






链表是线性表的一种。
线性表有两种存储结构:
1、顺序存储结构:用一段地址连续的存储单元依次存储线性表的数据元素;
2、链式存储结构(链表):是由一系列连接在一起的结点构成,其中的每个结点都是一个数据结构
(2)链表的结构:
先介绍链表的结构成分:
1、结点
结点有两部分信息组成,一部分是数据域:用来存放数据元素信息;另一种用来存放地址的域称为指针域,指针域中存储的信息称作指针或链。我们把结点记为Node。
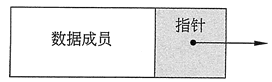
2、头结点:
(1):头结点是为了操作的统一与方便而设立的,放在第一个元素结点之前,其数据域一般无意义;
(2):首元结点也就是第一个元素的结点,它是头结点(存在)后边的第一个结点(第一个结点并不是头结点);
(3):头结点不是链表所必需的。
3、头指针:
(1):在线性表的链式存储结构中,头指针是指链表指向第一个结点的指针,若链表有头结点,则头指针就是指向链表头结点的指针;
(2):头指针具有标识作用,故常用头指针冠以链表的名字。
(3):无论链表是否为空,头指针均不为空。头指针是链表的必要元素。
记住区分头结点和头指针(重要)!!!
(3)链表的构建(以单链表为例):
上面我们已经知道链表的组成,但是该如何创建呢?
步骤1:先构造结点(两种方式):
方式一:
struct Node
{
int data; // 数据域,可以自己定义类型;
Node *next; // 指针域,存放的是地址;
};
方式二(构造函数的方式):
struct Node
{
int data; // 数据域,可以自己定义类型;
Node *next; // 指针域,存放的是地址;
Node (int x):
data(x),next(NULL){}
};
结点已经定义好了,现在需要创建链表了,上面已经说了,除了结点外,头指针是链表不可缺少的。为了明白链表的每一步操作,以下链表的操作全用函数实现的形式。
步骤2:先来创建一个空链表:
Node *createlinklist() // 返回值是指向Node这个结构体类型的指针
{
Node *phead = new Node; // 方式一
Node *phead = new Node(); // 方式二
phead->next = NULL; // 让next指向“NULL”,设置当前结点的后继指针指向空
return phead; // 返回头指针
}
我们复习以下new的用法:new开辟的空间在堆上,new返回的是一段空间的首地址。因此我们用Node *phead 结构体指针去接收它。
而Node *phead = new Node() 这句话的意思就是创建了指向Node结构体类型的一个头指针,并且头指针指向开辟的存储空间的地址。
需要注意,phead是一个指针,用“->” 访问,而不用“.”。
我们发现上面常见空链表的代码就两三行,其实也创建了头结点和头指针,有时在主函数实现就行。
我们先回顾一下结构体:
#include <iostream>
using namespace std;
struct Node{
int value;
Node* next;
};
int main()
{
Node node1, node2;
node1.value = 1;
node2.value = 2;
node1.next = &node2;
cout << (node1.next)->value << endl;
cout << "&node1=" << &node1 << endl;
cout << "node1.next=" << node1.next << endl;
cout << "&node2=" << &node2 << endl;
}
先生成两个node类的实例,node1和node2,分别将它们的value初始化为1和2,再用&运算符取出node2的首地址,赋值给node1.next。这样node1的next指针就指向了node2。这样我们就可以先拿到node1的next指针,在通过“->”运算符访问node2的value值,输出就是2。
其运行结果如下:
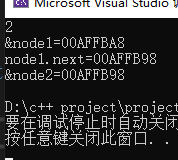
细心的人已经发现,这两个结点已经连在一起形成链表了,但是这样创建结点并连接会发现效率很低,node1和node2是我们提前声明好的,而我们如果创建更多结点的话显然这种方式并不合适。
故引出下文创建链表的方式:
#include <iostream>
using namespace std;
struct Node{
int value;
Node* next;
};
int main()
{
Node* head = new Node; // 创建头指针
head->next = NULL;
head->value = 1;
for (int i = 0; i < 10; i++)
{
Node *p = new Node;
p->value = i;
p->next = head;
head = p;
}
cout << head->value << endl; // 注意只打印head结点的值
}
上面添加链表的操作一般我们用函数形式实现(链表的函数都有同一的形式):
// 添加链表结点
void addList(Node *head)
{
Node* p = head;
for (int i = 0; i < 10; i++)
{
Node* q = new Node; //
q->value = i;
q->next = p;
p = q;
}
cout << p->value << endl;
}
链表已经创建好了,如何访问遍历呢?下面写遍历的函数:
// 遍历链表
void printfList(Node* head)
{
Node* p = head;
while (p!=nullptr) {
cout << p->value << endl;
p = p->next;
}
}
实现上面两个函数的主函数为:
#include <iostream>
using namespace std;
struct Node{
int value;
Node* next;
};
void printfList(Node* head)
{
Node* p = head;
while (p!=nullptr) {
cout << p->value << endl;
p = p->next;
}
}
Node * addList(Node *head)
{
Node* p = head;
for (int i = 0; i < 10; i++)
{
Node* q = new Node; //
q->value = i;
q->next = p;
p = q;
}
//cout << p->value << endl;
return p;
}
int main()
{
cout << "创建空链表" << endl;
Node* head = new Node; // 创建头指针
head->next = NULL;
head->value = 1;
cout << "添加链表" << endl;
Node *res = addList(head);
printfList(res);
}
其结果为:
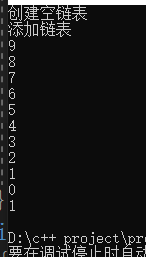
下面介绍的链表其他的功能函数。
有人可能会疑惑上面这段代码什么意思?
Node* q = new Node; //
q->value = i;
q->next = p;
p = q;















 658
658

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









