






[不忘初心]
在搭建分布式集群中,为了提供高可用性,Redis还提供了哨兵(sentinel)机制。本文,我们就来看看这部分的内容。本文的翻译内容鉴于博主英语太渣,各位看官如果发现不合理的地方还请及时指出。官方文档:http://redis.io/topics/sentinel
-------------------------------------------------------------------------------------------------------------------------------------
Redis Sentinel 为Redis集群提供了高可用性,在实际的项目中意味着你可以使用Sentinel创建一个部署环境,其能够在不用人工干预的处理某些错误情况。
Redis Sentinel 同样提供其他额外的任务功能,如,监控,通知,和作为客户端配置的提供者。下面是Redis Sentinel从宏观上所拥有的能力。
- 监控(Monitoring):Sentinel会持续不断的检查你的master节点和slave节点是否按照预期的那样正常工作。
- 通知(Notification):当被监控的某个Redis服务器出现问题时,Sentinel可以通过API向系统管理员或者其他应用程序发送通知。
- 自动故障转移(Automatic failover):如果master节点不是按照预期的那样工作,Sentinel能够开始一个故障转移操作,其将一个slave节点提升为 一个master节点, 并让其他slave节点更改对应的master为新的master节点。当客户端尝试连接失效的master服务器时,Sentinel也会通知客户端新的master服务器地址。
- 配置提供者(Configuration provider):Sentinel 作为一个为客户端服务发现的权威来源:客户端连接Sentinel节点目的是为了询问对一个给定服务的当前master节点的地址。如果发生故障转移,Sentinel也会通知新的地址。
Sentinel的分布式
Redis Sentinel是一个分布式系统:
Sentinel本身被设计为能够在一个框架中,运行多个Sentinel进程。这么做的好处如下:
- 当多个Sentinel同意一个事实:一个给定的master节点不再可用时,执行故障检测。这种做法降低了误报的概率。
- Sentinel能够在不是所有Sentinel进程都正常的情况下仍然工作,使得系统拥有鲁棒性。毕竟,如果一个故障转移系统本身就是一个单点故障,这样的话是无意义的事情。
Sentinel的总数目,Redis实例(master节点,slave节点)连接至Sentinel与Redis的客户端,都是带有特定属性的分布式系统。在本文的概念中将会逐步介绍:从所需要的基本信息开始,来理解的Sentinel基本属性,然后再介绍稍微难一点的信息(当然,是可选的)来理解Sentnel是如何工作的。
Quick Start
获取Sentinel
启动Sentinel
redis-sentinel /path/to/sentinel.confredis-server /path/to/sentinel.conf --sentinel在部署Sentinel之前,你需要了解的基本事项:
- 你至少需要3个Sentinel示例来搭建一个具有鲁棒性的系统。
- 这3个Sentinel示例应该被部署在3个独立的机器或者虚拟机中,使其能够以独立的方式陷入失败。举个例子,在不同物理机服务器或者虚拟机执行在不同的可用区域上。
- Sentinel+Redis的分布式系统不能够保证在发生故障期间将接受的写命令全部都持久化下来,因为,Reids使用的是异步复制的方式。但是,在使用缺少安全的方式来部署时,有办法让Redis在特定的部署方式下,只丢失有限时间的写操作。
- 你需要在你的客户端中添加Sentinel支持。流行的客户端库都拥有对Sentinel支持。但也不是所有的都支持。
- 如果你不再部署环境中不断的测试,那就没有高可用的安全的集群。或者,就算在生产环境下这么做了,集群也正常工作。你可能有一个错误的配置,当在这个错误明显的暴露时,可能已经为时过晚。
- Sentinel,Docker,或者其他定时的网络地址转换,或者端口映射都应该被关注到:Docker执行端口的映射,打断Sentinel的自动发现其他Sentinel进程和一个master节点的slave节点列表。在本文之后的内容,将介绍更多这部分内容。
配置Sentinel
Sentinel源码中包含一个sentinel.conf的文件,这个文件是一个带有详细注释的Sentinel配置文件示例。下面是运行一个Sentinel所需的最少配置:
sentinel monitor mymaster 127.0.0.1 6379 2
sentinel down-after-milliseconds mymaster 60000
sentinel failover-timeout mymaster 180000
sentinel parallel-syncs mymaster 1
sentinel monitor resque 192.168.1.3 6380 4
sentinel down-after-milliseconds resque 10000
sentinel failover-timeout resque 180000
sentinel parallel-syncs resque 5你只需要指明一个监控的master对象,对每一个master对象(可能有任何数量的slave)赋予不同的名称。此处,是没有必要指明slave节点的,因为Sentinel有自动发现的功能。Sentinel将会自动更新关于slave节点额外信息的配置(为了在重新启动是仍然保留这些配置信息)。这个配置同样将会在slave提升为master节点,或者是在每次发现一个新的Sentinel时重写。
上面的示例配置,包含两组Redis实例的监控,每一个都包含一个master节点和一组未定义数量的slave节点。其中一组称为mymaster,另一组称为resque。
Sentinel监控语句的参数含义如下:
sentinel monitor <master-group-name> <ip> <port> <quorum>为了清晰起见,我们来一个一个的介绍参数配置项的含义:
第一行配置:为Sentinel指定所监控的master节点对象,配置方法为NAME(mymaster)+IP(127.0.0.1)+PORT(6379)+最少的Sentinel表决数(N=2) ,即将该NAME的master节点判定为失效,至少需要N个Sentinel同意。(反之,只要表决数量少于N,就不会发生自动的故障转移)。前面的几个参数含义是非常明确的,但这个quorum(法定人数)的含义需要进一步解释:- quorum参数是Sentinel所有节点中需要同意一个master节点失去连接的最少数量,这么做是为了标记某个slave失效,并且可能的话,开始一个故障转移过程。
- 但是,quorum参数仅仅用来发现故障。为了实际执行一个故障转移过程,其中一个Sentinel需要被选举出来领导故障转移和在过程中被授权。这仅仅发生在多数Sentinel节点投票过程。
因此,举个例子,假设你拥有5个Sentinel进程,并且对一个给定的master节点的quorum参数配置为2,接下的发生事情如下:
- 如果2个Sentinel节点同时同意这个master节点不可访问,其中一个Sentinel将会尝试开始一个故障转移。
- 如果这里至少3个Sentinel是可访问的,故障转移过程将是被允许的,并且实际的开始运行。
在实际项目中,这意味着在故障发生期间,如果Sentinel节点的多数节点不能够通讯,那么Sentinel绝不会开始故障转移过程。
其他Sentinel功能的参数选项:
其他参数的配置格式如下:
sentinel <option_name> <master_name> <option_value>- down-after-millseconds:指定Sentinel任务服务器已经断线的毫秒数。(断线是指:没有应答PING命令,或者返回一个错误)。
- parallel-syncs:指定了在故障转移期间,最多可以有多少个slave服务器同时对新的master服务器进行同步,这个数字越小,完成故障转移所需的时间越长。但是,如果slave被配置为允许使用过期的数据集,那么你可能不希望所有的slave服务器都在同一时间向新的master服务器发送同步请求。因为尽管复制过程的绝大部分步骤都不会阻塞slave服务器,但slave服务器在载入master服务器的RDB文件时,仍然会造成slave服务器在一段时间内不能处理命令。如果全部的slave服务器同时对新的master服务器进行同步,那么就可能会造成所有从服务器在短时间内全部不可用的情况出现。那么,你可以通过将这个值设置为1,来保证每次只有一个slave服务器处于不能处理命令请求的状态。
本文档剩余的内容将对 Sentinel 系统的其他选项进行介绍, 示例配置文件 sentinel.conf 也对相关的选项进行了完整的注释。
所有的参数选项可以在运行期间使用SENTINEL SET命令进行修改。在下文中我们会详细介绍。
Sentinel部署示例
现在,你已经了解了关于Sentinel的基本信息,你可能想要知道在哪里部署自己的Sentinel进程,多少数量合适等等。本节内容展示了一些部署示例。我们使用了字符画(ASCII art)用图形的格式来为你展示一个配置示例,下面就是不同的符号含义:

我们在box中写出了具体的运行信息:
两个不同的box用直线连接表示它们之间能够进行会话:

发生网络分片时,使用反斜线表示:

同时,请注意下面的名称配置说明:
- Master节点简写为:M1,M2,M3,,,,Mn。
- Slave节点简写为:R1,R2,R3,,,,Rn(R代表副本(replica)
- Sentinel节点简写为:S1,S2,S3,,,,Sn
- 客户端节点简写为:C1,C2,C3,,,,Cn
- 当节点因为Sentinel的功能行为发生角色转变时,我们用中括号将其包围起来,因此,【M1】表示因为Sentinel中断作用产生的新节点。
Example 1:只有2个Sentinel,千万别这么做!

- 在这种配置之下,如果M1节点失效,R1将会被提升为master,因为2个Sentinel对故障能够达成一致意见(因为quorum=1),并且也能够授权一个故障转移,因为多数节点数量为2。因此,显然发生的情况是,表面上其能够正常的进行工作,但是确认下面第二点来看看为什么这种配置是错误的。
- 如果M1停止工作的box中的S1也停止工作。S2节点将不能够授权进行故障转移,于是整个系统将会彻底不可用。
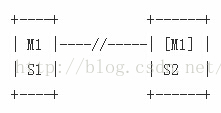
Example 2:用3个box搭建最低配置的集群
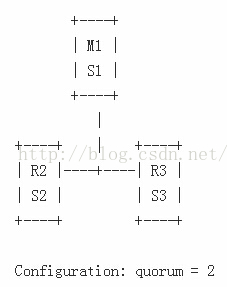
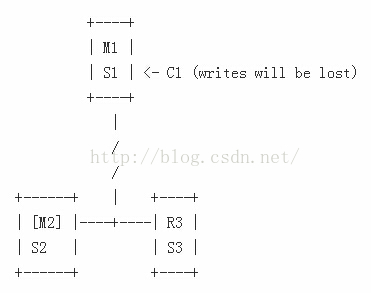
在这种情况下,网络分片将旧的master节点M1隔离开来,因此,Slave节点R2将被提升为master节点。但是,客户端,如C1,在与旧的master节点相同的分片网络中,可能会继续向旧的master写数据。但是,当分片网络重新合并时,这些写入的数据将会永久性的丢失,因为,此时旧的master节点会成为新的master节点的slave节点,并且丢弃它原有的数据集。
这个问题可以使用下面的复制配置项来适当规避,那就是master节点如果不能够与给定数量的slave节点进行通信的话,就停止接受写命令。配置如下:
min-slaves-to-write 1
min-slaves-max-lag 10在上面的例子中,M1使用这样的配置,那么将会在10s之后不可用。当分片网络重新连接后,Sentinel配置将会转向新的节点,客户端,C1节点将会获得新的有效配置,并且成为新的master节点。
但是,这种模式也不是绝对安全的。在这种细化的模式下,如果2个slave节点都失效了,master节点将停止接受写命令,整个集群服务都会失效。(原因是:min-slaves-to-write =1,即至少需要一个slave节点)
Example 3:在客户端Box中加入Sentinel
有时,我们只有两个可用的box,一个归master,一个归slave。这种配置在上面Example 2中是不可行的,但是,我们可以采取下面的策略,将Sentinel与Client部署在一起,如下:
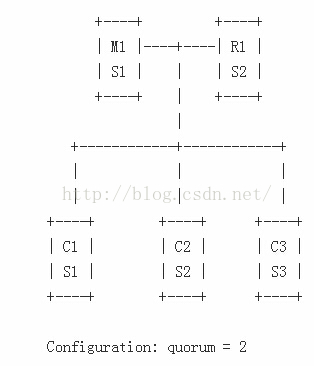
在这种配置下,Sentinel的视角和client是一样的:如果一个master能够被多数client链接,那就是正常的情况。C1,C2,C3,在此是一般意义的客户端,并不是说C1表示一个单独链接到Redis的客户端。其更像是一个应用服务器,一个Redis的app,或者类似的东西。
如果M1与S1所在的box失效了,将会毫无疑问的发生故障转移,但是,很容易发现的是不同的网络分片导致不同的结果。举个例子:如果client与server之间的网络断线,Sentinel将不能够正常运行,因为Redis的master节点与slave节点同时变得不可用。
注意,如果C3与M1处于同一个分片中,(几乎不是由于网络分片导致的,更多是不同的节点布局,或者软件成的故障导致),那么我们就发现了与example 2相似的问题,所不同的是这里我们无法打破对称,因为只有一个slave与master,因此,master节点在于其slave节点失去连接时,不能停止接受操作,否则,master节点在slave发生故障期间将进入永久不可用的状态。
因此,相比于Example 2 这是一个有效的配置,其优点如:Redis的高可用系统运行在相同box中,Redis本身变得更加容易管理,并且有能力将绑定链接的master节点放入包含少数节点的分片网络中。
Example 4:Sentinel处于少于3个client的一侧。
在Example 3的描述的配置:如果在client一侧,没有足够的3个box(如3个web server),是不可用的。在这种情况下,我们需要采取下面的混合配置,如下:
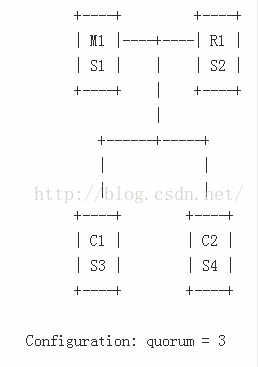
这和上面Example 3的配置类似,但是这里我们可用的4个box中运行了4个Sentinel。如果M1失效,其他3个Sentinel将会执行故障转移。
在这个配置方式下,我们移除C2和S4所处的box,并且设置quorum的值为2.然而,其结果并达不到在Redis Server一侧实现自动切换,并保证应用层的高可用性。
Sentinel,Docker,NAT及其他可能的问题
Docker使用了一种称为端口映射的技术:运行在Docker容器内部的进程可能向外暴露了另一个相比于程序实际使用的不同的端口号。这么做的意义在于:同一时间,在一台server上,使用相同的端口来运行多个容器。
Docker不是唯一使用这种方案的技术,其他的Network Address Translation 也可能配置了端口重映射,并且某些情况下并不适用端口而是使用IP地址。
重新映射端口和使用Sentinel进行地址创建的问题使用如下两种方式:
- Sentinel自动发现其他的Sentinel停止工作,其功能建立在Sentinel主动在连接上监听端口或者IP中受到其他每一个Sentinel发出的hello消息。但是,Sentinel无法了解到地址或者端口的重新映射,因此,相对于内部的端口,Sentinel可能声明了一个错误的信息给其他客户端来链接。
- 类似的方法,对Redis的master节点使用INFO命令列出其slave节点信息:地址信息是有master节点检查TCP远程连接的节点监测到的,但是端口却是slave节点在握手协议中自己声明的,因此,这个端口的值可能向上面例子的原因一样发生错误。
由于Sentinel使用master节点上INFO命令的输出信息来发现slave节点,已经发现的slave节点不可达,Sentinel将没有能力执行故障转移,因为从系统的角度,没有正常工作的slave节点,因此,现在还没有方法使用Sentinel监控一组用Docker部署的master节点和slave节点,除非你指定Docker用一对一的方式映射端口。
对于第一个问题,如果你想运行使用重定向端口的Docker部署的一组Sentinel的实例(或者其他具备端口重映射的NAT配置),你可以使用下面的两条Sentinel配置,目的是强制Sentinel声明一个指定的IP和端口。
sentinel announce-ip <ip>
sentinel announce-port <port>--net=host option for more information). This should create no issues since ports are not remapped in this setup。(还没用过Docker,各位看官先自己学习下吧)。
快速指南
在本文接下来的部分,我们将逐步介绍所有Sentinel API的细节内容,配置项,及其中详细的关键点。但对于那些想尽快运行起来整个系统模型的用户,本节将会展示如何配置和与3个Sentinel实例进行交互的一个基本教程。
这里我们假设实例运行的端口为5000,5001,5002。同时假设我们有一个运行在6379端口上的master节点,对应的slave运行在6380端口上。我们将在整个教程中使用IPV4的本地环路地址127.0.0.1作为IP,假设你是在个人电脑上进行运行一个仿真环境。
我们以由3个Sentinel组成的网络结构为例,给出基本配置内容,如下:
port 5000
sentinel monitor mymaster 127.0.0.1 6379 2
sentinel down-after-milliseconds mymaster 5000
sentinel failover-timeout mymaster 60000
sentinel parallel-syncs mymaster 1关于配置文件中的注意事项如下:
- master节点的名称为mymaster。其指明了一个master节点和对应的slave节点。由于每一个master节点的名称都不相同,因此Sentinel可以同时监控不同的master节点以及slave节点。
- 参数quorum的值配置为2。
- 参数down-after-millseconds的值配置为5000毫秒,意思是如果在5000毫秒之内,master节点如果没有返回ping命令,其就会判定为失效。
一旦你启动了3个Sentinel,将会看到如下的日志输出:
+monitor master mymaster 127.0.0.1 6379 quorum 2Sentinel将在发现失效和故障转移过程中将产生不同的事件并且输出到日志。
向Sentinel询问关于master节点的运行状态
启动Sentinel时最显然应该做的事情就是判断master节点是否正常工作:$ redis-cli -p 5000
127.0.0.1:5000> sentinel master mymaster
1) "name"
2) "mymaster"
3) "ip"
4) "127.0.0.1"
5) "port"
6) "6379"
7) "runid"
8) "953ae6a589449c13ddefaee3538d356d287f509b"
9) "flags"
10) "master"
11) "link-pending-commands"
12) "0"
13) "link-refcount"
14) "1"
15) "last-ping-sent"
16) "0"
17) "last-ok-ping-reply"
18) "735"
19) "last-ping-reply"
20) "735"
21) "down-after-milliseconds"
22) "5000"
23) "info-refresh"
24) "126"
25) "role-reported"
26) "master"
27) "role-reported-time"
28) "532439"
29) "config-epoch"
30) "1"
31) "num-slaves"
32) "1"
33) "num-other-sentinels"
34) "2"
35) "quorum"
36) "2"
37) "failover-timeout"
38) "60000"
39) "parallel-syncs"
40) "1"- 参数num-other-sentinels的值为2,因此我们知道当前的Sentinel已经发现了对当前master节点额外监控的2个Sentinel节点。如果回头检查日志就会发现“+Sentinel”事件在其中。
- 参数flags只有master。如果master下线了,我们就能到在这里看到s-down或者o_down。
- 参数num-slave的值为1,所以Sentinel发现当前的master节点只有1个slave节点。
更多的信息,可以使用下面的两条命令获取:
SENTINEL slaves mymaster
SENTINEL sentinels mymaster第二条将会提供关于其他Sentinel节点的信息。
获取当点master节点的地址
正如我们已经指明的那样,Sentinel也扮演了一个配置提供者的角色给那些想连接至master节点或者slave节点的client。由于可能发生故障转移,重新配置Server之后,client可能不知道当前集群网络中的哪个节点是当前真正的master节点,因此,Sentinel向外暴露了这样的接口供外部使用:
127.0.0.1:5000> SENTINEL get-master-addr-by-name mymaster
1) "127.0.0.1"
2) "6379"测试故障转移
在本节中,我们机器上的Sentinel部署环境需要提前准备好。接下来,结束master进程,并且检查配置是否改变。为了达到这个目的,我们使用如下的命令:
redis-cli -p 6379 DEBUG sleep 30如果你检查Sentinel的日志,就会发现下面的内容:
- 每一个监视该master节点的Sentinel节点都会产生一个“+sdown”事件
- 这个时间之后会转化为“+odown”,这意味着,多个Sentinel已经同意这个master节点失效。
- Sentinel将会选举出一个Sentinel来指挥尝试第一次的故障转移。
- 故障转移开始。
127.0.0.1:5000> SENTINEL get-master-addr-by-name mymaster
1) "127.0.0.1"
2) "6380"Sentinel API
Sentinel提供以充足的API来监控其状态,检查master节点,slave节点的运行状况,订阅接受特殊的通知和在运行时改变Sentinel的配置信息。- PING,返回PONG
- SENTINEL master:列出所有被监控的master节点,以及对应的状态信息。
- SENTINEL master <master name>:列出指定的master节点,以及这些节点对应的状态信息。
- SENTINEL slaves <master name>:列出指定的master节点的所有slave节点,以及这些节点对应的状态信息。
- SENTINEL sentinels<master name>:列出指定的master节点的Sentinel节点,以及这些节点对应的状态信息。
- SENTINEL get-master-addr-by-name<master name>:返回指定name的master节点的IP与端口。如果这个master节点正在进行故障转移,或者针对这个master节点的故障转移操作已经完成,那么该命令将会返回新的master节点的IP与端口。
- SENTINEL reset <pattern>:该命令将会重置所有匹配名称的master节点。pattern这个参数是Glob模式的。重置操作清楚知道当前master节点的状态,(包括正在执行故障转移),并以移除目前已经发现和关联到master节点的所有slave节点和对应的Sentinel。
- SENTINEL failover<master name>:当master节点失效时,在不询问其他Sentinel的条件下,强制开始一次自动的故障转移操作。(但是,发起故障转移的Sentinel会向其他Sentinel发送一份新版本的配置文件,其他Sentinel会跟据该文件进行相应的更新)。
- SENTINEL ckquorum<master name>:检查当前Sentinel的配置能否达到故障转移一个master节点所需要的quorum配置,并且多数节点需要授权进行故障转移。这个命令应该在监控系统中检查Sentienl部署是否正确。
- SENTINEL flushconfig:强制Sentienl将其配置信息写入磁盘,包括当前Sentinel状态信息。通常情况下Sentinel是在其发生变化时才重写配置(状态的子集的上下文持久化到磁盘中,在重启时仍然有效)。但是,该操作有可能会丢失,原因如:错误的操作,磁盘故障,打包升级脚本,或者管理员配置错误等。在这些情况下,为了手动调用此命令来强制将当前信息写入磁盘。即使之前的文件彻底丢失,该命令仍然能够正常运行。
在运行时重新配置Sentinel
从2.8.4版本开始,Sentinel提供了一组API来实现增加,删除,或者改变一个给定的master节点的配置。注意,如果你有多个运行的Sentinel,那你应该让改变的配置信息都作用与其他的Sentinel上,使得Sentinel的功能正常运行。这意味着:在单个节点上改变配置,这些新的配置信息不会自动的传递给其他的Sentinel节点。
下面的命令,可以用来在Sentienl之间更新配置信息:
- SENTINEL MONITOR <name> <ip> <port> <quorum>:该命令指示Sentinel监控一个给定name, ip,port,quorum信息的master节点。 这和在sentinel.conf文件中配置的内容是一样的,唯一的区别是你不能使用主机名称,而是需要提供一个IPV4或者IPV6的地址。
- SENTINEL REMOVE <name>:该命令用来移除给定的master节点:该master节点将不再被监控,并且从Sentinel内部状态中移除,因此,该master节点将不再显示在SENTINEL master命令的返回值中。
- SENTINEL SET <name><option><value>:该命令非常类似于Redis的CONFIG SET命令,被用来改变给定master节点的参数配置信息。给定多组配置信息也够被识别。所有通过sentinel.conf文件配置的参数也可以通过SET命令改变。
下面给出一个SENTINEL SET命令的示例来说明:
SENTINEL SET objects-cache-master down-after-milliseconds 1000SENTINEL SET objects-cache-master quorum 5增加或者移除Sentinel
在部署环境中增加一个Sentinel是非常简单的,因为Sentinel本身已经实现了自动发现的机制。你所需要做的只有为当前活跃的master的节点启动新的Sentinel配置即可。在10s钟之内,新的Sentinel将会感知到其他Sentinel和master节点的slave节点集合。如果你需要增加多个Sentinel,推荐的做法是一个一个的增加,等待上一个Sentinel完全被其他Sentienl接受之后再加入下一个的Sentinel。这种做法能够持续的保证多数节点在分片网络中能够保持连接,防止在添加新的Sentinel过程中发生故障。
这种设计方案可以很容易实现:在没有发生网络分片的情况下,以30秒为间隔,创建每一个Sentinel。
在整个操作过程的最后,可以使用SENTINEL MASTER mastername命令来检查是否所有的Sentinel都已经实现对master节点进行监控。
但是,移除一个Sentinel想对的复杂一点:Sentinel 绝对不会忘记已经连接上的其他Sentinel,即使某个Sentinel在很长一段时间内都是不可达的状态。采取这种策略的原因是:我们不想动态的改变需要授权一个故障转移和创建一个新配置的大多数节点的数量。因此,为了达到这个目的,我们需要采取下面的步骤来实现在没有网络分片的情况下移除一个Sentinel:
- 停止你将要移除的Sentinel进程。
- 发送SENTINEL RESET * 命令给所有其他Sentinel实例(如果你仅仅想重置一个指定的节点,也可以使用指定的名称来替代*)。一个接一个的,两步操作之间至少等待30秒。
- 检查所有Sentinel都同意仍然在活动状态的Sentinel实例,方法为:在每个Sentinel上使用SENTINEL MASTER mastername命令,观察输出。
移除旧的master节点或者不可达的salve节点
Sentinel绝不会忘记一个给定master节点的slave节点,即使它们已经很长时间处于不可达的状态。这种策略是非常有用的,因为Sentinel应该有能力正确的重新配置一个在网络分片或者发生故障之后重新连接的slave节点。除此之外,发生故障转移之后,发生故障的master节点沦为slave节点,这种方式使得只要其再次可用时能够尽可能快的重新对其配置。
但是在某些情况下,你想要通过Sentinel将其监控下的某个slave节点永久性的移除。为了达到这个目的,你需要发送一个SENTINEL RESET命令给所有的Sentinel:所有的Sentienl将会在10秒钟之内刷新slave节点列表,然后只添加当前master节点INFO命令返回结果列表中的正确的slave。
发布/订阅消息
<instance-type> <name> <ip> <port> @ <master-name> <master-ip> <master-port>- +reset-master<instance details>:master服务器已经被重置。
- +slave<instance details>:一个新的slave服务器已经被Sentinel发现并链接。
- +failover-state-reconf-slaves<instance details>:故障转移状态切换到reconf-slaves状态。
- +failover-detected<instance details>:另一个Sentinel还是故障转移,或者其他任何额外的实体被发现(一个slave节点变为master节点)。
- +slave-conf-sent<instance details>:领导(Leader)Sentinel向实例发送了SLAVEOF命令,为其设置新的master服务器。
- +slave-reconf-inprog<instance details>:当前实例正在将自己设置为指定master节点的salve,但是相应的同步过程尚未完成。
- +slave-reconf-done<instance details>:slave节点已经完成对新的master节点的同步。
- -dup-sentinel<instance details>:对于给定master节点进行监控的一个或多个Sentinel已经因为重复出现而被移除(这种情况发生在Sentinel示例重启的时候)。
- +sentitnel<instance details>:对指定master节点的新Sentinel已经被识别并添加。
- +sdown<instance details>:指定的实例现在处于主观下线状态(Subjectively Down)。
- -sdown<instance details>:指定的实例不再处于主观下线状态。
- +odown<instance details>:指定的实例现在处于客观下线状态(Objectively Down)。
- -odown<instance details>:指定的实例不再处于客官下线状态。
- +new-epoch<instance details>:当前的纪元(epoch)已经被更新。
- +try-failover<instance details>:新的故障转移进程正在执行中,等待被大多数的Sentinel选中。
- +elected-leader<instance details>:赢得指定纪元的选举,可以进行故障转移操作了。
- +failover-state-select-slave<instance details>:故障转移操作所处的状态是select-slave状态--Sentinel正在寻找可以升级为master节点的slave节点。
- no-good-slave<instance details>:Sentinel未能找到合适进行升级的slave节点。Sentinel会在一段时间之后再次尝试寻找合适的slave节点来进行升级,或者直接放弃故障转移操作。
- selected-slave<instance details>:Sentinel找到了适合进行升级的slave节点。
- failover-state-send-slaveof-noone<instance details>:Sentinel正在将指定的slave服务器升级为master,等待升级操作完成。
- failover-end-for-timeout<instance details>:故障转移因为超时而中止,不过所有slave节点最终都会开始复制新的master节点。
- failover-end<instance details>:故障转移操作顺利完成,所有slave节点开始复制新的master节点。
- switch-master<master name><oldip><oldport><newip><newport>:配置变更,master节点的IP和地址已经改变。这时绝大多数外部用户都关心的信息。
- +tile:进入tilt模式。
- -tile:退出tile模式。
处理-BUSY状态
slave节点的优先级
- 如果slave的优先级被设置为0,那么其将不能被提升为master节点。
- 该参数的值越小,优先级越高,更容易被Sentinel选中进行故障转移。
Sentinel和Redis授权
- master节点中配置requirepass参数,设置授权密码,确保拒绝接受未授权客户端的访问。
- slave节点中配置masterauth参数,来授权链接到master节点,实现正确的从master节点复制数据。
Sentinel客户端的实现
更多高级的概念
主观下线(SDOWN)和主观下线(ODOWN)失败状态
- 主观下线(Subjectively Down):指的是单个Sentinel实例对于服务器做出的下线判断。
- 客观下线(Objectively Down):指的是多个Sentienl实例(至少达到quorum参数的配置)在对同一个服务器做出SDOWN判断,并且通过SENTINEL is-master-down-by-addr命令相互交流之后,得出的服务器下线判断。
- 返回+PONG
- 返回-LOADING错误
- 返回-MASTERDOWN错误
Sentinel与Slave 自动发现
- 每一个Sentinel会以每2秒一次的频率,通过发布与订阅功能,向被它监视的所有master节点和slave节点的“_sentinel:hello_”频道发送一条消息,信息中包含了Sentinel的IP地址(ip),端口号(port),和运行ID(runid)。
- 每一个Sentienl都订阅了被他监控的所有master节点和salve节点的“_sentinel:hello_”频道,查找之前从未出现过的sentinel。当一个Sentinel发现了一个新的Sentinel时,它会将新的Sentinel添加到一个列表中,这个列表保存了Sentinel已知的,监视同一个master节点的其他所有Sentinel。
- Sentinel发送的hello信息中还包括完整的master节点的当前配置。如果一个Sentinel包含的master服务器配置比另一个Sentinel发送的配置要旧,那么这个Sentinel会立即升级到新配置上。
- 在将一个Sentinel添加到监视master服务器的列表上面之前,Sentinel会先检查列表中是否已经包含了和要添加的Sentinel拥有相同ID或者相同地址(IP,PORT)的Sentinel,如果是的话,Sentinel会先移除列表中已有的那些拥有相同运行ID或者相同地址的Sentinel,然后再添加新Sentinel。
Sentinel在非故障迁移的情况下对实例进行重新配置
- 根据当前的配置,如果一个slave节点被宣告为master节点,那么它会替代原有的master节点,成为新的master,并且成为就的master节点的所有slave对象节点的复制目标。
- 那些链接了错误master节点的slave会被重新配置,使得这些slave节点去复制正确的master节点。
- master节点从失效变为重新可用时,会被重新配置为slave。
- 在网络分片期间,被划分的slave节点一旦重新连接就会被重新配置
本节内容最重要的概念是:Sentinel是一个总是尝试将最新的合法配置传递给其监控的集合中所有对象的系统。
Slave选举与优先级
- 与master节点的失联时间(Disconnection time from the master)
- slave的优先级(Slave priority)
- 复制偏移量(Replication offset processed)
- 运行ID(Run ID)
一个slave节点,被发现与master节点失联超过10于配置的down-after-milliseconds-option时间,加上从准备执行故障转移的Sentinel上主观下线的时间,被视为不适合进行故障转移操作。接着会选择下一个slave节点并判断条件。
在更严格的条件下,一个slave节点的INFO命令输出提示其与master节点失联的时间超过:
(down-after-milliseconds * 10) + milliseconds_since_master_is_in_SDOWN_state会被视为是不可靠的,并且彻底的不考虑使用该节点。
Slave的选取范围只考虑通过上面测试的那些节点,并且按照上面的标准进行排序。具体如下:
- Slave节点按照redis.conf文件中配置的slave-priority参数的值进行排序,值越小,优先级越高。
- 如果优先级相同,那么检查复制过程的复制偏移量,并且接受到数据越多的slave节点优先级越高。
- 如果上面两个比较项都是相同的话,那么就执行一个更加深入的比较:Run ID,按照字典顺序选择Run ID较小的那一个。slave拥有较小的Run ID并不是一个真正的优势,但是,这个对slave的选举过程更加具有决定性的作用,而不是在排序之后随机选择一个。
如果有些实例将被必须被选择的话,Redis的master节点(可能在发生故障转移之后变为slave),slave节点,其都必须配置salve-priority参数项。否则,所有的实例都会使用默认的Run ID来运行。
Redis实例也可以对slave-priority参数配置为一个特殊的值:0,这么做的目的是保证该节点绝不会被Sentinel选中为新的master节点。然而,就算一个slave节点的优先级参数被设置为0,其将还是会被Sentinel重新配置从而使其在发生故障转移之后能够从新的master节点进行备份,唯一的区别就是:该slave本身不会成为master选举的备选对象。
算法及内部原理
Quorum
- Quorum:发现master节点进入错误状态的Sentinel数量,达到该数量时会被认为客观下线。
- 客观下线状态将会触发故障转移操作。
- 一旦故障转移触发,监控该master节点的Sentinel会尝试从多数Sentinel中获得授权并尝试故障转移。(或者如果quorum参数设置的值大于半数Sentinel数量,此时就需要按照quorum条件判断,即两者中取最大数)。
如果设置quorum的值小于部署的Sentinel中的半数,我们可以使Sentinel对故障转移更加敏感,即只要达到quorum,就算只有少数节点同意,不用与master节点商量,就可以触发故障转移。(仅仅是触发)
配置纪元(Configuration epochs)
配置传播
- 配置信息在“_sentinel_:hello”channel上发布/订阅消息。
分片网络下的一致性
- Redis 实例
- Sentinel 实例
- 客户端 实例

- 如果你使用Redis作为缓存,那么可能是分方便的,结果是:Client B仍然有能力向旧的master节点写入数据,即使这些数据最后都会丢失。
- 如果你使用Reids作为存储,这是不好的做法,并且你需要配置系统参数使得一定程度上能够避免这类情况发生。
min-slaves-to-write 1
min-slaves-max-lag 10- 使用同步复制(并且采取适当的一致性算法来运行复制状态的机器)
- 当存在多个不同版本的,可以合并的,相同对象时,使用最终一致性的系统设计
Sentinel 状态的持久化
TILT 模式
- 它不再执行操作。
- 当有实例向这个Sentinel发送SENTINEL is-master-down-by-addr命令时,Sentinel返回负值:因为当前Sentinel所进行的下线判断已经不再准确。














 3265
3265











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









