






OpenAI 发布 o1 系列大模型,AI 大模型进入新纪元**。**9 月 12 日,OpenAI 宣布开发了一系列全新AI 模型,其被命名为 OpenAI o1-preview,旨在在回应前投入更多时间思考。与之前的模型相比,这些模型能够更好地进行推理,并在科学、编程和数学等领域 解决更为复杂的问题。
o1 在物理、化 学和生物学等困难的基准任务中表现与博士生相似,此外,o1 在数学和编程领 域也表现优异。在国际数学奥林匹克竞赛的资格考试中,GPT-4o 仅正确解答了 **13%**的问题,而 OpenAI o1 的正确率达到了 83%。在 Codeforces 编程比赛中, OpenAI o1 的表现达到了第 89 个百分位。

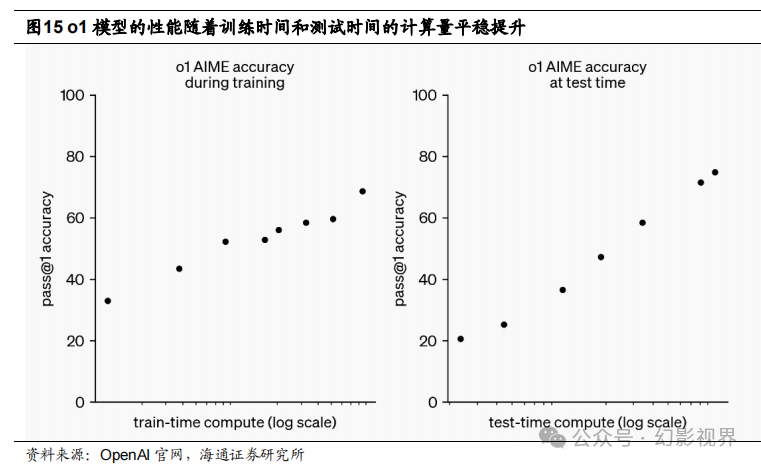
OpenAI o1 带来的是推理范式 的全面革新,即利用大语言模型学习推理(Learning to Reason with LLMs)。 OpenAI 的大规模强化学习算法通过高度数据高效的训练过程,教会模型如何通 过思维链条进行有效推理。OpenAI **发现,**o1 模型的性能随着更多的强化学习 (训练时的计算量)以及更多的思考时间(测试时的计算量)而持续提升。
我们认为,OpenAI o1 并非是颠覆式的技术革命,但是其在工程化 上已经达到了领先的地位,其在**自我对弈强化学习(Self-play RL)、思维链条 (CoT)、过程奖励模型(PRM)**等技术实践运用方面取得了显著的进步,并且 在深度思考和复杂推理上展现出了较高的能力。我们认为,o1 代表着 Scaling up **从预训练到推理的转变。**o1 带来的大模型技术创新,正推动 AI 向更深层次 的智能推理与问题解决能力发展。
幻影视界今天分享的是人工智能AI行业研究报告:**《OpenAI o1初探:或能成为引领AI Phenomenal Ride的LLM新范式》,**报告版权方/来源:海通证券。
研究报告内容摘要如下****
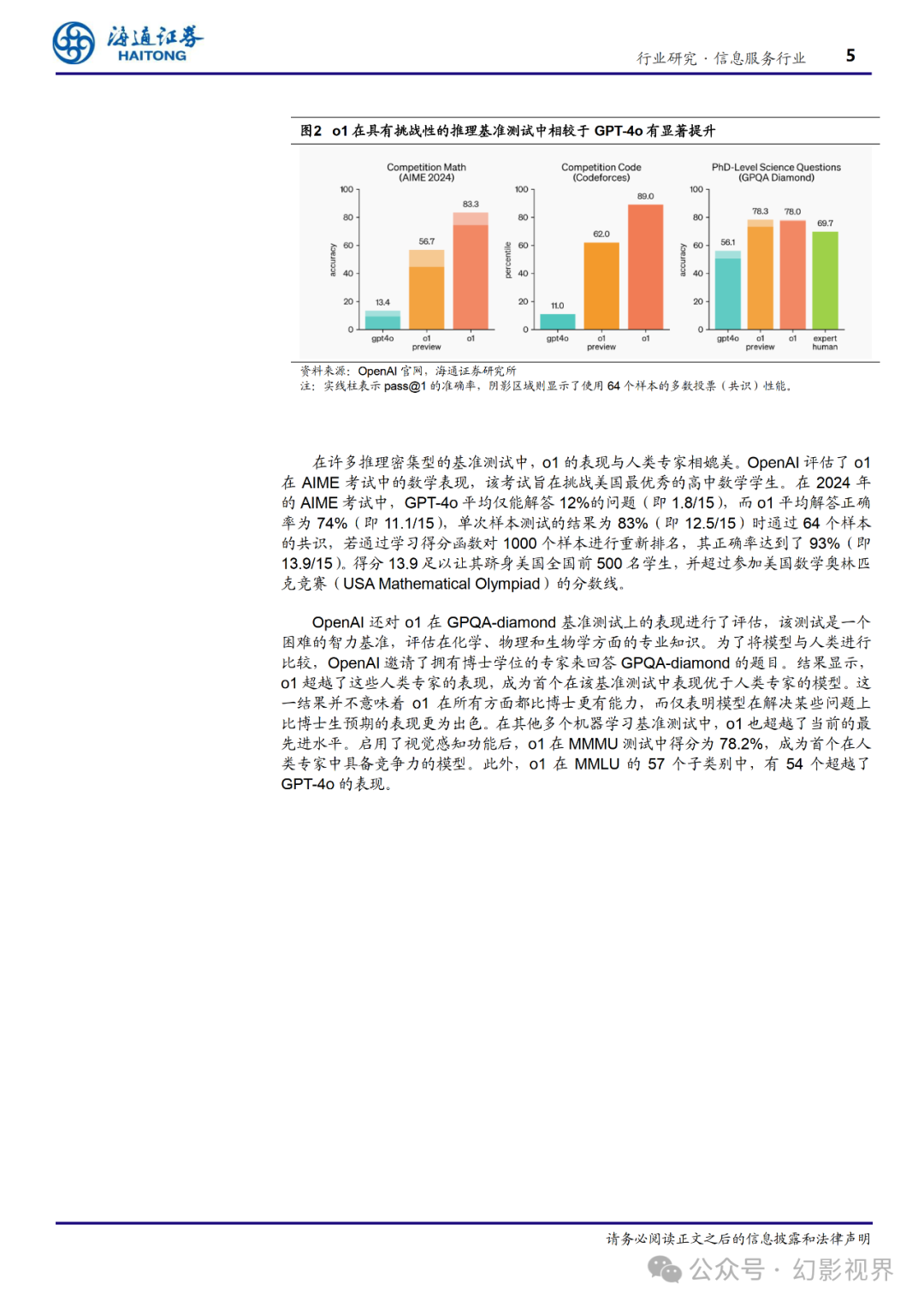
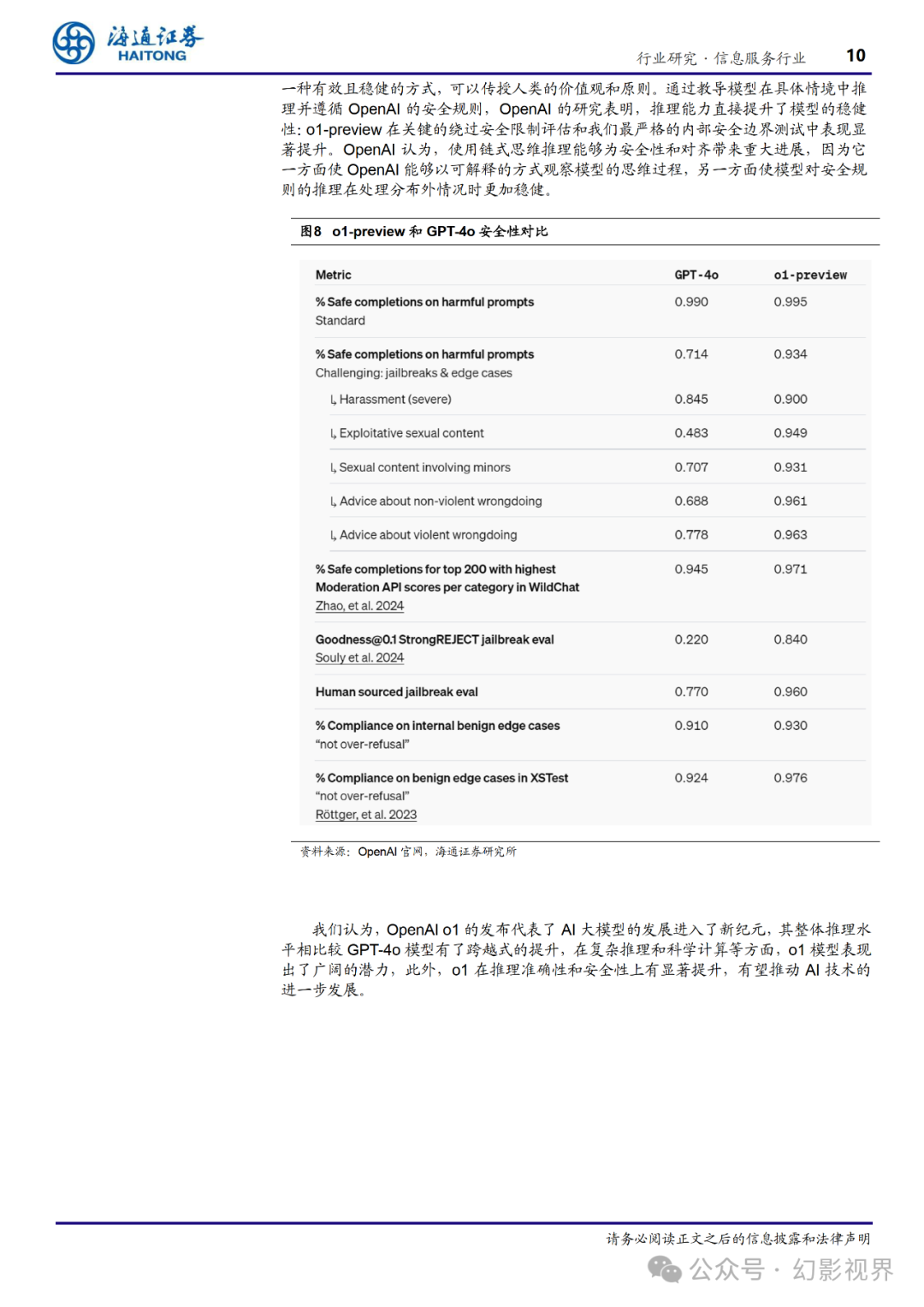
在 OpenAI 的测试中,OpenAI o1 在物理、化学和生物学等困难的基准任务中表现 与博士生相似。此外,OpenAI o1 在数学和编程领域也表现优异。在国际数学奥林匹克 竞赛(IMO)的资格考试中,GPT-4o 仅正确解答了 13%的问题,而 OpenAI o1 的正确 率达到了 83%。在 Codeforces 编程比赛中,OpenAI o1 的表现达到了第 89 个百分位。在 OpenAI 看来,这些增强的推理能力可能对解决科学、编程、数学等领域的复杂问题 特别有用。例如,o1 模型可以帮助医疗研究人员注释细胞测序数据,物理学家生成量子 光学所需的复杂数学公式,开发者在各个领域构建和执行多步工作流。
为了突出相较于 GPT-4o 在推理能力上的提升,OpenAI 对模型进行了多样化的人 类考试和机器学习基准测试。结果显示,o1 在绝大多数推理密集型任务中明显优于 GPT-4o。
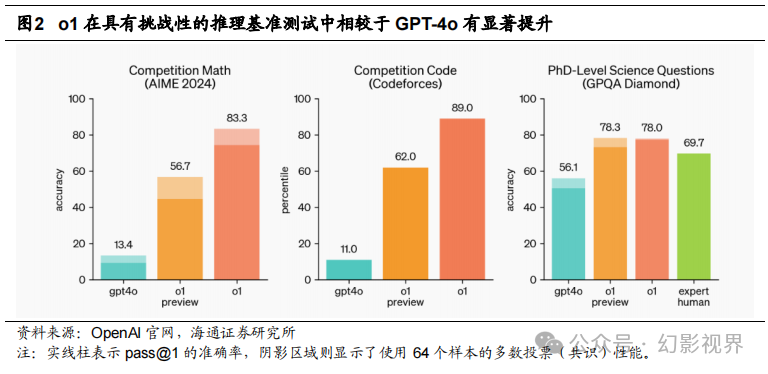
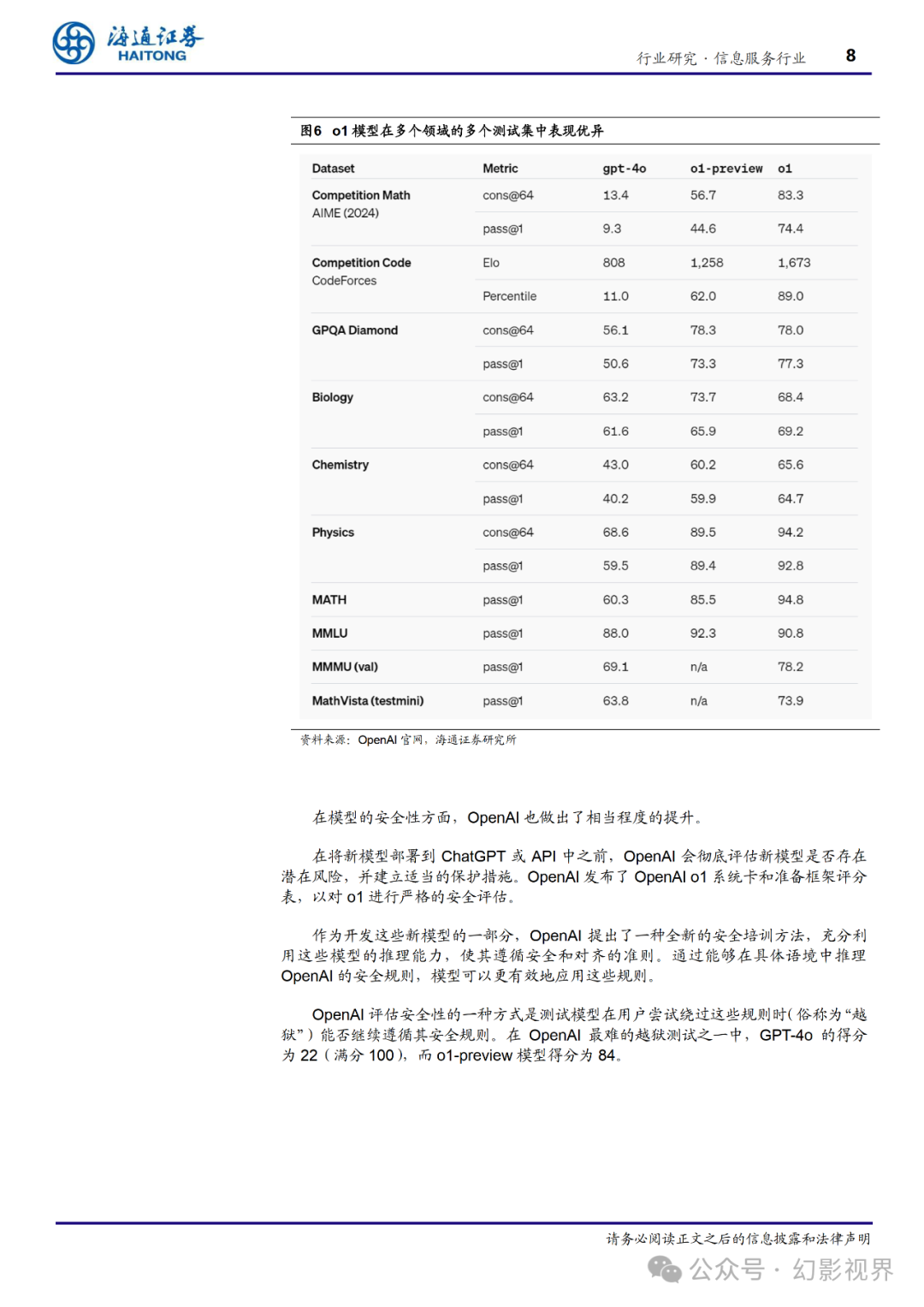
在许多推理密集型的基准测试中,o1 的表现与人类专家相媲美。OpenAI 评估了 o1 在 AIME 考试中的数学表现,该考试旨在挑战美国最优秀的高中数学学生。在 2024 年 的 AIME 考试中,GPT-4o 平均仅能解答 12%的问题(即 1.8/15),而 o1 平均解答正确 率为 74%(即 11.1/15),单次样本测试的结果为 83%(即 12.5/15)时通过 64 个样本 的共识,若通过学习得分函数对 1000 个样本进行重新排名,其正确率达到了 93%(即 13.9/15)。得分 13.9 足以让其跻身美国全国前 500 名学生,并超过参加美国数学奥林匹 克竞赛(USA Mathematical Olympiad)的分数线。
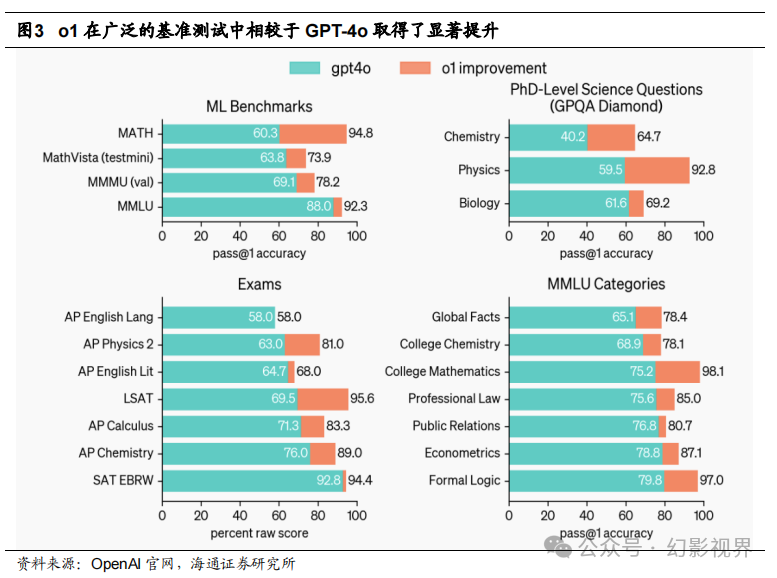
OpenAI 还对 o1 在 GPQA-diamond **基准测试上的表现进行了评估,该测试是一个 困难的智力基准,评估在化学、物理和生物学方面的专业知识。**为了将模型与人类进行 比较,OpenAI 邀请了拥有博士学位的专家来回答 GPQA-diamond 的题目。结果显示, o1 超越了这些人类专家的表现,成为首个在该基准测试中表现优于人类专家的模型。这 一结果并不意味着 o1 在所有方面都比博士更有能力,而仅表明模型在解决某些问题上 比博士生预期的表现更为出色。在其他多个机器学习基准测试中,o1 也超越了当前的最 先进水平。启用了视觉感知功能后,o1 在 MMMU 测试中得分为 78.2%,成为首个在人 类专家中具备竞争力的模型。此外,o1 在 MMLU 的 57 个子类别中,有 54 个超越了 GPT-4o 的表现。
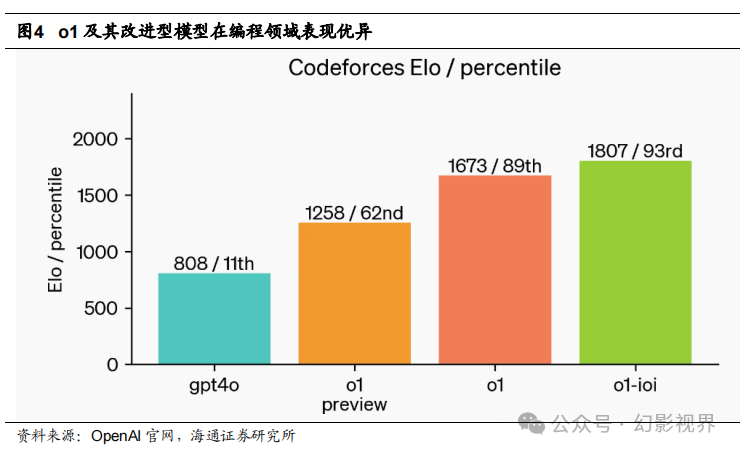
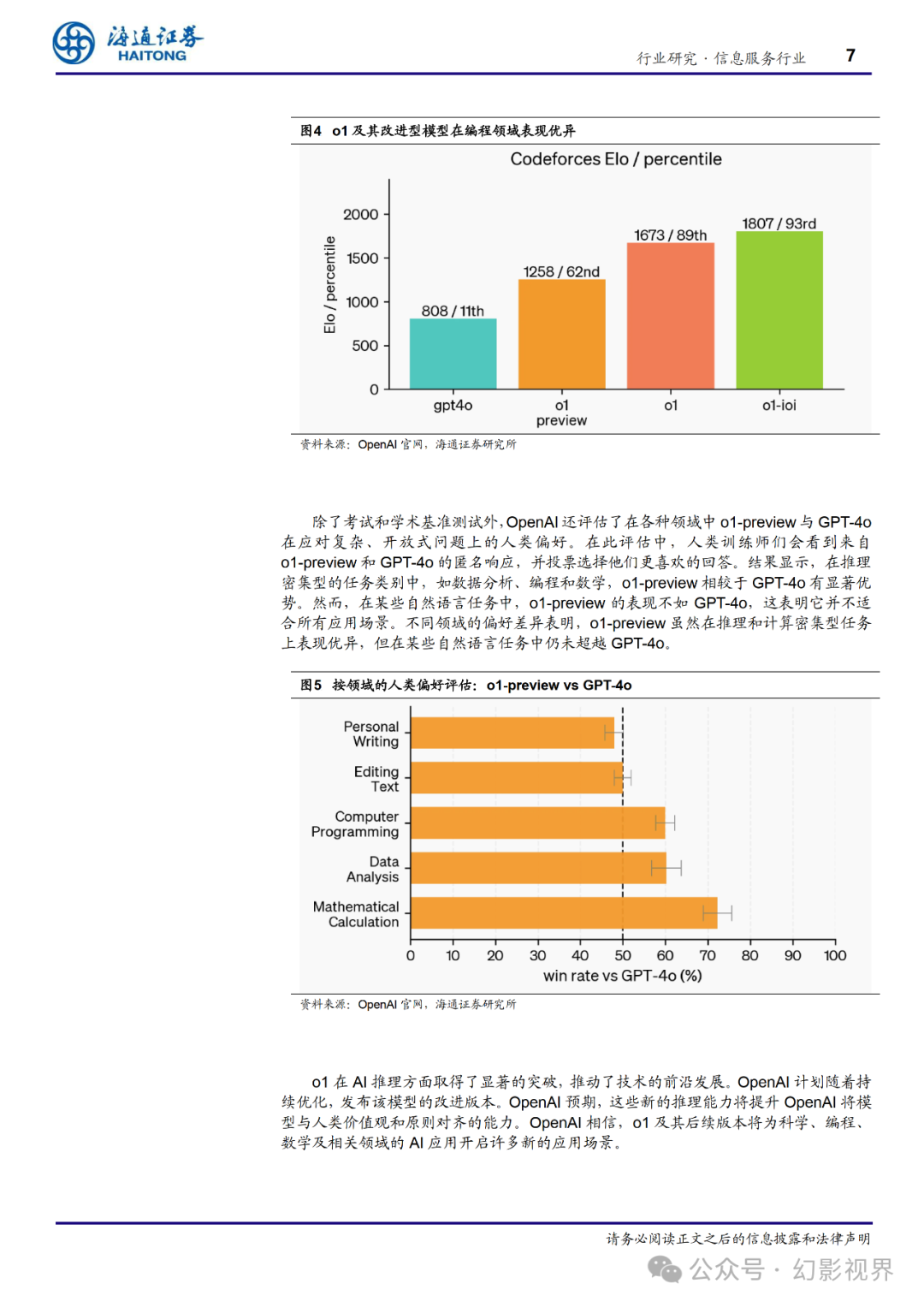
o1 在编程领域表现优异,OpenAI 训练了一款模型,命名为 o1-ioi,这个模型在 2024 年国际信息学奥林匹克竞赛(IOI)中获得了 213 分,排名在第 49 百分位。该模型基于 o1 进行初始化,并进一步训练以提升编程技能。
o1-ioi 在 2024 年 IOI 比赛中与人类参赛者在相同条件下竞争,有 10 小时的时间解 决 6 道复杂的算法问题,每题允许提交 50 **次解答。**对于每个问题,OpenAI 的系统生成 了多个候选解答,并根据测试时的选择策略提交了 50 次解答。提交选择基于 IOI 公开测 试案例、模型生成的测试案例以及学习到的评分函数。如果 OpenAI 随机提交解答,平 均分数仅为 156 分,这表明该策略在比赛条件下贡献了近 60 分的提升。当放宽提交次 数限制时,模型的表现显著提升。在每题允许提交 10000 次的情况下,o1-ioi 的得分达 到 362.14 分,超过了金牌门槛,且不需要任何测试时的选择策略。
**最后,**OpenAI 模拟了 Codeforces 平台上举办的竞争性编程比赛,以展示 o1-ioi **的 编程能力。**OpenAI 的评估严格遵循比赛规则,并允许 10 次提交。GPT-4o 的 Elo 评分 为 808,位于人类竞争者的第 11 百分位。而 o1-ioi 远远超越了 GPT-4o 和 o1,达到了 1807 的 Elo 评分,表现超过了 93%的参赛者。
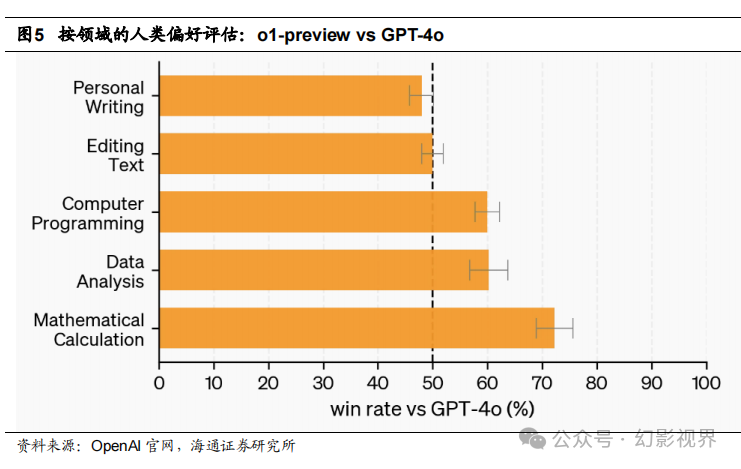
除了考试和学术基准测试外,OpenAI 还评估了在各种领域中 o1-preview 与 GPT-4o 在应对复杂、开放式问题上的人类偏好。在此评估中,人类训练师们会看到来自 o1-preview 和 GPT-4o 的匿名响应,并投票选择他们更喜欢的回答。结果显示,在推理 密集型的任务类别中,如数据分析、编程和数学,o1-preview 相较于 GPT-4o 有显著优 势。然而,在某些自然语言任务中,o1-preview 的表现不如 GPT-4o,这表明它并不适 合所有应用场景。不同领域的偏好差异表明,o1-preview 虽然在推理和计算密集型任务 上表现优异,但在某些自然语言任务中仍未超越 GPT-4o。
o1 在 AI 推理方面取得了显著的突破,推动了技术的前沿发展。OpenAI 计划随着持 续优化,发布该模型的改进版本。OpenAI 预期,这些新的推理能力将提升 OpenAI 将模 型与人类价值观和原则对齐的能力。OpenAI 相信,o1 及其后续版本将为科学、编程、 数学及相关领域的 AI 应用开启许多新的应用场景。

**全新的推理范式:思维链条+**自我对弈强化学习
OpenAI o1 带来的是推理范式的全面革新,即利用大语言模型学习推理(Learning to Reason with LLMs)。OpenAI 的大规模强化学习算法通过高度数据高效的训练过程,教会模型如何通过 思维链条进行有效推理。OpenAI 发现,o1 模型的性能随着更多的强化学习(训练时的 计算量)以及更多的思考时间(测试时的计算量)而持续提升。这种方法的扩展约束与 LLM 的预训练方式有显著不同,OpenAI 仍在继续探索其中的奥秘。
OpenAI o1**,能给** AI 带来什么?
我们认为,OpenAI o1 的命名,从某种意义上摆脱了 GPT(Generative Pre-trained Transformer)这一过去命名过分强调预训练(Pre-trained)的意味,而是让它更成为 一个更强调推理能力训练的模型系列。 我们认为,o1 至少为困于数据和基建无法快速提升预训练规模的模型公司们提供 了一个新的角度,从推理侧和强化学习的方法入手,加强模型的能力。
从某种意义上, OpenAI o1 **确实是第一个“推理模型”。**根据腾讯科技,月之暗面创始人杨植麟在一场分享中谈到了他对 o1 的看法,他认 为,规模定律之后,大模型发展的下一个范式是强化学习,OpenAI o1 模型的发布,通 过强化学习尝试突破数据墙,并看到计算更多向推理侧增加的趋势。
从应用的角度来看,o1 在很多领域的并不像现有的 GPT-4o 一样突出,在某些自 然语言任务中,可能 o1 的表现仍不如 GPT-4o,OpenAI 对 o1-mini 的评价更是“缺乏 广泛的世界知识”,此外 o1 也没有浏览网页或处理文件和图像的能力。
但是,在推理密集型的任务类别中,如数据分析、编程和数学,o1 相较于 GPT-4o 有显著优势,例如基于 o1 针对编程能力优化的 o1-ioi 在放宽提交次数限制时,能够在 2024 年国际信息学奥林匹克竞赛得分达到 362.14 分,超过了金牌门槛,且不需要任何 测试时的选择策略,在某种程度上,我们认为,可以说 o1 在部分细分领域已经接近了 当前人类的天花板,这就使得 o1 在部分细分的应用场景,已经接近“替代大部分人类” 这一目标。
根据 o1 现在的表现,我们认为,o1 处理复杂任务能力更加突出,它的先进推理能 力可以提升科学研究、数学计算和编程领域的效率,我们推测,这可能是因为这些领域 的任务通常具有明确的规则和目标,使得奖励函数更容易设计和优化,PRM 运作效率更 高,但这也代表未来 o1 在 STEM 领域可能有更多的应用空间,还可能推动人工智能在 生物制药、IC 制造等行业的创新应用,按照 o1 的发展思路,也许未来,人们能够让 AI **思考数小时、数天甚至数周,伴随着更高的推理成本,人类也会离新的抗癌药物、突破 性的电池甚至黎曼猜想的证明更近。 当然值得注意的是,**o1 目前仍处于 AI 发展的初级阶段。 根据深圳市人工智能产业协会官微,OpenAI 给 AI 划分了五个发展阶段。

第一级,「ChatBots」聊天机器人,比如 ChatGPT。
第二级,「Reasoners」推理者,解决博士水平基础问题的系统。
第三级,「Agents」智能体,代表用户采取行动的 AI 代理。
第四级,「Innovators」创新者,帮助发明的 AI。
第五级,「Organizations」组织,AI 可以执行整个人类组织的工作,这是实现 AGI的最后一步。
**我们认为,按照这个标准,**o1 目前在第二级,人类距离 AGI 的道路仍然道阻且长。 不过,根据 Tracking AI,o1 在最新门萨智商测试中,IQ 水平超过了 120 分,远超 目前业界其他大模型的水平,而且值得注意的是,这仅仅是 o1-preview 的水平,这也 代表着 o1 这类大模型所蕴含的巨大潜能。

**我们相信,**o1 代表的是全新的大模型推理范式,这一范式也许能够改变人们对于“智 能”这一概念的理解,当然,正如 Ilya 的论文标题所写,这仍需要“一步步验证(Let’s Verify Step by Step)”,但是也许数十年后,回望如今,我们也能说出,我们很幸运能够 “at the right place at the right time”,这是属于 AI 的“Phenomenal Ride”。
幻影视界整理分享报告原文节选如下:





大模型&AI产品经理如何学习
求大家的点赞和收藏,我花2万买的大模型学习资料免费共享给你们,来看看有哪些东西。
1.学习路线图

第一阶段: 从大模型系统设计入手,讲解大模型的主要方法;
第二阶段: 在通过大模型提示词工程从Prompts角度入手更好发挥模型的作用;
第三阶段: 大模型平台应用开发借助阿里云PAI平台构建电商领域虚拟试衣系统;
第四阶段: 大模型知识库应用开发以LangChain框架为例,构建物流行业咨询智能问答系统;
第五阶段: 大模型微调开发借助以大健康、新零售、新媒体领域构建适合当前领域大模型;
第六阶段: 以SD多模态大模型为主,搭建了文生图小程序案例;
第七阶段: 以大模型平台应用与开发为主,通过星火大模型,文心大模型等成熟大模型构建大模型行业应用。
2.视频教程
网上虽然也有很多的学习资源,但基本上都残缺不全的,这是我自己整理的大模型视频教程,上面路线图的每一个知识点,我都有配套的视频讲解。


(都打包成一块的了,不能一一展开,总共300多集)
因篇幅有限,仅展示部分资料,需要点击下方图片前往获取
3.技术文档和电子书
这里主要整理了大模型相关PDF书籍、行业报告、文档,有几百本,都是目前行业最新的。

4.LLM面试题和面经合集
这里主要整理了行业目前最新的大模型面试题和各种大厂offer面经合集。

👉学会后的收获:👈
• 基于大模型全栈工程实现(前端、后端、产品经理、设计、数据分析等),通过这门课可获得不同能力;
• 能够利用大模型解决相关实际项目需求: 大数据时代,越来越多的企业和机构需要处理海量数据,利用大模型技术可以更好地处理这些数据,提高数据分析和决策的准确性。因此,掌握大模型应用开发技能,可以让程序员更好地应对实际项目需求;
• 基于大模型和企业数据AI应用开发,实现大模型理论、掌握GPU算力、硬件、LangChain开发框架和项目实战技能, 学会Fine-tuning垂直训练大模型(数据准备、数据蒸馏、大模型部署)一站式掌握;
• 能够完成时下热门大模型垂直领域模型训练能力,提高程序员的编码能力: 大模型应用开发需要掌握机器学习算法、深度学习框架等技术,这些技术的掌握可以提高程序员的编码能力和分析能力,让程序员更加熟练地编写高质量的代码。

1.AI大模型学习路线图
2.100套AI大模型商业化落地方案
3.100集大模型视频教程
4.200本大模型PDF书籍
5.LLM面试题合集
6.AI产品经理资源合集
👉获取方式:
😝有需要的小伙伴,可以保存图片到wx扫描二v码免费领取【保证100%免费】🆓
















 2万+
2万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









