







最后
Python崛起并且风靡,因为优点多、应用领域广、被大牛们认可。学习 Python 门槛很低,但它的晋级路线很多,通过它你能进入机器学习、数据挖掘、大数据,CS等更加高级的领域。Python可以做网络应用,可以做科学计算,数据分析,可以做网络爬虫,可以做机器学习、自然语言处理、可以写游戏、可以做桌面应用…Python可以做的很多,你需要学好基础,再选择明确的方向。这里给大家分享一份全套的 Python 学习资料,给那些想学习 Python 的小伙伴们一点帮助!
👉Python所有方向的学习路线👈
Python所有方向的技术点做的整理,形成各个领域的知识点汇总,它的用处就在于,你可以按照上面的知识点去找对应的学习资源,保证自己学得较为全面。

👉Python必备开发工具👈
工欲善其事必先利其器。学习Python常用的开发软件都在这里了,给大家节省了很多时间。

👉Python全套学习视频👈
我们在看视频学习的时候,不能光动眼动脑不动手,比较科学的学习方法是在理解之后运用它们,这时候练手项目就很适合了。

👉实战案例👈
学python就与学数学一样,是不能只看书不做题的,直接看步骤和答案会让人误以为自己全都掌握了,但是碰到生题的时候还是会一筹莫展。
因此在学习python的过程中一定要记得多动手写代码,教程只需要看一两遍即可。

👉大厂面试真题👈
我们学习Python必然是为了找到高薪的工作,下面这些面试题是来自阿里、腾讯、字节等一线互联网大厂最新的面试资料,并且有阿里大佬给出了权威的解答,刷完这一套面试资料相信大家都能找到满意的工作。

一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!
---
### 浏览器控制
#### 修改浏览器窗口大小
`webdriver` 提供 `set_window_size()` 方法来修改浏览器窗口的大小。
from selenium import webdriver
Chrome浏览器
driver = webdriver.Chrome()
driver.get(‘https://www.csdn.net/’)
设置浏览器浏览器的宽高为:600x800
driver.set_window_size(600, 800)
也可以使用 `maximize_window()` 方法可以实现浏览器全屏显示。
from selenium import webdriver
Chrome浏览器
driver = webdriver.Chrome()
driver.get(‘https://www.csdn.net/’)
设置浏览器浏览器的宽高为:600x800
driver.maximize_window()
#### 浏览器前进&后退
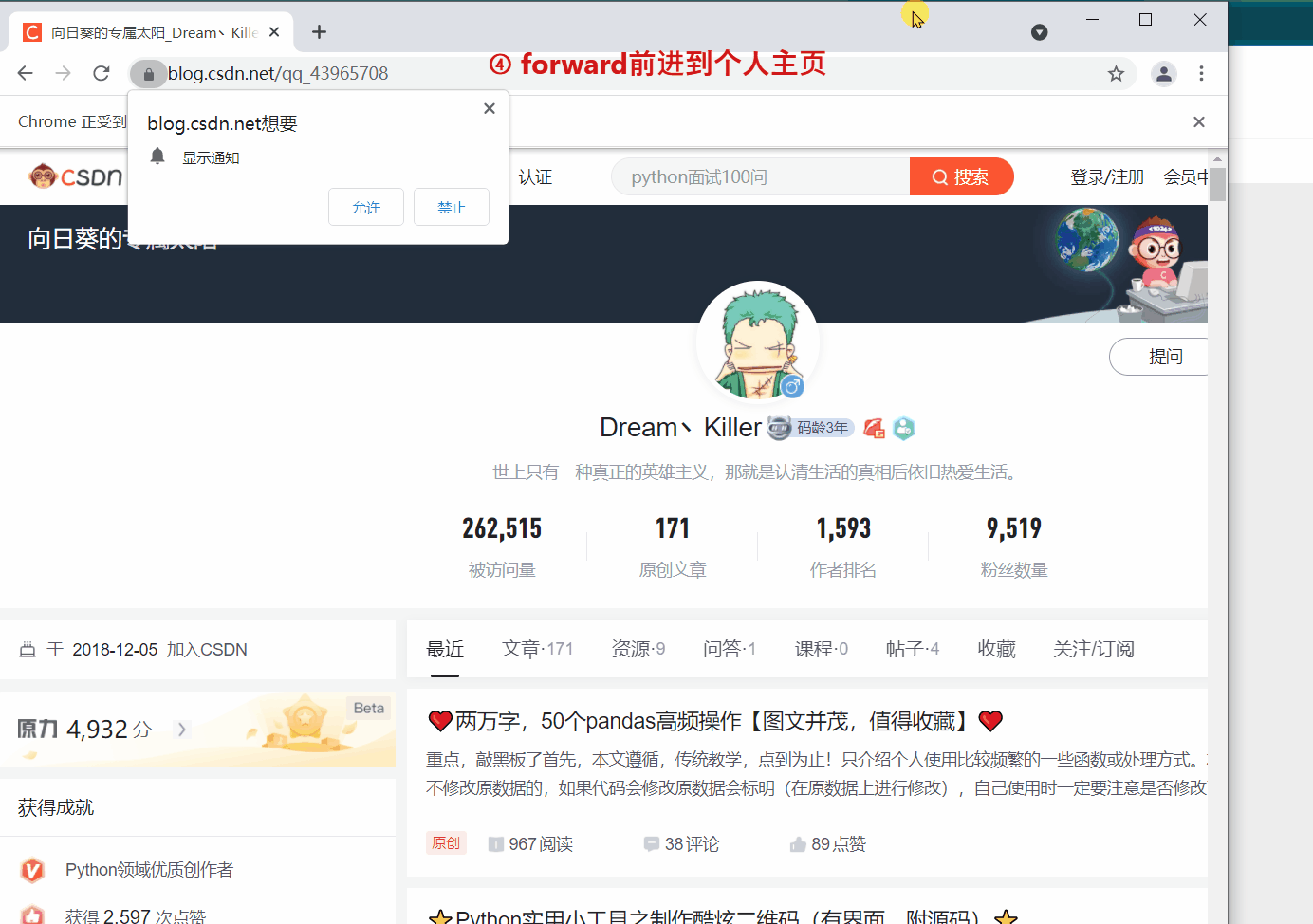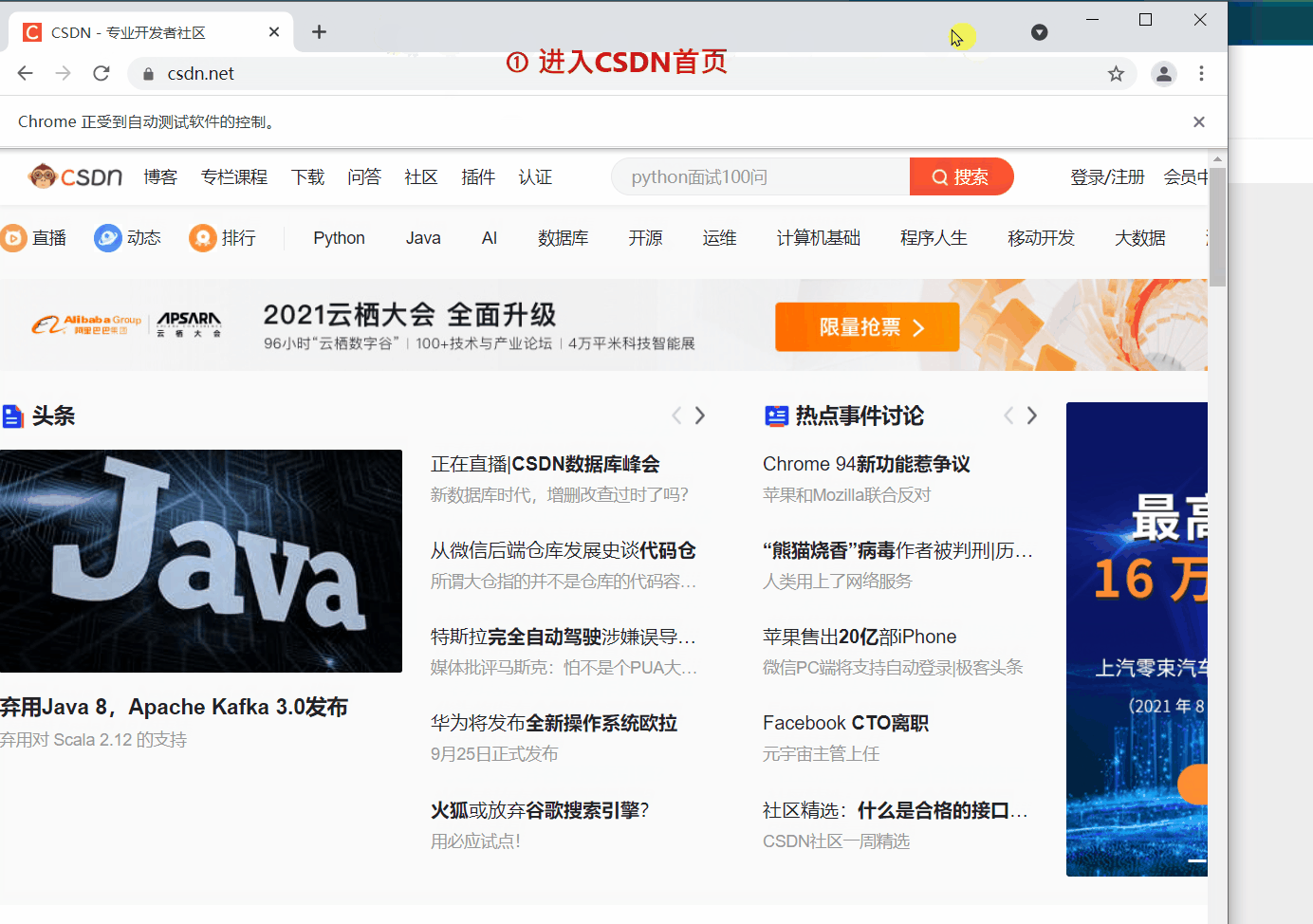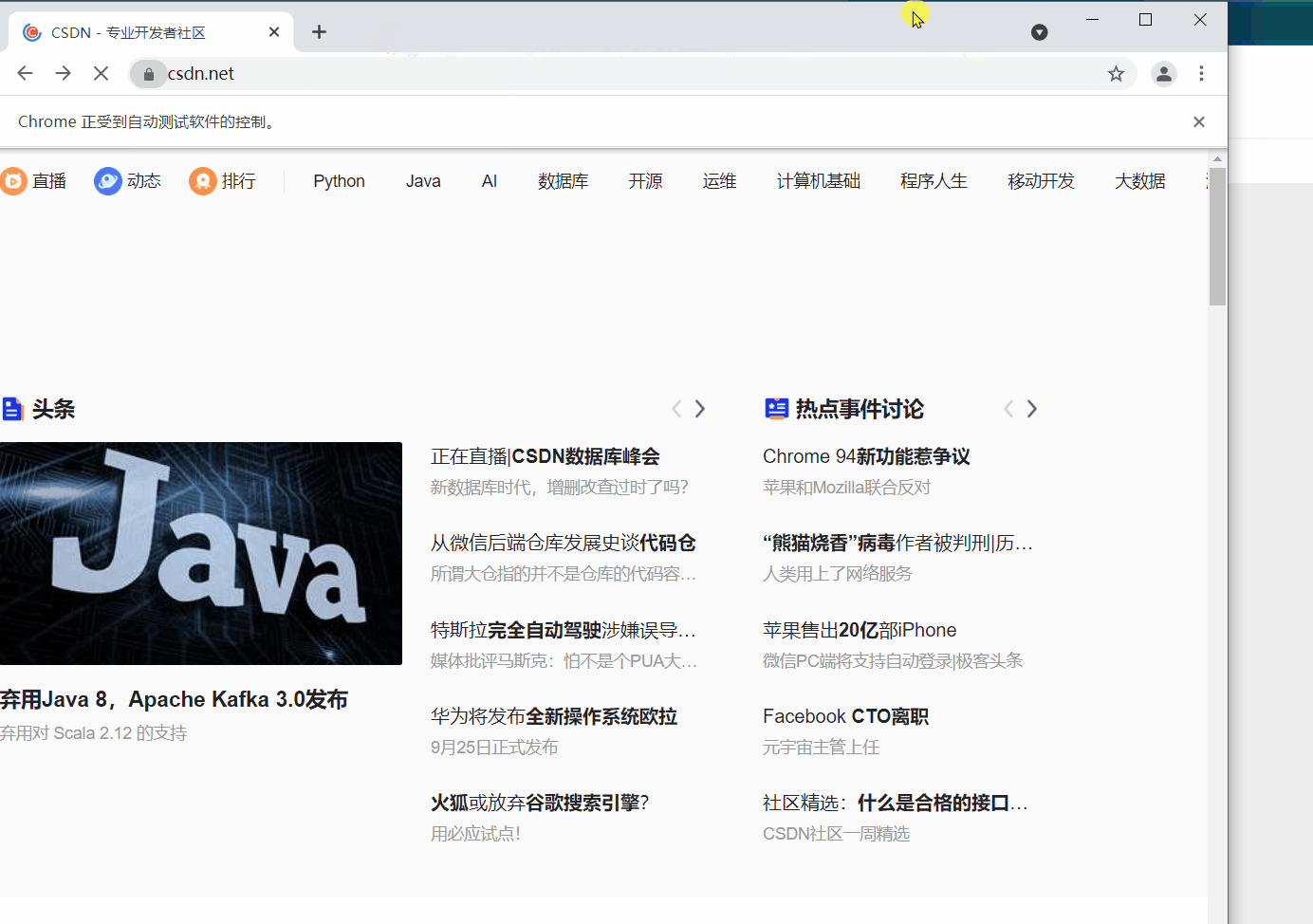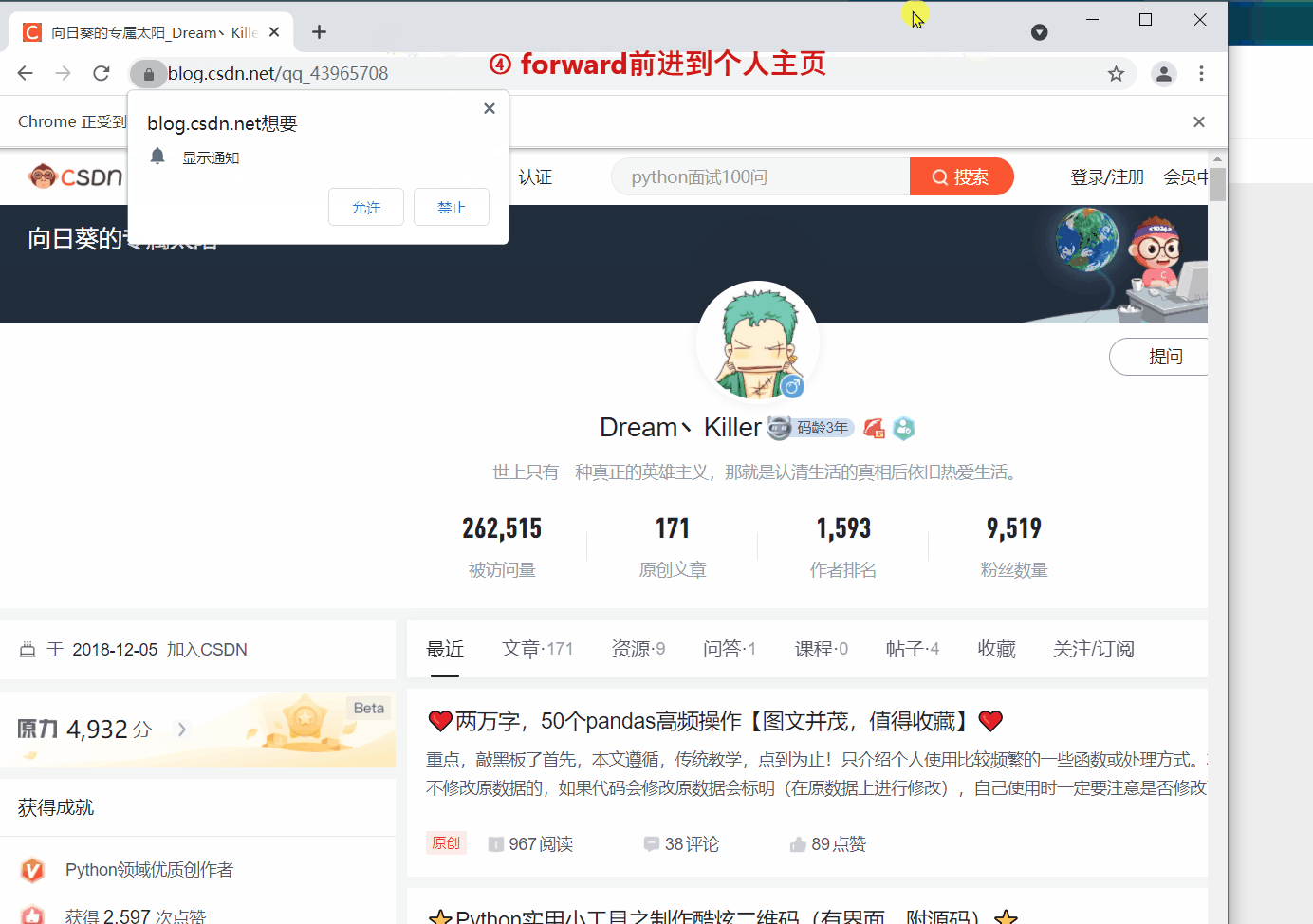
`webdriver` 提供 `back` 和 `forward` 方法来实现页面的后退与前进。下面我们 ①进入CSDN首页,②打开CSDN个人主页,③`back` 返回到CSDN首页,④ `forward` 前进到个人主页。
from selenium import webdriver
from time import sleep
driver = webdriver.Chrome()
访问CSDN首页
driver.get(‘https://www.csdn.net/’)
sleep(2)
#访问CSDN个人主页
driver.get(‘https://blog.csdn.net/qq_43965708’)
sleep(2)
#返回(后退)到CSDN首页
driver.back()
sleep(2)
#前进到个人主页
driver.forward()
细心的读者会发现第二次 `get()` 打开新页面时,会在原来的页面打开,而不是在新标签中打开。如果想的话也可以在新的标签页中打开新的链接,但需要更改一下代码,执行 `js` 语句来打开新的标签。
在原页面打开
driver.get(‘https://blog.csdn.net/qq_43965708’)
新标签中打开
js = “window.open(‘https://blog.csdn.net/qq_43965708’)”
driver.execute_script(js)
#### 浏览器刷新
在一些特殊情况下我们可能需要刷新页面来获取最新的页面数据,这时我们可以使用 `refresh()` 来刷新当前页面。
刷新页面
driver.refresh()
#### 浏览器窗口切换
在很多时候我们都需要用到窗口切换,比如:当我们点击注册按钮时,它一般会打开一个新的标签页,但实际上代码并没有切换到最新页面中,这时你如果要定位注册页面的标签就会发现定位不到,这时就需要将实际窗口切换到最新打开的那个窗口。我们先获取当前各个窗口的句柄,这些信息的保存顺序是按照**时间**来的,最新打开的窗口放在数组的**末尾**,这时我们就可以定位到最新打开的那个窗口了。
获取打开的多个窗口句柄
windows = driver.window_handles
切换到当前最新打开的窗口
driver.switch_to.window(windows[-1])
#### 常见操作
webdriver中的常见操作有:
| 方法 | 描述 |
| --- | --- |
| `send_keys()` | 模拟输入指定内容 |
| `clear()` | 清除文本内容 |
| `is_displayed()` | 判断该元素是否可见 |
| `get_attribute()` | 获取标签属性值 |
| `size` | 返回元素的尺寸 |
| `text` | 返回元素文本 |
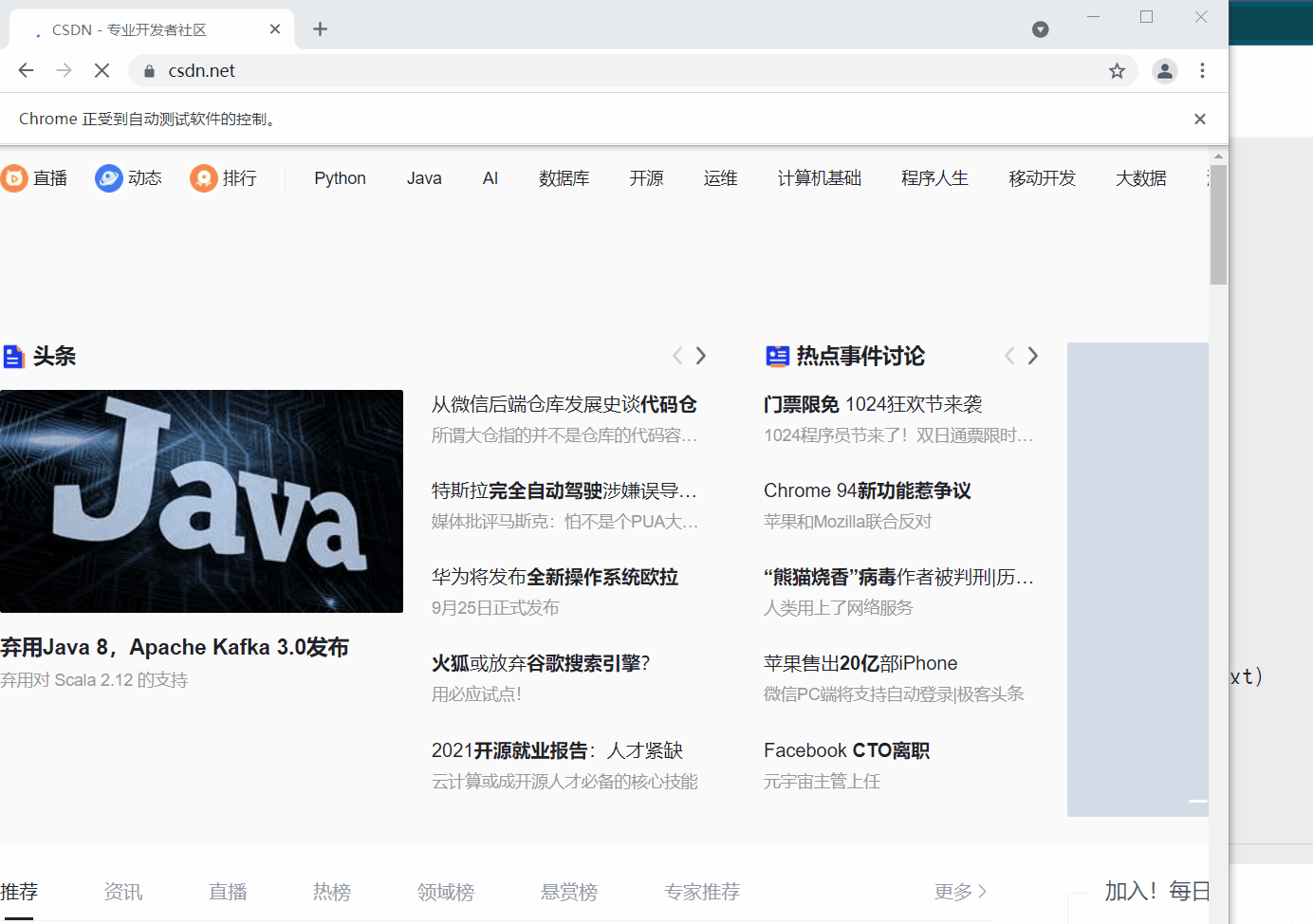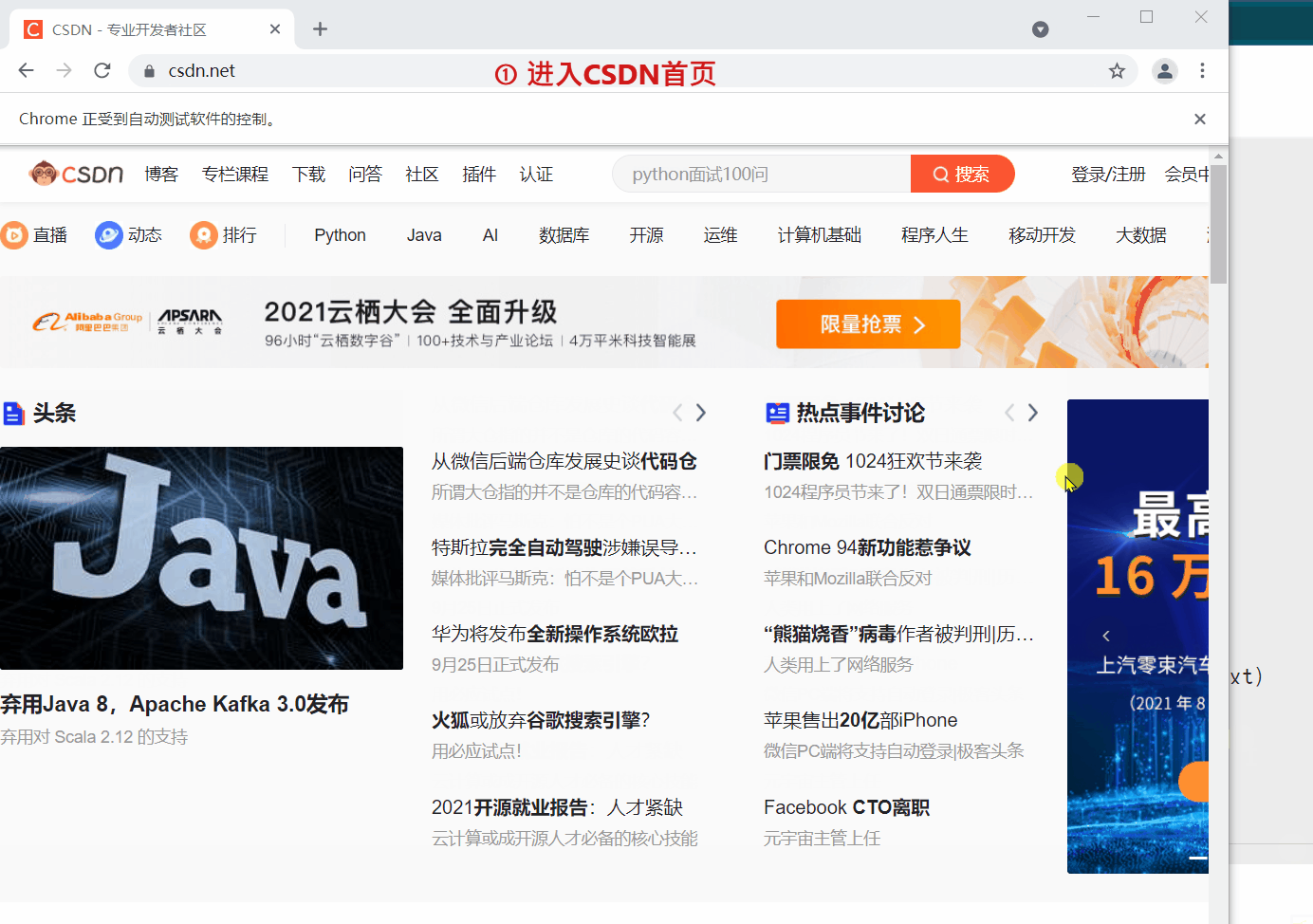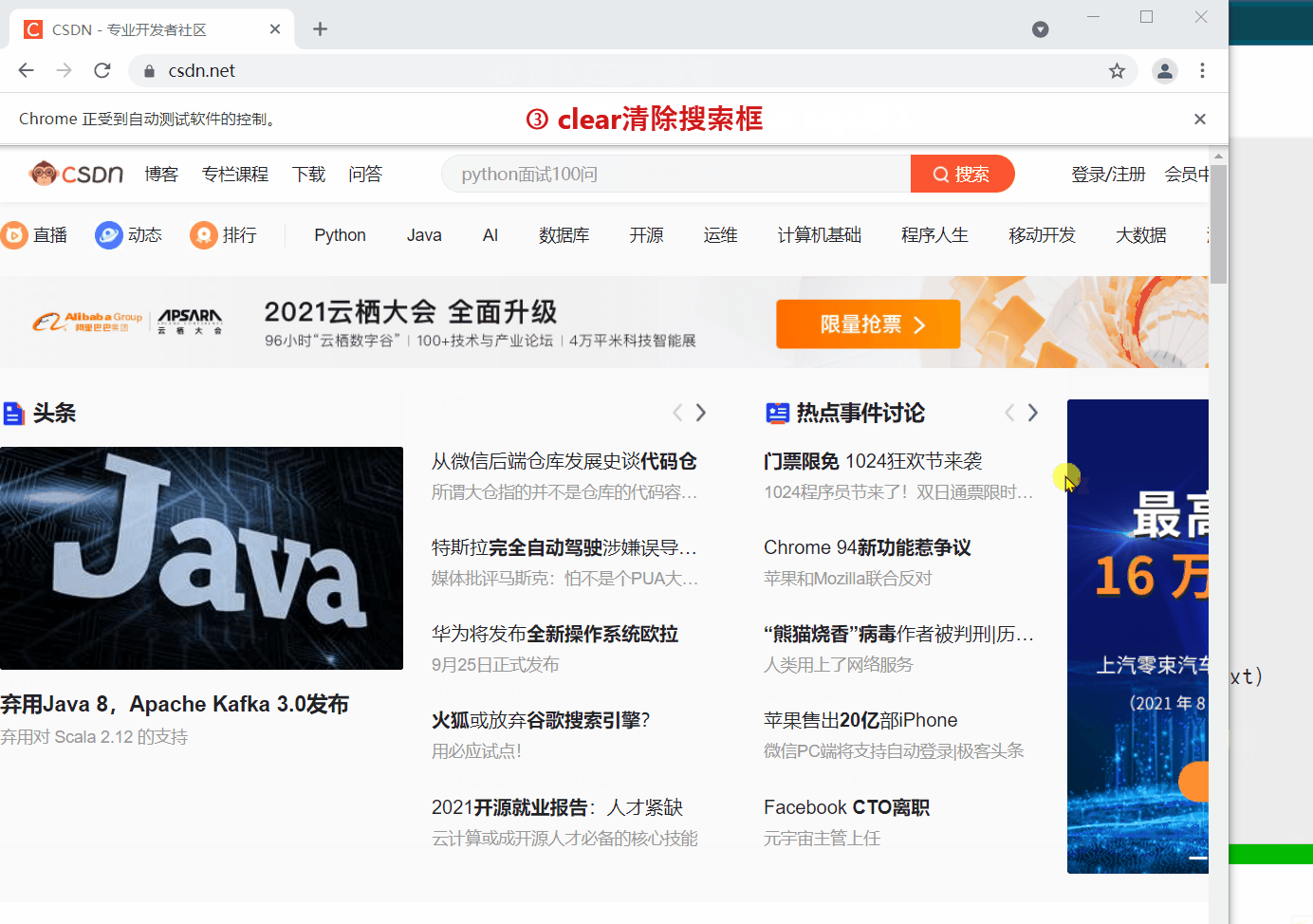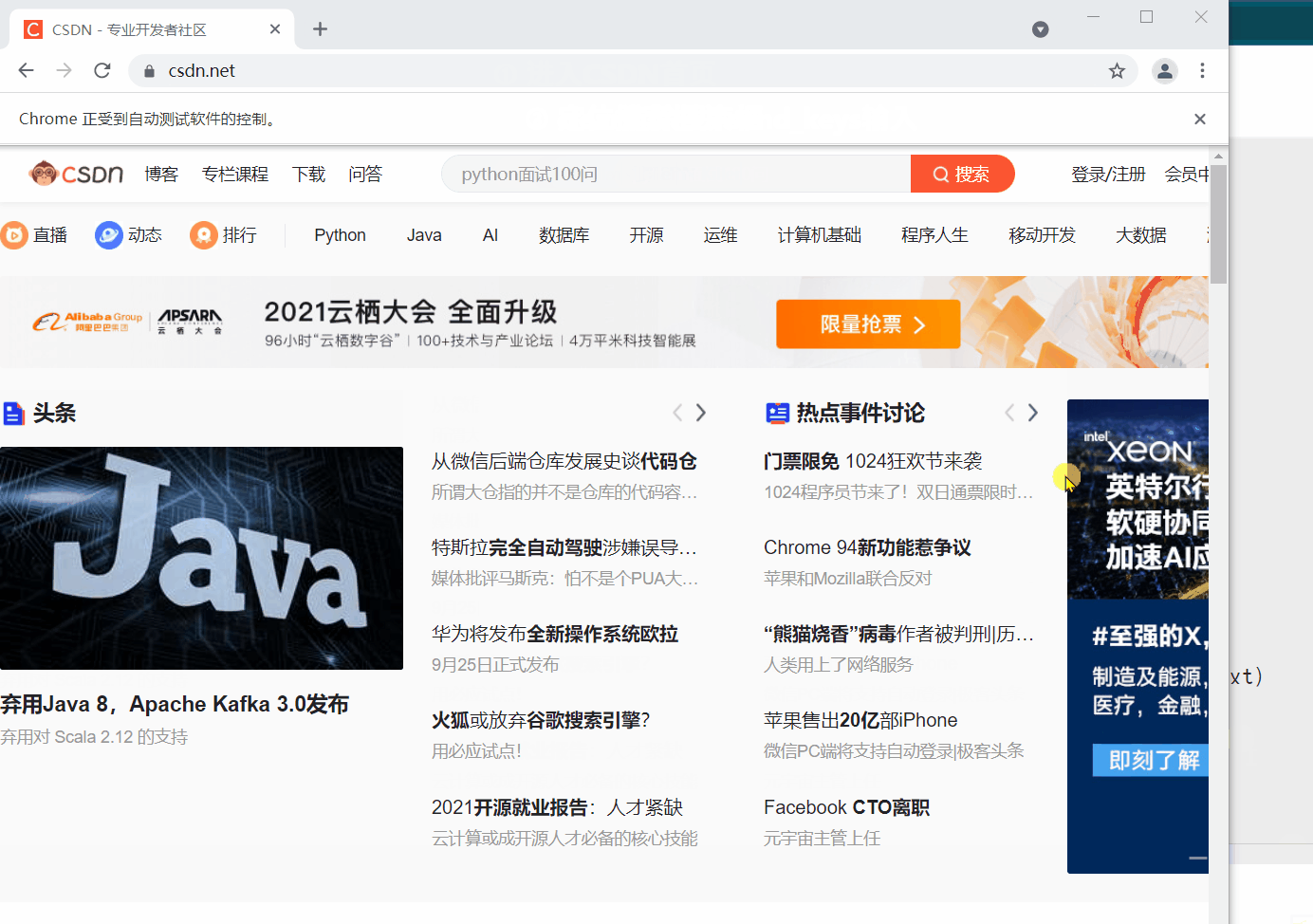
接下来还是用 CSDN 首页为例,需要用到的就是搜素框和搜索按钮。通过下面的例子就可以气息的了解各个操作的用法了。

from selenium import webdriver
driver = webdriver.Chrome()
driver.get(‘https://www.csdn.net/’)
sleep(2)
定位搜索输入框
text_label = driver.find_element_by_xpath(‘//*[@id=“toolbar-search-input”]’)
在搜索框中输入 Dream丶Killer
text_label.send_keys(‘Dream丶Killer’)
sleep(2)
清除搜索框中的内容
text_label.clear()
输出搜索框元素是否可见
print(text_label.is_displayed())
输出placeholder的值
print(text_label.get_attribute(‘placeholder’))
定位搜索按钮
button = driver.find_element_by_xpath(‘//*[@id=“toolbar-search-button”]/span’)
输出按钮的大小
print(button.size)
输出按钮上的文本
print(button.text)
‘’‘输出内容
True
python面试100问
{‘height’: 32, ‘width’: 28}
搜索
‘’’
---
### 鼠标控制
在webdriver 中,鼠标操作都封装在ActionChains类中,常见方法如下:
| 方法 | 描述 |
| --- | --- |
| `click()` | 单击左键 |
| `context_click()` | 单击右键 |
| `double_click()` | 双击 |
| `drag_and_drop()` | 拖动 |
| `move_to_element()` | 鼠标悬停 |
| `perform()` | 执行所有ActionChains中存储的动作 |
#### 单击左键
模拟完成单击鼠标左键的操作,一般点击进入子页面等会用到,左键不需要用到 `ActionChains` 。
定位搜索按钮
button = driver.find_element_by_xpath(‘//*[@id=“toolbar-search-button”]/span’)
执行单击操作
button.click()
#### 单击右键
鼠标右击的操作与左击有很大不同,需要使用 `ActionChains` 。
from selenium.webdriver.common.action_chains import ActionChains
定位搜索按钮
button = driver.find_element_by_xpath(‘//*[@id=“toolbar-search-button”]/span’)
右键搜索按钮
ActionChains(driver).context_click(button).perform()
#### 双击
模拟鼠标双击操作。
定位搜索按钮
button = driver.find_element_by_xpath(‘//*[@id=“toolbar-search-button”]/span’)
执行双击动作
ActionChains(driver).double_click(button).perform()
#### 拖动
模拟鼠标拖动操作,该操作有两个必要参数,
* **source**:鼠标拖动的元素
* **target**:鼠标拖至并释放的目标元素
定位要拖动的元素
source = driver.find_element_by_xpath(‘xxx’)
定位目标元素
target = driver.find_element_by_xpath(‘xxx’)
执行拖动动作
ActionChains(driver).drag_and_drop(source, target).perform()
#### 鼠标悬停
模拟悬停的作用一般是为了显示隐藏的下拉框,比如 CSDN 主页的收藏栏,我们看一下效果。
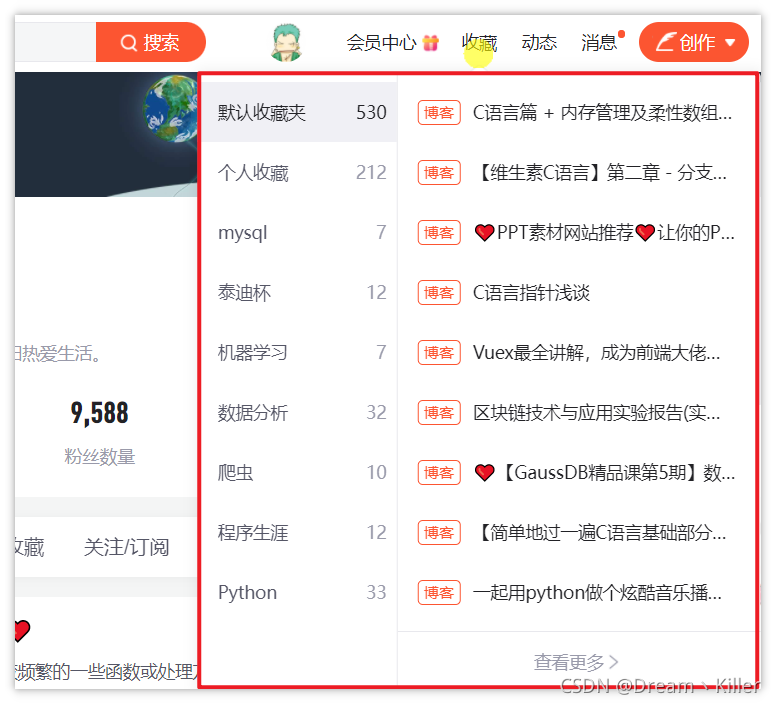
定位收藏栏
collect = driver.find_element_by_xpath(‘//*[@id=“csdn-toolbar”]/div/div/div[3]/div/div[3]/a’)
悬停至收藏标签处
ActionChains(driver).move_to_element(collect).perform()
---
### 键盘控制
`webdriver` 中 `Keys` 类几乎提供了键盘上的所有按键方法,我们可以使用 `send_keys + Keys` 实现输出键盘上的组合按键如 **“Ctrl + C”、“Ctrl + V”** 等。
from selenium.webdriver.common.keys import Keys
定位输入框并输入文本
driver.find_element_by_id(‘xxx’).send_keys(‘Dream丶killer’)
模拟回车键进行跳转(输入内容后)
driver.find_element_by_id(‘xxx’).send_keys(Keys.ENTER)
使用 Backspace 来删除一个字符
driver.find_element_by_id(‘xxx’).send_keys(Keys.BACK_SPACE)
Ctrl + A 全选输入框中内容
driver.find_element_by_id(‘xxx’).send_keys(Keys.CONTROL, ‘a’)
Ctrl + C 复制输入框中内容
driver.find_element_by_id(‘xxx’).send_keys(Keys.CONTROL, ‘c’)
Ctrl + V 粘贴输入框中内容
driver.find_element_by_id(‘xxx’).send_keys(Keys.CONTROL, ‘v’)
其他常见键盘操作:
| 操作 | 描述 |
| --- | --- |
| `Keys.F1` | F1键 |
| `Keys.SPACE` | 空格 |
| `Keys.TAB` | Tab键 |
| `Keys.ESCAPE` | ESC键 |
| `Keys.ALT` | Alt键 |
| `Keys.SHIFT` | Shift键 |
| `Keys.ARROW_DOWN` | 向下箭头 |
| `Keys.ARROW_LEFT` | 向左箭头 |
| `Keys.ARROW_RIGHT` | 向右箭头 |
| `Keys.ARROW_UP` | 向上箭头 |
---
### 设置元素等待
很多页面都使用 `ajax` 技术,页面的元素不是同时被加载出来的,为了防止定位这些尚在加载的元素报错,可以设置元素等来增加脚本的稳定性。`webdriver` 中的等待分为 显式等待 和 隐式等待。
#### 显式等待
显式等待:设置一个超时时间,每个一段时间就去检测一次该元素是否存在,如果存在则执行后续内容,如果超过最大时间(超时时间)则抛出超时异常(`TimeoutException`)。显示等待需要使用 `WebDriverWait`,同时配合 `until` 或 `not until` 。下面详细讲解一下。
>
> WebDriverWait(driver, timeout, poll\_frequency=0.5, ignored\_exceptions=None)
>
>
>
* `driver`:浏览器驱动
* `timeout`:超时时间,单位秒
* `poll_frequency`:每次检测的间隔时间,默认为0.5秒
* `ignored_exceptions`:指定忽略的异常,如果在调用 `until` 或 `until_not` 的过程中抛出指定忽略的异常,则不中断代码,默认忽略的只有 `NoSuchElementException` 。
>
> until(method, message=’ ‘)
> until\_not(method, message=’ ')
>
>
>
* `method`:指定预期条件的判断方法,在等待期间,每隔一段时间调用该方法,判断元素是否存在,直到元素出现。`until_not` 正好相反,当元素消失或指定条件不成立,则继续执行后续代码
* `message`: 如果超时,抛出 `TimeoutException` ,并显示 `message` 中的内容
`method` 中的预期条件判断方法是由 `expected_conditions` 提供,下面列举常用方法。
先定义一个定位器
from selenium.webdriver.common.by import By
from selenium import webdriver
driver = webdriver.Chrome()
locator = (By.ID, ‘kw’)
element = driver.find_element_by_id(‘kw’)
| 方法 | 描述 |
| --- | --- |
| title\_is(‘百度一下’) | 判断当前页面的 title 是否等于预期 |
| title\_contains(‘百度’) | 判断当前页面的 title 是否包含预期字符串 |
| presence\_of\_element\_located(locator) | 判断元素是否被加到了 dom 树里,并不代表该元素一定可见 |
| visibility\_of\_element\_located(locator) | 判断元素是否可见,可见代表元素非隐藏,并且元素的宽和高都不等于0 |
| visibility\_of(element) | 跟上一个方法作用相同,但传入参数为 element |
| text\_to\_be\_present\_in\_element(locator , ‘百度’) | 判断元素中的 text 是否包含了预期的字符串 |
| text\_to\_be\_present\_in\_element\_value(locator , ‘某值’) | 判断元素中的 value 属性是否包含了预期的字符串 |
| frame\_to\_be\_available\_and\_switch\_to\_it(locator) | 判断该 frame 是否可以 switch 进去,True 则 switch 进去,反之 False |
| invisibility\_of\_element\_located(locator) | 判断元素中是否不存在于 dom 树或不可见 |
| element\_to\_be\_clickable(locator) | 判断元素中是否可见并且是可点击的 |
| staleness\_of(element) | 等待元素从 dom 树中移除 |
| element\_to\_be\_selected(element) | 判断元素是否被选中,一般用在下拉列表 |
| element\_selection\_state\_to\_be(element, True) | 判断元素的选中状态是否符合预期,参数 element,第二个参数为 True/False |
| element\_located\_selection\_state\_to\_be(locator, True) | 跟上一个方法作用相同,但传入参数为 locator |
| alert\_is\_present() | 判断页面上是否存在 alert |
下面写一个简单的例子,这里定位一个页面不存在的元素,抛出的异常信息正是我们指定的内容。
from selenium import webdriver
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
from selenium.webdriver.common.by import By
driver = webdriver.Chrome()
element = WebDriverWait(driver, 5, 0.5).until(
EC.presence_of_element_located((By.ID, ‘kw’)),
message=‘超时啦!’)

#### 隐式等待
隐式等待也是指定一个超时时间,如果超出这个时间指定元素还没有被加载出来,就会抛出 `NoSuchElementException` 异常。
除了抛出的异常不同外,还有一点,隐式等待是全局性的,即运行过程中,如果元素可以定位到,它不会影响代码运行,但如果定位不到,则它会以轮询的方式不断地访问元素直到元素被找到,若超过指定时间,则抛出异常。
使用 `implicitly_wait()` 来实现隐式等待,使用难度相对于显式等待要简单很多。
示例:打开个人主页,设置一个隐式等待时间 5s,通过 `id` 定位一个不存在的元素,最后打印 抛出的异常 与 运行时间。
from selenium import webdriver
from time import time
driver = webdriver.Chrome()
driver.get(‘https://blog.csdn.net/qq_43965708’)
start = time()
driver.implicitly_wait(5)
try:
driver.find_element_by_id(‘kw’)
except Exception as e:
print(e)
print(f’耗时:{time()-start}')

代码运行到 `driver.find_element_by_id('kw')` 这句之后触发隐式等待,在轮询检查 5s 后仍然没有定位到元素,抛出异常。
#### 强制等待
使用 `time.sleep()` 强制等待,设置固定的休眠时间,对于代码的运行效率会有影响。以上面的例子作为参照,将 隐式等待 改为 强制等待。
from selenium import webdriver
from time import time, sleep
driver = webdriver.Chrome()
driver.get(‘https://blog.csdn.net/qq_43965708’)
start = time()
sleep(5)
try:
driver.find_element_by_id(‘kw’)
except Exception as e:
print(e)
print(f’耗时:{time()-start}')

值得一提的是,对于定位不到元素的时候,从耗时方面隐式等待和强制等待没什么区别。但如果元素经过 2s 后被加载出来,这时隐式等待就会继续执行下面的代码,但 sleep还要继续等待 3s。
---
### 定位一组元素
上篇讲述了定位一个元素的 8 种方法,定位一组元素使用的方法只需要将 `element` 改为 `elements` 即可,它的使用场景一般是为了批量操作元素。
* `find_elements_by_id()`
* `find_elements_by_name()`
* `find_elements_by_class_name()`
* `find_elements_by_tag_name()`
* `find_elements_by_xpath()`
* `find_elements_by_css_selector()`
* `find_elements_by_link_text()`
* `find_elements_by_partial_link_text()`
这里以 CSDN 首页的一个 博客专家栏 为例。
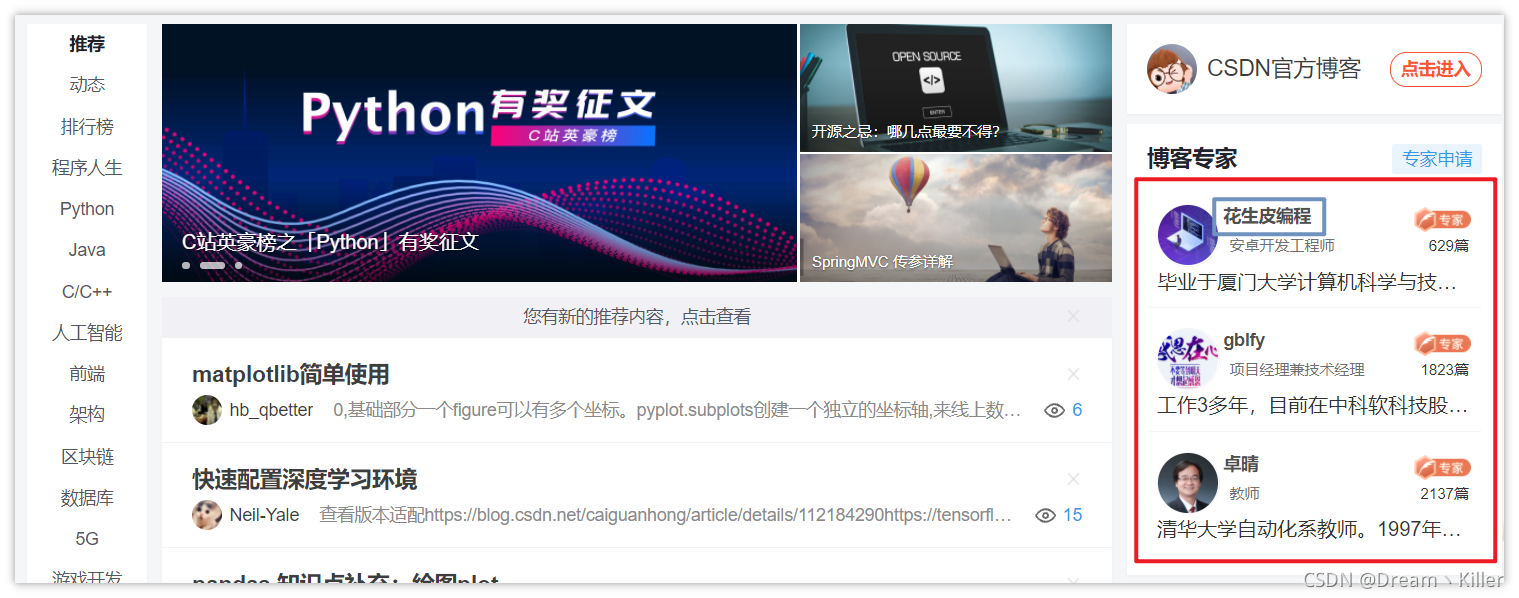
下面使用 `find_elements_by_xpath` 来定位三位专家的名称。

这是专家名称部分的页面代码,不知各位有没有想到如何通过 `xpath` 定位这一组专家的名称呢?
from selenium import webdriver
设置无头浏览器
option = webdriver.ChromeOptions()
option.add_argument(‘–headless’)
driver = webdriver.Chrome(options=option)
driver.get(‘https://blog.csdn.net/’)
p_list = driver.find_elements_by_xpath(“//p[@class=‘name’]”)
name = [p.text for p in p_list]
name

---
### 切换操作
#### 窗口切换
在 `selenium` 操作页面的时候,可能会因为点击某个链接而跳转到一个新的页面(打开了一个新标签页),这时候 `selenium` 实际还是处于上一个页面的,需要我们进行切换才能够定位最新页面上的元素。
窗口切换需要使用 `switch_to.windows()` 方法。
首先我们先看看下面的代码。
代码流程:先进入 【**CSDN首页**】,保存当前页面的句柄,然后再点击左侧 【**CSDN官方博客**】跳转进入新的标签页,再次保存页面的句柄,我们验证一下 `selenium` 会不会自动定位到新打开的窗口。
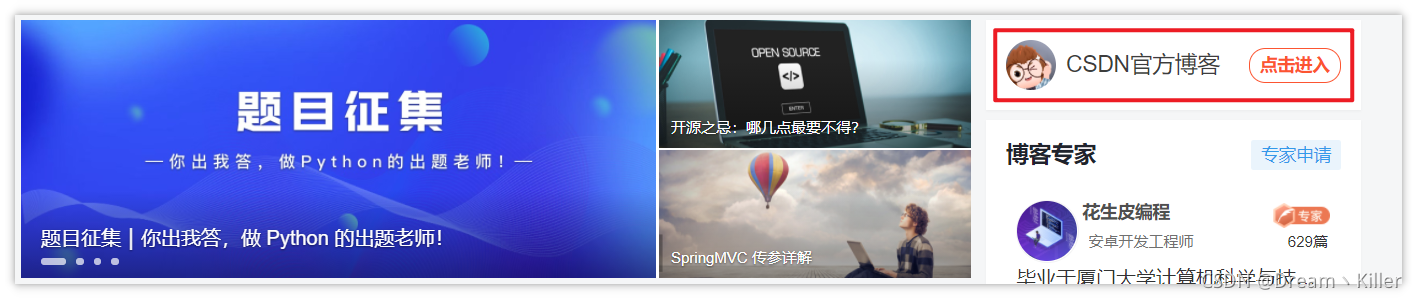
from selenium import webdriver
handles = []
driver = webdriver.Chrome()
driver.get(‘https://blog.csdn.net/’)
设置隐式等待
driver.implicitly_wait(3)
获取当前窗口的句柄
handles.append(driver.current_window_handle)
点击 python,进入分类页面
driver.find_element_by_xpath(‘//*[@id=“mainContent”]/aside/div[1]/div’).click()
获取当前窗口的句柄
handles.append(driver.current_window_handle)
print(handles)
获取当前所有窗口的句柄
print(driver.window_handles)

可以看到第一个列表 `handle` 是相同的,说明 `selenium` 实际操作的还是 CSDN首页 ,并未切换到新页面。
下面使用 `switch_to.windows()` 进行切换。
from selenium import webdriver
handles = []
driver = webdriver.Chrome()
driver.get(‘https://blog.csdn.net/’)
设置隐式等待
driver.implicitly_wait(3)
获取当前窗口的句柄
handles.append(driver.current_window_handle)
点击 python,进入分类页面
driver.find_element_by_xpath(‘//*[@id=“mainContent”]/aside/div[1]/div’).click()
切换窗口
driver.switch_to.window(driver.window_handles[-1])
获取当前窗口的句柄
handles.append(driver.current_window_handle)
print(handles)
print(driver.window_handles)

上面代码在点击跳转后,使用 `switch_to` 切换窗口,**`window_handles` 返回的 `handle` 列表是按照页面出现时间进行排序的**,最新打开的页面肯定是最后一个,这样用 `driver.window_handles[-1]` + `switch_to` 即可跳转到最新打开的页面了。
那如果打开的窗口有多个,如何跳转到之前打开的窗口,如果确实有这个需求,那么打开窗口是就需要记录每一个窗口的 `key`(别名) 与 `value`(`handle`),保存到字典中,后续根据 `key` 来取 `handle` 。
#### 表单切换
很多页面也会用带 `frame/iframe` 表单嵌套,对于这种内嵌的页面 `selenium` 是无法直接定位的,需要使用 `switch_to.frame()` 方法将当前操作的对象切换成 `frame/iframe` 内嵌的页面。
`switch_to.frame()` 默认可以用的 `id` 或 `name` 属性直接定位,但如果 `iframe` 没有 `id` 或 `name` ,这时就需要使用 `xpath` 进行定位。下面先写一个包含 `iframe` 的页面做测试用。
公众号:Python新视野
CSDN:Dream丶Killer
微信:python-sun
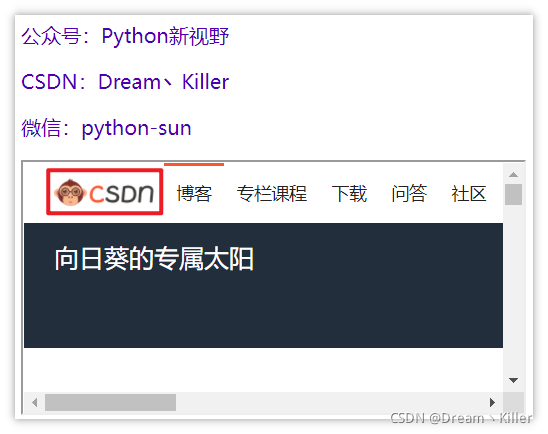
现在我们定位红框中的 CSDN 按钮,可以跳转到 CSDN 首页。
from selenium import webdriver
from pathlib import Path
driver = webdriver.Chrome()
读取本地html文件
driver.get(‘file:///’ + str(Path(Path.cwd(), ‘iframe测试.html’)))
1.通过id定位
driver.switch_to.frame(‘CSDN_info’)
2.通过name定位
driver.switch_to.frame(‘Dream丶Killer’)
通过xpath定位
3.iframe_label = driver.find_element_by_xpath(‘/html/body/iframe’)
driver.switch_to.frame(iframe_label)
driver.find_element_by_xpath(‘//*[@id=“csdn-toolbar”]/div/div/div[1]/div/a/img’).click()
这里列举了三种定位方式,都可以定位 `iframe` 。

---
### 弹窗处理
`JavaScript` 有三种弹窗 `alert`(确认)、`confirm`(确认、取消)、`prompt`(文本框、确认、取消)。
处理方式:先定位(`switch_to.alert`自动获取当前弹窗),再使用 `text`、`accept`、`dismiss`、`send_keys` 等方法进行操作
| 方法 | 描述 |
| --- | --- |
| `text` | 获取弹窗中的文字 |
| `accept` | 接受(确认)弹窗内容 |
| `dismiss` | 解除(取消)弹窗 |
| `send_keys` | 发送文本至警告框 |
这里写一个简单的测试页面,其中包含三个按钮,分别对应三个弹窗。
<script type="text/javascript">
const dom1 = document.getElementById(“alert”)
dom1.addEventListener(‘click’, function(){
alert(“alert hello”)
})
const dom2 = document.getElementById(“confirm”)
dom2.addEventListener(‘click’, function(){
confirm(“confirm hello”)
})
const dom3 = document.getElementById(“prompt”)
dom3.addEventListener(‘click’, function(){
prompt(“prompt hello”)
})

下面使用上面的方法进行测试。为了防止弹窗操作过快,每次操作弹窗,都使用 `sleep` 强制等待一段时间。
from selenium import webdriver
from pathlib import Path
from time import sleep
driver = webdriver.Firefox()
driver.get(‘file:///’ + str(Path(Path.cwd(), ‘弹窗.html’)))
sleep(2)
点击alert按钮
driver.find_element_by_xpath(‘//*[@id=“alert”]’).click()
sleep(1)
alert = driver.switch_to.alert
打印alert弹窗的文本
print(alert.text)
确认
alert.accept()
sleep(2)
点击confirm按钮
driver.find_element_by_xpath(‘//*[@id=“confirm”]’).click()
sleep(1)
confirm = driver.switch_to.alert
print(confirm.text)
取消
confirm.dismiss()
sleep(2)
点击confirm按钮
driver.find_element_by_xpath(‘//*[@id=“prompt”]’).click()
sleep(1)
prompt = driver.switch_to.alert
print(prompt.text)
向prompt的输入框中传入文本
prompt.send_keys(“Dream丶Killer”)
sleep(2)
prompt.accept()
‘’‘输出
alert hello
confirm hello
prompt hello
‘’’

>
> 注:细心地读者应该会发现这次操作的浏览器是 `Firefox` ,为什么不用 `Chrome` 呢?原因是测试时发现执行 `prompt` 的 `send_keys` 时,不能将文本填入输入框。尝试了各种方法并查看源码后确认不是代码的问题,之后通过其他渠道得知原因可能是 `Chrome` 的版本与 `selenium` 版本的问题,但也没有很方便的解决方案,因此没有继续深究,改用 `Firefox` 可成功运行。这里记录一下我的 `Chrome` 版本,如果有大佬懂得如何在 `Chrome` 上解决这个问题,请在评论区指导一下,提前感谢!
> selenium:3.141.0
> Chrome:94.0.4606.71
> 
>
>
>
---
### 上传 & 下载文件
#### 上传文件
常见的 web 页面的上传,一般使用 `input` 标签或是插件(`JavaScript`、`Ajax`),对于 `input` 标签的上传,可以直接使用 `send_keys(路径)` 来进行上传。
先写一个测试用的页面。

下面通过 `xpath` 定位 `input` 标签,然后使用 `send_keys(str(file_path)` 上传文件。
from selenium import webdriver
from pathlib import Path
from time import sleep
driver = webdriver.Chrome()
file_path = Path(Path.cwd(), ‘上传下载.html’)
driver.get(‘file:///’ + str(file_path))
driver.find_element_by_xpath(‘//*[@name=“upload”]’).send_keys(str(file_path))

#### 下载文件
##### Chrome浏览器
`Firefox` 浏览器要想实现文件下载,需要通过 `add_experimental_option` 添加 `prefs` 参数。
* `download.default_directory`:设置下载路径。
* `profile.default_content_settings.popups`:0 禁止弹出窗口。
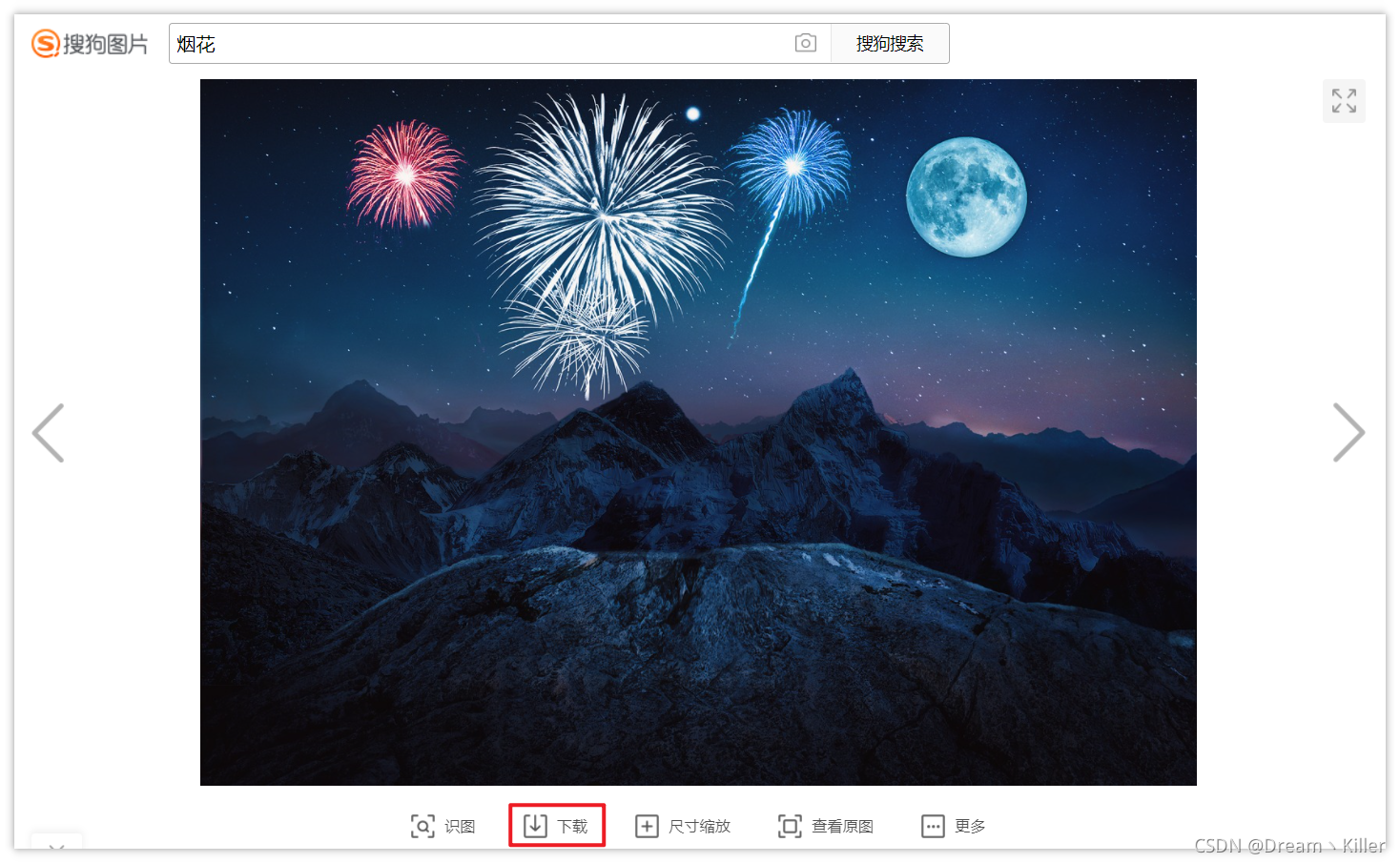
下面测试下载搜狗图片。指定保存路径为代码所在路径。
from selenium import webdriver
prefs = {‘profile.default_content_settings.popups’: 0,
‘download.default_directory’: str(Path.cwd())}
option = webdriver.ChromeOptions()
option.add_experimental_option(‘prefs’, prefs)
driver = webdriver.Chrome(options=option)
driver.get(“https://pic.sogou.com/d?query=%E7%83%9F%E8%8A%B1&did=4&category_from=copyright”)
driver.find_element_by_xpath(‘/html/body/div/div/div/div[2]/div[1]/div[2]/div[1]/div[2]/a’).click()
driver.switch_to.window(driver.window_handles[-1])
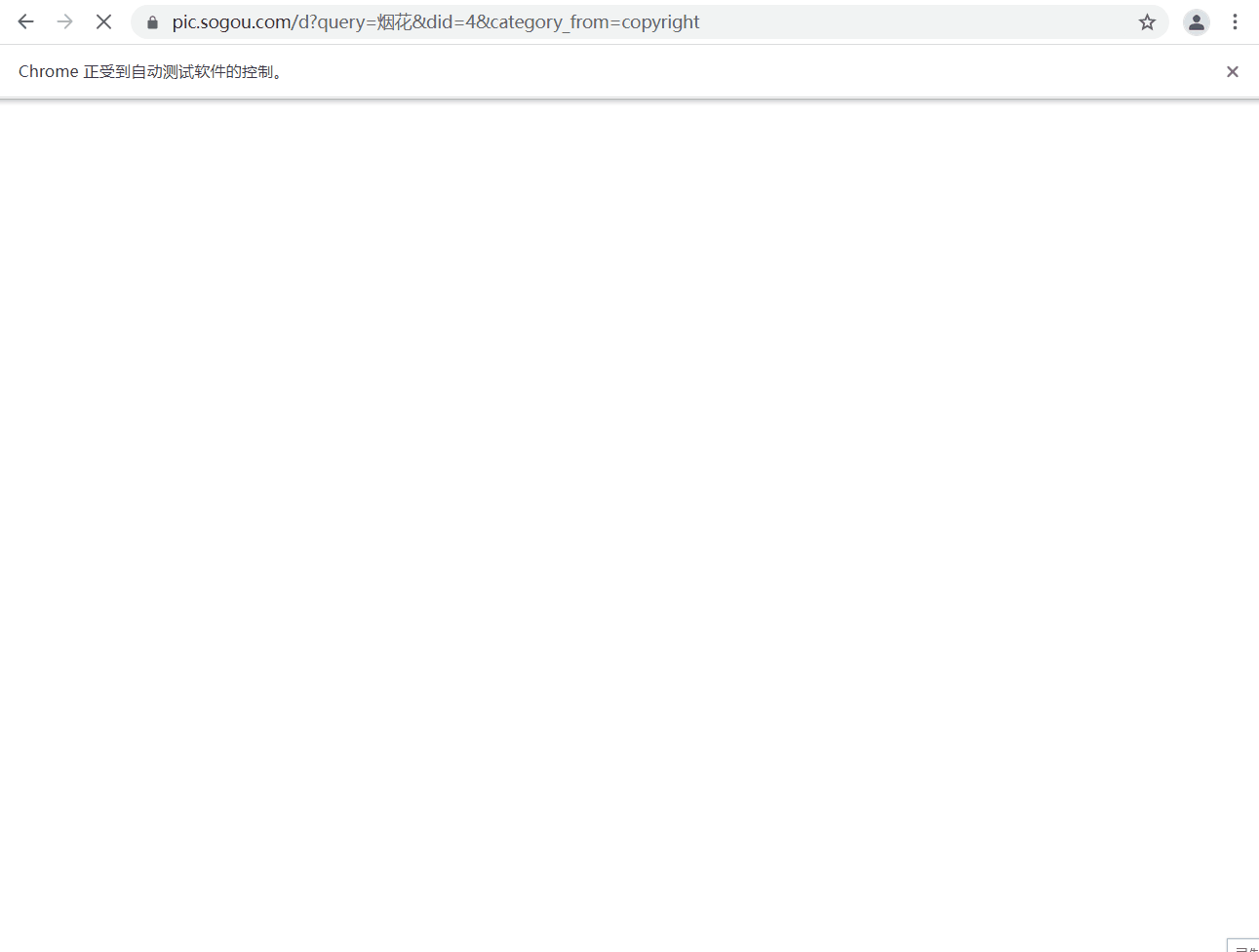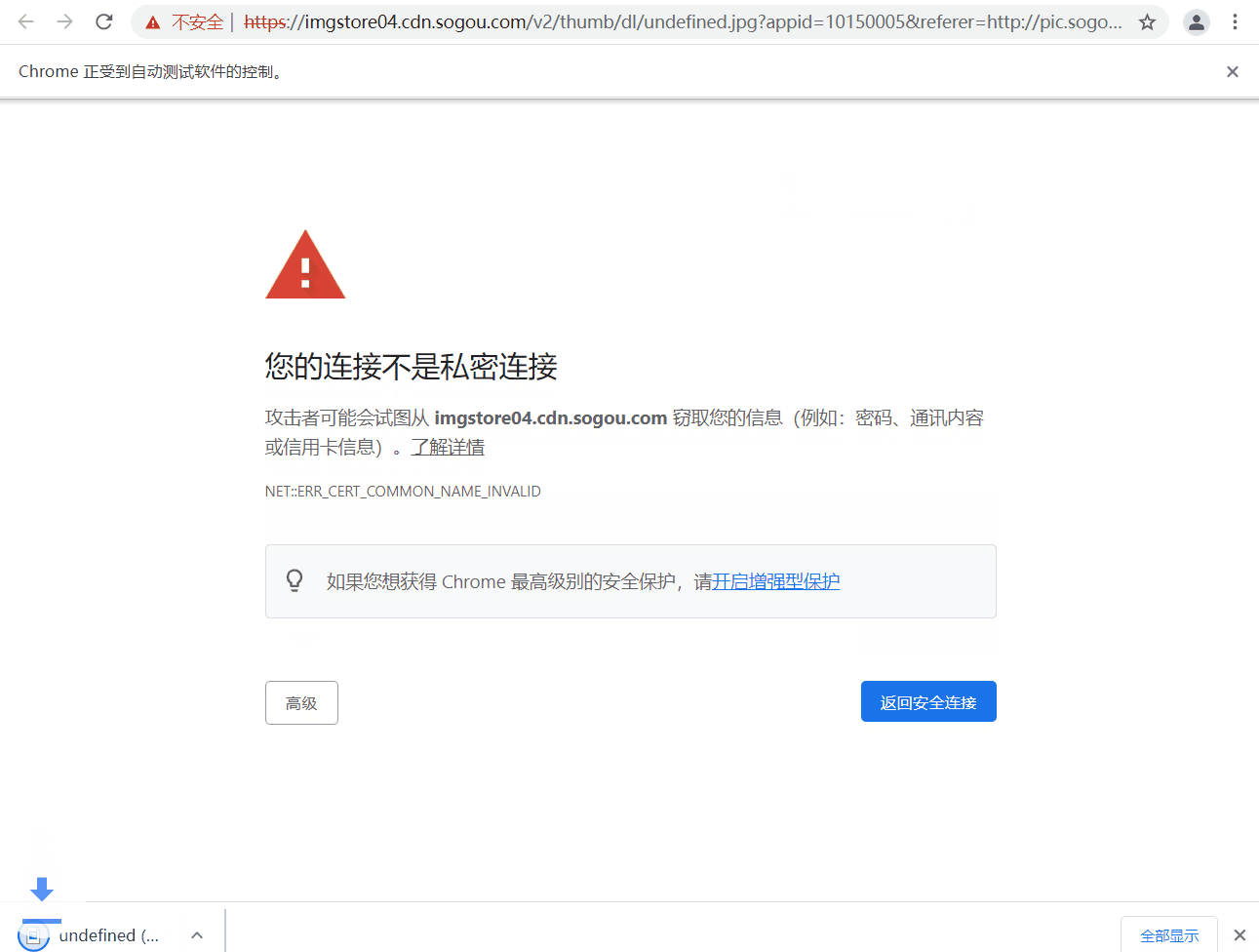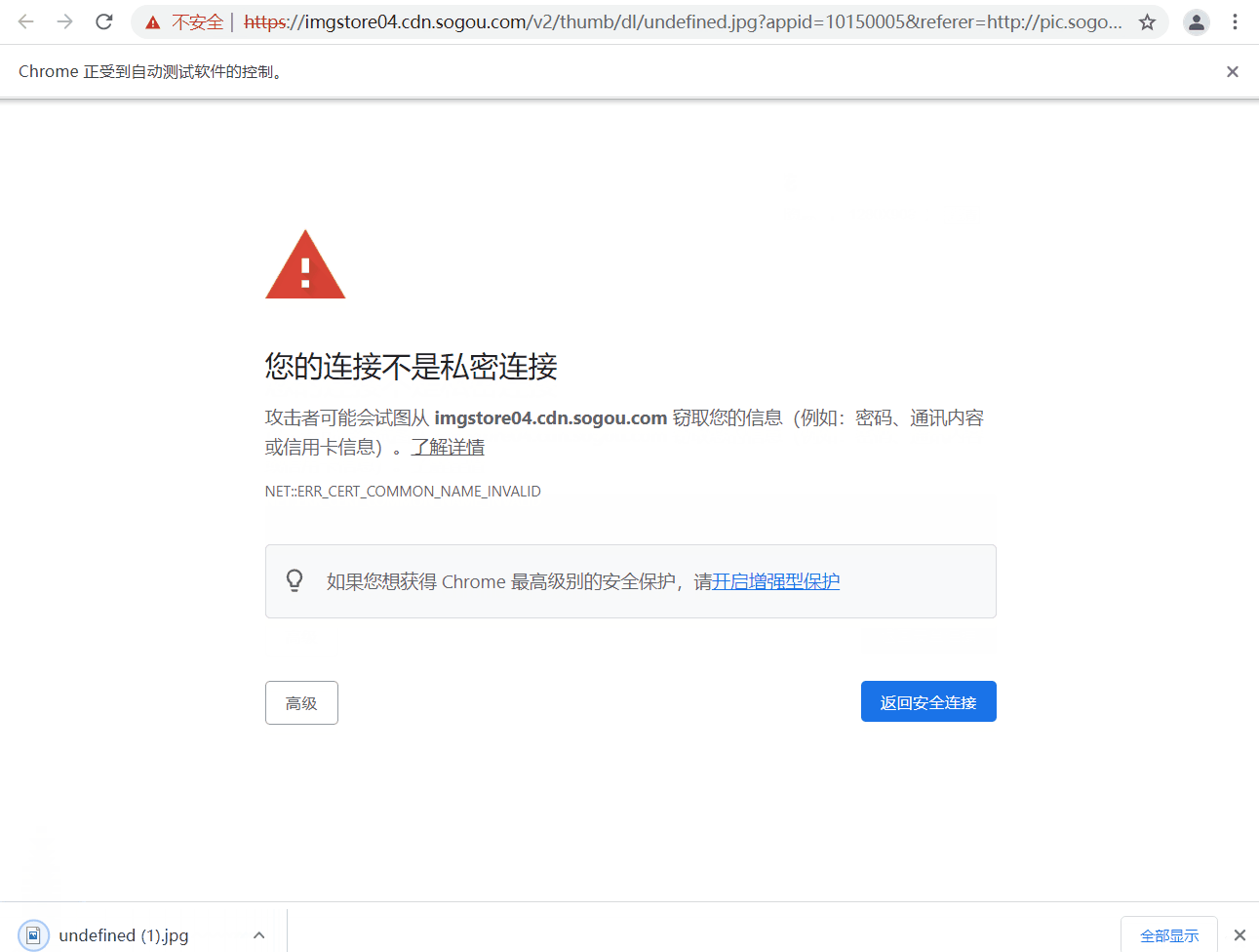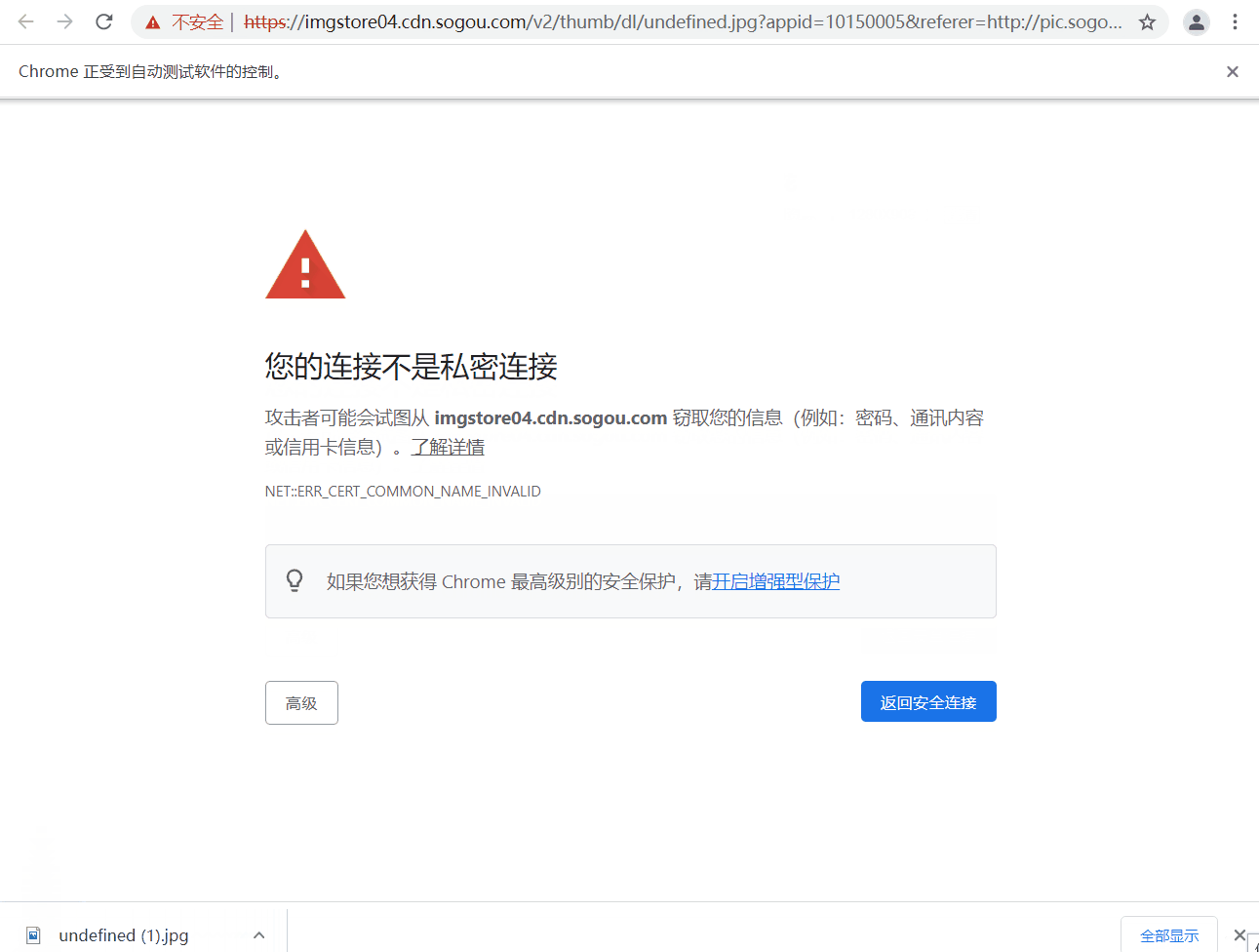
driver.find_element_by_xpath(‘./html’).send_keys(‘thisisunsafe’)
>
> 代码最后两句猜测有理解什么意思的吗~,哈哈,实际作用是当你弹出像下面的页面 “您的连接不是私密连接” 时,可以直接键盘输入 “thisisunsafe” 直接访问链接。那么这个键盘输入字符串的操作就是之间讲到的 `send_keys`,但由于该标签页是新打开的,所以要通过 `switch_to.window()` 将窗口切换到最新的标签页。
>
>
>
##### Firefox浏览器
`Firefox` 浏览器要想实现文件下载,需要通过 `set_preference` 设置 `FirefoxProfile()` 的一些属性。
* `browser.download.foladerList`:0 代表按浏览器默认下载路径;2 保存到指定的目录。
* `browser.download.dir`:指定下载目录。
* `browser.download.manager.showWhenStarting`:是否显示开始,`boolean` 类型。
* `browser.helperApps.neverAsk.saveToDisk`:对指定文件类型不再弹出框进行询问。
* **HTTP Content-type对照表**:<https://www.runoob.com/http/http-content-type.html>
from selenium import webdriver
import os
fp = webdriver.FirefoxProfile()
fp.set_preference(“browser.download.dir”,os.getcwd())
fp.set_preference(“browser.download.folderList”,2)
fp.set_preference(“browser.download.manager.showhenStarting”,True)
fp.set_preference(“browser.helperApps.neverAsk.saveToDisk”,“application/octet-stream”)
driver = webdriver.Firefox(firefox_profile = fp)
driver.get(“https://pic.sogou.com/d?query=%E7%83%9F%E8%8A%B1&did=4&category_from=copyright”)
driver.find_element_by_xpath(‘/html/body/div/div/div/div[2]/div[1]/div[2]/div[1]/div[2]/a’).click()
运行效果与 `Chrome` 基本一致,这里就不再展示了。
---
### cookies操作
`cookies` 是识别用户登录与否的关键,爬虫中常常使用 `selenium + requests` 实现 `cookie`持久化,即先用 `selenium` 模拟登陆获取 `cookie` ,再通过 `requests` 携带 `cookie` 进行请求。
`webdriver` 提供 `cookies` 的几种操作:读取、添加删除。
* `get_cookies`:以字典的形式返回当前会话中可见的 `cookie` 信息。
* `get_cookie(name)`:返回 `cookie` 字典中 `key == name` 的 `cookie` 信息。
* `add_cookie(cookie_dict)`:将 `cookie` 添加到当前会话中
* `delete_cookie(name)`:删除指定名称的单个 `cookie`。
* `delete_all_cookies()`:删除会话范围内的所有 `cookie`。
下面看一下简单的示例,演示了它们的用法。
from selenium import webdriver
driver = webdriver.Chrome()
driver.get(“https://blog.csdn.net/”)
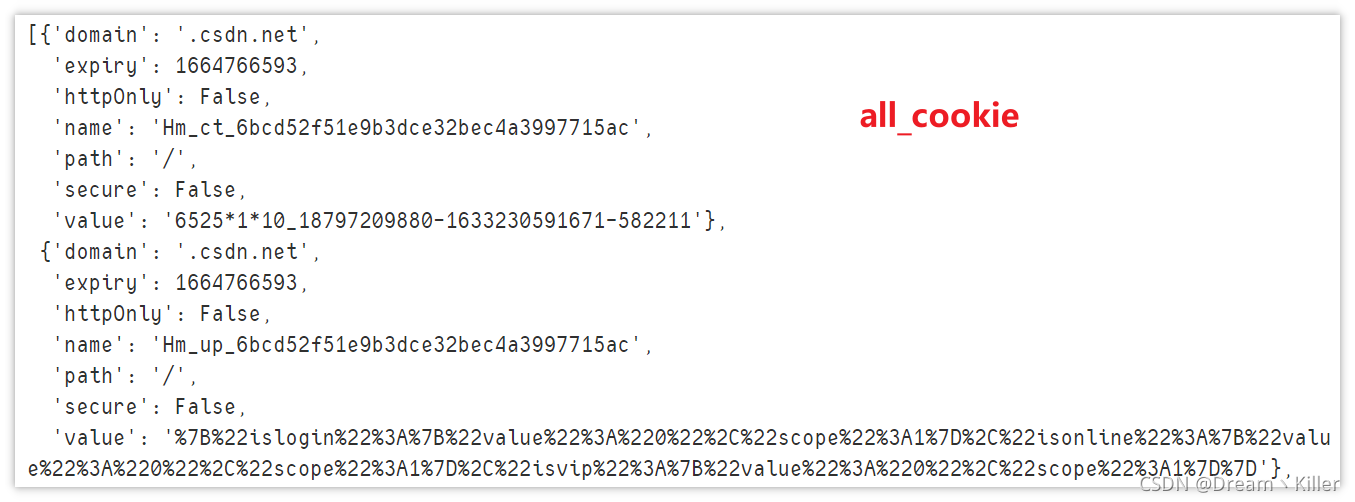
输出所有cookie信息
print(driver.get_cookies())
cookie_dict = {
‘domain’: ‘.csdn.net’,
‘expiry’: 1664765502,
‘httpOnly’: False,
‘name’: ‘test’,
‘path’: ‘/’,
‘secure’: True,
‘value’: ‘null’}
添加cookie
driver.add_cookie(cookie_dict)
显示 name = ‘test’ 的cookie信息
print(driver.get_cookie(‘test’))
删除 name = ‘test’ 的cookie信息
driver.delete_cookie(‘test’)
删除当前会话中的所有cookie
driver.delete_all_cookies()

---
### 调用JavaScript
`webdriver` 对于滚动条的处理需要用到 `JavaScript` ,同时也可以向 `textarea` 文本框中输入文本( `webdriver` 只能定位,不能输入文本),`webdriver` 中使用execute\_script方法实现 `JavaScript` 的执行。
#### 滑动滚动条
##### 通过 x ,y 坐标滑动
对于这种通过坐标滑动的方法,我们需要知道做表的起始位置在页面左上角(0,0),下面看一下示例,滑动 CSDN 首页。
from selenium import webdriver
from time import sleep
driver = webdriver.Chrome()
driver.get(“https://blog.csdn.net/”)
sleep(1)
js = “window.scrollTo(0,500);”
driver.execute_script(js)
#### 通过参照标签滑动
这种方式需要先找一个参照标签,然后将滚动条滑动至该标签的位置。下面还是用 CSDN 首页做示例,我们用循环来实现重复滑动。该 `li` 标签实际是一种**懒加载**,当用户滑动至最后标签时,才会加载后面的数据。
from selenium import webdriver
from time import sleep
driver = webdriver.Chrome()
driver.get(“https://blog.csdn.net/”)
sleep(1)
driver.implicitly_wait(3)
for i in range(31, 102, 10):
sleep(1)
target = driver.find_element_by_xpath(f’//*[@id=“feedlist_id”]/li[{i}]')
driver.execute_script(“arguments[0].scrollIntoView();”, target)
---
### 其他操作
#### 关闭所有页面
使用 `quit()` 方法可以关闭所有窗口并退出驱动程序。
driver.quit()
#### 关闭当前页面
使用 `close()` 方法可以关闭当前页面,使用时要注意 “当前页面” 这四个字,当你关闭新打开的页面时,需要切换窗口才能操作新窗口并将它关闭。,下面看一个简单的例子,这里不切换窗口,看一下是否能够关闭新打开的页面。
from selenium import webdriver
from time import sleep
driver = webdriver.Chrome()
driver.get(‘https://blog.csdn.net/’)
driver.implicitly_wait(3)
点击进入新页面
driver.find_element_by_xpath(‘//*[@id=“mainContent”]/aside/div[1]/div’).click()
切换窗口
driver.switch_to.window(driver.window_handles[-1])
sleep(3)
driver.close()
可以看到,在不切换窗口时,`driver` 对象还是操作最开始的页面。
#### 对当前页面进行截图
`wendriver` 中使用 `get_screenshot_as_file()` 对 “当前页面” 进行截图,这里和上面的 `close()` 方法一样,对于新窗口的操作,一定要切换窗口,不然截的还是原页面的图。对页面截图这一功能,主要用在我们测试时记录报错页面的,我们可以将 `try except` 结合 `get_screenshot_as_file()` 一起使用来实现这一效果。
try:
driver.find_element_by_xpath(‘//*[@id=“mainContent”]/aside/div[1]/div’).click()
except:
driver.get_screenshot_as_file(r’C:\Users\pc\Desktop\screenshot.png’)
#### 常用方法总结
获取当前页面url
driver.current_url
一、Python所有方向的学习路线
Python所有方向的技术点做的整理,形成各个领域的知识点汇总,它的用处就在于,你可以按照下面的知识点去找对应的学习资源,保证自己学得较为全面。


二、Python必备开发工具
工具都帮大家整理好了,安装就可直接上手!
三、最新Python学习笔记
当我学到一定基础,有自己的理解能力的时候,会去阅读一些前辈整理的书籍或者手写的笔记资料,这些笔记详细记载了他们对一些技术点的理解,这些理解是比较独到,可以学到不一样的思路。

四、Python视频合集
观看全面零基础学习视频,看视频学习是最快捷也是最有效果的方式,跟着视频中老师的思路,从基础到深入,还是很容易入门的。

五、实战案例
纸上得来终觉浅,要学会跟着视频一起敲,要动手实操,才能将自己的所学运用到实际当中去,这时候可以搞点实战案例来学习。
六、面试宝典


简历模板
网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。
一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









