






RLHF-Reward-Modeling: 训练RLHF奖励模型的开源工具包
RLHF-Reward-Modeling是一个专门用于训练强化学习中人类反馈(RLHF)奖励模型的开源项目。该项目由RLHFlow团队开发维护,提供了多种先进的奖励模型实现和训练方法,旨在帮助研究人员和开发者更好地捕捉人类偏好,从而改进RLHF的效果。
主要特点
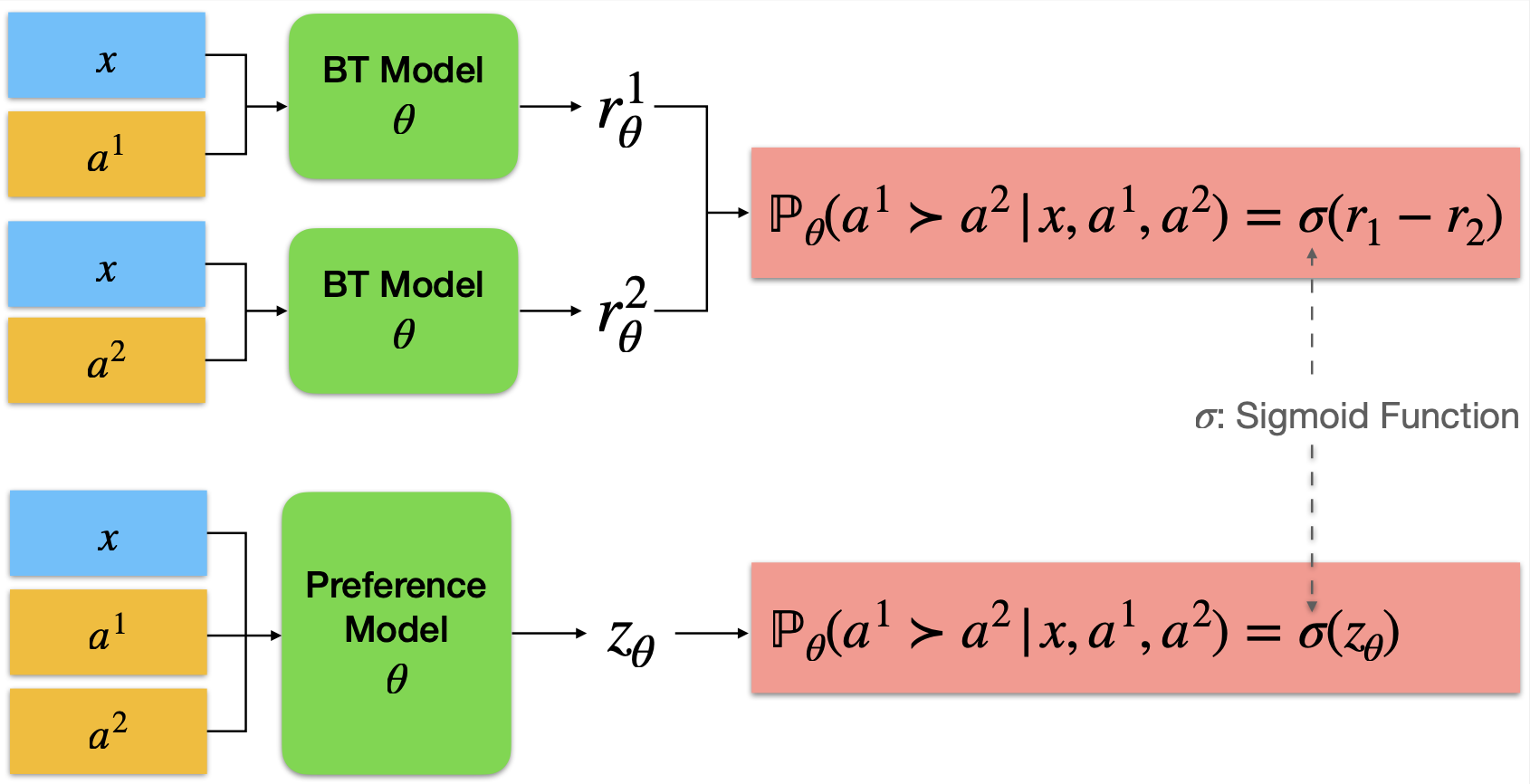
- 提供多种奖励模型实现,包括ArmoRM、配对偏好模型和Bradley-Terry模型等
- 支持大规模语言模型训练,如Gemma-7B等
- 在RewardBench基准测试中取得了SOTA性能
- 提供详细的安装说明和数据集准备指南
- 包含多个评估脚本和实用工具
核心模型
-
ArmoRM (Absolute-Rating Multi-Objective Reward Model)
- 在RewardBench上排名第一的8B模型
- 利用多目标奖励建模和专家混合实现可解释性偏好
-
配对偏好模型
- 基于SliC-HF方法实现
- 在RewardBench上表现优异
-
Bradley-Terry奖励模型
- 经典的比较建模方法
- 在某些任务上表现出色,如聊天任务
使用指南
-
安装 推荐为Bradley-Terry奖励模型和配对偏好模型创建单独的环境。详细安装说明请参考相应文件夹。
-
数据集准备 数据集需要预处理成标准格式,每个样本包含"chosen"和"rejected"两个对话,共享相同的prompt。
-
模型训练 提供了多种训练脚本,支持不同的模型架构和训练策略。
-
评估 可以使用RewardBench提供的数据集评估训练好的奖励模型。
相关资源
RLHF-Reward-Modeling为RLHF研究和应用提供了强大的工具支持。无论是想深入研究RLHF奖励建模,还是将其应用到实际项目中,这个开源项目都是一个很好的起点。欢迎探索使用,为RLHF的发展贡献力量!
文章链接:www.dongaigc.com/a/rlhf-reward-modeling-resources
https://www.dongaigc.com/a/rlhf-reward-modeling-resources















 103
103

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









