







文末赠免费精品编程资料~~
NumPy 是 Python 编程语言中用于数值计算的核心库之一,在统计分析方面,它也提供了各种各样的函数来实现统计分析。
NumPy统计分析功能概览
-
基本统计量:计算平均值、中位数、众数、标准差、方差等。
-
排序和搜索:排序数组、查找最大值、最小值、百分位数等。
-
聚合操作:求和、乘积、累加等。
-
随机数生成:生成随机数,用于模拟和实验设计。
-
线性代数:矩阵运算、特征值分解等,间接支持统计建模。
本文介绍一些numpy常用的一些统计分析案例的代码。
示例数据
import numpy as np
# 示例数据
np.random.seed(0) # 设置随机种子以获得可重复的结果
data = np.random.normal(loc=0.0, scale=1.0, size=(100, 5))
1. 计算每一列的均值
mean_values = np.mean(data, axis=0)
print("Mean values:", mean_values)

2. 计算每一列的标准差
std_dev = np.std(data, axis=0)
print("Standard Deviations:", std_dev)
![]()
3. 找出每列的最大值和最小值
max_values = np.max(data, axis=0)
min_values = np.min(data, axis=0)
print("Max values:", max_values)
print("Min values:", min_values)

4. 计算每一列的中位数
median_values = np.median(data, axis=0)
print("Median values:", median_values)
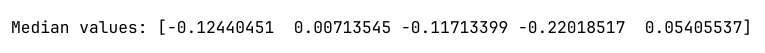
5. 计算每一列的四分位数
percentiles = np.percentile(data, [25, 50, 75], axis=0)
print("Percentiles:", percentiles)

6. 计算每一列的方差
variance = np.var(data, axis=0)
print("Variances:", variance)

7. 计算每一列的偏度和峰度
from scipy.stats import skew, kurtosis
skewness = np.apply_along_axis(lambda x: skew(x), 0, data)
kurtosis = np.apply_along_axis(lambda x: kurtosis(x), 0, data)
print("Skewness:", skewness)
print("Kurtosis:", kurtosis)

skew和kurtosis 函数需要至少有三个非零值的数组才能计算,否则它们会抛出错误。这样 apply_along_axis函数 可以沿着第一个轴(即列)来计算。
8. 计算每一列的累积和
cumulative_sum = np.cumsum(data, axis=0)
print("Cumulative sum of last row:", cumulative_sum[-1])

9. 使用广播进行数据标准化
normalized_data = (data - np.mean(data, axis=0)) / np.std(data, axis=0)
print("Normalized data sample:", normalized_data[:3])

10. 计算每一列的累乘
cumulative_product = np.cumprod(data, axis=0)
print("Cumulative product of last row:", cumulative_product[-1])
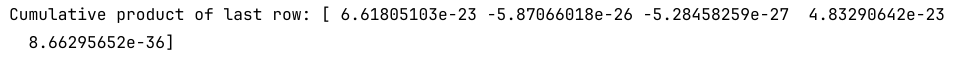
11. 计算每一列的几何平均数
geometric_mean = np.exp(np.mean(np.log(np.abs(data)), axis=0))
print("Geometric means:", geometric_mean)

12. 计算每一列的调和平均数
harmonic_mean = np.mean(1 / data, axis=0)**-1
print("Harmonic means:", harmonic_mean)

13. 使用高级索引进行数据筛选
mask = data > 0
positive_data = data[mask]
print("Positive data count:", len(positive_data))

14. 计算每一列的中位绝对偏差
mad = np.median(np.abs(data - np.median(data, axis=0)), axis=0)
print("Median absolute deviations:", mad)

15. 计算每一列的四分位距
iqr = np.subtract(*np.percentile(data, [75, 25], axis=0))
print("Interquartile ranges:", iqr)
![]()
16. 离群值检测
q1 = np.percentile(data, 25, axis=0)
q3 = np.percentile(data, 75, axis=0)
iqr = q3 - q1
lower_bound = q1 - 1.5 * iqr
upper_bound = q3 + 1.5 * iqr
outliers = ((data < lower_bound) | (data > upper_bound)).any(axis=1)
print("Outliers count:", outliers.sum())

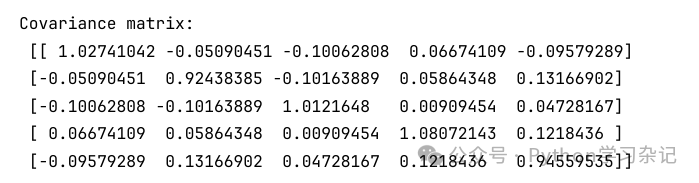
17. 计算每一列的协方差矩阵
cov_matrix = np.cov(data.T)
print("Covariance matrix:\n", cov_matrix)
18. 计算每一列的相关系数矩阵
corr_matrix = np.corrcoef(data.T)
print("Correlation matrix:\n", corr_matrix)

本文介绍了 NumPy 在执行数据统计分析时的多种高效方法。通过这些方法,大家可以快速掌握统计分析的技巧,并在实际应用中更加灵活地应对各种复杂问题。
文末福利
如果你对Python感兴趣的话,可以试试我整理的这一份全套的Python学习资料,【点击这里】免费领取!
包括:Python激活码+安装包、Python
web开发,Python爬虫,Python数据分析,人工智能、自动化办公等学习教程。带你从零基础系统性的学好Python!
① Python所有方向的学习路线图,清楚各个方向要学什么东西
② 100多节Python课程视频,涵盖必备基础、爬虫和数据分析
③ 100多个Python实战案例,学习不再是只会理论
④ 华为出品独家Python漫画教程,手机也能学习
⑤ 历年互联网企业Python面试真题,复习时非常方便
















 1556
1556

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









