







自我介绍一下,小编13年上海交大毕业,曾经在小公司待过,也去过华为、OPPO等大厂,18年进入阿里一直到现在。
深知大多数HarmonyOS鸿蒙开发工程师,想要提升技能,往往是自己摸索成长或者是报班学习,但对于培训机构动则几千的学费,着实压力不小。自己不成体系的自学效果低效又漫长,而且极易碰到天花板技术停滞不前!
因此收集整理了一份《2024年HarmonyOS鸿蒙开发全套学习资料》,初衷也很简单,就是希望能够帮助到想自学提升又不知道该从何学起的朋友,同时减轻大家的负担。

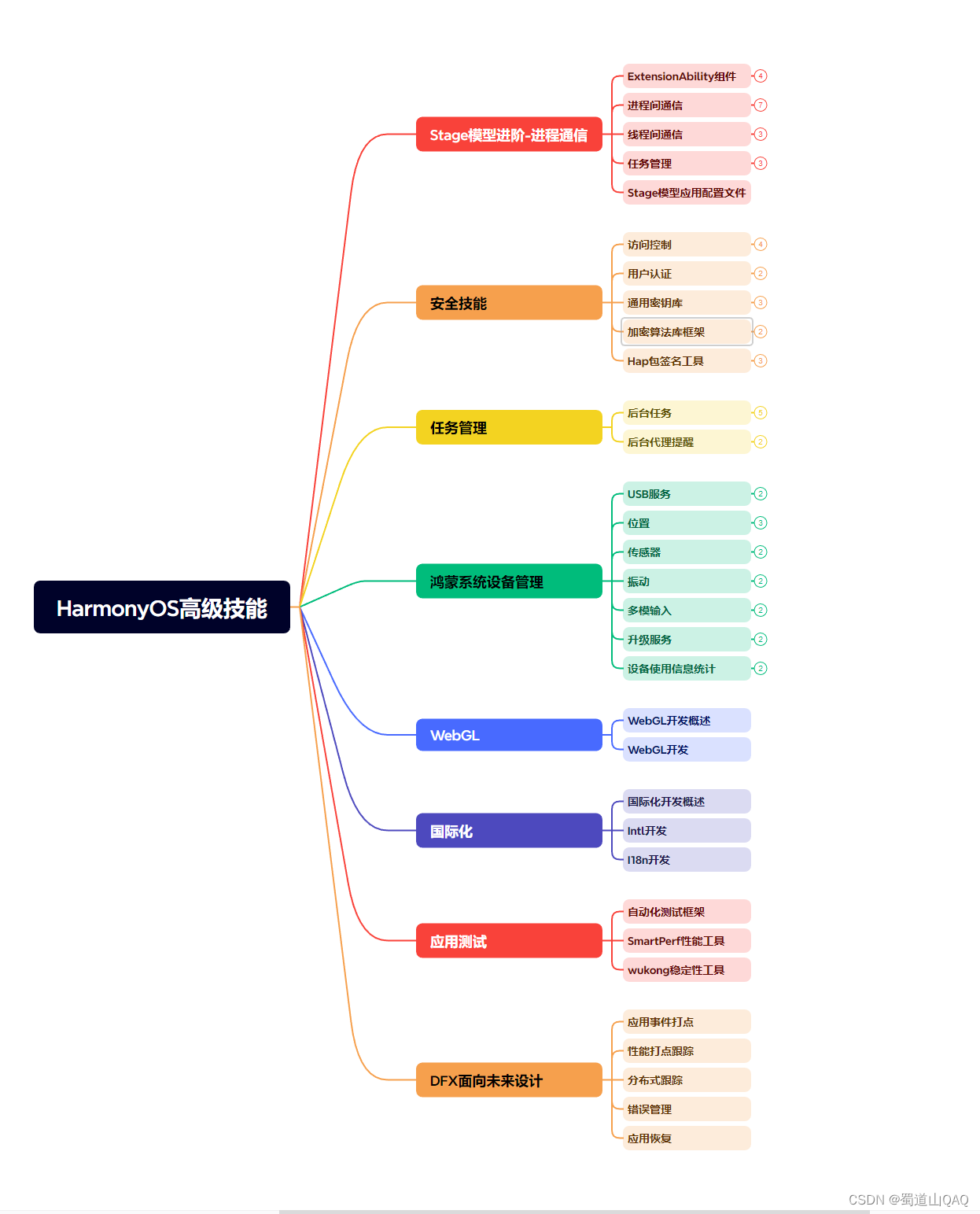



既有适合小白学习的零基础资料,也有适合3年以上经验的小伙伴深入学习提升的进阶课程,基本涵盖了95%以上HarmonyOS鸿蒙开发知识点,真正体系化!
由于文件比较大,这里只是将部分目录大纲截图出来,每个节点里面都包含大厂面经、学习笔记、源码讲义、实战项目、讲解视频,并且会持续更新
如果你觉得这些内容对你有帮助,可以添加VX:vip204888 (备注鸿蒙获取)

一个人可以走的很快,但一群人才能走的更远。不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎扫码加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!
简单举个例子,假设我们拥有一个烤箱,可以用来烤面包,由于烤箱容量的限制,一次只能烤4个面包,如果你试着一次烤8个面包,会大大加大烤箱的承载负荷,这已经远远超过了它的内存使用量,很有可能会因此烧掉你的面包。
模拟背压问题
回顾下之前所说的,当我们消耗的速度比生产的速度慢的时候,就会产生背压,下面用代码来模拟下这个过程
- 首先先创建一个方法,用来每秒发送元素
fun currentTime() = System.currentTimeMillis()
fun threadName() = Thread.currentThread().name
var start: Long = 0
fun createEmitter(): Flow<Int> =
(1..5)
.asFlow()
.onStart { start = currentTime() }
.onEach {
delay(1000L)
print("Emit $it (${currentTime() - start}ms) ")
}
- 接着需要收集元素,这里我们延迟3秒再接收元素, 延迟是为了夸大缓慢的消费者并创建一个超级慢的收集器。
fun main() {
runBlocking {
val time = measureTimeMillis {
createEmitter().collect {
print("\nCollect $it starts ${start - currentTime()}ms")
delay(3000L)
println(" Collect $it ends ${currentTime() - start}ms")
}
}
print("\nCollected in $time ms")
}
}
看下输出结果,如下图所示

这样整个过程下来,大概需要20多秒才能结束,这里我们模拟了接收元素比发送元素慢的情况,因此就需要一个背压机制,而这正是Flow本质中的,它并不需要另外的设计来解决背压
背压处理方式
使用buffer进行缓存收集
为了使缓冲和背压处理正常工作,我们需要在单独的协程中运行收集器。这就是.buffer()操作符进来的地方,它是将所有发出的项目发送Channel到在单独的协程中运行的收集器。
public fun <T> Flow<T>.buffer(
capacity: Int = BUFFERED,
onBufferOverflow: BufferOverflow = BufferOverflow.SUSPEND
): Flow<T>
它还为我们提供了缓冲功能,我们可以指定capacity我们的缓冲区和处理策略onBufferOverflow,所以当Buffer溢出的时候,它为我们提供了三个选项
enum BufferOverflow {
SUSPEND,
DROP_OLDEST,
DROP_LATEST
}
- 默认使用
SUSPEND:会将当前协程挂起,直到缓冲区中的数据被消费了 DROP_OLDEST:它会丢弃最老的数据DROP_LATEST: 它会丢弃最新的数据
好的,我们回到上文所展示的模拟示例,这时候我们可以加入缓冲收集buffer,不指定任何参数,这样默认就是使用SUSPEND,它会将当前协程进行挂起

此时当收集器繁忙的时候,程序就开始缓冲,并在第一次收集方法调用结束的时候,两次发射后再次开始收集,此时流程的耗时时长缩短到大约16秒就可以执行完毕,如下图所示输出结果

使用conflate解决
conflate操作符于Channel中的Conflate模式是一直的,新数据会直接覆盖掉旧数据,它不设缓冲区,也就是缓冲区大小为 0,丢弃旧数据,也就是采取 DROP_OLDEST 策略,那么不就等于buffer(0,BufferOverflow.DROP_OLDEST),可以看下它的源码可以佐证我们的判断
public fun <T> Flow<T>.conflate(): Flow<T> = buffer(CONFLATED)
在某些情况下,由于根本原因是解决生产消费速率不匹配的问题,我们需要做一些取舍的操作,conflate将丢弃掉旧数据,只有在收集器空闲之前发出的最后一个元素才被收集,将上文的模拟实例改为conflate执行,你会发现我们直接丢弃掉了2和4,或者说新的数据直接覆盖掉了它们,整个流程只需要10秒左右就执行完成了

使用collectLatest解决
通过官方介绍,我们知道collectLatest作用在于当原始流发出一个新的值的时候,前一个值的处理将被取消,也就是不会被接收, 和conflate的区别在于它不会用新的数据覆盖,而是每一个都会被处理,只不过如果前一个还没被处理完后一个就来了的话,处理前一个数据的逻辑就会被取消
suspend fun <T> Flow<T>.collectLatest(action: suspend (T) -> Unit)
还是上文的模拟实例,这里我们使用collectLatest看下输出结果:

这样也是有副作用的,如果每个更新都非常重要,例如一些视图,状态刷新,这个时候就不必要用collectLatest ; 当然如果有些更新可以无损失的覆盖,例如数据库刷新,就可以使用到collectLatest,具体详细的使用场景,还需要靠开发者自己去衡量选择使用
小结
对于Flow可以说不需要额外提供什么巧妙的方式解决背压问题,Flow的本质,亦或者说Kotlin协程本身就已经提供了相应的解决方案;开发者只需要在不同的场景中选择正确的背压策略即可。总的来说,它们都是通过使用Kotlin挂起函数suspend,当流的收集器不堪重负时,它可以简单地暂停发射器,然后在准备好接受更多元素时恢复它。
以说不需要额外提供什么巧妙的方式解决背压问题,Flow的本质,亦或者说Kotlin协程本身就已经提供了相应的解决方案;开发者只需要在不同的场景中选择正确的背压策略即可。总的来说,它们都是通过使用Kotlin挂起函数suspend,当流的收集器不堪重负时,它可以简单地暂停发射器,然后在准备好接受更多元素时恢复它。















 3570
3570

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









