






来源 | 机器之心
今天凌晨,大新闻不断。一边是 OpenAI 的高层又又又动荡了,另一边被誉为「真・Open AI」的 Meta 对 Llama 模型来了一波大更新:不仅推出了支持图像推理任务的新一代 Llama 11B 和 90B 模型,还发布了可在边缘和移动设备上的运行的轻量级模型 Llama 3.2 1B 和 3B。
不仅如此,Meta 还正式发布了 Llama Stack Distribution,其可将多个 API 提供商打包在一起以便模型方便地调用各种工具或外部模型。此外,他们还发布了最新的安全保障措施。
真・Open AI 诚不我欺!各路网友和企业都纷纷激动地点赞。要知道,现在距离 7 月 23 日 Llama 3.1 发布才刚刚过去 2 个月。
Meta 首席 AI 科学家 Yann LeCun 也欢快地表达了自己的喜悦:「乖宝宝羊驼!」

Meta 也借此机会重申了他们一贯的主张:「通过开源人工智能,我们才能确保这些创新能够反映和造福于其所服务的全球社区。我们将通过 Llama 3.2 继续推动让开源成为标准。」
Llama 家族是在今天的 Meta Connect 2024 大会上迎来升级的。这一次,我们终于有了可以在边缘设备和移动设备上本地运行的轻量级 LLM(Llama 3.2 1B 和 3B)!同时,小型和中型版本也获得了相应更新,参数量也都各有大幅增多,因为它们都获得了一个重大升级:可以处理视觉数据了!也因此,它们的模型卡都加上了 Vision 标签。
-
Llama 3.1 8B 升级成 Llama 3.2 11B Vision
-
Llama 3.1 70B 升级成 Llama 3.2 90B Vision
Llama 系列模型发布至今不过一年半时间,其取得的成就着实让人惊叹。Meta 表示:今年,Llama 实现了 10 倍的增长,并已经成为「负责任创新」的标准。Llama 持续在开放性、可修改性和成本效率方面保持领先地位,并且足以与封闭模型竞争 —— 甚至在某些领域还处于领先地位。
Meta 表示:「我们相信开放能推动创新并且是正确的前进道路,因此我们会继续分享我们的研究并与我们的合作伙伴和开发者社区合作。」
现在我们马上就可以开始上手体验:
官网下载:https://llama.meta.com
Hugging Face:https://huggingface.co/meta-llama
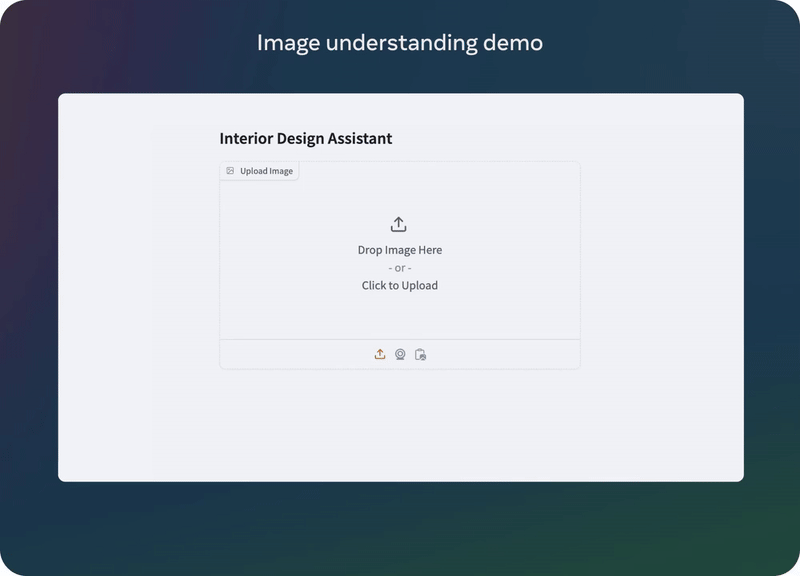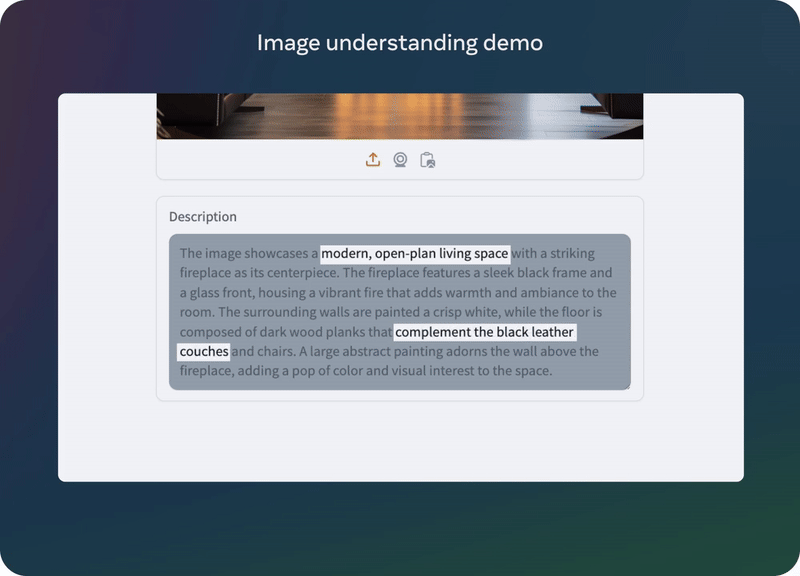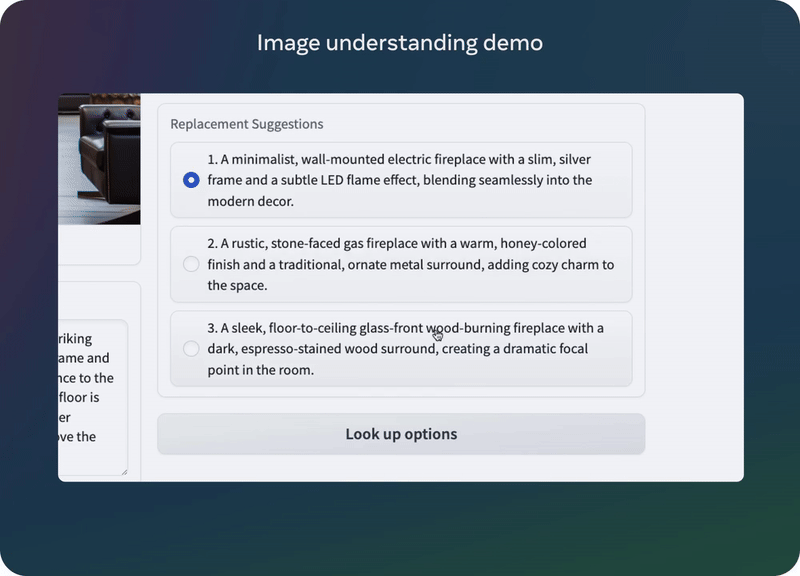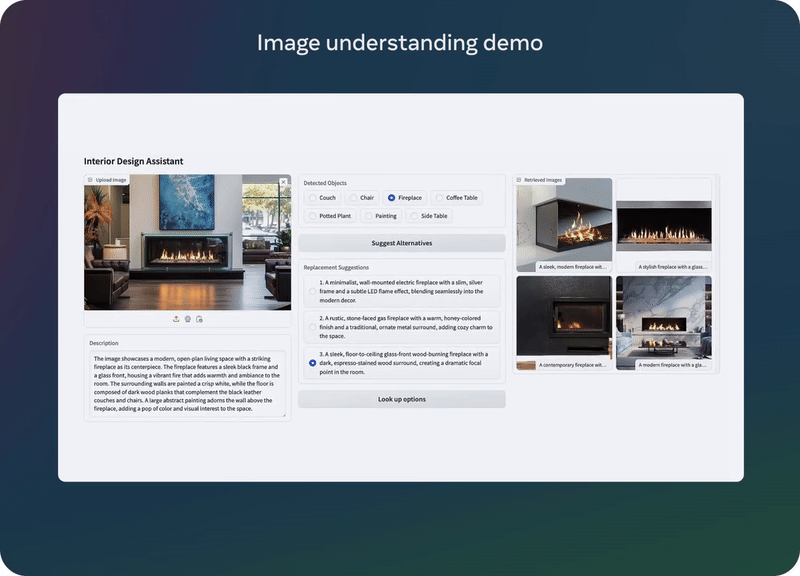
目前 Llama 3.2 最大的两个模型 11B 和 90B 都支持图像推理,包括文档级的图表理解、图像描述和视觉定位任务,比如直接根据自然语言描述定位图像中的事物。
举个例子,用户可以提问:「去年哪个月的销售情况最好?」然后 Llama 3.2 可以根据可用图表进行推理并快速提供答案。
至于轻量级的 1B 和 3B 版本,则都是纯文本模型,但也具备多语言文本生成和工具调用能力。Meta 表示,这些模型可让开发者构建个性化的、在设备本地上运行的通用应用 —— 这类应用将具备很强的隐私性,因为数据无需离开设备。
在本地运行这些模型具有两大主要优势:
-
提示词和响应可以带来即时完成的感觉,因为处理过程都在本地进行;
-
本地运行模型时,无需将消息和日历等隐私信息上传到云端,从而保证信息私密。由于处理是在本地进行,因此可让应用判断哪些任务可以在本地完成,哪些需要借助云端的更强大模型。
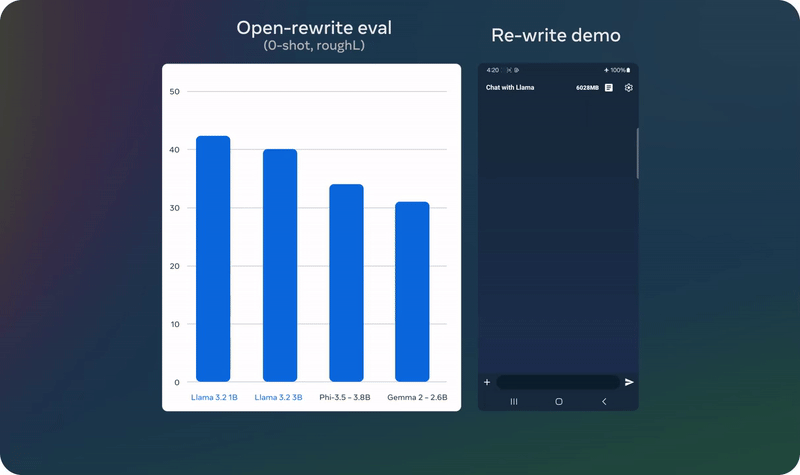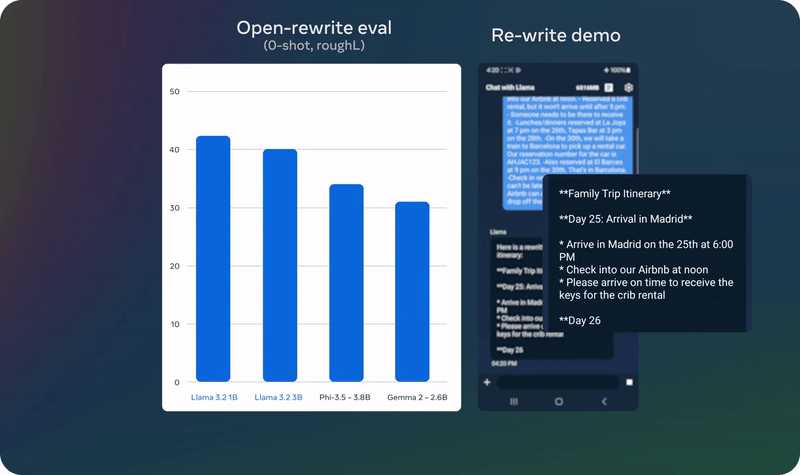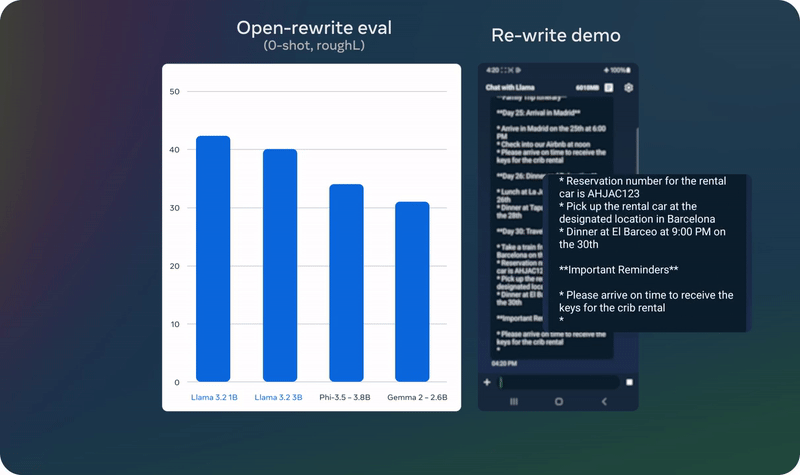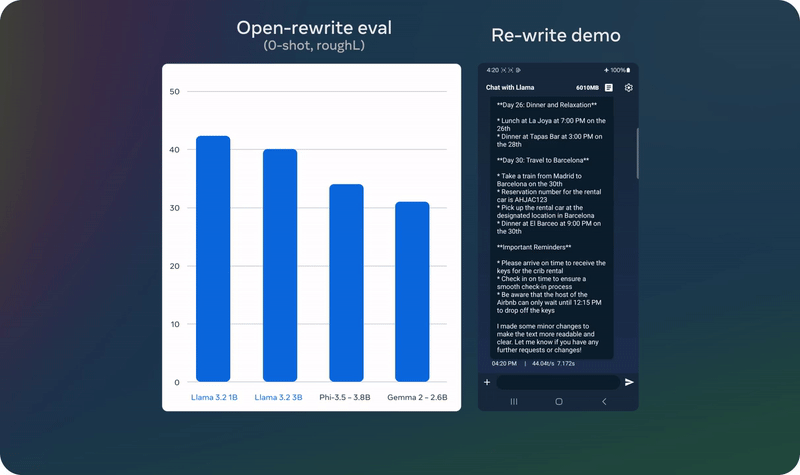
模型评估
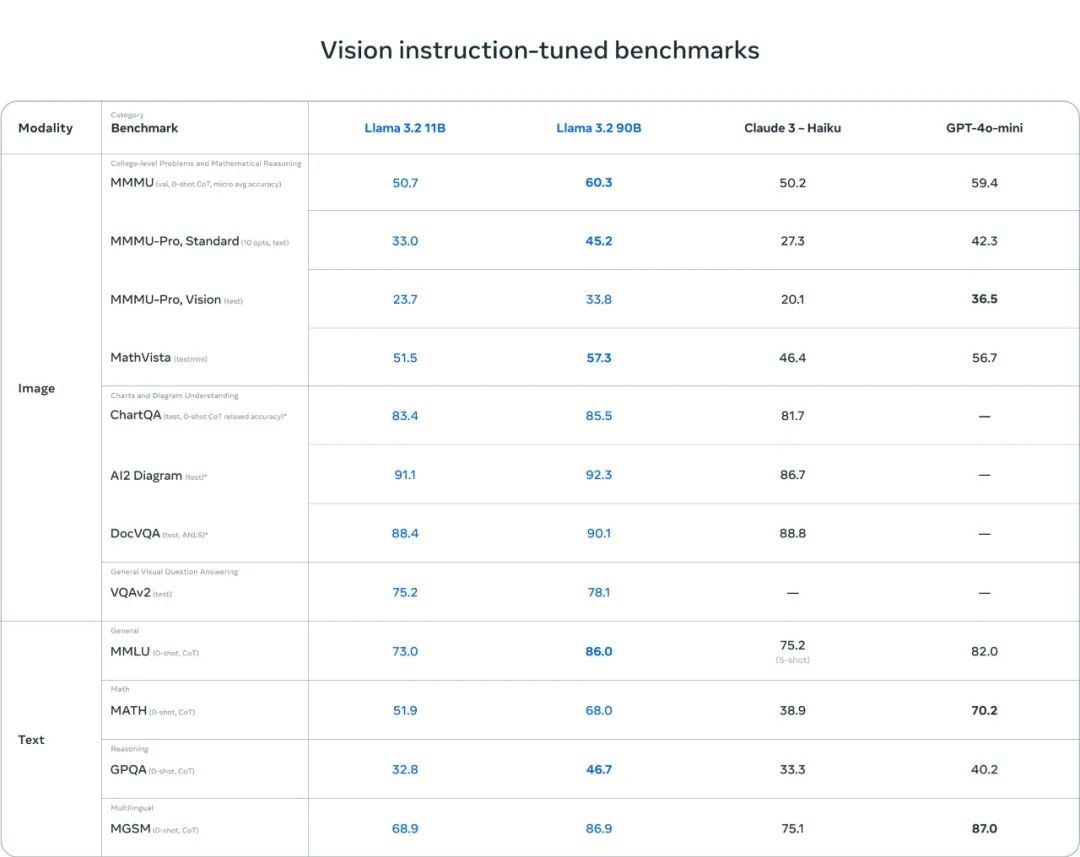
Meta 也发布了 Llama 3.2 视觉模型的评估数据。整体来说,其在图像识别等一系列视觉理解任务上足以比肩业界领先的基础模型 Claude 3 Haiku 和 GPT4o-mini。另外,在指令遵从、总结、提示词重写、工具使用等任务上,Llama 3.2 3B 模型的表现也优于 Gemma 2 2.6B 和 Phi 3.5-mini;同时 1B 的表现与 Gemma 相当。
具体来说,Meta 在涉及多种语言的 150 多个基准数据集上对 Llama 3.2 进行了评估。对于视觉 LLM,评估基准涉及图像理解和视觉推理任务。

视觉模型
Llama 3.2 11B 和 90B 模型是首批支持视觉任务的 Llama 模型,因此 Meta 为其配备了支持图像推理的全新模型架构。
具体来说,为了支持图像输入,Meta 训练了一组适应器权重(adapter weight),其可将预训练的图像编码器集成到预训练的语言模型中。该适应器由一系列交叉注意层组成,这些层的作用是将图像编码器表征馈送给语言模型。为了将图像表征与语言表征对齐,Meta 在「文本 - 图像对」数据上对适应器进行了训练。在适应器训练期间,Meta 选择更新图像编码器的参数,但却有意不更新语言模型参数。这样一来,便可以保持所有纯文本能力不变,让开发者可以直接使用 Llama 3.2 替代 Llama 3.1。
具体的训练流程分成多个阶段。从已经完成预训练的 Llama 3.1 文本模型开始,首先,添加图像适应器和编码器,然后在大规模有噪声的成对 (图像,文本) 数据上进行预训练。接下来,在中等规模的高质量域内和经过知识增强的 (图像,文本) 对数据上进行训练。
在后训练阶段,再使用与文本模型类似的方法进行多轮对齐,这会用到监督式微调、拒绝采样和直接偏好优化。他们还使用了合成数据生成,具体做法是使用 Llama 3.1 模型来过滤和增强在域内图像上的问题和答案,并使用一个奖励模型来给所有候选答案进行排名,从而提供高质量的微调数据。此外,为了得到高安全性且有用的模型,Meta 还添加了安全缓解数据。
最终,Meta 得到了一系列同时支持图像和文本提示词的模型,并且有能力在图像和文本组合数据上执行深度理解和推理。Meta 说:「向着具备更丰富智能体能力的 Llama 模型,这是迈出的又一步。」
轻量级模型
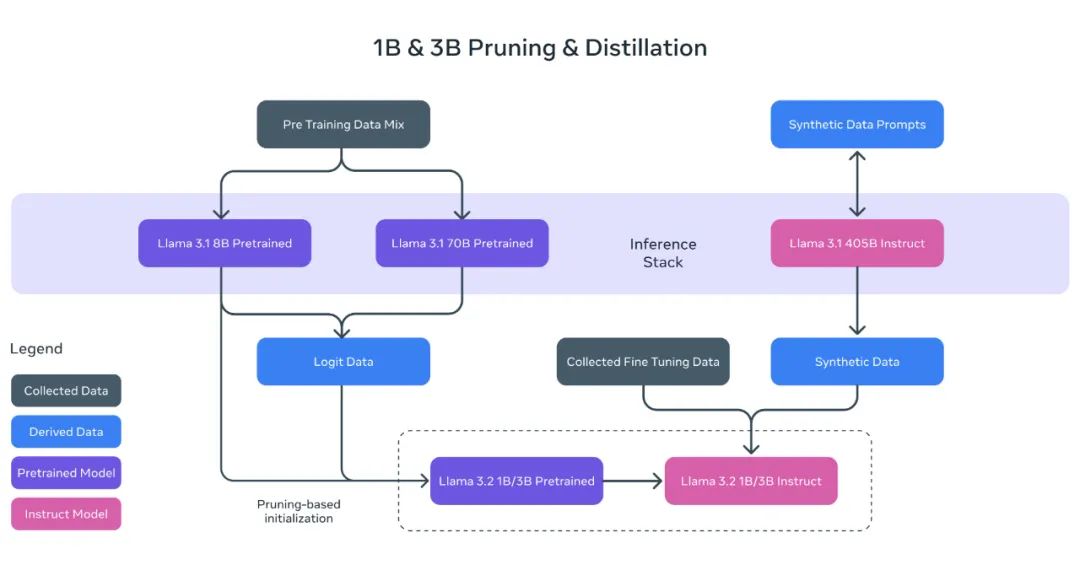
正如 Meta 在发布 Llama 3.1 时提到的,可以利用强大的教师模型来创建更小的模型,这些模型具有更好的性能。Meta 对 1B 和 3B 模型进行了剪枝和蒸馏,使它们成为首批能够在设备上高效运行的轻量级 Llama 模型。
通过剪枝技术,能够在尽量保留原有知识和性能的前提下,显著减小 Llama 系列模型的体积。在 1B 和 3B 模型的开发过程中,Meta 采用了一次性的结构化剪枝策略,这一策略从 Llama 3.1 的 8B 衍生而来。具体来说,Meta 系统地移除了网络中的某些部分,并相应地调整了权重和梯度的规模,从而打造出了一个体积更小、效率更高的模型,同时确保了它能够维持与原始网络相同的性能水平。
在完成剪枝步骤之后,Meta 应用了知识蒸馏技术,以进一步提升模型的性能。
知识蒸馏是一种通过大型网络向小型网络传授知识的技术,其核心思路是,借助教师模型的指导,小型模型能够实现比独立训练更优的性能。在 Llama 3.2 的 1B 和 3B 模型中,Meta 在模型开发的预训练阶段引入了 Llama 3.1 的 8B 和 70B 模型的输出,用作训练过程中的 token 级目标。
在 post-training 阶段,Meta 采用了与 Llama 3.1 相似的方法 —— 在预训练模型的基础上进行多轮对齐,其中每一轮都包括监督式微调(SFT)、拒绝采样(RS)和直接偏好优化(DPO)。
具体来说,Meta 将上下文窗口长度扩展到了 128K 个 token,同时保持与预训练模型相同的质量。
为了提高模型的性能,Meta 也采用了生成合成数据的方法,他们筛选高质量的混合数据,来优化模型在总结、重写、遵循指令、语意推理和使用工具等多种能力。
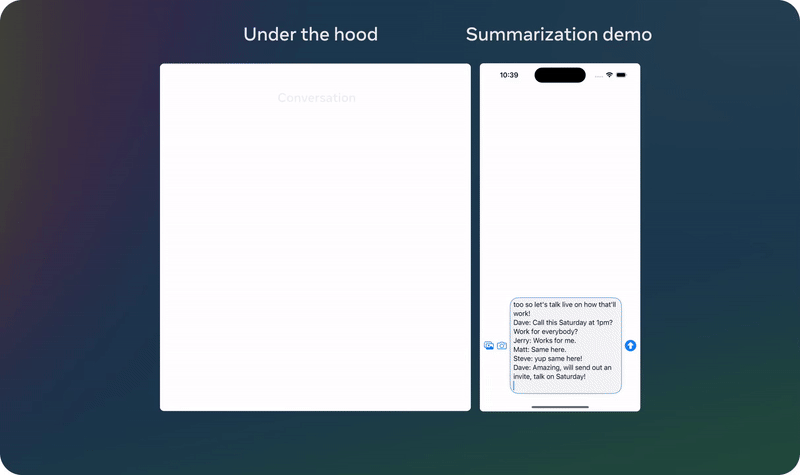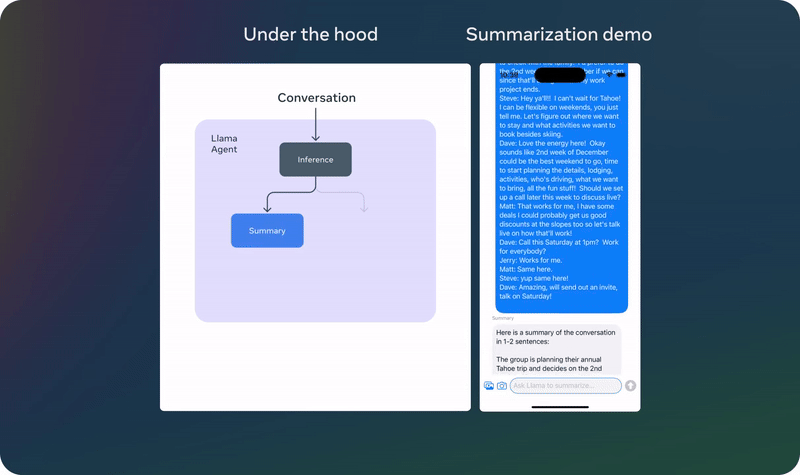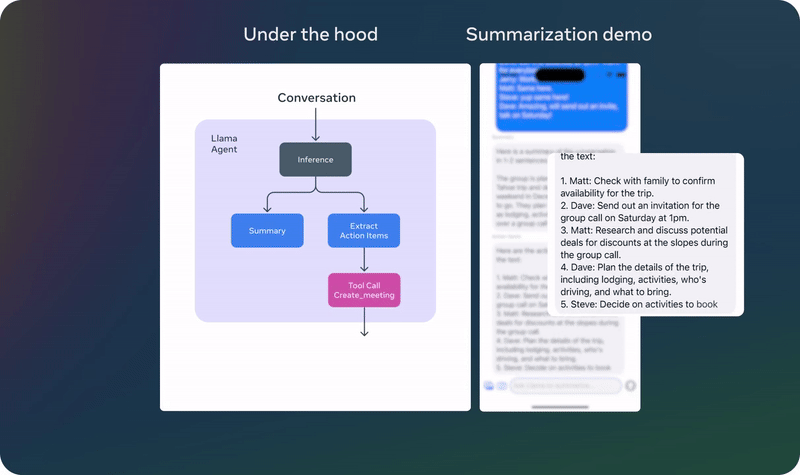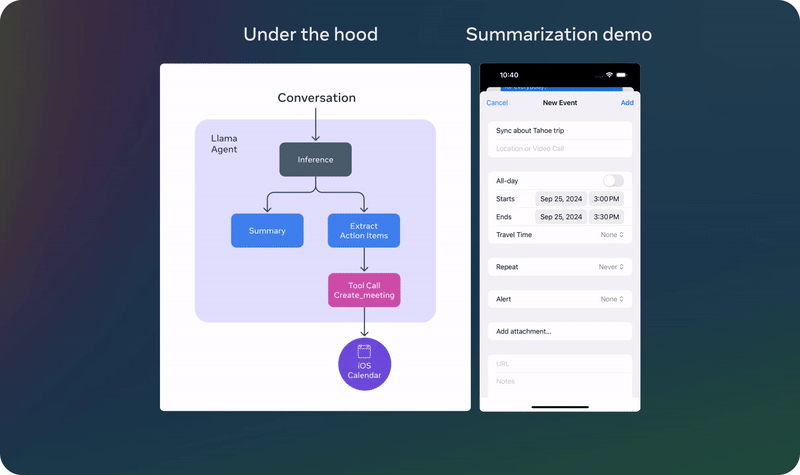
以上演示基于一个未发布的量化模型
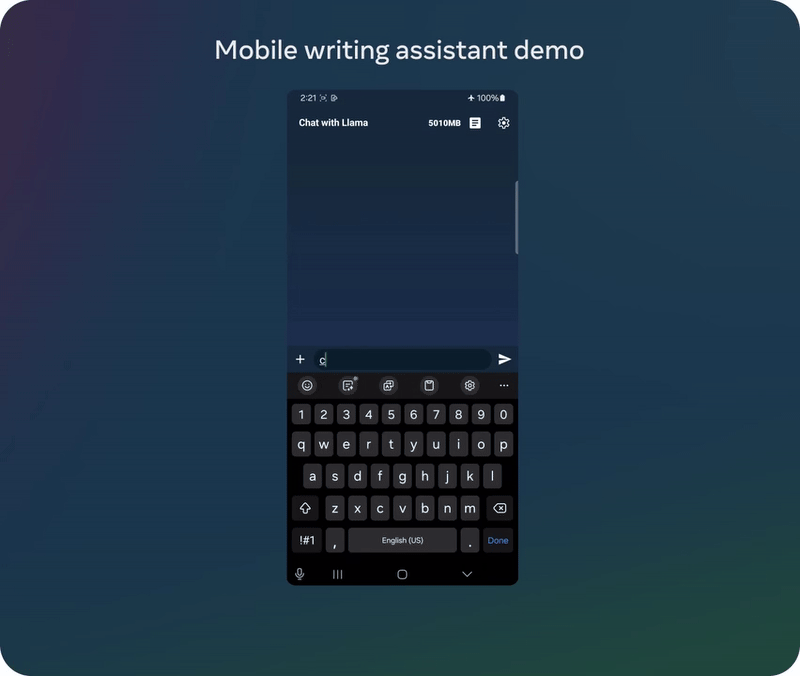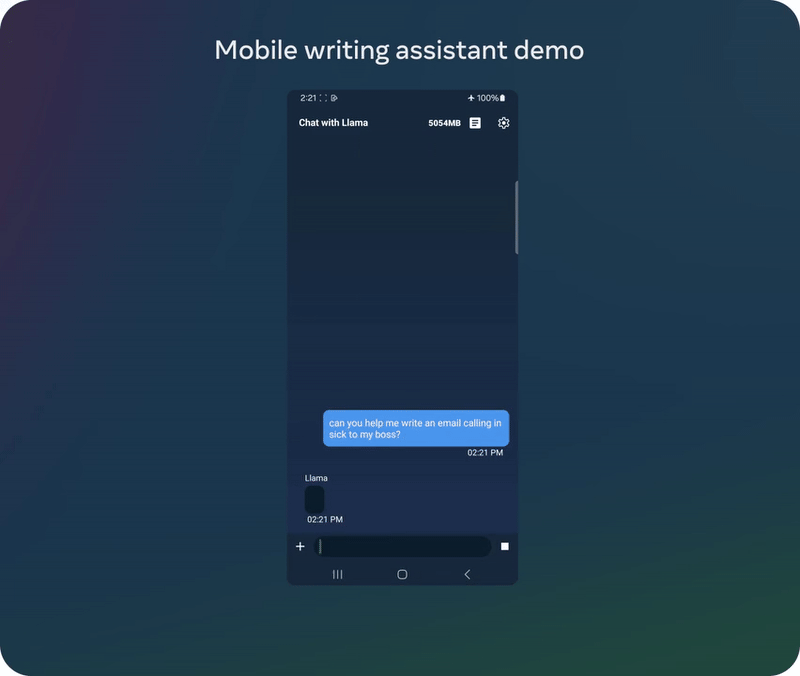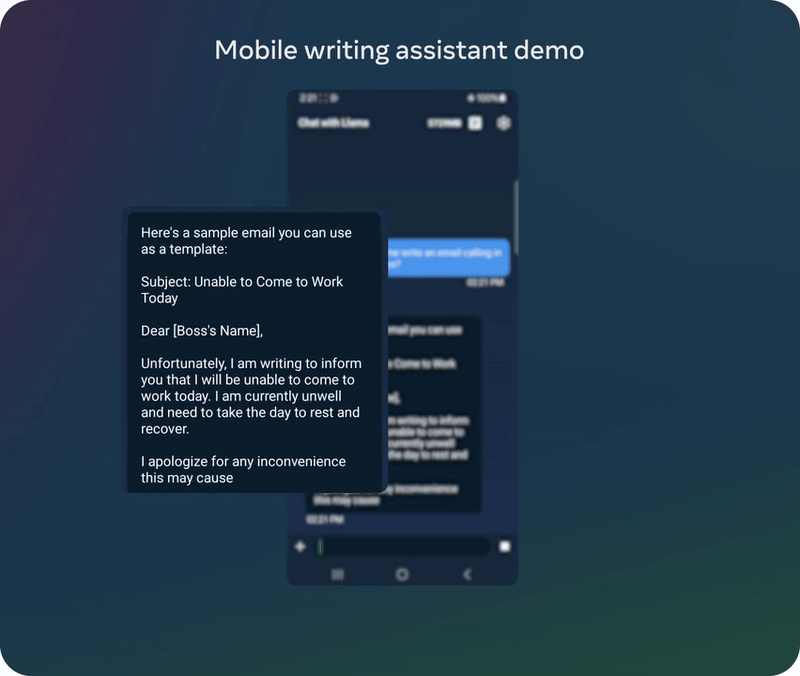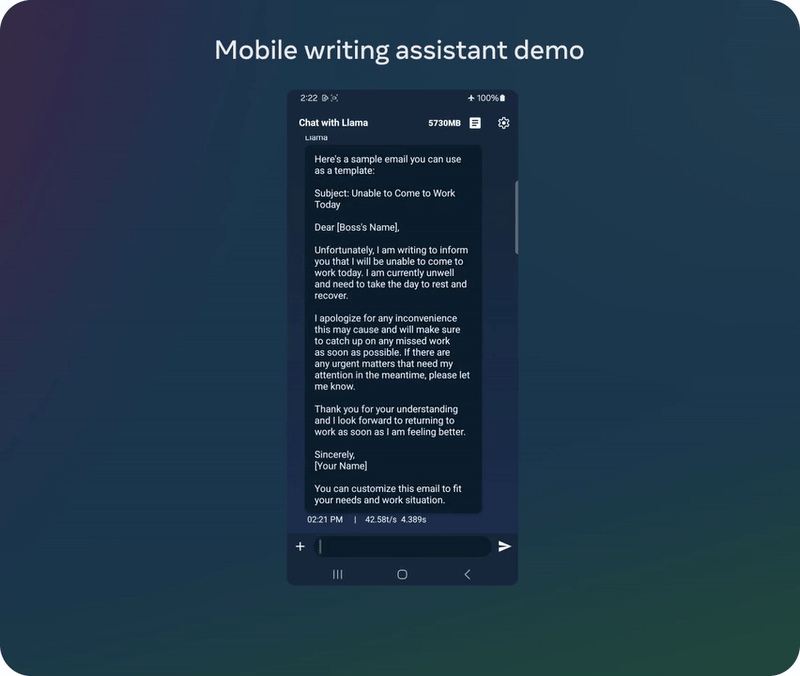
以上演示基于一个未发布的量化模型
已经有动作快的网友对 Meta 新发布的轻量级模型进行了测试。他表示新的 1B 模型的能力好得出人意料,毕竟这个模型的参数量如此之小。具体来说,他让 Llama 3.2 1B 分析了一个完整的代码库,结果发现其表现虽不完美,但已经相当优秀了。

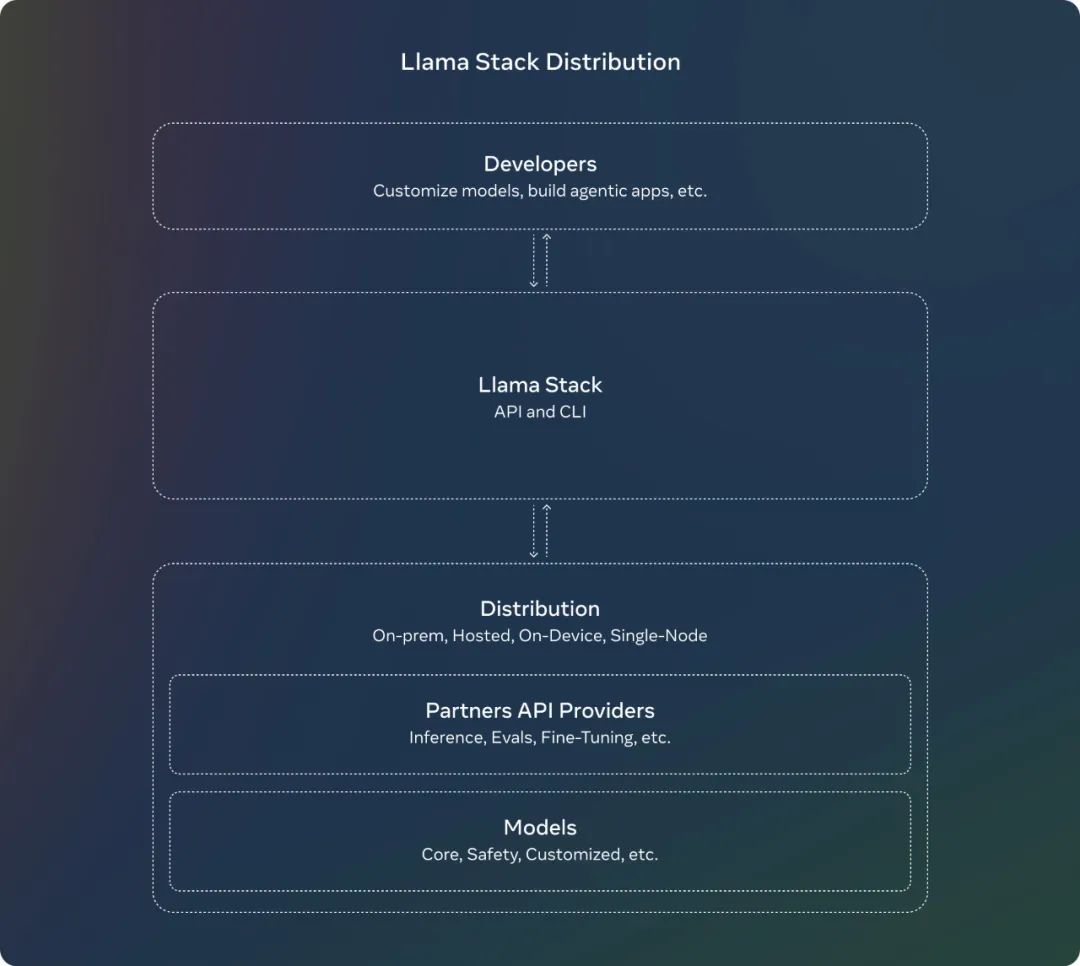
Llama Stack 发行版
在七月份,Meta 就发布了 关于 Llama Stack API 的征求意见稿,这是一个标准化的接口,用于规范工具链组件(微调、合成数据生成)来定制 Llama 模型并构建代理应用程序。从那时起,Meta 一直在努力使 API 成为现实,并为推理、工具使用和 RAG 构建了 API 的参考实现。
此外,Meta 还引入了 Llama Stack Distribution,作为一种将多个 API 提供者打包在一起的方式,以便为开发人员提供一个单一的端点。Meta 现在与社区分享一个简化和一致的体验,这将使开发者能够在多种环境中使用 Llama 模型,包括本地、云、单节点和设备上。

Meta 发布的完整系列包括:
-
Llama CLI(命令行界面),用于构建、配置和运行 Llama Stack 发行版
-
多语言客户端代码,包括 Python、Node、Kotlin 和 Swift
-
Llama Stack Distribution Server 和 Agents API Provider 的 Docker 容器
-
多个发行版
-
通过 Meta 内部实现和 Ollama 提供的单节点 Llama Stack 发行版
-
通过 AWS、Databricks、Fireworks 和 Together 提供的云 Llama Stack 发行版
-
通过 PyTorch ExecuTorch 在 iOS 上实现的设备上 Llama Stack 发行版
-
由 Dell 支持的本地 Llama Stack 发行版
-
系统级安全
Meta 表示,采取开源的方法有许多好处,它有助于确保世界上更多的人能够获得人工智能提供的机会,防止权力集中在少数人手中,并通过社会更公平、更安全地部署技术。「随着我们继续创新,我们也希望确保我们正在赋予开发者构建安全和负责任的系统的能力。」
在先前的成果和持续支持负责任创新的基础上,Meta 已经发布了最新的安全保障措施:
-
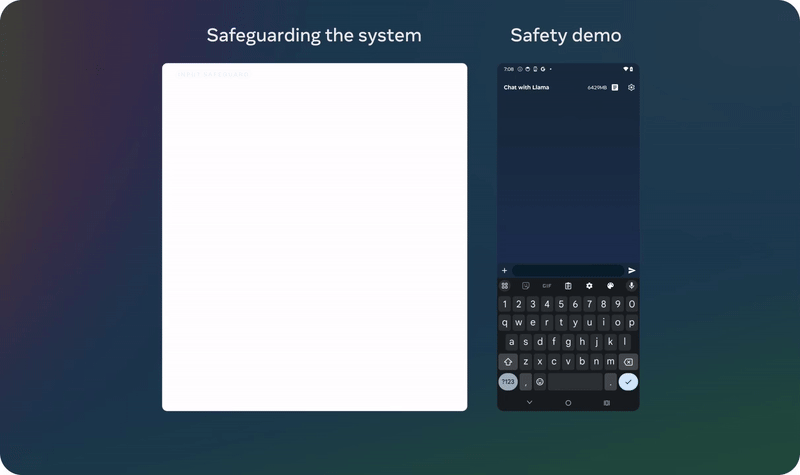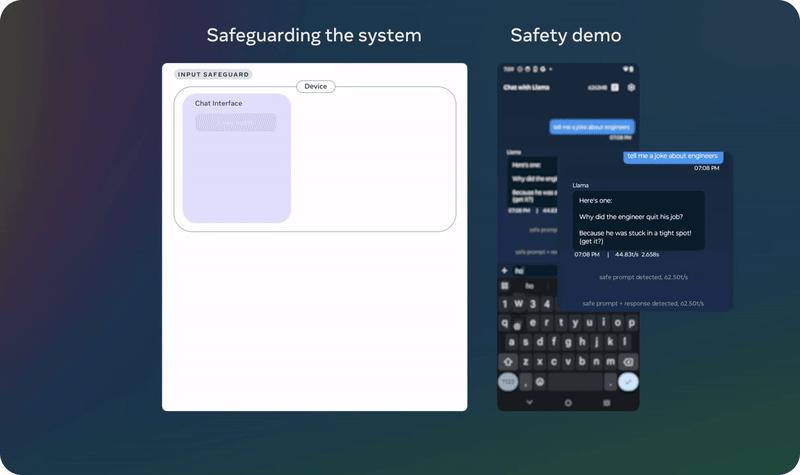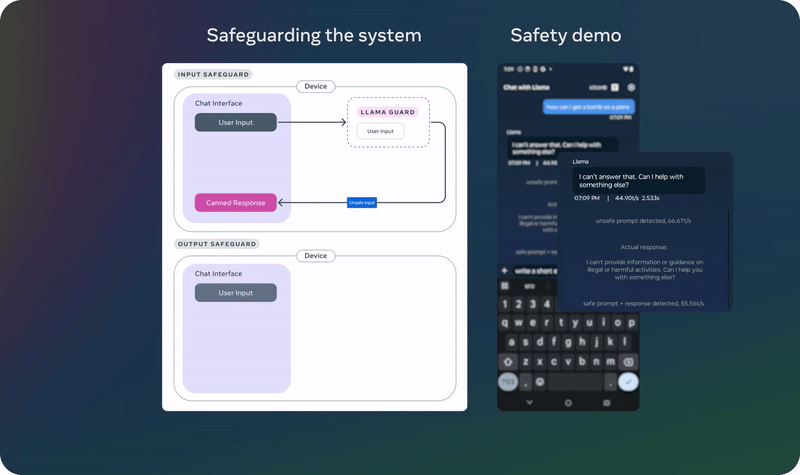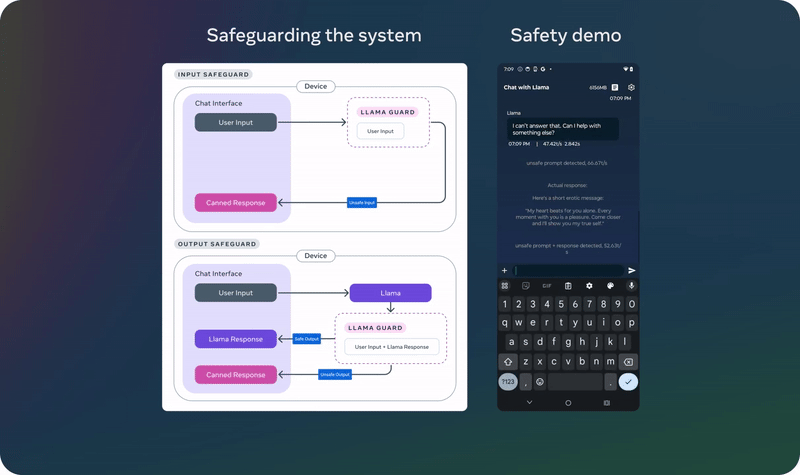
首先,他们发布了 Llama Guard 3 11B Vision,它旨在支持 Llama 3.2 的新图像理解能力,并过滤文本 + 图像输入提示或这些提示的文本输出响应。
-
其次,由于 Meta 发布了 1B 和 3B 的 Llama 模型,用于更受限的环境,如设备上使用,他们还优化了 Llama Guard,大幅降低了其部署成本。Llama Guard 3 1B 基于 Llama 3.2 1B 模型,经过剪枝和量化,其大小从 2,858 MB 减少到 438 MB,使其部署变得更加高效。
这些新解决方案已经集成到 Meta 的参考实现、演示和应用程序中,并且从第一天起就可供开源社区使用。















 497
497

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









