






散手第一式:数据包过滤
a.过滤需要的IP地址 ip.addr==

b.在数据包过滤的基础上过滤协议ip.addr==xxx.xxx.xxx.xxx and tcp

c.过滤端口ip.addr==xxx.xxx.xxx.xxx and http and tcp.port==80

d.指定源地址 目的地址ip.src==xxx.xxx.xxx.xxx and ip.dst==xxx.xxx.xxx.xxx
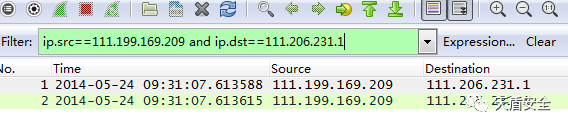
e.SEQ字段(序列号)过滤(定位丢包问题)
TCP数据包都是有序列号的,在定位问题的时候,我们可以根据这个字段来给TCP报文排序,发现哪个数据包丢失。
SEQ分为相对序列号和绝对序列号,默认是相对序列号显示就是0 1不便于查看,修改成绝对序列号方法请参考第三式。
![]()
散手第二式:修改数据包时间显示方式
有些同学抓出来的数据包,时间显示的方式不对,不便于查看出现问题的时间点,可以通过View---time display format来进行修改。
修改前:

修改后:


散手第三式:确认数据报文顺序
有一些特殊情况,客户的业务源目的IP 源目的端口 源目的mac 都是一样的,有部分业务出现业务不通,我们在交换机上做流统计就不行了,如下图网络架构。箭头是数据流的走向,交换机上做了相关策略PC是不能直接访问SER的。

那我们在排查这个问题的时候,我们要了解客户的业务模型和所使用的协议,很巧合这个业务是WEB。我们从而知道TCP报文字段里是有序列号的,我们可以把它当做唯一标示来进行分析,也可以通过序列号进行排序。
一般抓出来的都是相对序列号0 1不容易分析,这里我们通过如下方式进行修改为绝对序列号。
Edit-----preference------protocols----tcp---relative sequence numbers

修改参数如下:

我拿TCP协议举例

把TCP的这个选项去除掉

最后的效果:

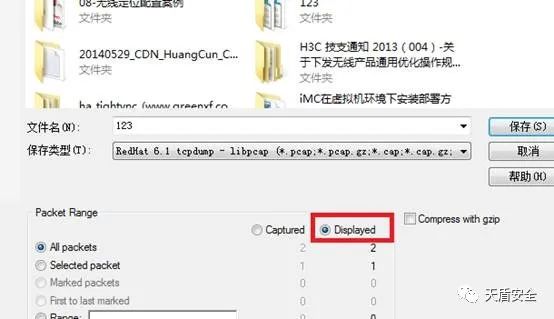
散手第四式:过滤出来的数据包保存
我们抓取数据包的时候数据量很大,但对于我们有用的只有几个,我们按条件过滤之后,可以把过滤后的数据包单独保存出来,便于以后来查看。

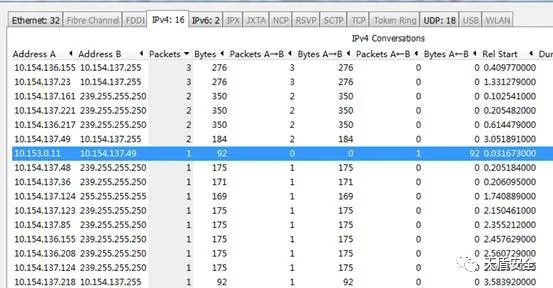
散手第五式:数据包计数统计
网络里有泛洪攻击的时候,我们可以通过抓包进行数据包个数的统计,来发现哪些数据包较多来进行分析。
Statistics------conversations

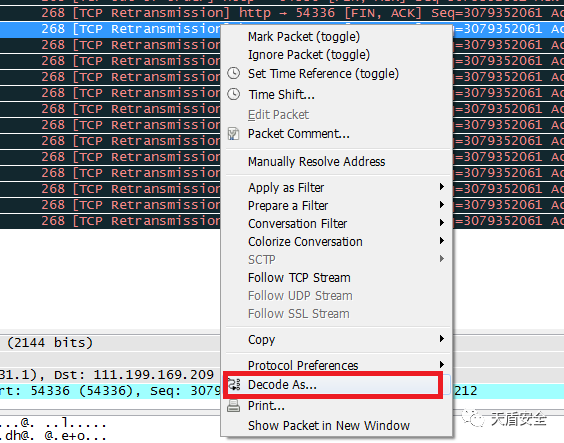
散手第六式:数据包解码
IPS发送攻击日志和防病毒日志信息端口号都是30514,SecCenter上只显示攻击日志,不显示防病毒日志。查看IPS本地有病毒日志,我们可以通过在SecCenter抓包分析确定数据包是否发送过来。
发过来的数据量比较大,而且无法直接看出是IPS日志还是AV日志,我们先把数据包解码。
(由于没有IPS的日志抓包信息,暂用其他代替)
解码前:

解码操作:

解码后:
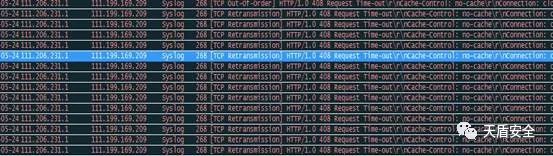
散手第七式:TCP数据报文跟踪
查看TCP的交互过程,把数据包整个交互过程提取出来,便于快速整理分析。
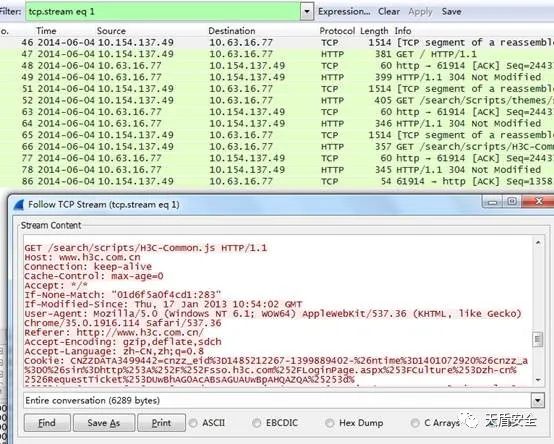
散手第八式:通过Wireshark来查看设备的厂家
查看无线干扰源的时候,我们可以看出干扰源的mac地址,我们可以通过Wireshark来查找是哪个厂商的设备,便于我们快速寻找干扰源。
例如:mac地址是A4-4E-31-30-0B-E0
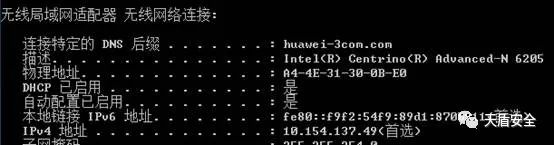
我们通过Wireshark安装目录下的manuf文件来查找
















 2452
2452

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









