






引言
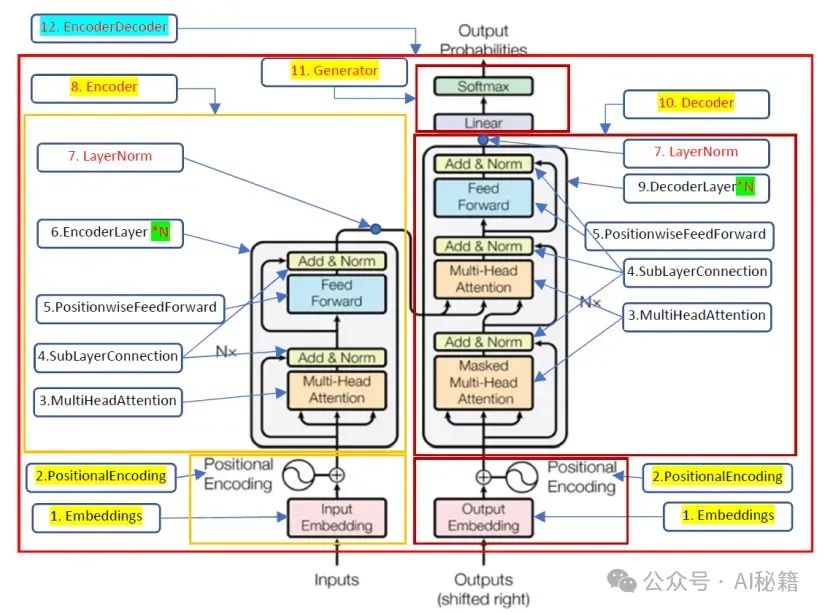
Position-wise Feed-Forward Networks(位置感知的前馈网络)是 Transformer 模型中编码器(Encoder)和解码器(Decoder)的组成部分之一。在 Transformer 的每个编码器和解码器层中,自注意力(Self-Attention)层之后便是位置感知的前馈网络。
理解
网络结构
位置感知的前馈网络由两个线性变换组成,中间夹着一个 ReLU 激活函数。具体来说,对于每个位置的输入,网络独立地应用相同的转换,公式如下:
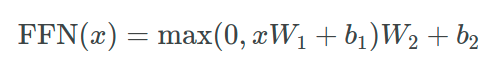
其中 ( W1 ), ( W2 ), 和 ( b1 ), ( b2 ) 是需要学习的参数,( x ) 是输入向量。
描述
1. 增加非线性:通过使用ReLU激活函数,FFN为模型引入非线性,使得模型能够学习更复杂的特征。
2. 提升表达能力:两个线性层的堆叠增加了模型的表达能力,允许其捕捉输入数据中的复杂关系。
3. 位置感知的前馈网络:它对每个位置的输入独立地应用相同的全连接网络,从而在不依赖于位置信息的情况下增加模型的非线性和复杂性。这种设计使得网络能够对每个位置的表示进行精细的转换,但并不直接提供关于位置之间关系的信息。
代码实现
以下是使用 PyTorch 实现位置感知的前馈网络的示例代码:

import torch
import torch.nn as nn
class PositionwiseFeedForward(nn.Module):
def __init__(self, d_model, d_ff, dropout=0.1):
super(PositionwiseFeedForward, self).__init__()
self.w_1 = nn.Linear(d_model, d_ff)
self.w_2 = nn.Linear(d_ff, d_model)
self.dropout = nn.Dropout(dropout)
self.relu = nn.ReLU()
def forward(self, x):
x = self.w_1(x)
x = self.relu(x)
x = self.w_2(x)
return x
# Example usage
d_model = 512 # Dimension of the model
d_ff = 2048 # Dimension of the inner layer in the feed-forward network
feed_forward = PositionwiseFeedForward(d_model, d_ff)
# Dummy input
input_tensor = torch.rand((64, 50, d_model)) # (batch_size, seq_length, d_model)
output_tensor = feed_forward(input_tensor)
在这个例子中,d_model 是模型的维度,d_ff 是前馈网络中间层的维度。input_tensor 是一个三维张量,包含了批次大小、序列长度和模型维度。
-
d_model: 输入和输出的维度。
-
d_ff: 前馈网络中间层的维度。
-
dropout: 在两个线性层之间使用的 dropout 比率,用于防止过拟合。
位置感知的前馈网络是 Transformer 架构中的关键组件之一,它通过增加模型的非线性和表达能力,帮助模型更好地处理序列数据。
最后的最后
感谢你们的阅读和喜欢,我收藏了很多技术干货,可以共享给喜欢我文章的朋友们,如果你肯花时间沉下心去学习,它们一定能帮到你。
因为这个行业不同于其他行业,知识体系实在是过于庞大,知识更新也非常快。作为一个普通人,无法全部学完,所以我们在提升技术的时候,首先需要明确一个目标,然后制定好完整的计划,同时找到好的学习方法,这样才能更快的提升自己。
这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】

大模型知识脑图
为了成为更好的 AI大模型 开发者,这里为大家提供了总的路线图。它的用处就在于,你可以按照上面的知识点去找对应的学习资源,保证自己学得较为全面。

经典书籍阅读
阅读AI大模型经典书籍可以帮助读者提高技术水平,开拓视野,掌握核心技术,提高解决问题的能力,同时也可以借鉴他人的经验。对于想要深入学习AI大模型开发的读者来说,阅读经典书籍是非常有必要的。

实战案例
光学理论是没用的,要学会跟着一起敲,要动手实操,才能将自己的所学运用到实际当中去,这时候可以搞点实战案例来学习。

面试资料
我们学习AI大模型必然是想找到高薪的工作,下面这些面试题都是总结当前最新、最热、最高频的面试题,并且每道题都有详细的答案,面试前刷完这套面试题资料,小小offer,不在话下

640套AI大模型报告合集
这套包含640份报告的合集,涵盖了AI大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,这套报告合集都将为您提供宝贵的信息和启示。

这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】















 303
303

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









