




【生成式AI】DDPM(去噪扩散概率模型)和DDIM(去噪扩散隐式模型):从随机噪声到艺术创作的魔法之旅
【生成式AI】DDPM(去噪扩散概率模型)和DDIM(去噪扩散隐式模型):从随机噪声到艺术创作的魔法之旅
文章目录
欢迎铁子们点赞、关注、收藏!
祝大家逢考必过!逢投必中!上岸上岸上岸!upupup
大多数高校硕博生毕业要求需要参加学术会议,发表EI或者SCI检索的学术论文会议论文。详细信息可扫描博文下方二维码 “
学术会议小灵通”或参考学术信息专栏:https://ais.cn/u/mmmiUz
DDPM与DDIM:从随机噪声到艺术创作的魔法之旅
- 探索生成式AI中两种核心扩散模型的原理与奥秘
- 在人工智能生成内容(AIGC)的浪潮中,扩散模型以其出色的生成质量和稳定性成为了当之无愧的明星。今天,我们将深入解析两种重要的扩散模型——DDPM(去噪扩散概率模型)和DDIM(去噪扩散隐式模型),揭示它们如何将随机噪声转化为惊艳的图像作品。
一、 基础概念:什么是扩散模型?
想象一下,你有一幅清晰的画作,然后不断地在上面撒上细微的噪点,直到画作完全变成随机噪声。接着,你尝试学习如何逆向这个过程——从随机噪声一步步恢复出原始画作。这就是扩散模型的核心思想。
1.1 扩散过程的核心组件
- 前向过程:逐步破坏数据,添加噪声
- 反向过程:学习从噪声中恢复原始数据
- 噪声调度:控制每一步添加的噪声量
二、 DDPM:扩散模型的奠基者
2.1 前向过程:数据的渐进式破坏
- DDPM的前向过程是一个固定的马尔可夫链,逐步向数据添加高斯噪声。
import torch
import torch.nn as nn
import numpy as np
class DDPMScheduler:
def __init__(self, num_timesteps=1000, beta_start=0.0001, beta_end=0.02):
self.num_timesteps = num_timesteps
# 线性噪声调度
self.betas = torch.linspace(beta_start, beta_end, num_timesteps)
self.alphas = 1. - self.betas
self.alpha_bars = torch.cumprod(self.alphas, dim=0) # ᾱ_t = ∏(1-β_s)
def add_noise(self, x0, t, noise=None):
"""前向扩散过程:根据时间步t向x0添加噪声"""
if noise is None:
noise = torch.randn_like(x0)
# 计算当前时间步的ᾱ_t
alpha_bar_t = self.alpha_bars[t].view(-1, 1, 1, 1)
# 前向扩散公式:x_t = √ᾱ_t * x0 + √(1-ᾱ_t) * ε
xt = torch.sqrt(alpha_bar_t) * x0 + torch.sqrt(1 - alpha_bar_t) * noise
return xt, noise
2.2 反向过程:学习去噪的艺术
- DDPM的核心是训练一个神经网络来预测添加的噪声。
class DDPM(nn.Module):
def __init__(self, network, num_timesteps=1000):
super().__init__()
self.network = network # 通常是U-Net
self.scheduler = DDPMScheduler(num_timesteps)
def forward(self, x0, t=None):
"""训练过程:预测噪声"""
batch_size = x0.shape[0]
# 随机采样时间步
if t is None:
t = torch.randint(0, self.scheduler.num_timesteps, (batch_size,))
# 添加噪声
noise = torch.randn_like(x0)
xt, true_noise = self.scheduler.add_noise(x0, t, noise)
# 预测噪声
predicted_noise = self.network(xt, t)
# 简单的MSE损失
loss = nn.MSELoss()(predicted_noise, true_noise)
return loss
@torch.no_grad()
def sample(self, shape, device):
"""采样过程:从噪声生成图像"""
# 从纯噪声开始
x = torch.randn(shape, device=device)
# 逐步去噪
for t in reversed(range(self.scheduler.num_timesteps)):
# 预测噪声
predicted_noise = self.network(x, torch.tensor([t] * shape[0], device=device))
# 计算x_{t-1}
x = self._reverse_step(x, t, predicted_noise)
return x
def _reverse_step(self, xt, t, predicted_noise):
"""DDPM反向步骤"""
beta_t = self.scheduler.betas[t]
alpha_t = self.scheduler.alphas[t]
alpha_bar_t = self.scheduler.alpha_bars[t]
if t > 0:
z = torch.randn_like(xt)
else:
z = torch.zeros_like(xt)
# DDPM反向步骤公式
mean = (xt - beta_t * predicted_noise / torch.sqrt(1 - alpha_bar_t)) / torch.sqrt(alpha_t)
variance = torch.sqrt(beta_t)
return mean + variance * z
2.3 DDPM的优势与局限
优势:
- 训练稳定:简单的噪声预测目标
- 生成质量高:在足够多步数下产生高质量样本
- 理论完备:有坚实的概率理论基础
局限:
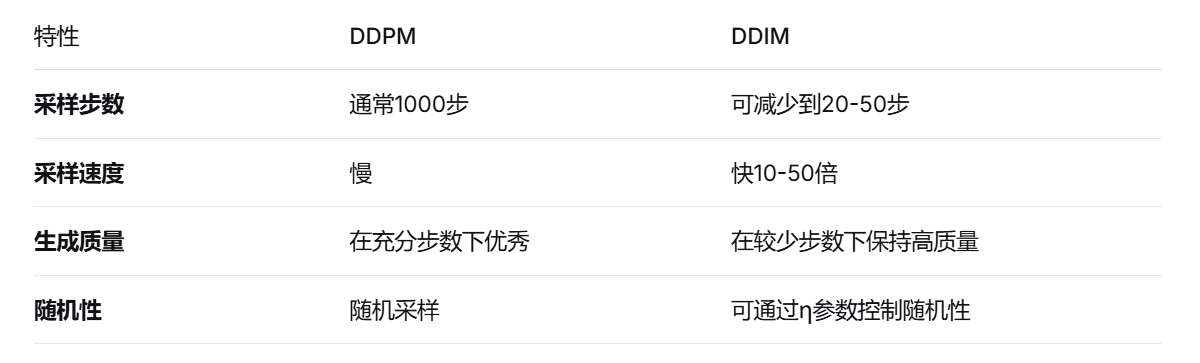
- 采样速度慢:需要1000步或更多步数
- 计算成本高:每个样本都需要多次神经网络前向传播
三、 DDIM:加速采样的革命
- DDIM的核心洞察是:扩散过程的前向过程不一定是马尔科夫的,我们可以设计非马尔科夫的前向过程,从而允许更快的反向采样。
3.1 DDIM的理论基础
class DDIMScheduler:
def __init__(self, num_timesteps=1000, ddim_discretize="uniform", ddim_eta=0.0):
self.num_timesteps = num_timesteps
self.ddim_eta = ddim_eta # 控制随机性的参数
# 使用与DDPM相同的噪声调度
self.betas = torch.linspace(0.0001, 0.02, num_timesteps)
self.alphas = 1. - self.betas
self.alpha_bars = torch.cumprod(self.alphas, dim=0)
def get_ddim_timesteps(self, num_inference_steps):
"""选择用于DDIM采样的时间步子集"""
# 从原始1000步中选择一个子序列
step_ratio = self.num_timesteps // num_inference_steps
timesteps = list(range(0, self.num_timesteps, step_ratio))
return timesteps
3.2 DDIM的采样算法
class DDIM(DDPM):
def __init__(self, network, num_timesteps=1000, ddim_eta=0.0):
super().__init__(network, num_timesteps)
self.ddim_eta = ddim_eta
@torch.no_grad()
def ddim_sample(self, shape, device, num_inference_steps=50):
"""DDIM加速采样"""
# 选择时间步子集
timesteps = self.scheduler.get_ddim_timesteps(num_inference_steps)
# 从纯噪声开始
x = torch.randn(shape, device=device)
for i, t in enumerate(reversed(timesteps)):
# 预测噪声
predicted_noise = self.network(x, torch.tensor([t] * shape[0], device=device))
# DDIM反向步骤
x = self._ddim_step(x, t, predicted_noise, timesteps, i)
return x
def _ddim_step(self, xt, t, predicted_noise, timesteps, step_index):
"""DDIM反向步骤的核心算法"""
# 获取前一个时间步
prev_t = timesteps[len(timesteps) - step_index - 2] if step_index < len(timesteps) - 1 else 0
alpha_bar_t = self.scheduler.alpha_bars[t]
alpha_bar_prev = self.scheduler.alpha_bars[prev_t]
# 预测的x0
predicted_x0 = (xt - torch.sqrt(1 - alpha_bar_t) * predicted_noise) / torch.sqrt(alpha_bar_t)
# 预测的方向
direction = torch.sqrt(1 - alpha_bar_prev - self.ddim_eta**2) * predicted_noise
# 随机噪声(当ddim_eta > 0时添加)
if self.ddim_eta > 0:
noise = torch.randn_like(xt)
else:
noise = torch.zeros_like(xt)
# DDIM更新公式
x_prev = torch.sqrt(alpha_bar_prev) * predicted_x0 + direction + self.ddim_eta * noise
return x_prev
3.3 DDIM的独特优势
# DDIM的特殊功能示例
class AdvancedDDIM(DDIM):
def __init__(self, network, num_timesteps=1000, ddim_eta=0.0):
super().__init__(network, num_timesteps, ddim_eta)
@torch.no_grad()
def interpolate_latent(self, x1, x2, num_steps=10):
"""在潜在空间中进行插值"""
interpolations = []
for alpha in torch.linspace(0, 1, num_steps):
# 线性插值
z = alpha * x1 + (1 - alpha) * x2
# 使用DDIM从插值的潜在变量生成图像
generated = self.ddim_sample_from_latent(z.unsqueeze(0))
interpolations.append(generated)
return torch.cat(interpolations)
@torch.no_grad()
def ddim_sample_from_latent(self, xt, start_t=500, num_steps=20):
"""从中间潜在状态开始采样"""
timesteps = self.scheduler.get_ddim_timesteps(num_steps)
# 找到起始时间步
start_index = min(range(len(timesteps)),
key=lambda i: abs(timesteps[i] - start_t))
x = xt
for i in range(start_index, len(timesteps)):
t = timesteps[i]
prev_t = timesteps[i-1] if i > 0 else 0
predicted_noise = self.network(x, torch.tensor([t] * x.shape[0]))
x = self._ddim_step(x, t, predicted_noise, timesteps, i)
return x
四、 DDPM与DDIM的深度对比分析
4.1 采样过程对比
4.2 数学性质对比
def compare_sampling_process():
"""对比DDPM和DDIM的采样过程"""
# DDPM采样轨迹(随机性较强)
ddpm_trajectory = []
x = initial_noise
for t in reversed(range(1000)):
x = ddpm_reverse_step(x, t)
ddpm_trajectory.append(x)
# DDIM采样轨迹(更确定性的路径)
ddim_trajectory = []
x = initial_noise
timesteps = select_timesteps(50) # 只选50个时间步
for t in reversed(timesteps):
x = ddim_reverse_step(x, t)
ddim_trajectory.append(x)
return ddpm_trajectory, ddim_trajectory
4.3 实际应用场景
DDPM适用场景:
- 对生成质量要求极高的应用
- 计算资源充足,不关心推理速度
- 需要完全随机性的生成过程
DDIM适用场景:
- 需要快速推理的实际应用
- 交互式图像生成工具
- 需要确定性生成或潜在空间操作的研究
五、 实际性能对比
5.1 速度与质量权衡
import time
from evaluate import calculate_fid, calculate_inception_score
def benchmark_models(model, test_dataset, device):
"""基准测试DDPM和DDIM的性能"""
results = {}
# DDPM采样(1000步)
start_time = time.time()
ddpm_samples = model.sample((100, 3, 64, 64), device) # 标准DDPM采样
ddpm_time = time.time() - start_time
# DDIM采样(50步)
start_time = time.time()
ddim_samples = model.ddim_sample((100, 3, 64, 64), device, num_inference_steps=50)
ddim_time = time.time() - start_time
# 评估生成质量
results['ddpm_fid'] = calculate_fid(ddpm_samples, test_dataset)
results['ddim_fid'] = calculate_fid(ddim_samples, test_dataset)
results['ddpm_time'] = ddpm_time
results['ddim_time'] = ddim_time
results['speedup'] = ddpm_time / ddim_time
return results
5.2 不同步数下的性能表现
实验表明:
- DDPM:需要接近1000步才能达到最佳质量
- DDIM:在50-100步时就能达到接近DDPM的质量
- 加速比:DDIM通常比DDPM快10-50倍
六、 进阶应用与变体
6.1 条件生成
class ConditionalDDIM(DDIM):
def __init__(self, network, num_timesteps=1000, ddim_eta=0.0):
super().__init__(network, num_timesteps, ddim_eta)
@torch.no_grad()
def conditional_sample(self, condition, shape, device, num_steps=50):
"""基于条件的采样"""
x = torch.randn(shape, device=device)
timesteps = self.scheduler.get_ddim_timesteps(num_steps)
for i, t in enumerate(reversed(timesteps)):
# 将条件信息与噪声图像一起输入网络
predicted_noise = self.network(x, torch.tensor([t] * shape[0], device=device), condition)
x = self._ddim_step(x, t, predicted_noise, timesteps, i)
return x
6.2 文本到图像生成
- 现代文本到图像模型(如Stable Diffusion)实际上使用的是潜在空间的DDIM:
class LatentDDIM:
def __init__(self, vae, unet, clip_model):
self.vae = vae # 变分自编码器,用于图像与潜在空间的转换
self.unet = unet # 在潜在空间中进行去噪的U-Net
self.clip_model = clip_model # 文本编码器
def text_to_image(self, prompt, num_steps=20):
"""文本到图像生成"""
# 编码文本提示
text_embeddings = self.clip_model.encode_text(prompt)
# 从潜在空间中的噪声开始
latent = torch.randn(1, 4, 64, 64) # 潜在空间维度
# 使用DDIM在潜在空间中采样
for t in reversed(range(num_steps)):
# 预测噪声(结合文本条件)
noise_pred = self.unet(latent, t, text_embeddings)
# DDIM步骤
latent = self.ddim_step(latent, t, noise_pred)
# 解码回像素空间
image = self.vae.decode(latent)
return image
七、 总结与展望
7.1 技术演进路径
DDPM → DDIM → 更高效的变体
- DDPM:奠定了扩散模型的概率理论基础
- DDIM:实现了数量级的速度提升,保持了生成质量
- 后续发展:DPM-Solver、Progressive Distillation等进一步加速技术
7.2 核心启示
- 理论洞察的价值:DDIM的成功表明,对基础理论的深刻理解可以带来突破性的改进
- 实用性驱动创新:DDIM的诞生正是为了解决DDPM采样慢的实际问题
- 灵活性的重要性:DDIM提供的确定性采样和潜在空间操作为后续应用开辟了新道路
7.3 未来方向
- 更快的采样算法:目标是在10步以内达到高质量生成
- 更好的条件控制:更精确地控制生成内容的各个方面
- 多模态扩展:将扩散模型扩展到视频、3D、音频等领域


















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











