







总结
为了帮助大家更好温习重点知识、更高效的准备面试,特别整理了《前端工程师面试手册》电子稿文件。
内容包括html,css,JavaScript,ES6,计算机网络,浏览器,工程化,模块化,Node.js,框架,数据结构,性能优化,项目等等。
包含了腾讯、字节跳动、小米、阿里、滴滴、美团、58、拼多多、360、新浪、搜狐等一线互联网公司面试被问到的题目,涵盖了初中级前端技术点。
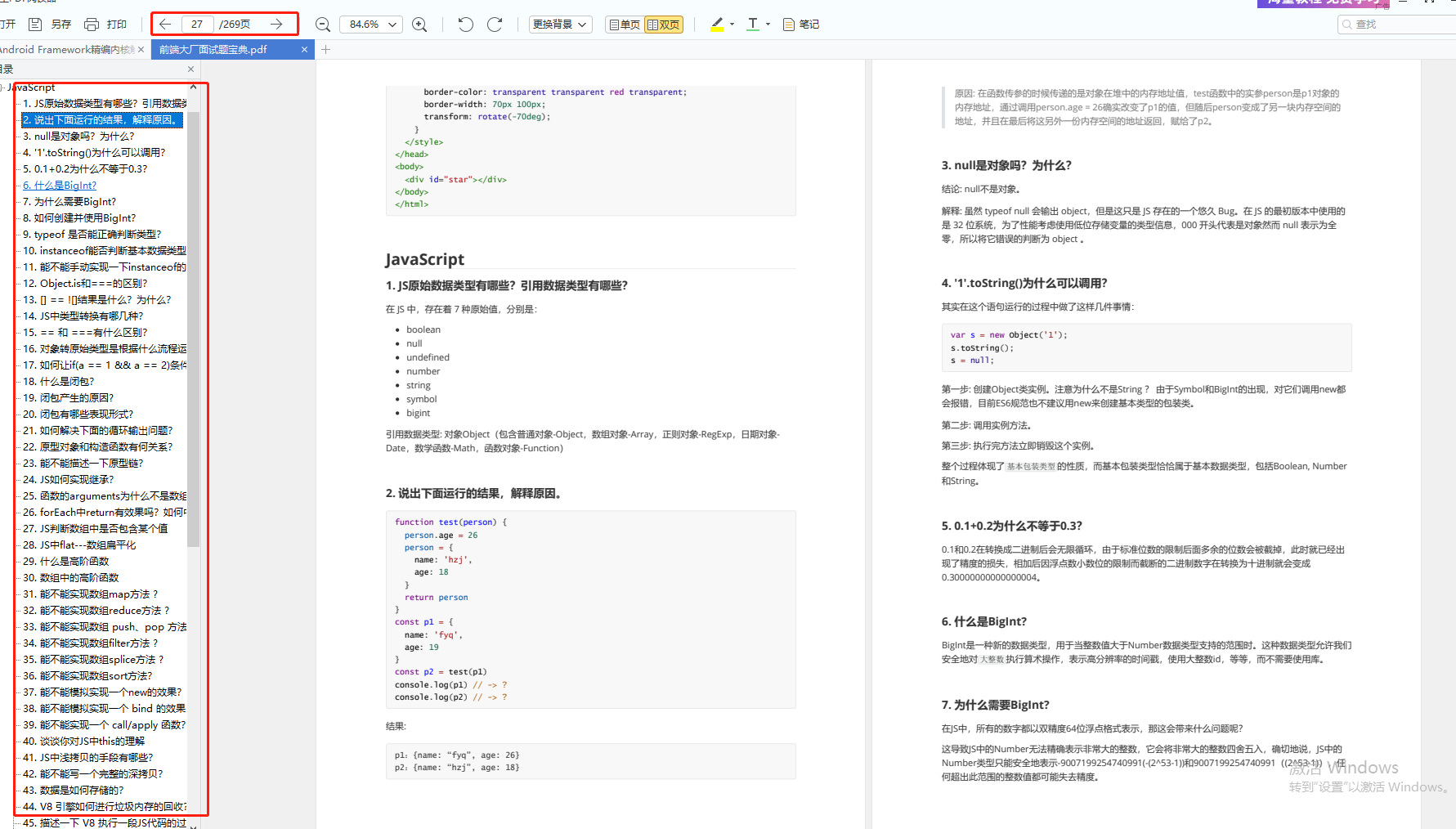
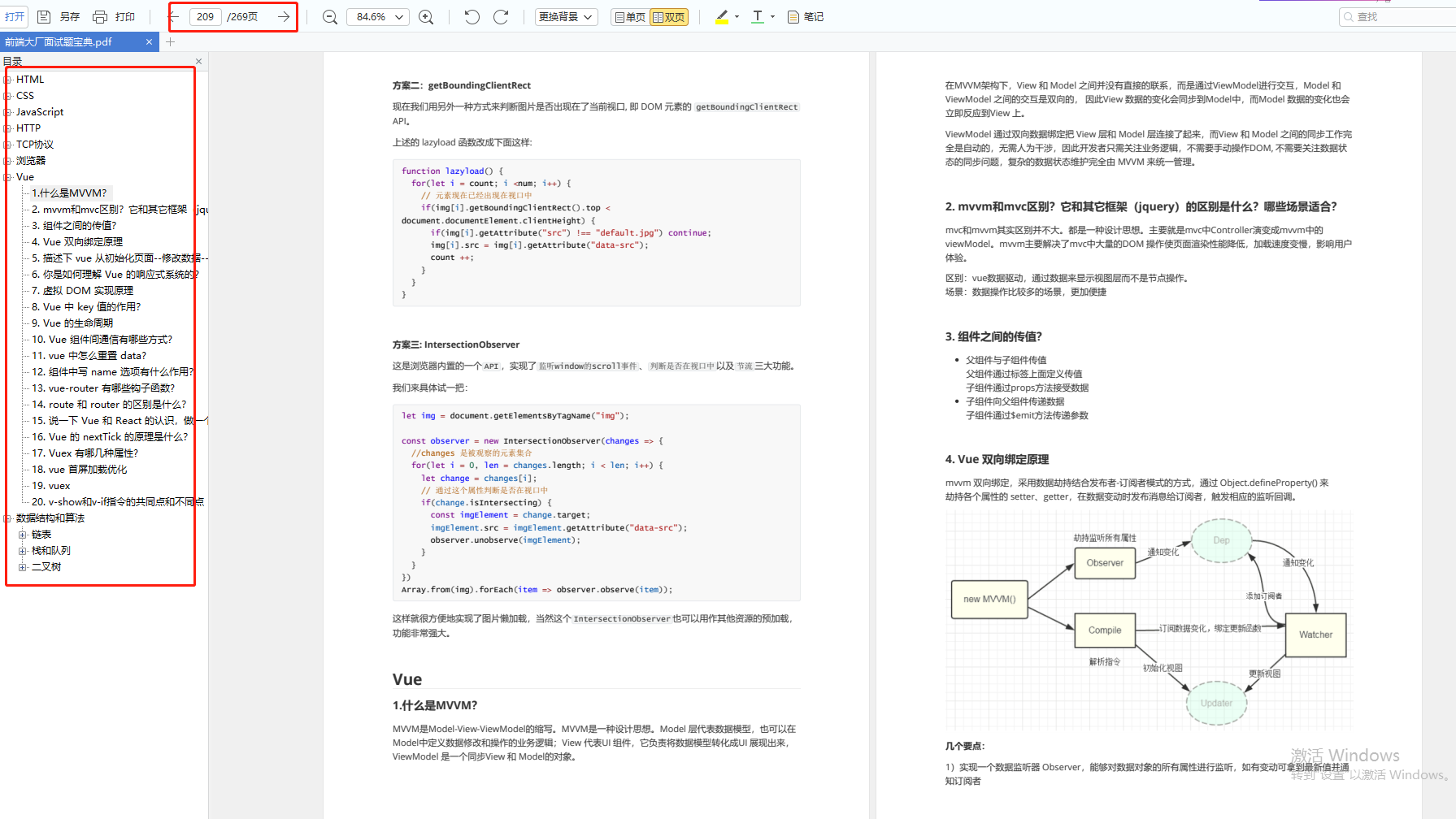
前端面试题汇总
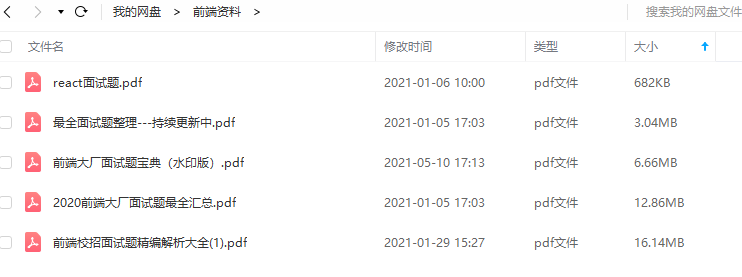
开源分享:【大厂前端面试题解析+核心总结学习笔记+真实项目实战+最新讲解视频】
JavaScript
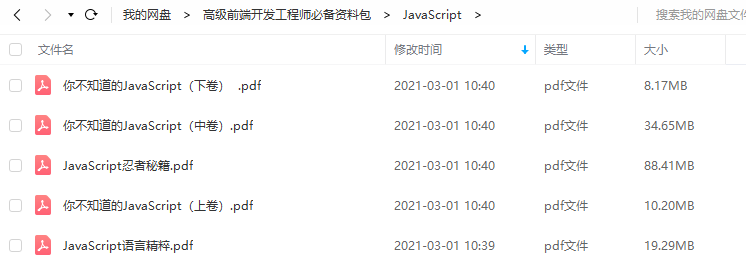
性能
linux

可以发现:Array对象的键名就是整数值,键值就是添加进数组的元素,另外Array对象还有一个length属性来记录元素个数。
那么Array为什么要和Object区别开来呢?Object并不是很难实现一个Array形式的对象,比如类数组对象arguments,几乎具有了Array的所有特点,且可以借用Array原型上方法,所以几乎可以认为它们在形式上是一致的。
原因是:底层数据结构不同,数组的底层数据结构是一个线性表,即在内存上体现为一段连续的内存,假设内存被分为大小相同的块,一段连续的内存可以理解为一段紧挨着的多个内存块。我们知道数据存在内存中都是有内存地址的,而数据内存地址的计算和内存块的大小有关,

那么其实我们知道了内存块大小,数组起始位置内存地址,就可以获得数组中所有元素的起始内存地址了
比如创建一个数组长度为9的数组arr,arr的第一个元素位置是0x000,内存块大小是10(假设,真实计算很复杂),那么第一个元素的起始位置就是 0x000 + 0*10 第二个元素的起始位置就是 0x000 + 1*10,第三个元素的起始位置就是 0x000 + 2*10 ,最后一个元素的起始位置就是 0x000 + 8*10,而这个的0,1,2,…,8就是我们熟知的数组元素索引
arr[0],arr[1],arr[2],…,arr[8]
所以,说到现在,我们发现数组的优势是:根据索引号来查找数组元素,速度块,效率高。但是根据数组元素,查找数组元素的索引,那就没有捷径可言了,只能根据索引遍历出每一个数组元素,然后和要查找的数据元素进行对比,再优化一点就需要使用算法了,比如二分查找,排序后二分查找。
我们在回头看Array对象的整数值属性,你就不会觉得它是一个单纯的Object对象的属性了,首先它不是程序员设置的,而是数组底层根据内存块大小和数组对象在堆中起始内存地址计算得到的索引号。所以Array表面看上去是一个Object,平平无奇,但是底层内存层面上,人家有独到之处。
那么Set的底层实现也是数组吗?就像我们上面代码实现的那样?
答:肯定不是,如果是的话,那么Set就没有必要被创造出来了。
Set去重机制,准确来说是底层数据结构决定的,Set的底层数据结构是哈希表,什么是哈希表?
我们通常将哈希表称为数组升级版,或者说是数组“值”查询的救星。
数组在“值”查询上表现拙劣,性能不佳,而哈希表在”值“查询上表现良好,性能不错。
那么哈希表是如何实现”值“查询的呢?
哈希表在内存上,也是开辟一段连续内存用来存储数据,但是有别于数组,哈希表不会将元素按照添加顺序依次存入连续内存中,元素在内存中存储位置是由哈希算法计算得出的。
哈希算法:将元素值 和 哈希表长度 经过一种算法 计算出 元素 在哈希表中的存储位置
最简单的哈希算法,就是 元素值的哈希值 对 哈希表长度求模,得到模值,就是元素在哈希表中的存储位置
假设哈希表长度 5,现在要存入元素a,a的哈希值假设为123,那么123%5 = 3,那么a就存在哈希表的第3块内存上
这样计算元素的存储位置的好处是什么呢?
当我们需要在哈希表中查找某元素位置时,不需要遍历出所有元素再对比,而是直接将要查找的元素 放入计算哈希值的算法中,得到哈希值,然后对哈希表长度求模,就得到了元素在哈希表中的位置。
即哈希表查找元素位置,不是找出来的,是算出来的,算比找快,也就是典型的动脑子比动手快。
根据以上哈希表的工作原理,我们已经可以知道哈希表在内存上虽然也是一段连续内存,但是哈希表不使用索引,也不会产出索引,而是直接根据元素计算出其内存地址。
这也是ES6的Set没有get(index)方法的原因,我们可以发现Set的查找操作has(ele)全部是基于元素本身的,没有基于索引。
那么哈希表真的就完美了吗?
答:不完美
因为哈希表有一个致命缺点,它计算元素存储位置的哈希算法,会发生哈希冲突
什么叫哈希冲突呢?
比如我们有一个元素 ‘abc’,还有一个元素 ‘bca’,如果我们是按照字符串每个字符的哈希值之和的方式得到字符串元素的哈希值,那么上面两个字符串的哈希值相同,而哈希值相同就会导致它们对哈希表长度取模相同,即最终存储在哈希表的同一个位置上,那么是要发生覆盖吗?那肯定不行,因为’abc’和’bca’明显是两个不同的字符串,所以此时就发生了哈希冲突,哈希表处理哈希冲突的方式是拉链法,即哈希表每一个存储位置可以看出一个桶,当需要在一个存储位置上存储多个值的话,就相当于像桶中放数据,而在数据结构上,这个桶就是单向链表。所以哈希表数据结构可以看出是(数组+单向链表),每个数组元素位置上可以拉一条单向链表存储多个值,一次来解决哈希冲突的元素的存放问题。

当哈希表某一个位置发生的哈希冲突次数很多时,会导致该位置拉出来的单向链表越来越长。
当我们在哈希表上查找的值,刚好在某个位置的单向链表上的话,那么此时该值的查询效率就会骤降,因为单向链表的长处在于元素的插入删除,而不在于元素的查询,我们可以将单向链表的查询操作的时间复杂度看成O(n),差不多和数组一样。
而ES6的Set的一个地方的设计也体现了其对于哈希冲突的现象的担忧:
那就是Set没有length,只有size属性,这说明了什么呢?
我们知道数组的length就是数组存储的元素的个数
那么我们敢说哈希表的length,就是哈希表存储的元素个数吗?
答:不敢,因为哈希冲突的原因,哈希表存储元素的个数可能会大于哈希表的长度
所以发现减少哈希冲突的哈希算法,一直是哈希表数据结构的首要目的。
另外,Set去重机制,就是计算插入元素的哈希值 通过哈希算法得到它在哈希表中的位置,得到位置检查该位置是否已有元素,若已有,则对比是否元素相同,若相同,则不插入,达到去重目的,若不同,则说明哈希冲突,需要拉链。
通过以上对于Array和Set底层数据结构的探究,我们再来回顾Set特性
成员的值都是唯一的,没有重复的值
就会发现,这是很浅的理解,Set比较Array的最大不同就是:Set的值查找效率要比Array快的多,原因就是Set底层是哈希表,它查找元素,不是真的找,而是根据哈希算法,算出元素在哈希表中位置。
此时我们再去理解Set的实例方法和实例属性,就会发现它们设计的多么美妙
在Set操作元素的方法中,没有get(index),只有has(ele),
Set元素个数不是length属性,而是size属性。
另外ES6的Set还有一个重要特性,那就是遍历出Set中元素的顺序 和 插入元素到Set中的顺序一致。

那是否和之前Set底层数据结构哈希表”存入元素的顺序无法决定其存储位置“这一论证冲突呢?
答:不冲突,因为哈希表如果想记录存入元素的顺序很简单,那就是维护一条插入链,这和Java的LinkedHashSet设计很像。
加入了元素插入链的哈希表可以记住元素的插入顺序

当需要遍历Set时,会去获取这条插入链,根据插入链来遍历

我们可以理解Set的内置属性Entries就是插入链,而不是将其理解为数组的索引
会c++的小伙伴可以去v8/src at lkgr · v8/v8 · GitHub看下chrome v8源码中对于Set的实现,但是听说ES6的Set和Map都是用原生JS写的
另外上面关于Array描述都是片面的,实际上JS的Array神通广大,你有没有注意到JS的Array数组容量是动态的?有没有注意到Array数组还可以模拟栈结果,队列结构?有没有注意过Array数组在各个位置插入删除元素的性能是怎么样的?
从Chrome源码看JS Array的实现 - 知乎 (zhihu.com)")
这篇文章看完后,知道JS Array会数组元素少的时候使用快查询:索引查询,在数组元素多的时候采用慢查询:哈希查询,让我不禁怀疑起JS Array底层并不是一个单纯的数组数据结构,可能还会转成哈希表,或者二者兼有。而Set与Array的最大不同,应该就是Set底层是纯粹的哈希表。
对比Map和Object
Map对象和Object对象其实都是存储的键值对,但是Map对象对比Object对象最明显的区别是Object对象的key只能是字符串,就算设置Object对象的key为对象,最终也会调用key的toString方法将其转为字符串,而Map的key可以是任意类型的数据。
那么如果理解到这里的话,那还是比较浅层次的理解。
我们可以思考一下Object对象的属性是如何保证唯一的?我们访问一个Object对象的属性的值时,是如何查询到属性的?
(更新)从Chrome源码看JS Object的实现 – 人人FED (rrfed.com)从Chrome源码看JS Object的实现 – 人人FED (rrfed.com)")
可能我们理解Object对象要保证属性唯一,那么最简单就是哈希表,但是JS Object并没有首选哈希表来存储属性,而是搞了一个searchCache缓存,这个缓存中,保存了对象上所有属性的哈希值,如果有新属性加入,则会先去searchCache缓存中查询是否已有该属性。另外Object对象的键值对保存在一个FixedArray中,即一个数组结构中。
即:为了保证Object对象属性唯一,搞了一个searchCache缓存,每次新增属性都要去这个缓存中找一找是否已存在,若已存在,则将属性值覆盖到FixedArray的同名属性键值对中,若不存在,则将属性哈希值保存进searchCache,并将属性的键值对加入FixedArray中
在FixedArray覆盖旧的键值对时,会采用顺序查找后覆盖(对象属性个数<=8)或者二分查找后覆盖(对象属性个数>8)
当然这种方案在属性个数多的时候,效率很低,所在在对象属性个数达到128个以上时,就会使用哈希表代替searchCache缓存来保证属性唯一性,而键值对依旧保存在FixedArray中。
这里为什么会有searchCache保证对象属性唯一(对象属性128个及以下),和哈希表保证对象属性唯一(对象属性128以上),因为哈希表会发生哈希冲突,而searchCache不会发生冲突,可能JS团队测试过128是一个分界线吧,当属性个数超过128,哈希表的查找属性的优越性能 会比 哈希冲突造成的影响 更划算吧。
另外对象的属性一般都是字符串,但是这里的字符串可以分为整数字符串和非整数字符串,比如argument类数组对象的属性就是整数字符串,这些对象整数属性的属性值会保存带一个elements有序数组中,且保存位置就是整数属性对应的element数组索引号,这样就可以根据索引号是属性唯一,并且可以实现根据索引号快速查询属性值。缺点就是,会造成内存浪费,因为数组的容量必须大于数组元素个数,且随着元素个数不断增加会扩容。
我们将去哈希表中查找属性,叫做慢查询,利用索引号去elements数组中查询属性,叫快查询,然而快查询是有可能变为慢查询的,那就是整数属性跨度太大时,{ 0:‘a’, 100000:‘b’ },此时不可能为了存储两个元素,就创建一个长度超过100000数组,所以此时会使用哈希表去存储属性。
通过上面对于Object对象存储和查询属性,保证属性唯一的分析,我们可知,Object对象并不是单纯的使用某一种方式,当对象属性个数不超过128时,会使用searchCache缓存属性的哈希值,来保证属性去重,当对象属性超过128时,就会使用哈希表存储属性,来保证去重,但是当属性是整数,或整数字符串时,又会使用element有序数组,并将整数(字符串)属性作为elements数组的索引号,以实现属性唯一,当整数属性跨度较大时,又会使用哈希表保证整数属性唯一
可以看见Object对象的属性查询和存储搞得很复杂。
而ES6的Map就简简单单了,单纯使用哈希表来保证属性唯一。
那么二者在属性查找性能上的对比,抛开引用类型属性,单纯比较简单类型属性的话:
如果属性个数<=128,那么Object对象是searchCache查找,Map是哈希表查找,如果不考虑哈希冲突,那肯定是Map快,如果考虑哈希冲突,那就不一定了。
如果属性个数>123,那么Object是哈希表查找,Map也是哈希表查找,感觉区别不大
如果属性是整数属性,且分布均匀,那Object对象会将整数属性当成数组索引查找,而Map还是使用哈希表查找,这个时候应该看Map的哈希算法对于整数属性的哈希值计算快不快了,但是应该还是没有Object对象直接当成数组索引来查快,因为一个要计算得到位置,一个直接当成位置
其他方面Map和Object的比较,MDN上做了很好的总结
最后
正值招聘旺季,很多小伙伴都询问我有没有前端方面的面试题!
开源分享:【大厂前端面试题解析+核心总结学习笔记+真实项目实战+最新讲解视频】

属性,且分布均匀,那Object对象会将整数属性当成数组索引查找,而Map还是使用哈希表查找,这个时候应该看Map的哈希算法对于整数属性的哈希值计算快不快了,但是应该还是没有Object对象直接当成数组索引来查快,因为一个要计算得到位置,一个直接当成位置
其他方面Map和Object的比较,MDN上做了很好的总结
最后
正值招聘旺季,很多小伙伴都询问我有没有前端方面的面试题!
开源分享:【大厂前端面试题解析+核心总结学习笔记+真实项目实战+最新讲解视频】
[外链图片转存中…(img-GnfvHwhM-1715760499455)]















 712
712

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









