称双精度,8个字节存储数据,精度有15位左右 -
Decimal(定点数:能够保证整数部分一定精确,小数部分超出长度会四舍五入
Decimal定点数,系统自动根据存储的数据来分配存储空间,每大概9个数会分配四个字节进行存储,同时小数和整数部分是分开的。
基本语法:
Decimal(M,D):M表示总长度(最大不超过65),D表示小数部分长度(不超过30)
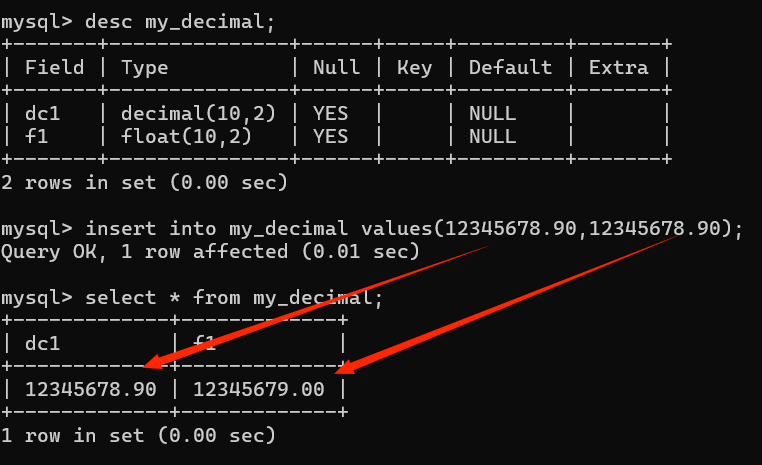
定点数如果是因为整数部分进位超出长度会
报错!
定点数的应用:涉及金钱会使用
时间日期类型
1. Date
日期类型:系统使用三个字节来存储数据
对应的格式为:YYYY-mm-dd,范围(1000-01-01~9999-12-12),初始值:0000-00-00
2. Time
时间类型:能够表示某个指定时间,同样3个字节存储,
对应格式:HH:ii:ss,(mysql中的time类型能够表示时间范围(-838:59:59~838:59:59),具体用来描述时间段)
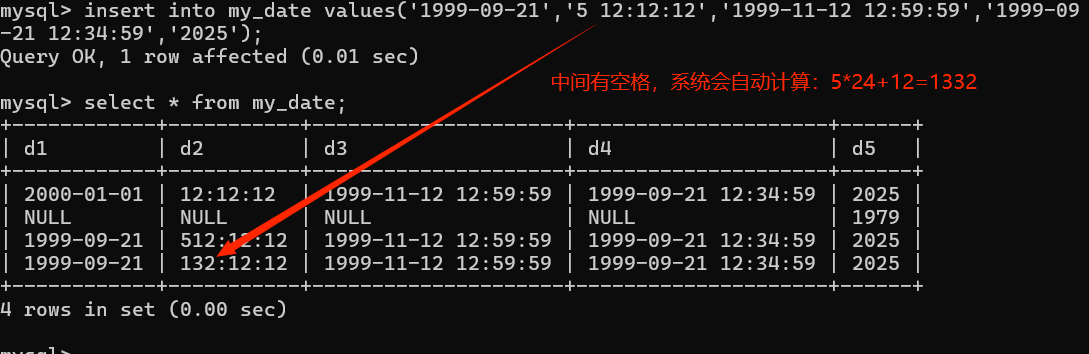
5作为天数*24小时,加上后面的时间
3. DateTime
**日期时间类型:**结合上面两个,使用八个字节存储
格式:YYYY-mm-dd HH:ii:ss 范围(1000-01-01 00:00:00~9999-12-12 23:59:59)
4. Timestamp
时间戳类型:表示从格林威治事件开始
格式:YYYY-mm-dd HH:ii:ss
5. Year
年类型:占用一个字节,能表示1900~2155年
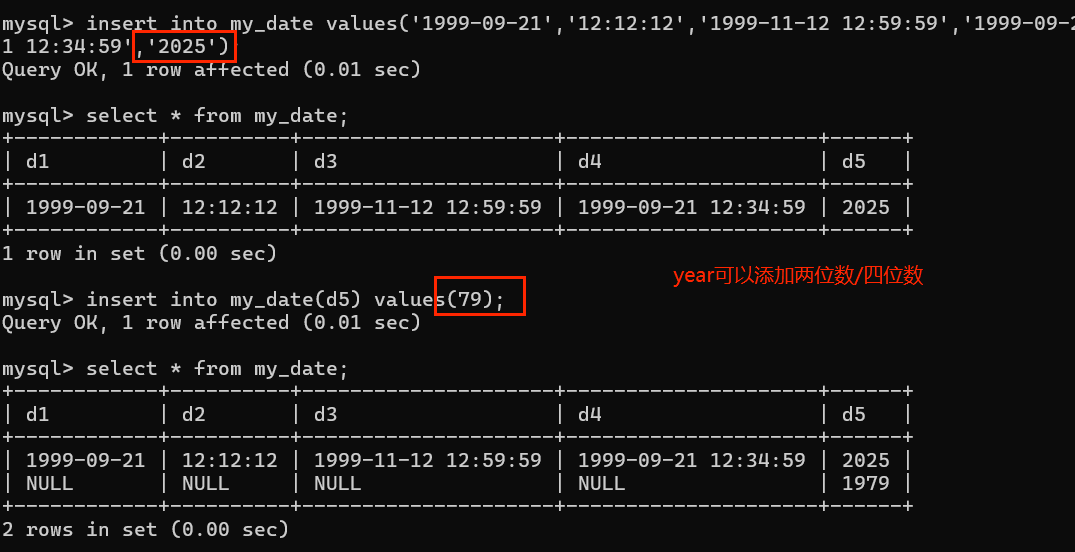
两种数据插入方式:0~99和四位数的具体年
两位数划分:数字<=69——匹配20+数字
数字>69——匹配**19+**数字
1) 创建对应的时间日期类型的数据表
字符串型
1. char
定长字符:指定长度之后,系统一定会分配指定的空间
基本语法:char(L),L表示字符数(中文和英文字母一样),L(0~255)
2. varchar
变长字符:指定长度之后,系统还是会根据实际存储的数据来计算长度,分配合适长度
基本语法:varchar(L),L表示字符数,L(0~65535)
varchar需要记录数据长度(系统根据长度自动分配空间),所以每个varchar数据产生后,系统都会在数据后面增加1-2个字节的空间来保存数据占空间的长度
(数据<127字符,额外增加一个字节空间;>127则增加两个)
- char 和varchar对比
1)char一定会使用指定的空间,即使没有用到;varchar是根据数据来定空间
2)char的数据查询效率比varchar高;varchar是需要通过后面的记录数来计算
如果确定数据长度,使用char,否则使用varchar类型
如果数据超过225个字符,则不论怎样都使用text
3. text 文本类型
-
mysql提供两种文本类型:
Text:存储普通的字符文本
Blob:存储二进制文本(图片/文件)【一般不会存储文件本身,而是通过一个链接来指向文件】 -
文本类型:
tinytext:实际能够存储255字符
text:64KB
mediumtext:16MB
longtext:4GB
注意:
- 一般之间使用
Text,因为系统会自动根据存储的数据长度来选择合适的文本类型- 选择字符存储,如果数据超过255个字符,选择text存储
4. Enum 枚举类型
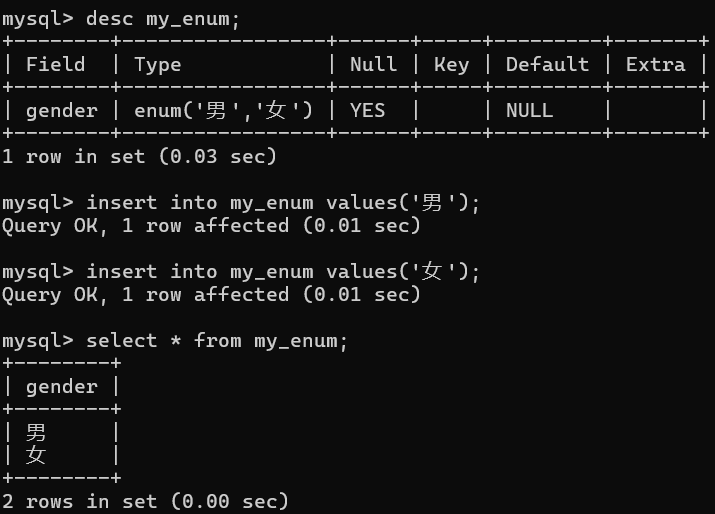
在数据插入之前,先设定几个项,这几个项就是可能最终出现的数据结果。
如果确定某个字段的数据只有那么几个值:如性别(男、女、保密),系统就可以在设定字段的时候规定当前字段只能存放固定的几个值,使用枚举
- 基本语法:
enum('选项1', '选项2'……)
- 存储原理:
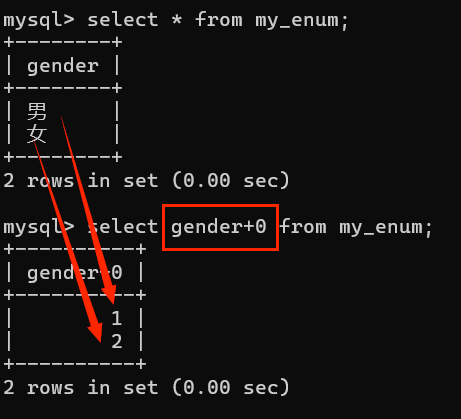
实际上字段上所存储的值并不是真正的字符串,而是存储字符串对应的下标
(当系统设定枚举类型的时候,会给枚举中每个元素定义一个下标,这个下标规则从1开始)【如:enum(1=>'男', 2=>'女')即1代表男,2代表女】
特性:在mysql中系统是自动进行类型转换的,如果碰到
+、-、*、/,系统就会将数据转换为数值,而普通字符串转会为数值为0
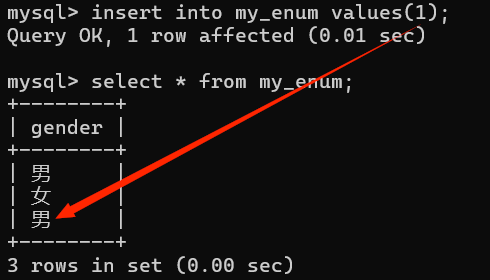
- 既然实际enum存储的结果是数值,那么就可以使用对应的数值来插入数据!
- 枚举的意义:
- 规范数据本身,限定只能插入规定的数据项
- 节省存储空间
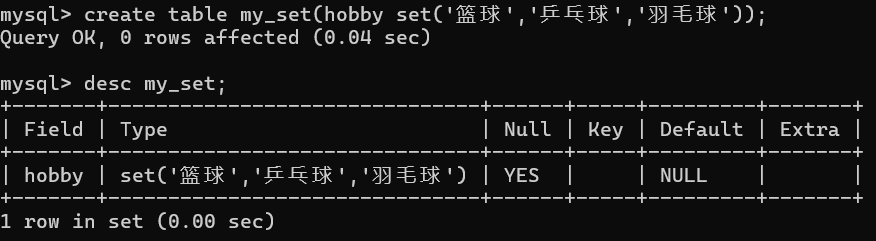
5. Set 集合类型
将多个数据选项可以同时保存的数据类型,本质是将指定的项按照对应的二进制位来进行控制,1表示该选项被选中,0则未选中。【一般用于多选框】
- 基本语法 :
set('值1', '值2', '值3'……)
系统位set提供了多个字节进行保存,但是系统会自动计算来选择具体的存储单元
1 字节——set只能有8个选项
2 字节——set只能有16个选项
3 字节——set只能有24个选项
4 字节——set只能有64个选项(最多64个)
Set 和 enum一样,最终存储到数据字段中的依旧是数字,而不是字符串。
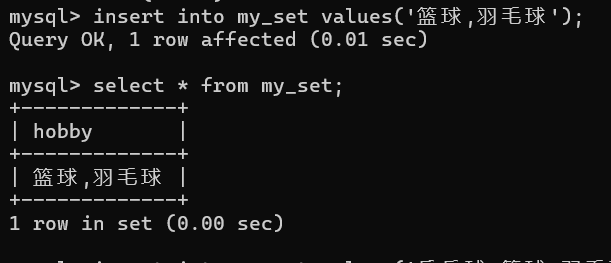
多个选项用逗号隔开,插入顺序无所谓,最终系统都会变成选项对应的顺序
-
数据存储的方式
被选中的对应值为1,否则为0,生成二进制数,对应数据选项
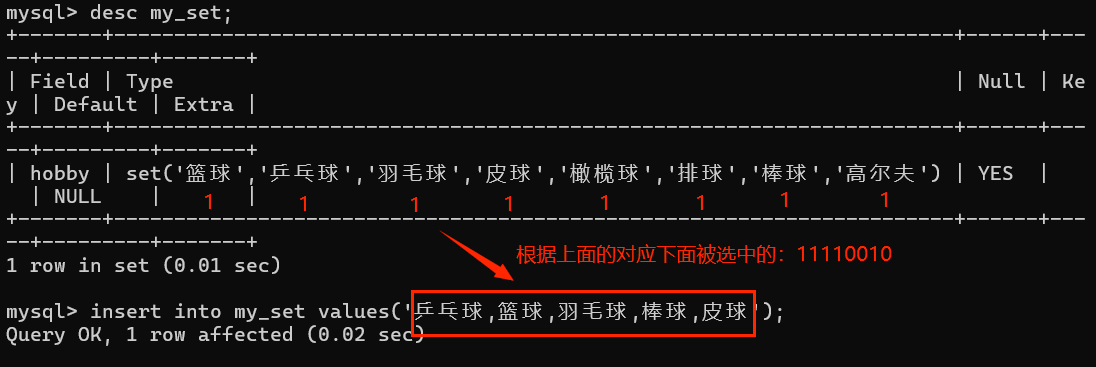
-
系统在进行存储的时候会自动将得到的最终的二进制颠倒过来,然后再进行转换成十进制存储。
如:图上11110010变成01001111====1+2+4+8+64=79
Why? 因为此例子为八位,若只有七位,那最后一位永远为0(系统要补足八位)。因此需要颠倒过来才符合,不然会很大 -
查看数据:
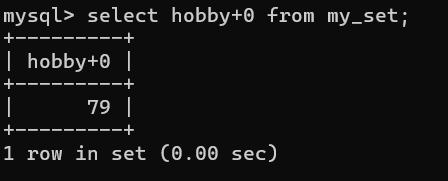
如果想要所有选项,则可以通过数值(255)
实际上不会有,有时选项没有八位
- 意义:
- 规范数据;2. 存储节省空间
字段属性(列属性)
在mysql中一共有6个属性:Null,默认值,列描述,主键,唯一键,自动增长
-
Null属性:代表字段为空(默认允许)
NOT Null表示不允许为空,插入元素时必须插入该字段数据
显示对应值为YES:表示该字段可以为空(系统会保留一个字节来存储NULL) -
Default 默认值
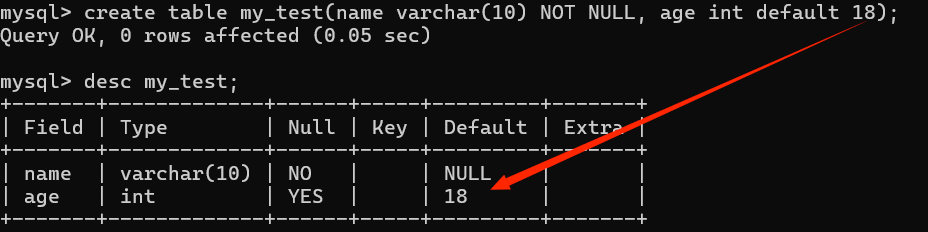
Default关键字另一种使用:在进行数据插入的时候,字段值直接使用default
如:insert into my_test values('Jack', default);就会使用默认年纪18 -
comment 列描述
专门用于给开发人员进行维护的一个注释说明
基本语法:comment '字段描述'
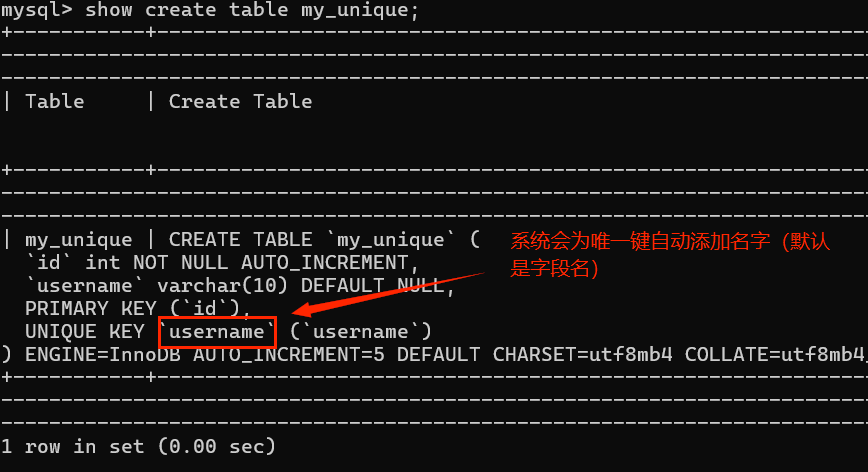
**查看comment** : `show create table 表名;`
4. primary key 主键
一张表有且只能有一个主键约束,但这个主键可以由一个或多个字段组成
-
创建主键:
- 随表创建:
字段名 primary key
primary key(字段名) - 表后创建:
alter table 表名 add primary key(字段名);
- 随表创建:
-
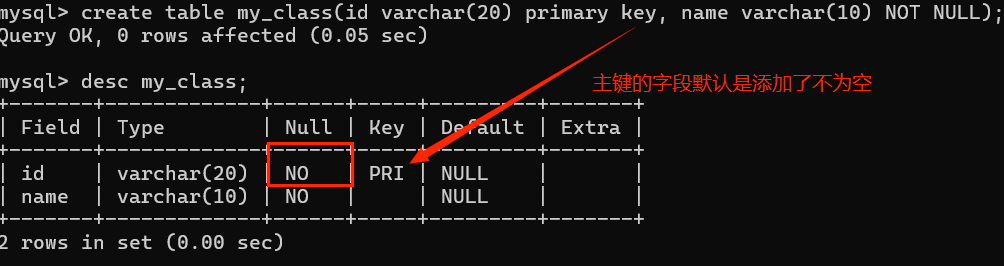
查看
-
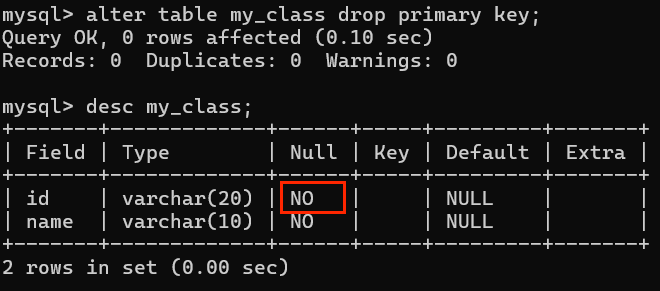
删除主键:
alter table 表名 drop primary key;
-
复合主键
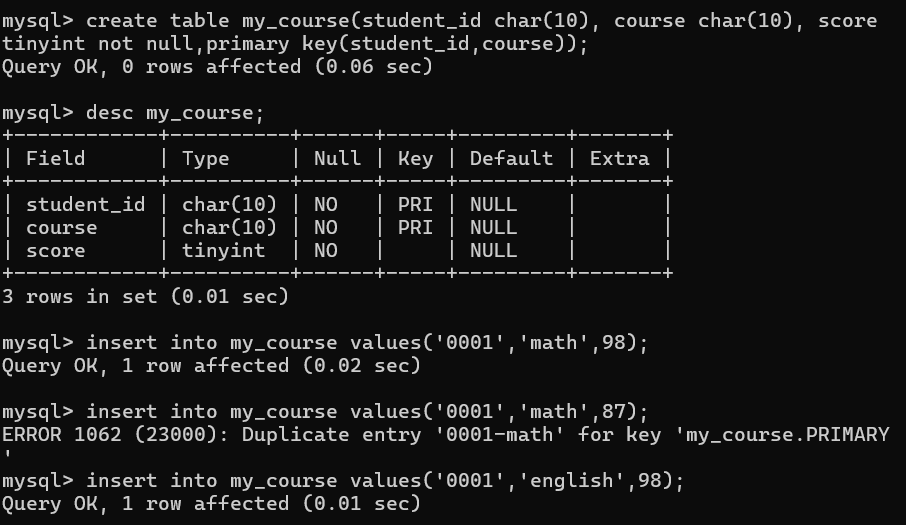
案例:一张学生选课表,一个学生可以选择多个选修课,一个选修课可以由多名学生选择,但一个学生在一个选修课中只有一个成绩
create table my_course(student_id char(10), course char(10), score tinyint not null);
但是出现问题,插入数据时,同一门课course,可以插入不同成绩score。
添加primary key(studnet_id, course),实现两者共同唯一
-
主键约束
1) 数据不为空 2)不能重复 -
主键分类
对应字段的业务意义分类:①业务主键:具有业务意义(ID);②逻辑主键:自然增长的整型(应用广泛),保证数据唯一性
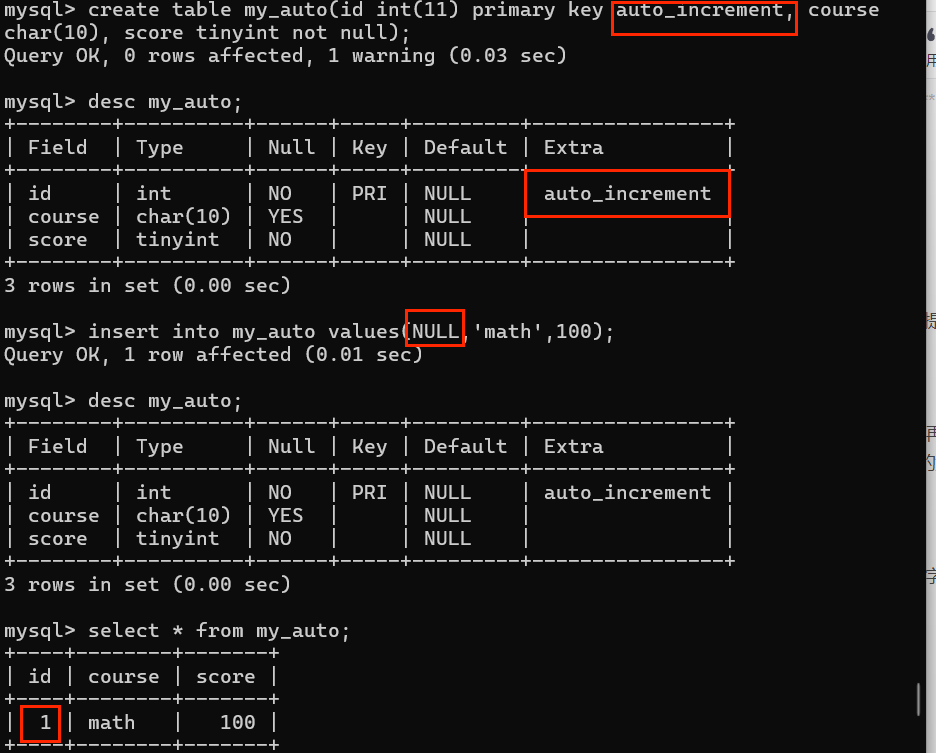
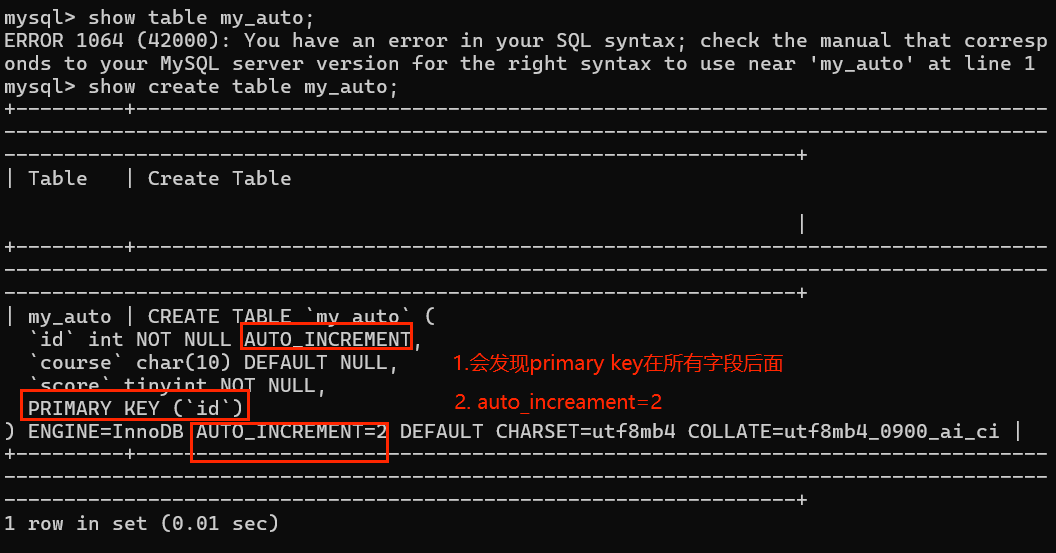
5. 自动增长 auto_increment
当给定字段该属性之后,该列的数据在没有提供数据时,根据之前存在数据进行自动增加并填充。【通常用于逻辑主键】
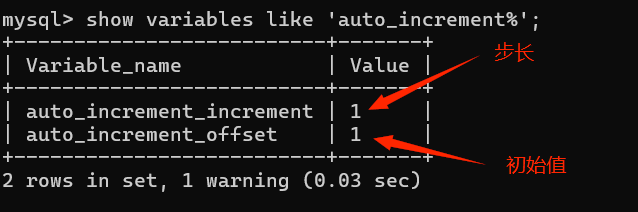
- 原理
系统保存自动增长数据的字段的数据值,再给定一个指定步长
当插入数据没有给定值NULL(自动增长的触发),在原始基础上加上步长
(注意:只适用于数值)
- 可以修改auto_increment:
alter table 表名 auto_increment = 数值; - 删除自增长:
alter table 表名 modify 字段 字段类型;不需要添加primary key,不影响的,primary key已经存在 - 添加自增长:
alter table 表名 modify 字段 字段类型 auto_increment; - 查看自增长初始变量:
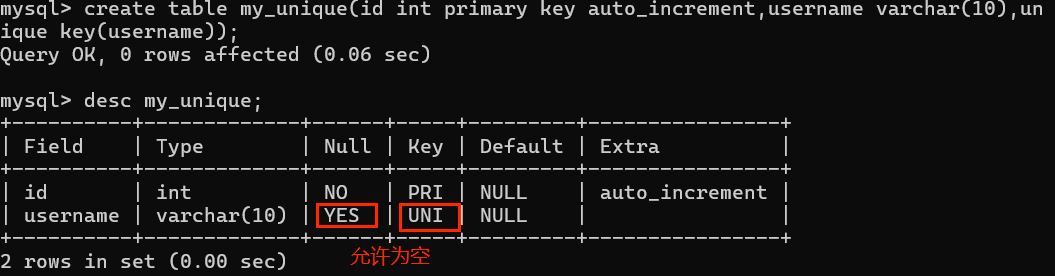
6. 唯一键 unique key
来确保对应的字段中的数据唯一的
-
特点:
1. 唯一键在一张表中可以有多个
2. 唯一键允许字段数据为NULL,NULL可以有多个(NULL不参与比较) -
创建唯一键 :
1. 表字段后:字段 unique [key]
2. 在所有字段后面使用:unique key(字段列表)
3. 创建完表之后也可以增加唯一键:alter table 表名 add unique key(字段)
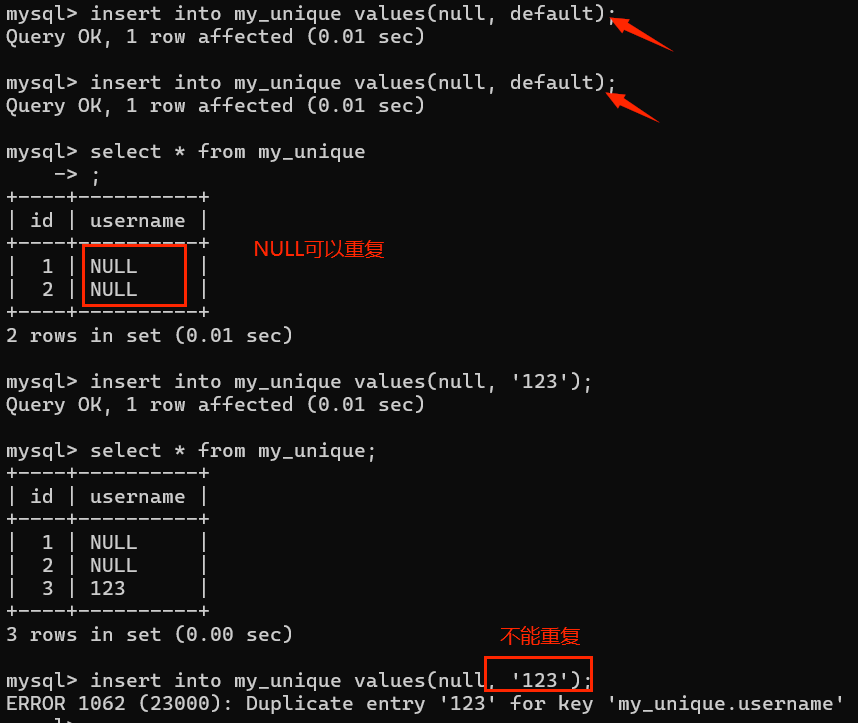
- 查看唯一键
- 删除唯一键
一个表中允许有多个唯一键,alter table 表名 drop unique key;就不对,系统无法确认删哪个
index关键字:表示索引。而唯一键是索引的一种(提升查询效率)
删除语法:alter table 表名 drop index 唯一键名字;
- 复合唯一键
唯一键与主键一样可以使用多个字段来共同保证唯一性
一般主键都是单一字段(逻辑主键),而其他需要唯一性的内容都是由唯一键来处理。
表关系
-
一对一 :一张表中的一条记录与另一张表中最多有一条明确的关系。通常【保证两张表中使用同样的主键即可】
-
一对多:或者多对一。【在‘多’关系的表中去维护一个字段,这个字段是‘一’关系的主键】

在’多‘表孩子表里面维护‘唯一’母亲表的关系
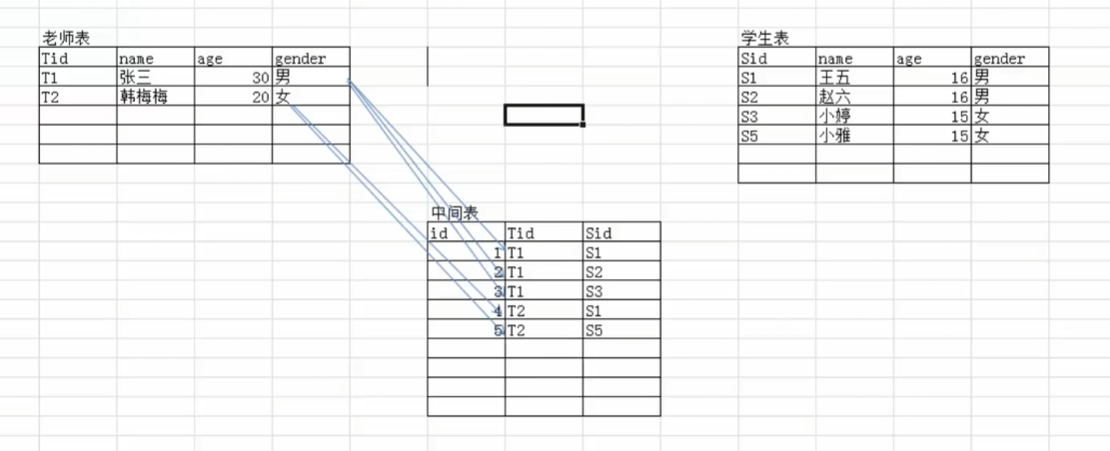
- 多对多:一张表中有多条记录,在另外一张也可以匹配多条,反过来也一样。
【通过第三张表解决】



















 5533
5533

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









