



今天给大家分享机器学习中的一个关键概念,超参数调优
超参数调优(Hyperparameter Tuning)是指在机器学习模型训练过程中,通过选择最合适的超参数来提高模型性能的过程。
超参数是指在训练模型之前手动设置的参数,它们不同于模型的权重和偏置,因为它们并不是通过数据自动学习得到的。超参数对模型的性能有着重要影响,因此选择合适的超参数至关重要。
超参数调优的目标
超参数调优的目标是通过寻找一组合适的超参数,使得机器学习模型在训练数据和验证数据上都能取得最好的性能。好的超参数设置能够显著提升模型的表现,而不恰当的超参数则可能导致过拟合或欠拟合,影响模型的泛化能力。
超参数和参数的区别
-
超参数
这些是控制学习过程的参数,不是通过训练数据学习到的,而是在模型训练之前设定的。
超参数包括学习率、正则化系数、树的深度、神经网络的层数和每层神经元的数量等。
-
参数
这些是模型从训练数据中学习到的值。
例如,在回归问题中,参数是线性回归模型的系数;在神经网络中,参数是网络中每一层的权重和偏置。
常见的超参数调优方法
下面是几种常见的超参数调优方法。
1.网格搜索
网格搜索是最常见的超参数调优方法,它通过遍历所有可能的超参数组合来找到最佳配置。
网格搜索会生成一个超参数的网格(即每个超参数的所有可能值的组合),然后遍历所有的超参数组合进行训练和评估,最后选择最好的超参数组合作为最终模型的超参数。
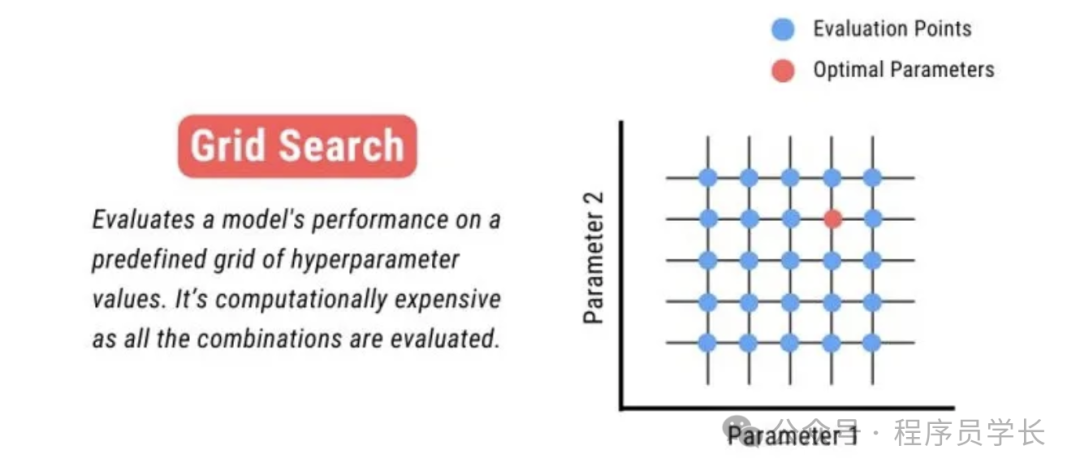
实现步骤
-
设定超参数的候选值。
-
生成超参数网格,遍历这个网格的所有可能组合,训练并评估每一组超参数。
-
选择表现最好的超参数组合。
优点
-
简单易实现,能够确保找到一个在给定网格中的最优超参数组合。
-
可以通过交叉验证来评估每个超参数组合的性能,减少过拟合风险。
缺点
-
计算开销大,尤其是在超参数空间较大的时候,可能会产生大量的训练和评估工作。
-
搜索过程是穷举的,无法跳过不合适的区域。
例子
假设我们有两个超参数:max_depth(决策树的最大深度)和 min_samples_split(每个内部节点的最小样本数)。
我们可以为每个超参数设定一个值域
-
max_depth = [3, 5, 7, 10]
-
min_samples_split = [2, 5, 10]
网格搜索将对每一个可能的组合进行测试(例如(3, 2)、(3, 5)、(5, 2)、(5, 10)等),找到最优的超参数组合。
from sklearn.model_selection import GridSearchCV
from sklearn.tree import DecisionTreeClassifier
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
# 加载数据
data = load_iris()
X = data.data
y = data.target
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=42)
# 定义模型
tree = DecisionTreeClassifier(random_state=42)
# 定义超参数网格
param_grid = {
'max_depth': [3, 5, 10, None],
'min_samples_split': [2, 5, 10]
}
# 设置网格搜索
grid_search = GridSearchCV(tree, param_grid, cv=3, n_jobs=-1)
# 训练模型
grid_search.fit(X_train, y_train)
# 输出最佳参数和得分
print("Best Parameters: ", grid_search.best_params_)
print("Best Cross-validation Score: ", grid_search.best_score_)
# 在测试集上评估性能
test_score = grid_search.score(X_test, y_test)
print("Test Score: ", test_score)
2.随机搜索
随机搜索是一种较为高效的超参数调优方法,与网格搜索不同的是,随机搜索不会遍历所有的超参数组合,而是从超参数空间中随机选择一些组合进行评估。
这意味着它并不保证每一对超参数都被测试,但通过随机选择,能够以较低的计算成本探索更广泛的超参数空间。
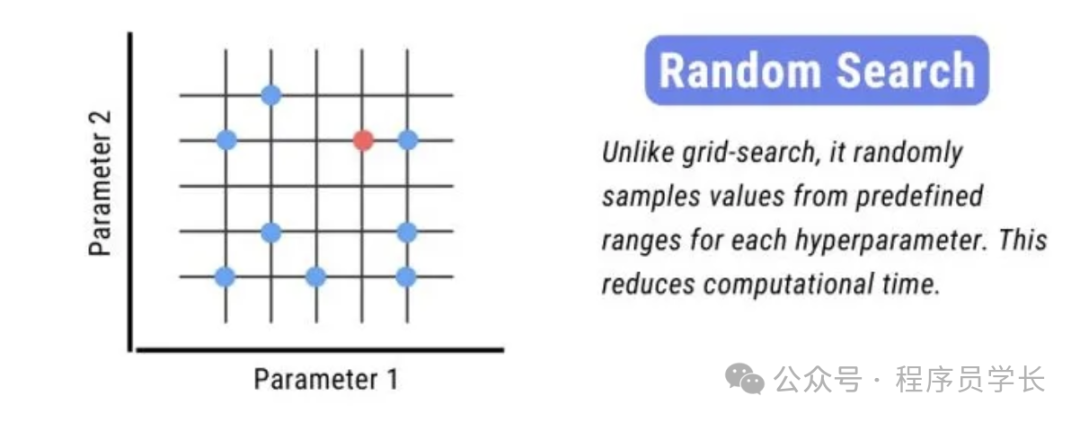
实现步骤
-
定义参数范围:首先定义每个超参数的搜索范围。
-
随机采样:从参数空间中随机选择多个超参数组合。
-
训练和评估:使用这些超参数组合训练模型,并在验证集上评估其性能。
-
选择最佳结果:根据评估结果,选择性能最好的超参数组合。
优点
-
与网格搜索相比,随机搜索的计算开销较小。它并不需要对整个超参数空间进行穷举,通常能以更少的计算量找到相对较好的超参数组合。
-
对于超参数空间很大且连续的情况,随机搜索能比网格搜索更高效地探索空间。
缺点
-
不能保证找到最优解,可能错过最佳的超参数组合。
例子
假设我们仍然在调节 max_depth 和 min_samples_split 两个超参数,但这次我们没有穷举所有的组合,而是随机选择一些组合,例如随机选取 max_depth 在 [3, 5, 7, 10] 之间的某个值和 min_samples_split 在 [2, 5, 10] 之间的某个值进行试验。
from sklearn.model_selection import RandomizedSearchCV
from sklearn.svm import SVC
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
from scipy.stats import uniform
# 加载数据
data = load_iris()
X = data.data
y = data.target
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=42)
# 定义模型
svm = SVC()
# 定义参数空间
param_dist = {
'C': uniform(0.1, 10), # C 的取值范围从 0.1 到 10
'gamma': uniform(0.001, 1) # gamma 的取值范围从 0.001 到 1
}
# 设置随机搜索
random_search = RandomizedSearchCV(svm, param_distributions=param_dist, n_iter=100, cv=3, random_state=42)
# 训练模型
random_search.fit(X_train, y_train)
# 输出最佳参数和得分
print("Best Parameters: ", random_search.best_params_)
print("Best Cross-validation Score: ", random_search.best_score_)
# 在测试集上评估性能
test_score = random_search.score(X_test, y_test)
print("Test Score: ", test_score)
3.贝叶斯优化
贝叶斯优化是一种更为高级和高效的超参数优化方法。它通过利用贝叶斯定理以及高斯过程来进行超参数优化。
贝叶斯优化通过建立一个代理模型(通常是高斯过程模型),在已知的超参数和对应的模型性能之间构建概率关系。然后,通过代理模型预测哪些超参数可能会带来更好的性能,并根据这些预测选择下一个超参数组合进行评估。
通过迭代地评估这些候选超参数,贝叶斯优化能够以更少的计算代价找到最优超参数。
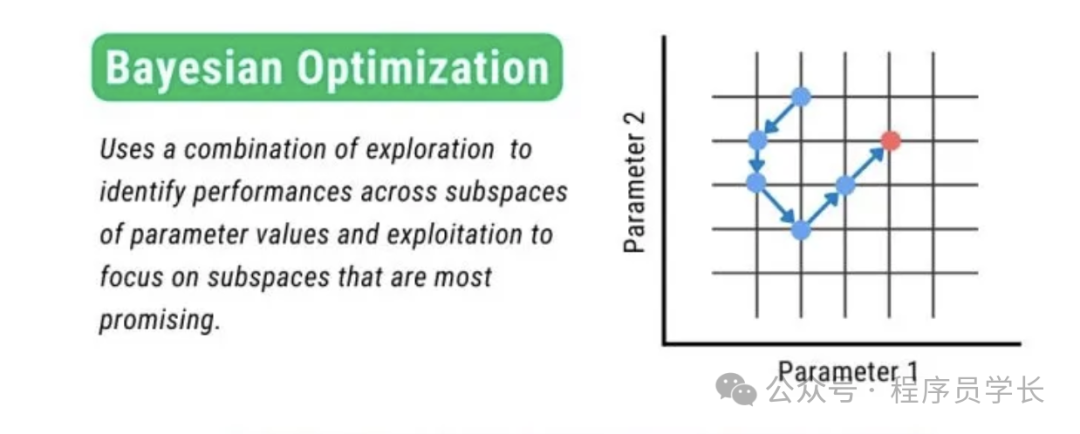
具体步骤如下
-
首先,选择一个初始的超参数组合,并训练模型评估其性能。
-
根据已有的超参数和性能数据,使用贝叶斯优化算法(如高斯过程)构建代理模型。
-
使用该代理模型预测不同超参数的性能,并选择最有可能提高性能的超参数组合进行试验。
-
不断重复这个过程,直到找到最优的超参数组合。
优点
-
贝叶斯优化能够智能地选择下一个超参数组合作为评估对象,相比于网格搜索和随机搜索,它可以减少评估次数,达到更高的效率。
-
适合于计算资源有限的情况,尤其是在超参数空间较大或每次评估成本较高的情况下。
缺点
-
贝叶斯优化的实现较为复杂,需要构建和调整代理模型
-
在某些情况下,贝叶斯优化可能会比随机搜索更慢,因为它需要不断地通过代理模型更新和推理。
例子
假设我们要优化一个神经网络的超参数,如学习率(learning rate)和batch size。贝叶斯优化会首先在这两个超参数的空间中选择一个随机的配置,训练模型并评估其性能,然后根据该评估结果更新一个高斯过程模型,该模型预测哪些超参数组合可能会得到更好的结果。贝叶斯优化的关键是不断地调整超参数的选择,逐步找到最优的组合。
from skopt import BayesSearchCV
from sklearn.svm import SVC
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
# 加载数据
data = load_iris()
X = data.data
y = data.target
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=42)
# 定义模型
svm = SVC()
# 定义贝叶斯优化的参数空间
param_space = {
'C': (0.1, 10.0), # C 的范围
'gamma': (0.001, 1.0) # gamma 的范围
}
# 设置贝叶斯优化
opt = BayesSearchCV(svm, param_space, n_iter=50, cv=3, random_state=42)
# 训练模型
opt.fit(X_train, y_train)
# 输出最佳参数和得分
print("Best Parameters: ", opt.best_params_)
print("Best Cross-validation Score: ", opt.best_score_)
# 在测试集上评估性能
test_score = opt.score(X_test, y_test)
print("Test Score: ", test_score)

















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









