







如果在扣减数据时,发生异常出现回滚,那么此时就需要回滚成之前的值,就是需要一个日志来记录扣减之前的值,那么就是通过这个undolog来记录的。就是说在这个update更新语句中,在开启事务之后,提交事务之前,这个库存100就会记录在undolog日志里面,减完后的80这个值如果整个事务没有出现异常那么就直接加入到数据库里面,如果出现异常那么就将undolog里面的值作为回滚数据。一句话说这个undolog日志**就是用来记录被修改的值,防止出现异常回滚的**
### 2,undolog版本控制链
当然这个undolog日志也不是只记录一条,如在一个或者多个事务中对这个库存进行了多次的修改,那么这个undolog就会形成一条历史版本控制链。在这个版本控制链中,有一个隐藏的事务id和指针。事务id在新增或者更新都会生成一个事务id,默认**自增**(重点);指针所指向的就是当前数据修改前的一个历史数据,如果出现了回滚,那么就会根据这个链路依次的往前回滚,直到找到上一个或者前面几个。
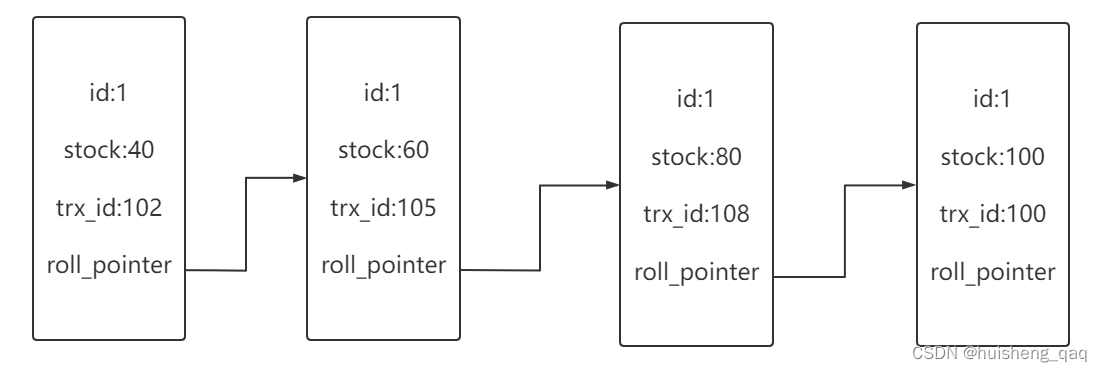
这个事务id是在sql更新或者新增的时候生成,并非事务提交的时候生成,因此可能出现事务大的id先提交,那么版本控制链路里面的事务id的大小就是乱序的。
### 3,readView
#### 3.1,readview简介
在上面的undolog日志里面,可以发现确实时记录了所有的修改的值,也知道这个undolog是用来回滚的,但是会存在一个问题,如果单纯使用一个undolog来解决这个回滚问题,那么就会不知道回滚到链路中的哪一个结点,因此就需要引入这个readView来和这个undolog结合使用,通过readview来知道需要回滚到链路的哪一个结点。
在一个事务里面,执行任何查询都会生成当前事务的一致性视图read-view,在可重复读中的事务隔离级别中,该视图在事务结束之前都不会变化。当然如果是读已提交的隔离级别那么在每次执行sql时都会重新生成视图。
在可重复读的事务里面,这个readview视图由未提交的事务id数组和已创建的最大事务id(max\_id)组成,因此这个最大的 **max\_id** 可能在数组里面,也可能不在,因为事务最大的id可能先提交,而数组里面的id都是未提交的。
[trx_id1,trx_id2],max_id
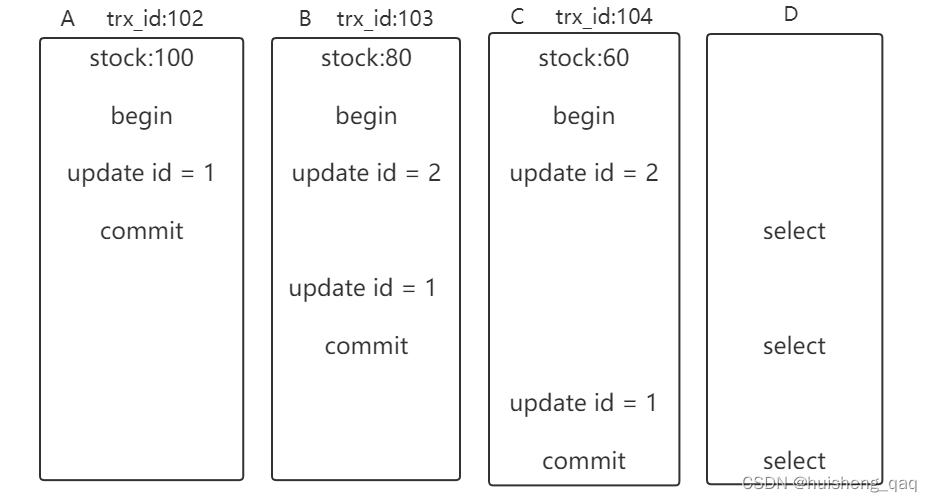
如上图,有四个事务ABCD,同时开启事务,同时去操作这个商品表的库存,事务ABC在执行更新语句之后,就会产生一个事务id,因为事务id是自增的,因此从左往右事务依次递增。而事务D里面主要是用来查询,并无增删改操作,主要是查询当前事务中的库存的数量,由于没有更新和查询语句,因此也没有事务id。由于三个事务是同时开始,因此commit提交的时间取决于更新语句的时间,谁先更新完谁先提交,因此可能会出现事务大的id先提交。
**上图主要是针对库存表中id为1的那一行数据进行操作的,而id=2只是为了通过更新语句给这个事务生成一个事务id**。
并且mvcc机制主要是针对于可重复读的这个隔离级别,因此在D中暂时只考虑查询有其他事务提交的数据,未提交之前的数据暂时不做select查询考虑
#### 3.2,readview和undolog结合使用规则
在使用这个readview只能看到当前的几个事务,并且不能得知事务的提交顺序,因此需要结合上面所说的undolog一起使用。在两者结合使用之前,需要有一个readview视图和undolog版本的比对规则,接下来先详细的说一下这个比对规则的一些命名:**假设这个数组中未提交的的事务id数组的最小值假设为min\_id,已创建事务的事务id的最大id为max\_id,undolog版本控制链的头结点为head结点**。如在下面的第三个select查询语句中,min\_id = 102 , max\_id = 104。
然后以这个min\_id和这个max\_id为分界处,小于这个min\_id的为已提交事务,在这两个值区间的为未提交或者已提交事务,大于这个max\_id的,为未开始事务。

那么规则如下:
>
> head结点的事务id <= min\_Id:已提交的事务,该事务是可见的
>
>
> min\_Id < head结点的事务id <= max\_Id:未提交的事务或者已提交的事务
>
>
> 如果事务id在数组中:表示事务未提交,不可见
>
>
> 如果事务id不在数组中:那么表示已提交,是可见的
>
>
> max\_Id < head结点的事务id : 未开始的事务,不可见
>
>
>
总结:**只要满足一个事务是可见的,那么这个版本控制链路对应结点的值就是需要找的值**。
#### 3.3,readview和undolog基本使用
1,假设库存一开始为200,由于事务id是自增,那么可以暂时假设这个事务trx\_id=101的值对应的库存就是200,那么在事务D中,在第一次查询之后就会生成一个readview视图,并且在事务提交之前,这个视图的值不会改变。接下来主要研究一下在这个RR的默认级别事务中,为何select查询的值可以不变化,以及readview和undolog匹配的过程是咋样的。
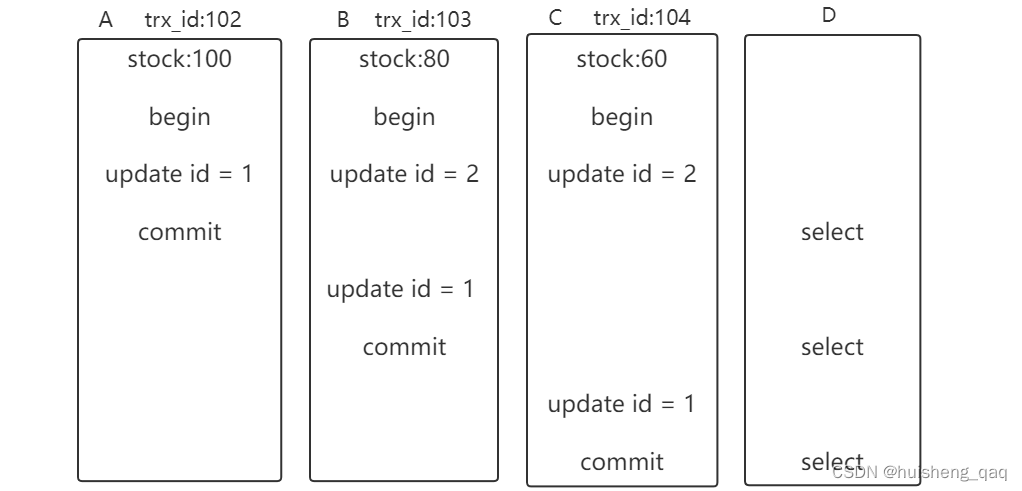
2,接下来看第一个select查询,此时事务ABC都因为有了更新语句,因此此时abc都有对应的事务,并且事务A已经提交事务,此时的事务readview组成如下,而undolog链路中的值如下图,因为主要是针对表中id为1的库存对应的版本链路,因此暂时只有两个数据,bc中两个更新语句只为了生成事务id,数据并不在一个undolog版本链路上,并且此时头节点head对应的事务id为102。
**那么通过这个头结点head对应的事务和readview的视图进行对比,此时的head事务id为102,min\_id为数组中最小值103,max\_id为已创建的最大值id104,根据版本比对规则,符合第一条head结点的事务id小于min\_id,即当前结点时可见的,只要获取到的值是可见的,那么查询到的值就是这个事务对应的值,即100**。
//第一个select查询语句的值,由未提交的事务id数组和已创建的最大的事务id组成
[103,104],104

3,接下来看第二个select查询语句,此时的事务B提交了,事务B是操作id为1的商品数据,因此在更新时会将原始值加入到这个undolog的日志版本链路上。由于事务D并没有提交,因此此时的readview如下,和之前一样,但是undolog日志链路会多一条数据,其链路如下图
**那么此时的头节点的值为事务id103,即head对应的事务id为103,min\_id为103,max\_id为104。根据版本对比规则,符合第二条,但是此时的head对应的事务id还在数组中,因此这个结点的数据并不可见。那么将继续对比下一个结点,下一个结点的事务id为102,符合第一条head结点的事务id小于min\_id,即事务id为102对应的结点时可见的,那么查询到的值仍然时100**
//第二个select查询语句的值,由未提交的事务id数组和已创建的最大的事务id组成
[103,104],104

4,接下来再看第三个select语句,第三个select查询语句就是在事务C提交之后进行查询的,那么此时的readview视图如下,依旧不变,因为操作的是id为1的值,因此undolog版本链路上会多一条数据。
**此时的头节点head的事务id为104,min\_id为103,max\_id为104。根据版本对比规则,符合第二条,但是此时的head对应的事务id还在数组中,因此这个结点的数据并不可见;那么将继续对比下一个结点,下一个结点的事务id为103,符合第二条,但是此时的head对应的事务id还在数组中,因此这个结点的数据也不可见;接下来对比第三条,head结点的事务id为102,小于min\_id103,即事务id为102对应的结点时可见的,那么查询到的值仍然时100**
//第三个select查询语句的值,由未提交的事务id数组和已创建的最大的事务id组成
[103,104],104

因此不管后面有再多的其他事务更改,只要当前事务没有提交,那么当前事务对应的readview就不会改变,通过undolog的日志版本链路,并且结合readview的版本比对规则,就可以找到一个可见的事务对应的数据,那并且这个值一定是最先获取的值,就如上面商品的库存,即使数据库中的值真的变了,也可以通过这个mvcc机制来保证事务的隔离性,从而解决使用读写锁效率低慢的问题。一句话总结就是:**根据数据版本链对比规则,来读取同一条数据在版本链上的不同版本数据,并且可以存在多个事务形成多个readview,但是版本链undolog只有一条**
### 4,总结
**mvcc被称为多版本并发控制机制,由于mysql中的事务默认使用的是可重复读,在这个隔离级别中并没有解决幻读问题,因此可以通过mvcc机制解决,并且还可以解决并发中读写锁,读写冲突问题,从而提高并发读写的性能和效率。mvcc机制主要就是通过undolog的日志版本控制链和readview视图组成。undolog链路中的每个结点由一个事务id和一个指针组成,事务id是在更新或者插入数据时会生成,指针是用来指向上一个版本,在执行完更新语句时就会将这个事务id加入到版本链路中;readview视图由未提交的事务id数组和已创建的最大的事务id组成,并且在一个事务中,第一次select查询就会生成一个readview视图,并且在事务提交之前该事务的readview视图不变。然后根据readview视图比对规则,其规则就是将undolog链路中的头节点为head结点,将数组中的最小id为min\_id,将已创建的最大的id为max\_id,然后根据视图比对规则,找到一个事务id是可见的,那么找到的第一个可见的值,该事务id对应结点的值就是需要查询出来的值。主要就是通过版本链比对规则,来读取同一条数据版本链路上面的不同数据。这样就可以保证在一个事务中查询的值可以一直不变,不受其他事务的影响,并且这种方案的效率远远高于读写锁。**
# 总结
其他的内容都可以按照路线图里面整理出来的知识点逐一去熟悉,学习,消化,不建议你去看书学习,最好是多看一些视频,把不懂地方反复看,学习了一节视频内容第二天一定要去复习,并总结成思维导图,形成树状知识网络结构,方便日后复习。
这里还有一份很不错的《Java基础核心总结笔记》,特意跟大家分享出来
**目录:**

**部分内容截图:**


记》,特意跟大家分享出来
**目录:**
[外链图片转存中...(img-revTjypA-1720083466668)]
**部分内容截图:**
[外链图片转存中...(img-CDtpyMoi-1720083466669)]
[外链图片转存中...(img-60gFD6Bv-1720083466669)]















 612
612

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









