







}
g_driver_table = NULL;
}
}
……
return array;
}
虚拟索引的核心功能全部位于hypopg\_index.cpp文件中。用户通过SQL语句调用系统函数hypopg\_create\_index来创建虚拟索引,该系统函数主要通过调用hypo\_index\_store\_parsetree函数来完成虚拟索引的创建。虚拟索引的结构体名为hypoIndex,该结构体的许多字段是从它涉及的表的RelOptInfo结构体中读取的,hypoIndex的结构如下:
typedef struct hypoIndex {
Oid oid; /* 虚拟索引的oid,该oid是唯一的 /
Oid relid; / 涉及的表的oid */
…
char indexname; / 虚拟索引名 */
BlockNumber pages; /* 预估索引使用的磁盘页数 */
double tuples; /* 预估索引所涉及的元组数目 */
/* 索引描述信息 */
int ncolumns; /* 涉及的总列数 */
int nkeycolumns; /* 涉及的关键列数 */
…
Oid relam; /* 记录索引操作回调函数的元组的oid, 从pg_am系统表中获取的 */
…
} hypoIndex;
函数hypo\_index\_store\_parsetree的输入参数为创建索引的SQL语句和其语法树,依据该语句的解析结果来创建新的虚拟索引,代码如下:
hypoIndex *hypo_index_store_parsetree(IndexStmt *node, const char queryString)
{
……
// 获得创建索引的表的oid
relid = RangeVarGetRelid(node->relation, AccessShareLock, false);
……
// 对该创建索引的语句进行语法解析
node = transformIndexStmt(relid, node, queryString);
……
// 新建虚拟索引,该虚拟索引的结构体类型hypoIndex定于位于文件openGauss-server/src/include/dbmind/hypopg_index.h,与索引结构体IndexOptInfo类似
entry = hypo_newIndex(relid, node->accessMethod, nkeycolumns, ninccolumns, node->options);
// 根据语法树的解析结果为虚拟索引entry内的各个成员赋值
PG_TRY();
{
……
entry->unique = node->unique;
entry->ncolumns = nkeycolumns + ninccolumns;
entry->nkeycolumns = nkeycolumns;
……
}
PG_CATCH();
{
hypo_index_pfree(entry);
PG_RE_THROW();
}
PG_END_TRY();
// 设置虚拟索引的名字
hypo_set_indexname(entry, indexRelationName.data);
// 将新建的虚拟索引entry添加到虚拟索引的全局链表hypoIndexes上,该全局变量为节点类型为hypoIndex的List链表,记录了全部创建过的虚拟索引
hypo_addIndex(entry);
return entry;
}
// 该函数被赋值给全局的函数指针get_relation_info_hook,当数据库执行EXPLAIN时,会通过该函数指针跳转到本函数
void hypo_get_relation_info_hook(PlannerInfo *root, Oid relationObjectId, bool inhparent, RelOptInfo rel)
{
/ 判断是否开启GUC参数enable_hypo_index,当SQL语句是EXPLAIN命令时,变量isExplain的值为真 */
if (u_sess->attr.attr_sql.enable_hypo_index && isExplain) {
Relation relation;
relation = heap_open(relationObjectId, AccessShareLock);
if (relation->rd_rel->relkind == RELKIND_RELATION) {
ListCell *lc;
/* 遍历全局变量链表hypoIndexes中的每个创建过的虚拟索引 */
foreach (lc, hypoIndexes) {
hypoIndex *entry = (hypoIndex *)lfirst(lc);
// 判断该虚拟索引和该表是否匹配
if (hypo_index_match_table(entry, RelationGetRelid(relation))) {
// 如果匹配,则将该索引加入该表的indexlist中,indexlist是节点类型为IndexOptInfo的链表,是结构体类型RelOptInfo的成员,记录了表的所有的索引
hypo_injectHypotheticalIndex(root, relationObjectId, inhparent, rel, relation, entry);
}
}
}
heap_close(relation, AccessShareLock);
}
……
}
### 8.4.5 使用示例
#### 1. 单条查询语句的索引推荐
单条查询语句的索引推荐功能支持用户在数据库中直接进行操作,本功能基于查询语句的语义信息和数据库的统计信息,对用户输入的单条查询语句生成推荐的索引。本功能涉及的函数接口如表8-9所示。
表8-9 单query索引推荐功能的函数接口
| 函数名 | 参数 | 返回值 | 功能 |
| --- | --- | --- | --- |
| gs\_index\_advise | SQL语句字符串 | 无 | 针对单条查询语句生成推荐索引(该版本只支持B树索引) |
使用上述函数,获取针对该query生成的推荐索引,推荐结果由索引的表名和列名组成。
opengauss=> select * from gs_index_advise(‘SELECT c_discount from bmsql_customer where c_w_id = 10’);
table | column
----------------±---------
bmsql_customer | (c_w_id)
(1 row)
上述结果表明:应当在bmsql\_customer的c\_w\_id列上创建索引,例如可以通过下述SQL语句创建索引。
CREATE INDEX idx on bmsql_customer(c_w_id);
某些SQL语句,也可能被推荐创建联合索引,例如:
opengauss=# select * from gs_index_advise(‘select name, age, sex from t1 where age >= 18 and age < 35 and sex = ‘‘f’’;’);
table | column
-------±-----------
t1 | (age, sex)
(1 row)
上述语句结果表明应该在表t1上创建一个联合索引(age, sex),可以通过下述命令创建该索引,并将其命名为idx1。
CREATE INDEX idx1 on t1(age, sex);
#### 2. 虚拟索引
虚拟索引功能支持用户在数据库中直接进行操作,该功能模拟真实索引的建立,避免真实索引创建所需的时间和空间开销,用户基于虚拟索引,可通过优化器评估该索引对指定查询语句的代价影响。
虚拟索引功能涉及的系统函数接口如表8-10所示。
表8-10 虚拟索引功能的接口
| 函数名 | 参数 | 返回值 | 功能 |
| --- | --- | --- | --- |
| hypopg\_create\_index | 创建索引语句的字符串 | 无 | 创建虚拟索引 |
| hypopg\_display\_index | 无 | 结果集 | 显示所有创建的虚拟索引信息 |
| hypopg\_drop\_index | 索引的oid | 无 | 删除指定的虚拟索引 |
| hypopg\_reset\_index | 无 | 无 | 清除所有虚拟索引 |
| hypopg\_estimate\_size | 索引的oid | 整数型 | 估计指定索引创建所需的空间大小 |
本功能涉及的GUC参数如表8-11所示。
表8-11 GUC参数
| | | | | |
| --- | --- | --- | --- | --- |
| 参数名 | 级别 | 功能 | 类型 | 默认值 |
| enable\_hypo\_index | PGC\_USERSET | 是否开启虚拟索引功能 | bool | off |
(1) 使用hypopg\_create\_index函数创建虚拟索引。例如:
opengauss=> select * from hypopg_create_index(‘create index on bmsql_customer(c_w_id)’);
indexrelid | indexname
------------±------------------------------------
329726 | <329726>btree_bmsql_customer_c_w_id
(1 row)
(2) 开启GUC参数enable\_hypo\_index,该参数控制数据库的优化器进行EXPLAIN时是否考虑创建的虚拟索引。通过对特定的查询语句执行explain,用户可根据优化器给出的执行计划评估该索引是否能够提升该查询语句的执行效率。例如:
opengauss=> set enable_hypo_index = on;
SET
开启GUC参数前,执行EXPLAIN+查询语句,如下所示:
opengauss=> explain SELECT c_discount from bmsql_customer where c_w_id = 10;
QUERY PLAN
Seq Scan on bmsql_customer (cost=0.00…52963.06 rows=31224 width=4)
Filter: (c_w_id = 10)
(2 rows)
开启GUC参数后,执行EXPLAIN+查询语句,如下所示:
opengauss=> explain SELECT c_discount from bmsql_customer where c_w_id = 10;
QUERY PLAN
[Bypass]
Index Scan using <329726>btree_bmsql_customer_c_w_id on bmsql_customer (cost=0.00…39678.69 rows=31224 width=4)
Index Cond: (c_w_id = 10)
(3 rows)
通过对比两个执行计划可以观察到,该索引预计会降低指定查询语句的执行代价,用户可考虑创建对应的真实索引。
(3) (可选)使用hypopg\_display\_index函数展示所有创建过的虚拟索引。例如:
opengauss=> select * from hypopg_display_index();
indexname | indexrelid | table | column
--------------------------------------------±-----------±---------------±-----------------
<329726>btree_bmsql_customer_c_w_id | 329726 | bmsql_customer | (c_w_id)
<329729>btree_bmsql_customer_c_d_id_c_w_id | 329729 | bmsql_customer | (c_d_id, c_w_id)
(2 rows)
(4) (可选)使用hypopg\_estimate\_size函数估计虚拟索引创建所需的空间大小(单位:字节)。例如:
opengauss=> select * from hypopg_estimate_size(329730);
hypopg_estimate_size
15687680
(1 row)
(5) 删除虚拟索引。
① 使用hypopg\_drop\_index函数删除指定oid的虚拟索引。例如:
opengauss=> select * from hypopg_drop_index(329726);
hypopg_drop_index
t
(1 row)
② 使用hypopg\_reset\_index函数一次性清除所有创建的虚拟索引。例如:
opengauss=> select * from hypopg_reset_index();
hypopg_reset_index
(1 row)
#### 3. 基于工作负载的索引推荐
对于工作负载级别的索引推荐,用户可通过运行数据库外的脚本使用此功能,本功能将包含有多条DML语句的工作负载作为输入,最终生成一批可对针对整体工作负载的索引。
(1) 准备好包含有多条DML语句的文件作为输入的工作负载,文件中每条语句占据一行。用户可从数据库的离线日志中获得历史的业务语句。
(2) 运行python脚本index\_advisor\_workload.py,命令如下:
python index_advisor_workload.py [p PORT] [d DATABASE] [f FILE] [–h HOST] [-U USERNAME] [-W PASSWORD]
[–max_index_num MAX_INDEX_NUM] [–multi_iter_mode]
还有兄弟不知道网络安全面试可以提前刷题吗?费时一周整理的160+网络安全面试题,金九银十,做网络安全面试里的显眼包!
王岚嵚工程师面试题(附答案),只能帮兄弟们到这儿了!如果你能答对70%,找一个安全工作,问题不大。
对于有1-3年工作经验,想要跳槽的朋友来说,也是很好的温习资料!
【完整版领取方式在文末!!】
93道网络安全面试题
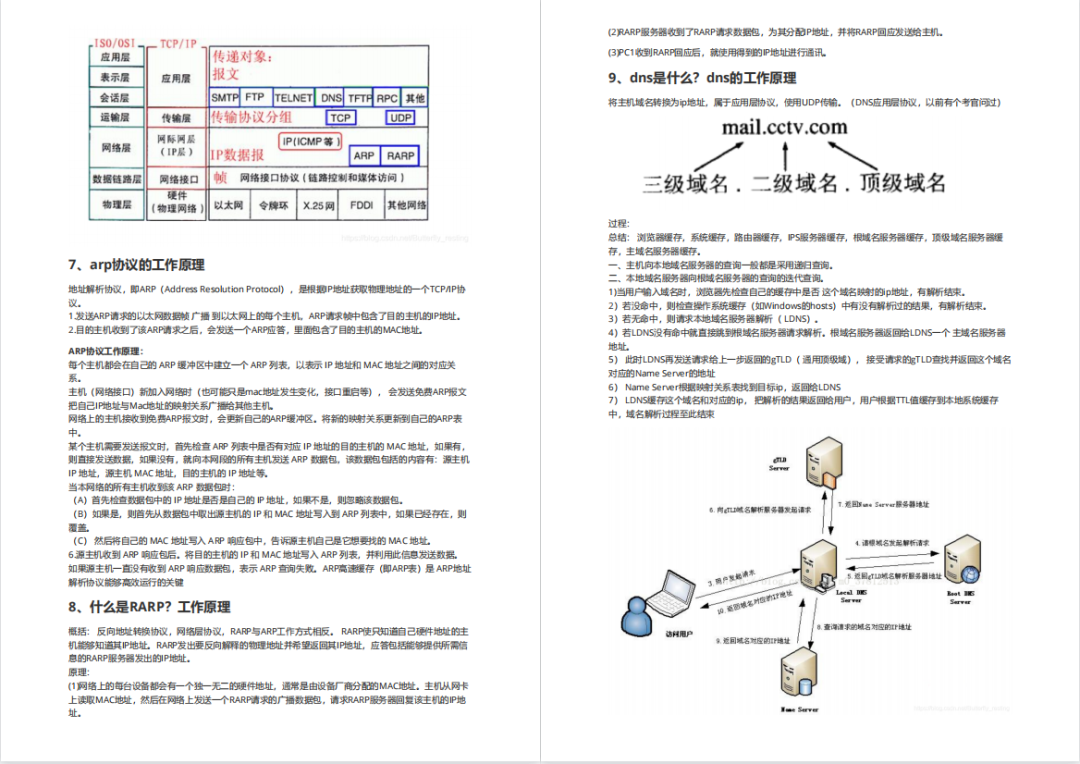


内容实在太多,不一一截图了
黑客学习资源推荐
最后给大家分享一份全套的网络安全学习资料,给那些想学习 网络安全的小伙伴们一点帮助!
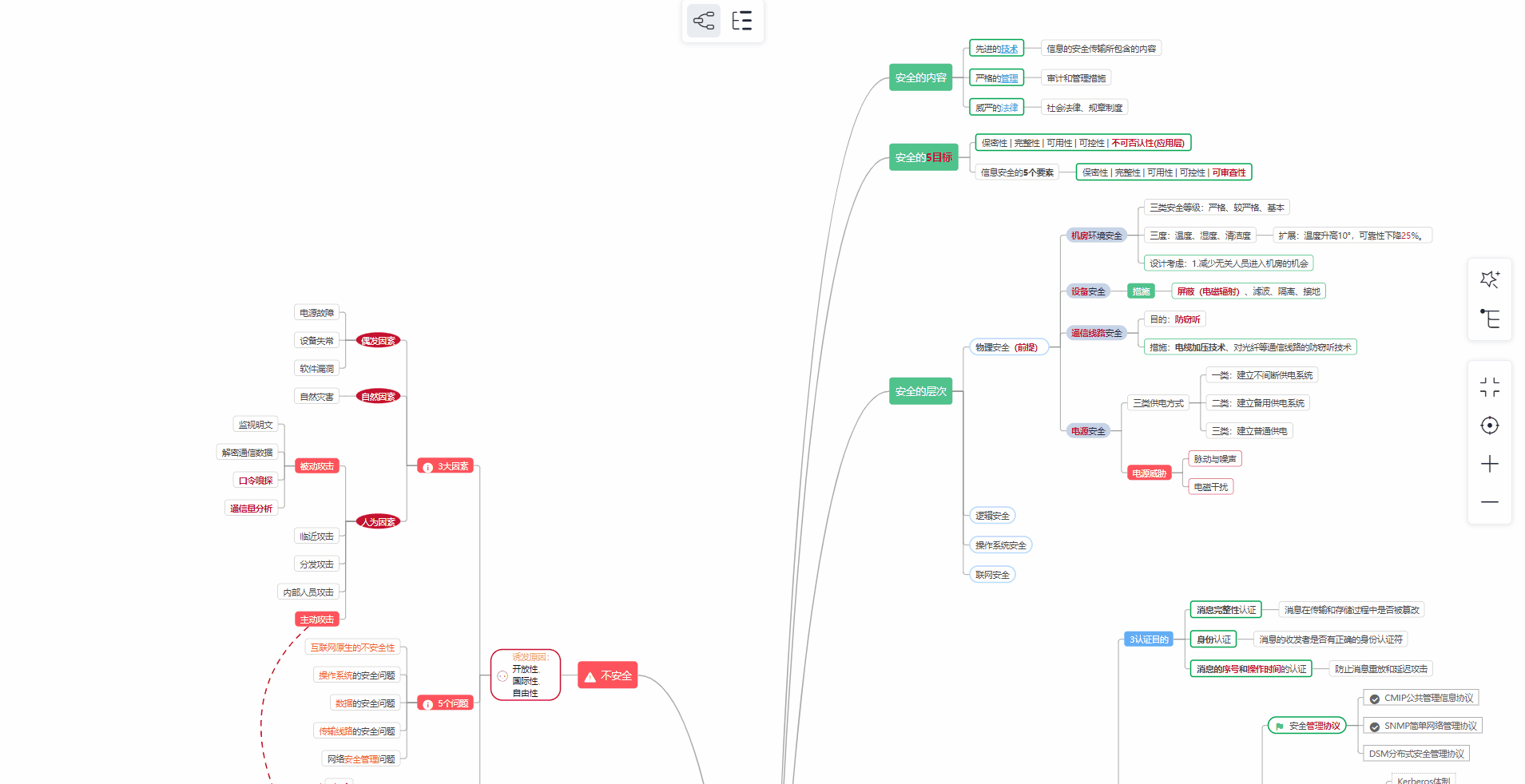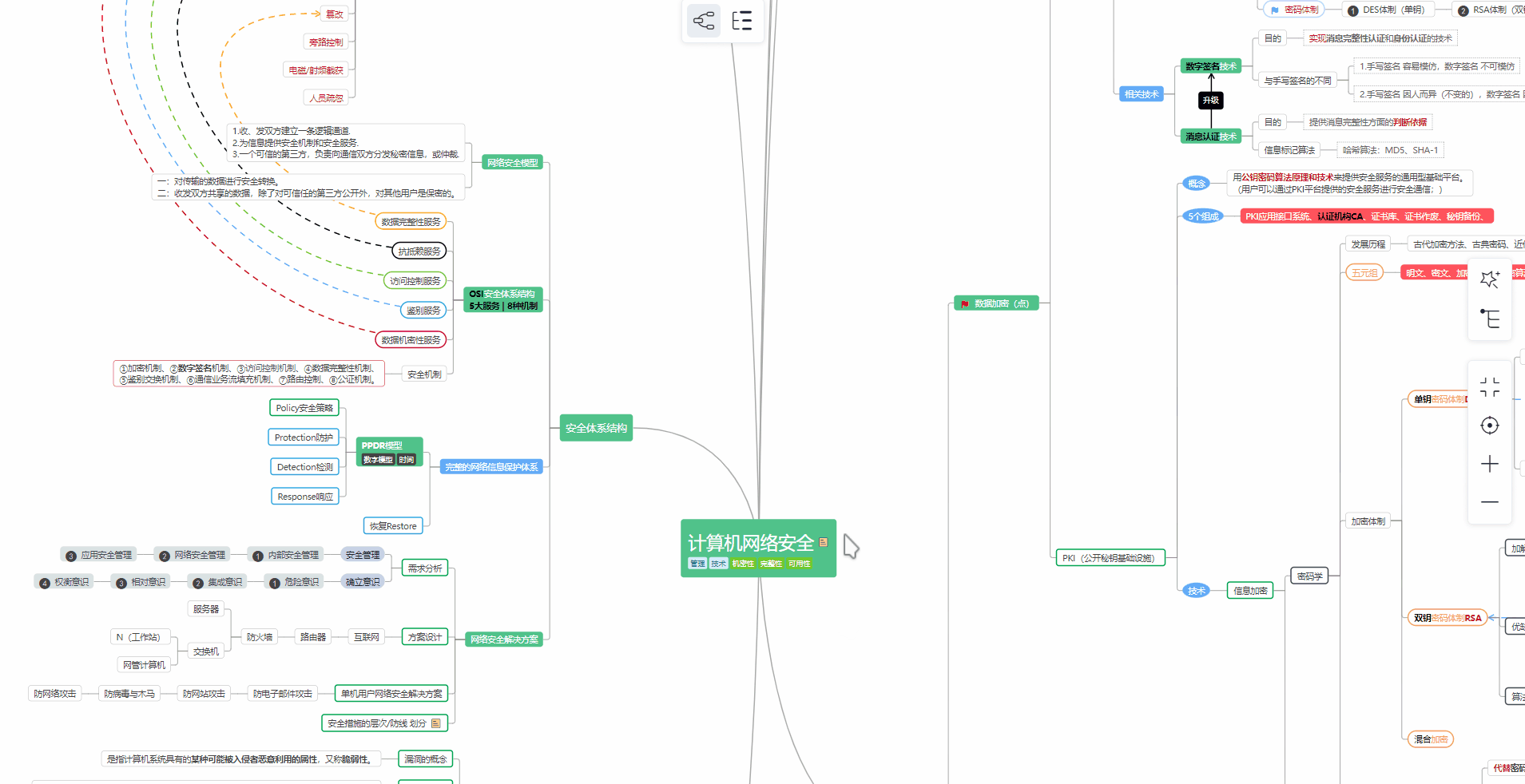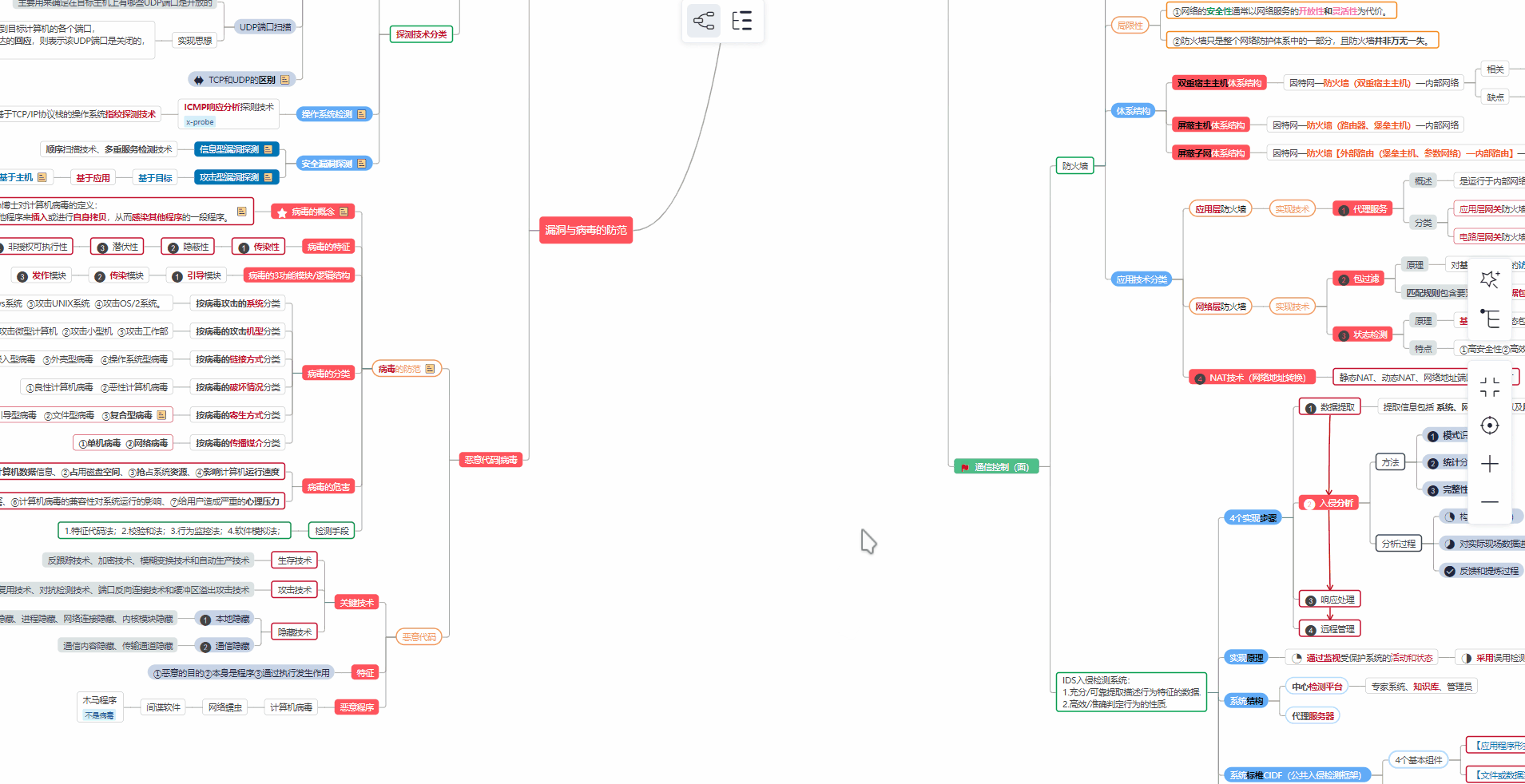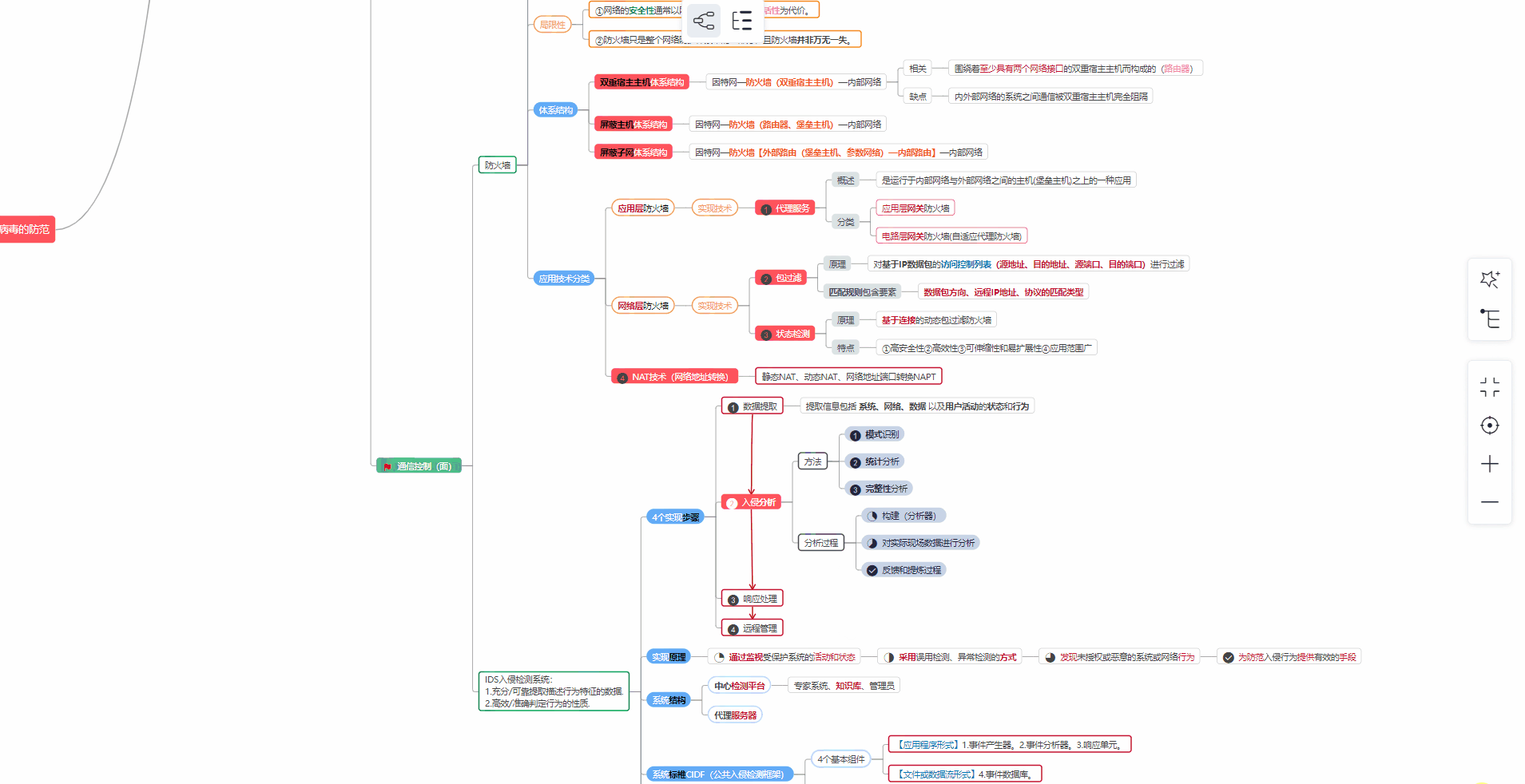
对于从来没有接触过网络安全的同学,我们帮你准备了详细的学习成长路线图。可以说是最科学最系统的学习路线,大家跟着这个大的方向学习准没问题。
1️⃣零基础入门
① 学习路线
对于从来没有接触过网络安全的同学,我们帮你准备了详细的学习成长路线图。可以说是最科学最系统的学习路线,大家跟着这个大的方向学习准没问题。
② 路线对应学习视频
同时每个成长路线对应的板块都有配套的视频提供:

网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。
一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!















 1295
1295

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









