






ID自动生成
======
前面文章中,我们添加一个文档执行的请求如下:
curl -X PUT “localhost:9200/twitter/_doc/1?pretty” -H ‘Content-Type: application/json’ -d’
{
“user” : “kimchy”,
“post_date” : “2009-11-15T14:12:12”,
“message” : “trying out Elasticsearch”
}
’
在type后面有一个1表示文档的id,这个id也可以不写,不写默认会自动生成id,请求如下:
curl -X POST “localhost:9200/twitter/_doc?pretty” -H ‘Content-Type: application/json’ -d’
{
“user” : “kimchy”,
“post_date” : “2009-11-15T14:12:12”,
“message” : “trying out Elasticsearch”
}
’
在这个请求中,op_type会被自动设置为create,执行结果如下:
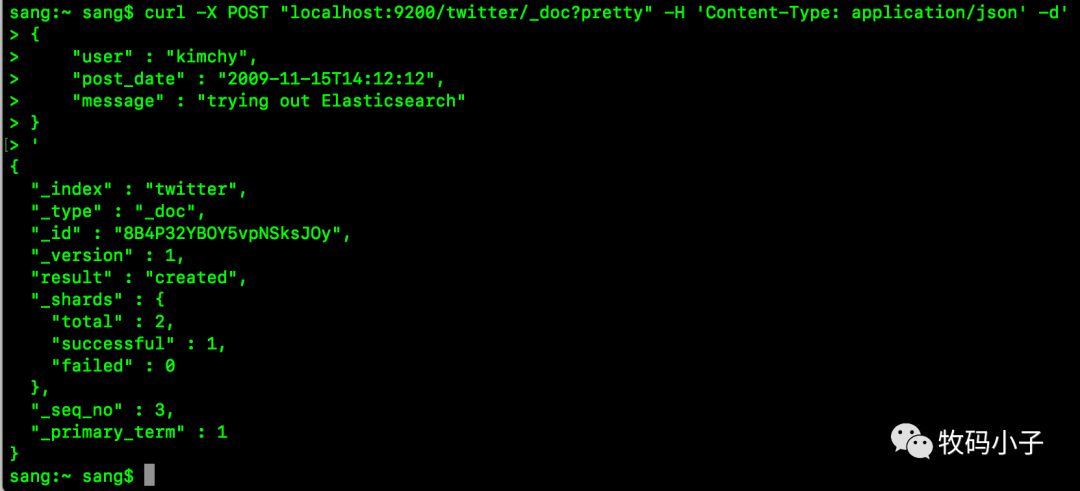
可以看到,此时生成的id是一个字符串。
路由机制
====
Elasticsearch是一个分布式系统,当一个文档要被索引时,该文档会被索引到系统中的某一个分片上,那么到底是哪一个分片呢?在elasticsearch文档读写模型一文中,我们简单介绍过这个话题,但是没有深入探究,这里,就和读者一起来探讨下Elasticsearch中的路由机制。
分片位置的计算公式如下:
position=hash(routing) % numberofprimary_shards
在这里,routing是一个任意字符串,Elasticsearch默认是将文档的id作为routing值,通过hash函数计算后,生成一个数字,这个数字再和主分片的总数取余,得到一个处于 [0,number_of_primary_shards-1]区间内的数,该数字就是该文档所在的分片。基于这样的映射模式,Elasticsearch不支持索引创建成功后,修改分片数量,即分片数量要一开始就确定好,以后不能修改,否则会导致之前计算出来的position失效(即查找时找不到之前的文档,因此numberofprimary_shards已经变了)。
默认情况下,这种路由机制会通过id将文档平均分配在所有的分片上,这也导致了Elasticsearch无法确定一个文档的具体位置,当有查询请求时,它需要将查询请求广播到所有分片上去执行,这无疑降低的查询的效率,对于这个问题,读者可以使用自定义路由模式去解决,如下请求:
curl -X POST “localhost:9200/twitter/_doc/1?pretty&routing=sang” -H ‘Content-Type: application/json’ -d’
{
“user” : “kimchy”,
“post_date” : “2009-11-15T14:12:12”,
“message” : “trying out Elasticsearch”
}
’
开发者在添加文档时指定路由,在查询的时候也指定路由,这样就可以避免Elasticsearch向所有的分片发送查询请求,减少系统资源的消耗,查询请求如下:
curl -X GET “localhost:9200/twitter/_search?pretty&routing=sang”
不过这种方式又会带来另外一个问题,即路由相同的文档总是被分在同一个分片上,无法做到将文档平均分配在不同的分片上,因此,两种不同的方式,需要读者在开发中根据实际需求进行取舍。
分布式
===
基于路由机制,索引操作将被定向到主分片上并执行,在主分片完成操作后,如果需要,再将更新操作分发到副本分片上。
Wait For Active Shardsedit
==========================
为了提高写入系统的 resiliency(弹性),索引操作可以配置为在继续索引之前等待一定数量的活动副本分片,如果所需的活动副本分片数没有达到指定数量,那么写入操作必须等待并且重试,直到必需的副本分片数已启动,或者发生了超时为止。
在默认情况下,只需要主分片处于活动状态,写操作就会继续,开发者可以通过设置 index.write.wait_for_active_shards来动态地在索引设置中覆盖此默认值。要只是需要更改每个操作的此行为,则可以使用 wait_for_active_shards请求参数,参数有效值是 all或任何不大于副本分片数的正整数,如果指定负值或者大于副本分片数的数字将抛出错误。
例如,假设我们有一个集群,该集群有三个节点A,B和C,我们创建一个索引,索引副本数设置为3。默认情况下,索引操作将仅确保每个分片的主副本在操作之前可用。这意味着,即使B和C下线了,只要A托管了主副本分片,索引操作仍然执行。如果请求设置 wait_for_active_shards为3(并且3个节点都已启动),则索引操作将在执行之前需要3个活动副本分片,这是必须满足的要求,因为在集群有3个活动节点,每个节点有一个分片的副本。但是,如果我们将 wait_for_active_shards设置为 all(即4),索引操作将不会执行,因为索引中的每个分片的4没有四个副本,那么该操作将超时,除非在集群中启动新节点以托管分片的第四个副本。
重要的是要注意,这个设置极大地减少了写操作不写入所需数量的副本分片的可能性,但是它不能完全消除这种可能性,因为这种检查在写操作开始之前发生,一旦写操作正在进行,复制仍然可能在任意数量的副本分片上失败,但在主分片上成功。写操作响应的 _shard字段显示复制成功/失败的副本分片的数量。
Noop Updates
============
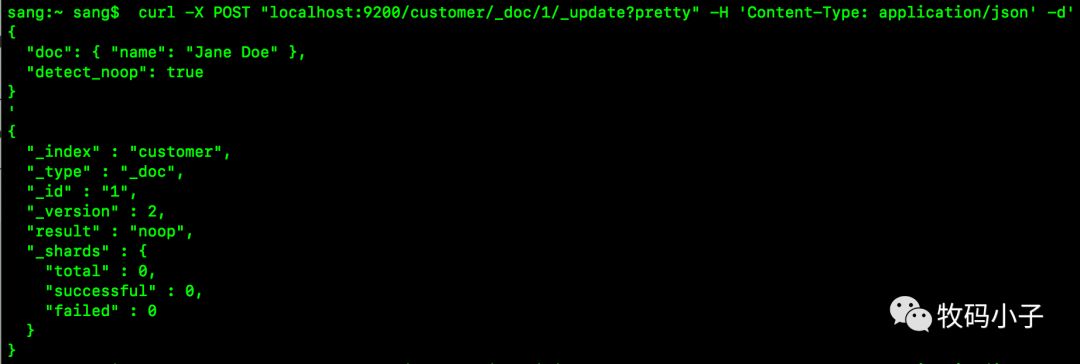
当使用索引API更新文档时,即使文档没有更改,也始终创建新版本的文档。如果这不可接受,请使用将 detectnoop设置为true的update API 。此选项在索引API上不可用,因为索引api无法提取旧的文档,当然也无法和新的文档进行比较,具体用法如下图:
Timeout
=======
执行索引操作时分配的主分片可能不可用,原因各种个样,此时,索引操作将在主分片上等待最多1分钟,然后失败并响应错误。 timeout参数可以用于显式指定等待时间。以下是将其设置为5分钟的示例:
curl -X PUT “localhost:9200/twitter/_doc/1?timeout=5m” -H ‘Content-Type: application/json’ -d’
{















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









