






- strconv提供类型转化的函数
// 字符串转换为十进制整数
func Atoi(s string) (int, error)
// 字符串转换为某一进制的整数,例如八进制、十六进制
func ParseInt(s string, base int, bitSize int) (i int64, err error)
// 整数转换为字符串
func Itoa(i int) string
// 某一进制的整数转换为字符串,例如八进制整数转换为字符串
func FormatInt(i int64, base int) string
字符编码
- 在 Go 语言中,字符串是默认通过 UTF-8 的形式编码的。
- 目前大多数网站都使用 UTF-8 编码,但其实服务器发送过来的 HTML 文本可能拥有很多编码形式。一些国内的网站就会采用 GB2312 的编码方式。
- 要实现编码的通用性,我们使用官方处理字符集的库:
go get golang.org/x/net/html/charset
go get golang.org/x/text/encoding
封装编码和获取网页内容
package main
import (
"bufio"
"fmt"
"github.com/funbinary/go\_example/pkg/errors"
"golang.org/x/net/html/charset"
"golang.org/x/text/encoding"
"golang.org/x/text/encoding/unicode"
"golang.org/x/text/transform"
"io"
"net/http"
)
func main() {
//url := "https://www.thepaper.cn/"
url := "https://www.chinanews.com.cn/"
body, err := Fetch(url)
if err != nil {
fmt.Println("read content failed:%v", err)
return
}
fmt.Println(string(body))
}
func Fetch(url string) ([]byte, error) {
var e encoding.Encoding
resp, err := http.Get(url)
if err != nil {
return nil, errors.Wrap(err, "fetch url error")
}
defer resp.Body.Close()
if resp.StatusCode != http.StatusOK {
return nil, errors.Errorf("Error status code:%v", resp.StatusCode)
}
r := bufio.NewReader(resp.Body)
e, err = DeterminEncoding(r)
utf8r := transform.NewReader(r, e.NewDecoder())
return io.ReadAll(utf8r)
}
func DeterminEncoding(r \*bufio.Reader) (encoding.Encoding, error) {
bytes, err := r.Peek(1024)
if err != nil {
return unicode.UTF8, err
}
e, \_, \_ := charset.DetermineEncoding(bytes, "")
return e, nil
}
正则表达式
正则表达式是一种描述文本内容组成规律的表示方式,它可以描述或者匹配符合相应规则的字符串。
用途
- 校验数据的有效性
- 搜索
- 替换特定模式的字符串
标准
-
POSIX
- BRE
- ERE
- Linux 和 Mac 在原生集成 GNU 套件(例如 grep 命令)时,遵循了 POSIX 标准,并弱化了 GNU BRE 和 GNU ERE 之间的区别。
- GNU BRE 和 GNU ERE 的差别主要体现在一些语法字符是否需要转义上
# BRE > echo "addf" | grep 'd\{1,3\}' # ERE 需要使用-E参数 > echo "addf" | grep -E 'd{1,3}' -
PCRE
- perl演进
- 大部分高级语言,包括Go使用
- grep要使用 -P
# 使用 ERE 标准 > echo "11d23a" | grep -E '[[:digit:]]+' # 使用 PCRE 标准 > echo "11d23a" | grep -P '\d+'
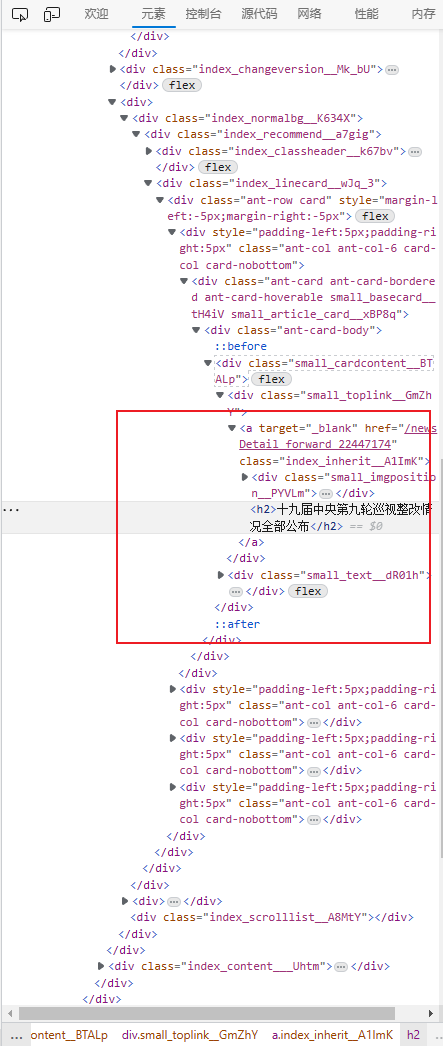
获取推荐页面标题
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-aKEIRy1k-1679758861177)(https://assets.b3logfile.com/siyuan/1658627274984/assets/image-20230325230448-leqouxs.png)]
package main
import (
"bufio"
"fmt"
"github.com/funbinary/go\_example/pkg/errors"
"golang.org/x/net/html/charset"
"golang.org/x/text/encoding"
"golang.org/x/text/encoding/unicode"
"golang.org/x/text/transform"
"io"
"net/http"
"regexp"
)
// var headerRe = regexp.MustCompile(`<div class="news\_li"[\s\S]\*?<h2>[\s\S]\*?<a.\*?target="\_blank">([\s\S]\*?)</a>`)
var headerRe = regexp.MustCompile(`<div class="small\_cardcontent\_\_BTALp"[\s\S]\*?<h2>([\s\S]\*?)</h2>`)
func main() {
url := "https://www.thepaper.cn/"
body, err := Fetch(url)
if err != nil {
fmt.Println("read content failed:%v", err)
return
}
matches := headerRe.FindAllSubmatch(body, -1)
for \_, m := range matches {
fmt.Println("fetch card news:", string(m[1]))
}
}
func Fetch(url string) ([]byte, error) {
var e encoding.Encoding
resp, err := http.Get(url)
if err != nil {
return nil, errors.Wrap(err, "fetch url error")
}
defer resp.Body.Close()
if resp.StatusCode != http.StatusOK {
return nil, errors.Errorf("Error status code:%v", resp.StatusCode)
}
r := bufio.NewReader(resp.Body)
e, err = DeterminEncoding(r)
utf8r := transform.NewReader(r, e.NewDecoder())
return io.ReadAll(utf8r)
}
func DeterminEncoding(r \*bufio.Reader) (encoding.Encoding, error) {
bytes, err := r.Peek(1024)
if err != nil {
return unicode.UTF8, err
}
e, \_, \_ := charset.DetermineEncoding(bytes, "")
return e, nil
}
Xpath
XPath 定义了一种遍历 XML 文档中节点层次结构,并返回匹配元素的灵活方法。而 XML 是一种可扩展标记语言,是表示结构化信息的一种规范。例如,微软办公软件 Words 在 2007 之后的版本的底层数据就是通过 XML 文件描述的。HTML 虽然不是严格意义的 XML,但是它的结构和 XML 类似。
获取推荐页面标题
package main
import (
"bufio"
"bytes"
"fmt"
"github.com/antchfx/htmlquery"
"github.com/funbinary/go\_example/pkg/errors"
"golang.org/x/net/html/charset"
"golang.org/x/text/encoding"
"golang.org/x/text/encoding/unicode"
"golang.org/x/text/transform"
"io"
"net/http"
)
// xpath
func main() {
url := "https://www.thepaper.cn/"
body, err := Fetch(url)
if err != nil {
fmt.Println("read content failed:%v", err)
return
}
doc, err := htmlquery.Parse(bytes.NewBuffer(body))
if err != nil {
fmt.Println("htmlquery.Parse failed:%v", err)
}
nodes := htmlquery.Find(doc, `//div[@class="small\_cardcontent\_\_BTALp"]//h2`)
for \_, node := range nodes {
fmt.Println("fetch card news:", node.FirstChild.Data)
}
}
func Fetch(url string) ([]byte, error) {
var e encoding.Encoding
resp, err := http.Get(url)
if err != nil {
return nil, errors.Wrap(err, "fetch url error")
}
defer resp.Body.Close()
if resp.StatusCode != http.StatusOK {
return nil, errors.Errorf("Error status code:%v", resp.StatusCode)
}
r := bufio.NewReader(resp.Body)
e, err = DeterminEncoding(r)
utf8r := transform.NewReader(r, e.NewDecoder())
return io.ReadAll(utf8r)
}
func DeterminEncoding(r \*bufio.Reader) (encoding.Encoding, error) {
bytes, err := r.Peek(1024)
if err != nil {
return unicode.UTF8, err
}
e, \_, \_ := charset.DetermineEncoding(bytes, "")
return e, nil
}
CSS选择器
CSS(层叠式样式表)是一种定义 HTML 文档中元素样式的语言。在 CSS 文件中,我们可以定义一个或多个 HTML 中的标签的路径,并指定这些标签的样式。在 CSS 中,定义标签路径的方法被称为 CSS 选择器。
CSS 选择器考虑到了我们在搜索 HTML 文档时常用的属性。我们前面在 XPath 例子的中使用的 div[@class=“news_li”],在 CSS 选择器中可以简单地表示为 div.news_li。这是一种更加简单的表示方法。
package main
import (
"bufio"
"bytes"
"fmt"
"github.com/PuerkitoBio/goquery"
"github.com/funbinary/go\_example/pkg/errors"
"golang.org/x/net/html/charset"
"golang.org/x/text/encoding"
"golang.org/x/text/encoding/unicode"
"golang.org/x/text/transform"
"io"
"net/http"
)
// xpath
func main() {
url := "https://www.thepaper.cn/"
body, err := Fetch(url)
if err != nil {
fmt.Println("read content failed:%v", err)
return
}
doc, err := goquery.NewDocumentFromReader(bytes.NewBuffer(body))
if err != nil {
fmt.Println("htmlquery.Parse failed:%v", err)
}
doc.Find("div.small\_cardcontent\_\_BTALp h2").Each(func(i int, selection \*goquery.Selection) {
title := selection.Text()
fmt.Println("fetch card:", i, " ", title)
})
}
func Fetch(url string) ([]byte, error) {
var e encoding.Encoding
resp, err := http.Get(url)
if err != nil {
return nil, errors.Wrap(err, "fetch url error")
}
defer resp.Body.Close()
if resp.StatusCode != http.StatusOK {
return nil, errors.Errorf("Error status code:%v", resp.StatusCode)
}
r := bufio.NewReader(resp.Body)
e, err = DeterminEncoding(r)
utf8r := transform.NewReader(r, e.NewDecoder())
return io.ReadAll(utf8r)
}
func DeterminEncoding(r \*bufio.Reader) (encoding.Encoding, error) {
bytes, err := r.Peek(1024)
if err != nil {
return unicode.UTF8, err
}
e, \_, \_ := charset.DetermineEncoding(bytes, "")
return e, nil
}
思考题
在类似如下的日志文件中,包含了很多订单号的信息,即 order_id 后面的一串数字。我们可以用什么方式,将 order_id 后面的订单 ID 都像下面这样打印出来?(提示:用 grep 就可以做到)
2022-11-22 name=versionReport||order_id=3732978217343693673||trace_id=XXX
2022-11-22 name=versionReport||order_id=3732978217343693674||trace_id=XXX
grep -oP 'order_id=\d+'|grep -oP '\d+'
grep -oE 'order_id=\d+' | grep -oE '\d+'















 810
810

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









