







网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。
一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!
openGauss提供了智能索引推荐功能,该功能将索引设计的流程自动化、标准化,可分别针对单条查询语句和工作负载推荐最优的索引,提升作业效率、减少数据库管理人员的运维操作。
openGauss的智能索引推荐功能可覆盖多种任务级别和使用场景,具体包含以下三个特性。
(1) 单条查询语句的索引推荐。该特性可基于查询语句的语义信息和数据库的统计信息,对用户输入的单条查询语句生成推荐的索引。
(2) 虚拟索引。该特性可模拟真实索引的建立,同时避免真实索引创建所需的时间和空间开销,用户可通过优化器评估虚拟索引对指定查询语句的代价影响。
(3) 基于工作负载的索引推荐。该特性将包含有多条DML语句的工作负载作为任务的输入,最终生成一批可优化整体工作负载执行时间的索引。该功能适用于多种使用场景,例如,当面对一批全新的业务SQL且当前系统中无索引,本功能将针对该工作负载量身定制,推荐出效果最优的一批索引;当系统中已存在索引时,本功能仍可查漏补缺,对当前生产环境中运行的作业,通过获取日志来推荐可提升工作负载执行效率的索引,或者针对极个别的慢SQL进行单条查询语句的索引推荐。
8.4.2 现有技术
索引推荐技术按照任务级别划分,可分为基于单条查询语句的索引推荐和基于工作负载的索引推荐。对于基于单条查询语句的索引推荐,使用者每次向索引设计工具提供一个查询语句,工具会针对该语句生成最佳的索引。目前的主流算法是首先提取该查询语句的语义信息和数据库中的统计信息,然后基于相关的索引设计和优化理论,对各子句中的谓词进行分析和处理,启发式地推荐最优索引。此类任务主要是针对个别查询时间慢的SQL进行索引优化,应用场景较为有限。
一般来说,更广泛使用的任务场景是基于工作负载的索引推荐,即给定一个包含多种类型SQL语句的工作负载,生成使得系统在该工作负载下的运行时间降至最低的索引集合。在索引选择算法中,核心是量化和估计索引对于工作负载的收益,这里的收益是指,当该索引应用于指定工作负载时,工作负载的总代价的减少量。根据代价估计的方式的不同,目前的算法可分为两大类。
(1) 基于优化器的代价估计的方法。采用优化器的代价模型来对索引进行代价估计是较为准确的,因为优化器负责查询计划和索引的选择。同时,一些数据库系统支持虚拟索引的功能,虚拟索引并没有在存储空间中创建物理上的索引,而是通过模拟索引的效果来影响优化器的代价估计。目前的主流数据库产品均采用了该种方法,如SQL Server的AutoAdmin、DB2的DB2 Advisor等。
(2) 基于机器学习的方法。上一种方法由于优化器的局限性,会导致索引收益的估计发生偏差,例如选择度的错误估算或者代价估计模型不准确。在学术界的最新进展中,一些方法采用了机器学习算法来预测和分类哪种查询计划更加有效,或者是采用基于神经网络的代价模型来缓解传统模型带来的问题。但是此类方法往往需要大量的训练数据,并不适用于全部的业务环境。
8.4.3 实现原理
1. 针对单条查询语句的索引推荐
单条查询语句的索引推荐是以数据库的系统函数形式提供的,用户可以通过调用gs_index_advise()命令使用。其原理是利用在SQL引擎、优化器等处获取到的信息,使用启发式算法进行推荐。该功能可以用来对因索引配置不当而导致的慢SQL进行优化。

图8-12 单条查询语句的索引推荐流程图
单条查询语句的索引推荐步骤如图8-12所示,该过程如下。
(1) 对给定的查询语句进行词法和语法解析,得到解析树。
(2) 依次对解析树中的单个或多个查询子句的结构进行分析。
(3) 整理查询条件,分析各个子句中的谓词。
(4) 解析From子句,提取其中的表信息,如果其中含有join子句,则解析并保存join关系。
(5) 解析Where子句,如果是谓词表达式,则计算各谓词的选择度,并将各谓词根据选择度的大小进行倒序排列,依据最左匹配原则添加候选索引,如果是Join关系,则解析并保存join关系。
(6) 如果是多表查询,即该语句中含有join关系,则将结果集最小的表作为驱动表,根据前述过程中保存的join关系和连接谓词为其他被驱动表添加候选索引。
(7) 解析Group和Order子句,判断其中的谓词是否有效,如果有效则插入到候选索引的合适位置,Group子句中的谓词优于Order子句,且两者只能同时存在一个;这里,候选索引的排列优先级为:join中的谓词> Where等值表达式中的谓词> Group或Order中的谓词> Where非等值表达式中的谓词。
(8) 检查该索引是否在数据库中已存在,若存在则不再重复推荐。
(9) 输出最终的索引推荐建议。
2. 虚拟索引
通过虚拟索引功能实现对待创建索引的效果和代价进行估计。对于给定的索引表名和列名,可以在数据库内部建立虚拟索引,该虚拟索引只具有待创建索引的元信息,而不会真正创建物理索引文件,因此避免了真实索引的创建开销。这些元信息包括:待创建索引的表名、列名和其他统计信息,虚拟索引仅用于通过explain语句显示优化器的可能执行路径,不能提供真正的索引扫描。
因此,对某条SQL语句执行explain命令,可以查看到创建索引前后优化器规划出的执行计划、检验该待创建索引是否被数据库采用以及是否有性能提升。虚拟索引主要是基于数据库中的hook(钩子机制)实现的,即通过使用全局的函数指针get_relation_info_hook和explain_get_index _name_hook,来干预和改变查询计划的估计过程,让优化器在规划路径时,考虑到可能出现的索引扫描。
3. 基于工作负载的索引推荐
基于工作负载的索引推荐功能的主要模块如图8-13所示。

图8-13 基于工作负载索引推荐流程图
主要包括以下步骤。
(1) 对于给定的工作负载,首先对工作负载进行压缩。由于工作负载中通常存在着大量相似的语句,为了减少数据库功能的调用次数,我们会对工作负载中的SQL语句进行模板化和采样。
(2) 对压缩后的工作负载,调用单条查询语句的索引推荐功能为每条语句生成推荐索引,作为候选索引集合。
(3) 对候选索引集合中的每个索引,在数据库中创建对应的虚拟索引,根据优化器的代价估计来计算该索引对整个负载的收益。
(4) 在候选索引集合的基础上,基于索引代价和收益进行索引的选择。openGauss实现了两种算法进行索引优选:一种是在限定索引集大小的条件下,根据索引的收益进行排序,然后选取靠前的候选索引来最大化索引集的总收益,最后采用微调策略,基于索引间的相关性进行调整和去重,得到最终的推荐索引集合;另一种方法是采用贪心算法来迭代地进行索引集合的添加和代价推断,最终生成推荐的索引集合。两种算法各有优劣,第一种方法未充分考虑索引间的相互关系,而第二种方法会伴随较多的迭代过程。
(5) 输出最终的索引推荐建议。
8.4.4 关键源码解析
1. 项目结构
智能索引推荐功能在项目中的源代码路径在openGauss-server/src/gausskernel/dbmind中,涉及的相关文件如表8-8所示。
表8-8 智能索引推荐功能源代码路径
| 文件路径 | 说明 |
|---|---|
| kernel/index_advisor.cpp | 单条查询语句的索引推荐。 |
| kernel/hypopg_index.cpp | 虚拟索引特性实现 |
| tools/index_advisor/index_advisor_workload.py | 基于工作负载的索引推荐 |
其中,单条查询语句的索引推荐功能和虚拟索引的功能通过数据库的系统函数进行调用,基于工作负载的索引推荐功能需要通过数据库外部的脚本运行。
2. 关键代码解析
单条语句索引推荐的所有实现部分都只存在于index_advisor.cpp文件中,该功能的主要入口为suggest_index函数,它通过系统函数gs_index_advise进行调用,代码如下:
SuggestedIndex *suggest_index(const char *query_string, _out_ int *len)
{
……
// 对查询语句进行词法和语法解析,获得解析树
List *parse_tree_list = raw_parser(query_string);
…
// 递归地搜索解析树中的SelectStmt结构
Node *parsetree = (Node *)lfirst(list_head(parse_tree_list));
find_select_stmt(parsetree);
…
// 依次解析和处理SelectStmt结构中的各个子句部分
ListCell *item = NULL;
foreach (item, g_stmt_list) {
SelectStmt *stmt = (SelectStmt *)lfirst(item);
/* 处理SelectStmt 结构体中涉及的FROM子句,提取涉及的表,解析和保存这些表中的join关系 */
parse_from_clause(stmt->fromClause);
…
if (g_table_list) {
// 处理WHERE子句,提取条件表达式中的谓词并添加候选索引,解析和保存其中的join关系
parse_where_clause(stmt->whereClause);
// 根据保存的join关系确定驱动表
determine_driver_table();
// 处理GROUP子句,如果满足条件,则将其中的谓词添加为候选索引
if (parse_group_clause(stmt->groupClause, stmt->targetList)) {
add_index_from_group_order(g_driver_table, stmt->groupClause, stmt->targetList, true);
/* 处理ORDER子句,如果满足条件,则将其中的谓词添加为候选索引 */
} else if (parse_order_clause(stmt->sortClause, stmt->targetList)) {
add_index_from_group_order(g_driver_table, stmt->sortClause, stmt->targetList, false);
}
// 如果是多表查询,则根据保存的join关系为被驱动表添加候选索引
if (g_table_list->length > 1 && g_driver_table) {
add_index_for_drived_tables();
}
/* 对全局变量中的每个table依次进行处理,函数generate_final_index将前述过程生成的候选索引进行字符串拼接,并检查和已存在的索引是否重复 */
ListCell *table_item = NULL;
foreach (table_item, g_table_list) {
TableCell *table = (TableCell *)lfirst(table_item);
if (table->index != NIL) {
Oid table_oid = find_table_oid(query_tree->rtable, table->table_name);
if (table_oid == 0) {
continue;
}
generate_final_index(table, table_oid);
}
}
g_driver_table = NULL;
}
}
……
return array;
}
虚拟索引的核心功能全部位于hypopg_index.cpp文件中。用户通过SQL语句调用系统函数hypopg_create_index来创建虚拟索引,该系统函数主要通过调用hypo_index_store_parsetree函数来完成虚拟索引的创建。虚拟索引的结构体名为hypoIndex,该结构体的许多字段是从它涉及的表的RelOptInfo结构体中读取的,hypoIndex的结构如下:
typedef struct hypoIndex {
Oid oid; /* 虚拟索引的oid,该oid是唯一的 */
Oid relid; /* 涉及的表的oid */
…
char *indexname; /* 虚拟索引名 */
BlockNumber pages; /* 预估索引使用的磁盘页数 */
double tuples; /* 预估索引所涉及的元组数目 */
/* 索引描述信息 */
int ncolumns; /* 涉及的总列数 */
int nkeycolumns; /* 涉及的关键列数 */
…
Oid relam; /* 记录索引操作回调函数的元组的oid, 从pg_am系统表中获取的 */
…
} hypoIndex;
函数hypo_index_store_parsetree的输入参数为创建索引的SQL语句和其语法树,依据该语句的解析结果来创建新的虚拟索引,代码如下:
hypoIndex *hypo_index_store_parsetree(IndexStmt *node, const char *queryString)
{
……
// 获得创建索引的表的oid
relid = RangeVarGetRelid(node->relation, AccessShareLock, false);
……
// 对该创建索引的语句进行语法解析
node = transformIndexStmt(relid, node, queryString);
……
// 新建虚拟索引,该虚拟索引的结构体类型hypoIndex定于位于文件openGauss-server/src/include/dbmind/hypopg_index.h,与索引结构体IndexOptInfo类似
entry = hypo_newIndex(relid, node->accessMethod, nkeycolumns, ninccolumns, node->options);
// 根据语法树的解析结果为虚拟索引entry内的各个成员赋值
PG_TRY();
{
……
entry->unique = node->unique;
entry->ncolumns = nkeycolumns + ninccolumns;
entry->nkeycolumns = nkeycolumns;
……
}
PG_CATCH();
{
hypo_index_pfree(entry);
PG_RE_THROW();
}
PG_END_TRY();
// 设置虚拟索引的名字
hypo_set_indexname(entry, indexRelationName.data);
// 将新建的虚拟索引entry添加到虚拟索引的全局链表hypoIndexes上,该全局变量为节点类型为hypoIndex*的List链表,记录了全部创建过的虚拟索引
hypo_addIndex(entry);
return entry;
}
// 该函数被赋值给全局的函数指针get_relation_info_hook,当数据库执行EXPLAIN时,会通过该函数指针跳转到本函数
void hypo_get_relation_info_hook(PlannerInfo *root, Oid relationObjectId, bool inhparent, RelOptInfo *rel)
{
/* 判断是否开启GUC参数enable_hypo_index,当SQL语句是EXPLAIN命令时,变量isExplain的值为真 */
if (u_sess->attr.attr_sql.enable_hypo_index && isExplain) {
Relation relation;
relation = heap_open(relationObjectId, AccessShareLock);
if (relation->rd_rel->relkind == RELKIND_RELATION) {
ListCell *lc;
/* 遍历全局变量链表hypoIndexes中的每个创建过的虚拟索引 */
foreach (lc, hypoIndexes) {
hypoIndex *entry = (hypoIndex *)lfirst(lc);
// 判断该虚拟索引和该表是否匹配
if (hypo_index_match_table(entry, RelationGetRelid(relation))) {
// 如果匹配,则将该索引加入该表的indexlist中,indexlist是节点类型为IndexOptInfo的链表,是结构体类型RelOptInfo的成员,记录了表的所有的索引
hypo_injectHypotheticalIndex(root, relationObjectId, inhparent, rel, relation, entry);
}
}
}
heap_close(relation, AccessShareLock);
}
……
}
8.4.5 使用示例
1. 单条查询语句的索引推荐
单条查询语句的索引推荐功能支持用户在数据库中直接进行操作,本功能基于查询语句的语义信息和数据库的统计信息,对用户输入的单条查询语句生成推荐的索引。本功能涉及的函数接口如表8-9所示。
表8-9 单query索引推荐功能的函数接口
| 函数名 | 参数 | 返回值 | 功能 |
|---|---|---|---|
| gs_index_advise | SQL语句字符串 | 无 | 针对单条查询语句生成推荐索引(该版本只支持B树索引) |
使用上述函数,获取针对该query生成的推荐索引,推荐结果由索引的表名和列名组成。
opengauss=> select * from gs_index_advise('SELECT c_discount from bmsql_customer where c_w_id = 10');
table | column
----------------+----------
bmsql_customer | (c_w_id)
(1 row)
上述结果表明:应当在bmsql_customer的c_w_id列上创建索引,例如可以通过下述SQL语句创建索引。
CREATE INDEX idx on bmsql_customer(c_w_id);
某些SQL语句,也可能被推荐创建联合索引,例如:
opengauss=# select * from gs_index_advise('select name, age, sex from t1 where age >= 18 and age < 35 and sex = ''f'';');
table | column
-------+------------
t1 | (age, sex)
(1 row)
上述语句结果表明应该在表t1上创建一个联合索引(age, sex),可以通过下述命令创建该索引,并将其命名为idx1。
CREATE INDEX idx1 on t1(age, sex);
2. 虚拟索引
虚拟索引功能支持用户在数据库中直接进行操作,该功能模拟真实索引的建立,避免真实索引创建所需的时间和空间开销,用户基于虚拟索引,可通过优化器评估该索引对指定查询语句的代价影响。
虚拟索引功能涉及的系统函数接口如表8-10所示。
表8-10 虚拟索引功能的接口
本人从事网路安全工作12年,曾在2个大厂工作过,安全服务、售后服务、售前、攻防比赛、安全讲师、销售经理等职位都做过,对这个行业了解比较全面。
最近遍览了各种网络安全类的文章,内容参差不齐,其中不伐有大佬倾力教学,也有各种不良机构浑水摸鱼,在收到几条私信,发现大家对一套完整的系统的网络安全从学习路线到学习资料,甚至是工具有着不小的需求。
最后,我将这部分内容融会贯通成了一套282G的网络安全资料包,所有类目条理清晰,知识点层层递进,需要的小伙伴可以点击下方小卡片领取哦!下面就开始进入正题,如何从一个萌新一步一步进入网络安全行业。
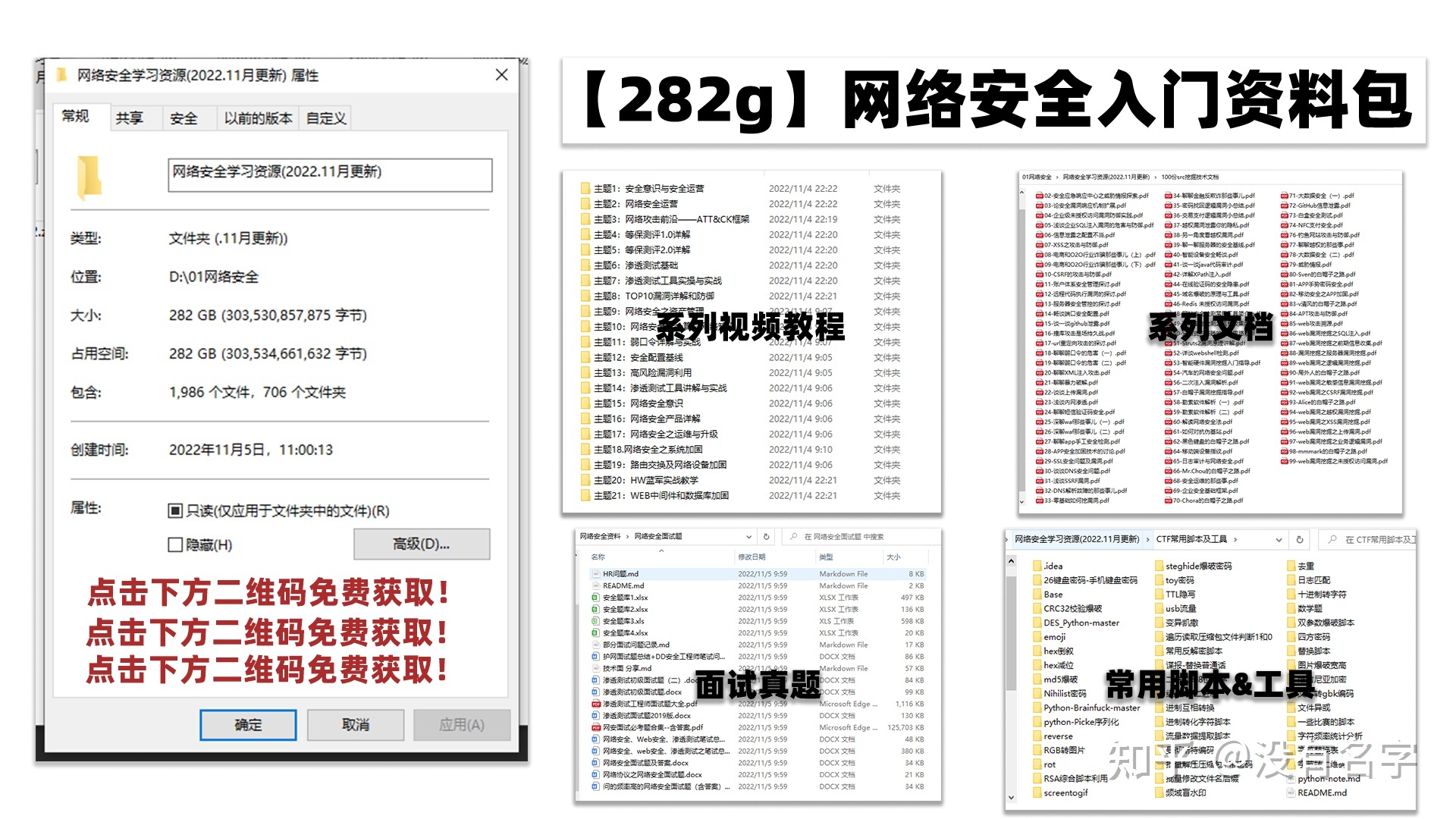
学习路线图
其中最为瞩目也是最为基础的就是网络安全学习路线图,这里我给大家分享一份打磨了3个月,已经更新到4.0版本的网络安全学习路线图。
相比起繁琐的文字,还是生动的视频教程更加适合零基础的同学们学习,这里也是整理了一份与上述学习路线一一对应的网络安全视频教程。
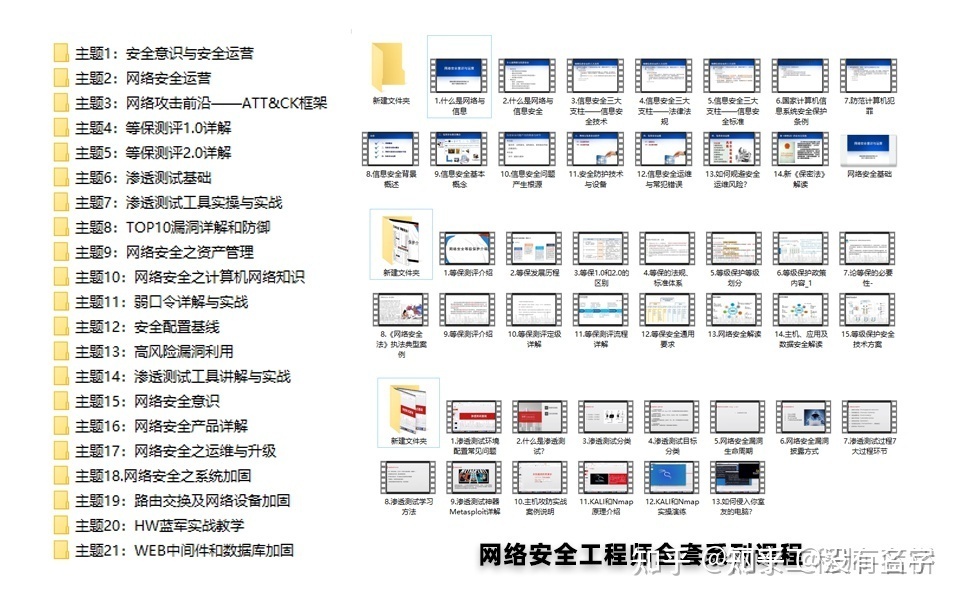
网络安全工具箱
当然,当你入门之后,仅仅是视频教程已经不能满足你的需求了,你肯定需要学习各种工具的使用以及大量的实战项目,这里也分享一份我自己整理的网络安全入门工具以及使用教程和实战。
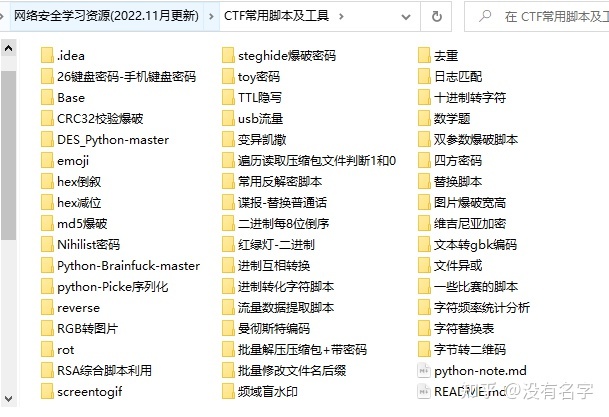
项目实战
最后就是项目实战,这里带来的是SRC资料&HW资料,毕竟实战是检验真理的唯一标准嘛~

面试题
归根结底,我们的最终目的都是为了就业,所以这份结合了多位朋友的亲身经验打磨的面试题合集你绝对不能错过!
网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。
一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!















 1871
1871

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









