




 本文介绍了在Python爬虫中遇到的乱码问题及其解决方案,使用requests库发送HTTP请求时设置encoding。同时,提供了Python爬虫的入门学习大纲,包括基础知识、数据解析、存储方法和进阶技巧等内容,以及一份全面的学习资料链接。
本文介绍了在Python爬虫中遇到的乱码问题及其解决方案,使用requests库发送HTTP请求时设置encoding。同时,提供了Python爬虫的入门学习大纲,包括基础知识、数据解析、存储方法和进阶技巧等内容,以及一份全面的学习资料链接。
运行结果如下图所示,第一个print显示乱码,加入encoding之后再print正常显示
 #返回html信息的二进制(bytes)类型,response.content
#返回html信息的二进制(bytes)类型,response.content
print(response.content)
输出如下内容: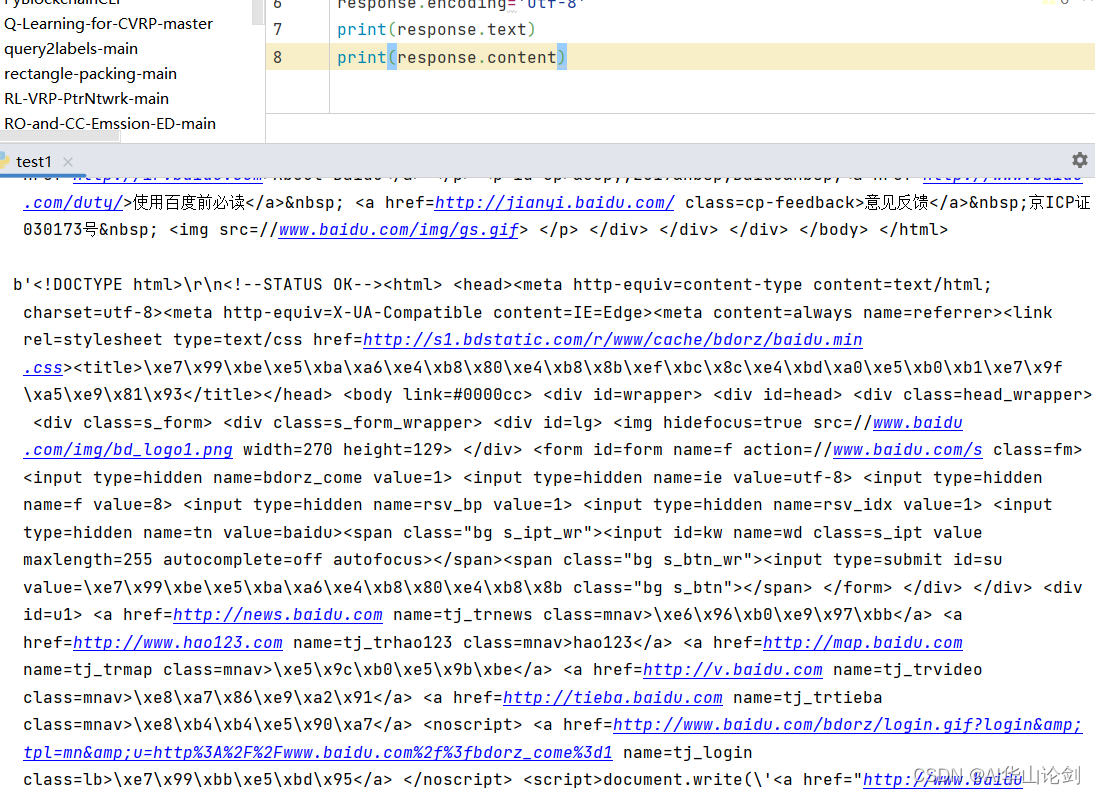 最后一步保存到文件系统
最后一步保存到文件系统
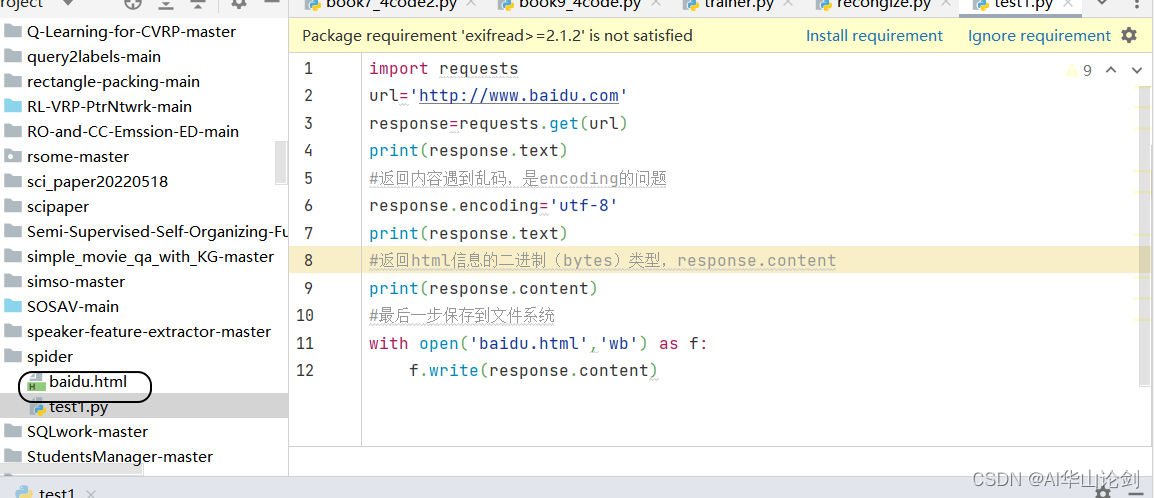
得到所想要的网站html文件。
完整代码如下:
import requests
url='http://www.baidu.com'
response=requests.get(url)
print(response.text)
#返回内容遇到乱码,是encoding的问题
response.encoding='utf-8'
print(response.text)
#返回html信息的二进制(bytes)类型,response.content
print(response.content)
#最后一步保存到文件系统
with open('baidu.html','wb') as f:
f.write(response.content)
当学习Python爬虫时,以下是一个入门学习大纲供参考:
- 基础知识:
Python基础语法:学习Python的基本语法、变量、数据类型、流程控制、函数等基础知识。
HTML基础:了解HTML标签的基本结构和常见标签的使用。
HTTP协议:熟悉HTTP请求和响应的基本结构,了解HTTP的GET、POST等常用方法
- 网络请求:
requests库:学习如何使用Python中的requests库发送HTTP请求,并获取响应数据。
网络爬虫框架:了解Scrapy等常用的网络爬虫框架,学习如何使用框架进行数据爬取
- 数据解析和提取:
正则表达式:学习正则表达式的基本语法和用法,用于从HTML文本中提取所需信息。
BeautifulSoup库:掌握BeautifulSoup库的使用,用于解析HTML文档,并提供简单的数据提取方法。
XPath:了解XPath语法,学习使用XPath从HTML文档中提取数据。
- 数据存储:
文件存储:学习将爬取到的数据存储到本地文件中,如CSV、JSON等格式。
数据库存储:了解如何将爬取到的数据存储到数据库中,如MySQL、MongoDB等。
- 反爬虫和数据清洗:
反爬虫机制:学习常见的反爬虫机制,如User-Agent检测、验证码处理等。
数据清洗:了解数据清洗的基本方法,如去除HTML标签、去除重复数据等。
- 进阶技巧:
并发爬虫:学习如何使用多线程、协程等技术提高爬虫的效率。
动态网页爬取:了解如何处理使用JavaScript动态生成内容的网页。
IP代理和登录验证:了解如何使用IP代理和处理登录验证等问题。
- 伦理和法律问题:
自我介绍一下,小编13年上海交大毕业,曾经在小公司待过,也去过华为、OPPO等大厂,18年进入阿里一直到现在。
深知大多数Python工程师,想要提升技能,往往是自己摸索成长或者是报班学习,但对于培训机构动则几千的学费,着实压力不小。自己不成体系的自学效果低效又漫长,而且极易碰到天花板技术停滞不前!
因此收集整理了一份《2024年Python开发全套学习资料》,初衷也很简单,就是希望能够帮助到想自学提升又不知道该从何学起的朋友,同时减轻大家的负担。





既有适合小白学习的零基础资料,也有适合3年以上经验的小伙伴深入学习提升的进阶课程,基本涵盖了95%以上前端开发知识点,真正体系化!
由于文件比较大,这里只是将部分目录大纲截图出来,每个节点里面都包含大厂面经、学习笔记、源码讲义、实战项目、讲解视频,并且后续会持续更新
如果你觉得这些内容对你有帮助,可以扫码获取!!!(备注Python)
端开发知识点,真正体系化!**
由于文件比较大,这里只是将部分目录大纲截图出来,每个节点里面都包含大厂面经、学习笔记、源码讲义、实战项目、讲解视频,并且后续会持续更新
如果你觉得这些内容对你有帮助,可以扫码获取!!!(备注Python)



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









