









网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。
一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!
```
+ **提交**
```
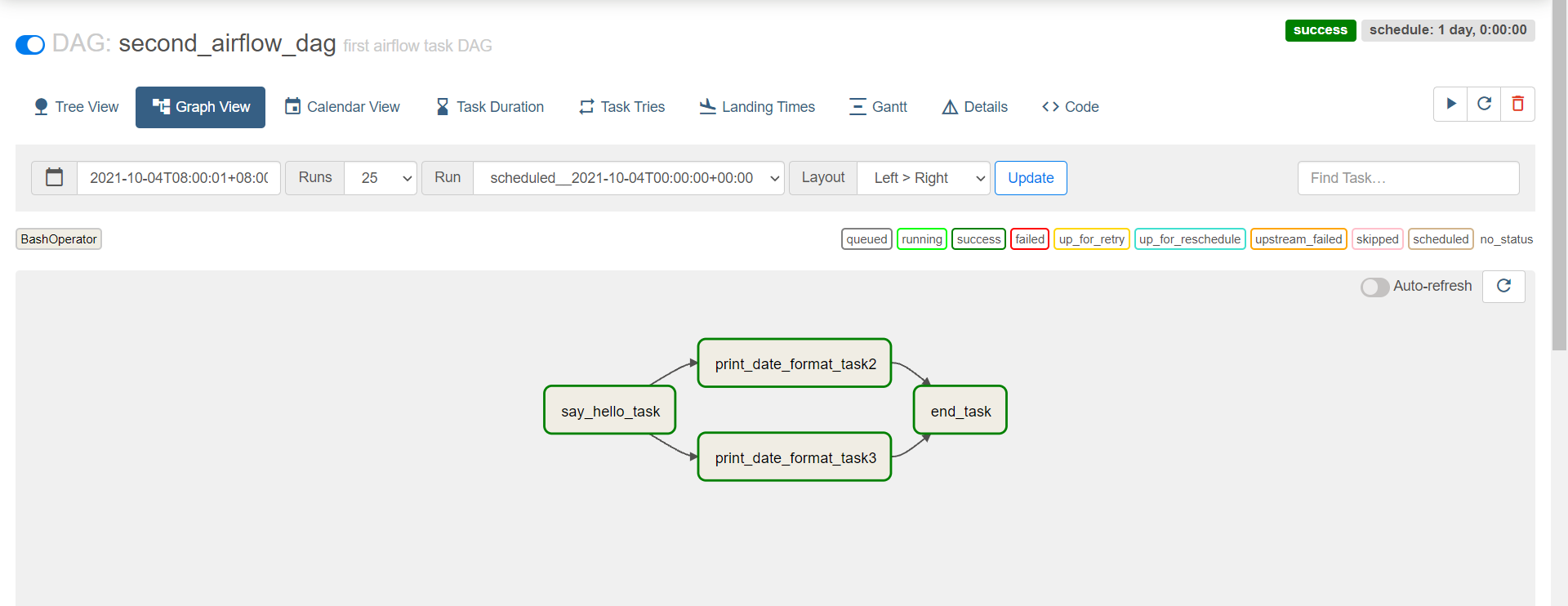
python second_bash_operator.py
```
+ **查看**
-
小结
- 实现AirFlow的依赖调度测试
知识点09:Python调度测试
-
目标:实现Python代码的调度测试
-
实施
-
需求:调度Python代码Task的运行
-
代码
- 创建
cd /root/airflow/dags vim python_etl_airflow.py- 开发
# import package from airflow import DAG from airflow.operators.python import PythonOperator from airflow.utils.dates import days_ago import json # define args default_args = { 'owner': 'airflow', } # define the dag with DAG( 'python\_etl\_dag', default_args=default_args, description='DATA ETL DAG', schedule_interval=None, start_date=days_ago(2), tags=['itcast'], ) as dag: # function1 def extract(\*\*kwargs): ti = kwargs['ti'] data_string = '{"1001": 301.27, "1002": 433.21, "1003": 502.22, "1004": 606.65, "1005": 777.03}' ti.xcom_push('order\_data', data_string) # function2 def transform(\*\*kwargs): ti = kwargs['ti'] extract_data_string = ti.xcom_pull(task_ids='extract', key='order\_data') order_data = json.loads(extract_data_string) total_order_value = 0 for value in order_data.values(): total_order_value += value total_value = {"total\_order\_value": total_order_value} total_value_json_string = json.dumps(total_value) ti.xcom_push('total\_order\_value', total_value_json_string) # function3 def load(\*\*kwargs): ti = kwargs['ti'] total_value_string = ti.xcom_pull(task_ids='transform', key='total\_order\_value') total_order_value = json.loads(total_value_string) print(total_order_value) # task1 extract_task = PythonOperator( task_id='extract', python_callable=extract, ) extract_task.doc_md = """\ #### Extract task A simple Extract task to get data ready for the rest of the data pipeline. In this case, getting data is simulated by reading from a hardcoded JSON string. This data is then put into xcom, so that it can be processed by the next task. """ # task2 transform_task = PythonOperator( task_id='transform', python_callable=transform, ) transform_task.doc_md = """\ #### Transform task A simple Transform task which takes in the collection of order data from xcom and computes the total order value. This computed value is then put into xcom, so that it can be processed by the next task. """ # task3 load_task = PythonOperator( task_id='load', python_callable=load, ) load_task.doc_md = """\ #### Load task A simple Load task which takes in the result of the Transform task, by reading it from xcom and instead of saving it to end user review, just prints it out. """ # run extract_task >> transform_task >> load_task -
提交
python python_etl_airflow.py- 查看

-
-
小结
- 实现Python代码的调度测试
知识点10:Oracle与MySQL调度方法
-
目标:了解Oracle与MySQL的调度方法
-
实施
-
Oracle调度:参考《oracle任务调度详细操作文档.md》
- step1:本地安装Oracle客户端
- step2:安装AirFlow集成Oracle库
- step3:创建Oracle连接
- step4:开发测试
query_oracle_task = OracleOperator( task_id = 'oracle\_operator\_task', sql = 'select \* from ciss4.ciss\_base\_areas', oracle_conn_id = 'oracle-airflow-connection', autocommit = True, dag=dag ) -
MySQL调度:《MySQL任务调度详细操作文档.md》
-
step1:本地安装MySQL客户端
-
step2:安装AirFlow集成MySQL库
-
step3:创建MySQL连接
-
step4:开发测试
- 方式一:指定SQL语句
query_table_mysql_task = MySqlOperator( task_id='query\_table\_mysql', mysql_conn_id='mysql\_airflow\_connection', sql=r"""select \* from test.test\_airflow\_mysql\_task;""", dag=dag )+ 方式二:指定SQL文件 ``` query_table_mysql_task = MySqlOperator( task_id='query\_table\_mysql\_second', mysql_conn_id='mysql-airflow-connection', sql='test\_airflow\_mysql\_task.sql', dag=dag ) ```- 方式三:指定变量
insert_sql = r""" INSERT INTO `test`.`test\_airflow\_mysql\_task`(`task\_name`) VALUES ( 'test airflow mysql task3'); INSERT INTO `test`.`test\_airflow\_mysql\_task`(`task\_name`) VALUES ( 'test airflow mysql task4'); INSERT INTO `test`.`test\_airflow\_mysql\_task`(`task\_name`) VALUES ( 'test airflow mysql task5'); """ insert_table_mysql_task = MySqlOperator( task_id='mysql\_operator\_insert\_task', mysql_conn_id='mysql-airflow-connection', sql=insert_sql, dag=dag )
-
-
-
小结
- 了解Oracle与MySQL的调度方法
知识点11:大数据组件调度方法
-
目标:了解大数据组件调度方法
-
实施
-
AirFlow支持的类型
- HiveOperator
- PrestoOperator
- SparkSqlOperator
-
需求:Sqoop、MR、Hive、Spark、Flink
-
解决:统一使用BashOperator或者PythonOperator,将对应程序封装在脚本中
- Sqoop
run_sqoop_task = BashOperator( task_id='sqoop\_task', bash_command='sqoop --options-file xxxx.sqoop', dag=dag, )- Hive
run_hive_task = BashOperator( task_id='hive\_task', bash_command='hive -f xxxx.sql', dag=dag, )- Spark
run_spark_task = BashOperator( task_id='spark\_task', bash_command='spark-sql -f xxxx.sql', dag=dag, )- Flink
run_flink_task = BashOperator( task_id='flink\_task', bash_command='flink run /opt/flink-1.12.2/examples/batch/WordCount.jar', dag=dag, )
-
-
小结
- 了解大数据组件调度方法



既有适合小白学习的零基础资料,也有适合3年以上经验的小伙伴深入学习提升的进阶课程,涵盖了95%以上大数据知识点,真正体系化!
由于文件比较多,这里只是将部分目录截图出来,全套包含大厂面经、学习笔记、源码讲义、实战项目、大纲路线、讲解视频,并且后续会持续更新
gfcV-1715732389968)]
[外链图片转存中…(img-m6UQ1ZEa-1715732389968)]
[外链图片转存中…(img-zuP1GiEq-1715732389968)]
既有适合小白学习的零基础资料,也有适合3年以上经验的小伙伴深入学习提升的进阶课程,涵盖了95%以上大数据知识点,真正体系化!
由于文件比较多,这里只是将部分目录截图出来,全套包含大厂面经、学习笔记、源码讲义、实战项目、大纲路线、讲解视频,并且后续会持续更新















 124
124

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









