



作者:Ligeng Zhu,Nvidia Research
原文:https://zhuanlan.zhihu.com/p/23282743306
随着 deepseek-v3/r1 的爆火,各大 serving 厂商久旱逢甘霖终于是找到机会来宣传自家服务,在各大 MaaS 上线的如火如荼的时候,有人担忧厂商价格这么便宜(¥16 / Mtoken)真的能赚钱吗,会不会 V3/R1 的火热只是昙花一现?
即便H800 GPU打满并且做出一流优化,H800每百万token的成本是约150元,昇腾是约300元 ... 如果满血版的DeepSeek R1每日输出1000亿token,那么每月的机器成本是4.5亿,亏损4亿!用户越多,亏损越多。
TLDR
如果不优化直接用 TP / PP,那么部署是亏钱的,但如果优化的好,盈利点十分充裕 (>90%)
考虑到 serving throughput = latency * batch-size
H100 / H800 的 throughput 很好预估,它们都是 80G 的卡,显存塞满的时候每一步 decoding 都需要把 GPU memory 挪到 L123 cache,那么预估 latency 是 3.35TB/s / 80G = 42.88 token/s 。在 SGLang 提供的 deployment 方案[1]中,我们可以很容易的 observe 到 32 token/s + 的实际速率。
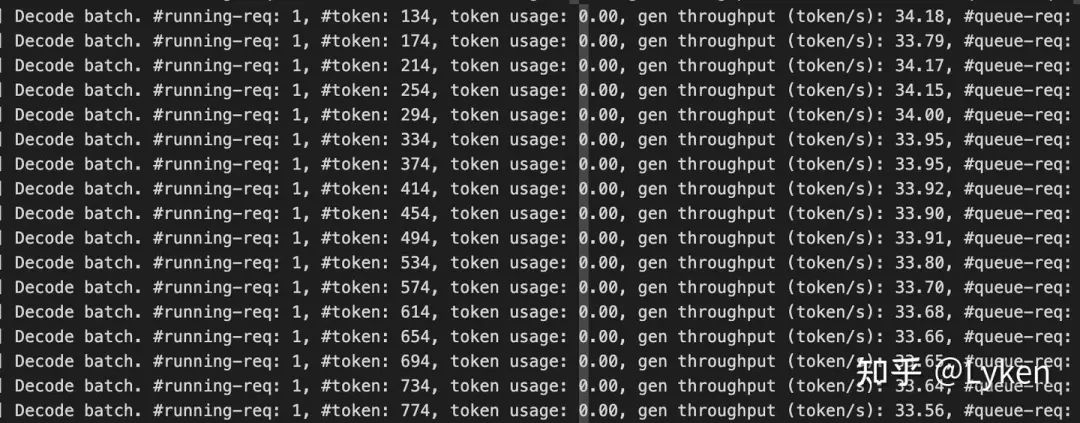
2x8H100 throughput with SGLang
接下来算 batch-size,参照 deepseek-v3 论文 sec2.1.1 [2]的信息,kvcache 需要缓存的是 ,那么每个 token 需要的缓存 kvcache 是
(512 + 64) * 5000 * 61 = 167M(假设每个输出为 5k seqlen)。参考 v3 论文 32 + 320 的配置,model weights 经过 shard 后占用可忽略,主要是每个 node 被 kvcache 占满。因此理论 batch size 可达到 80G / 167M = 479(考虑 overhead 向下取 400)。这样每张卡的理论 throughput 可达到 400 bs × 42.8 token/s = 17K token/s = 61M token/hour。H100 的租金为 $2/hour,因此 offline batched hosting成本可低至 $0.03/M。
考虑实际 throughput 30 token/s,bs 40,即 1.2K token/s = 4M token/hour,比较实际的成本为 $0.5/M tokens = ¥3.7/M tokens,相比官方 API 16元的价格仍有利润空间, 更别说后面还有 MTP / fp4 等优化。
那回到一开始,为什么有一些 source 认为 hosting dsv3 需要高达 ¥150 / M token 的成本呢?因为他们采用的是 SGLang 现有的 out-of-box PP + TP ,并没有上 DeepSeek 介绍的 320 + 32 为 sparse experts 方案。现在 SGLang 在 2x8h800 上部署 single query 是 ~33 token/s,如果 batch-size 开到 12,那么 throughput ~ 400 token/s = 1.4M token/hour,机器的价格是 ,算下来就是22.3 / M tokens ~= ¥150 / M token。而这个价格,离实际上的硬件最优利用率仍有很大距离。
那回到一开始,为什么有一些 source 认为 hosting dsv3 需要高达 ¥150 / M token 的成本呢?
因为他们采用的是 SGLang 现有的 out-of-box PP + TP ,并没有上 DeepSeek 介绍的 320 + 32 为 sparse experts 方案。现在 SGLang 在 2x8h800 上部署 single query 是 ~33 token/s,如果 batch-size 开到 12,那么 throughput ~ 400 token/s = 1.4M token/hour,机器的价格是 ,算下来就是22.3 / M tokens ~= ¥150 / M token。而这个价格,离实际上的硬件最优利用率仍有很大距离。
很多计算公式源于和 Yixin Dong[3] 的讨论,他的 XGrammar 是现在最好 LLM 的形式化输出插件,强烈推荐。
Yixin Dong关于XGrammar的直播分享:
陈天奇团队开源XGrammar:近零开销实现LLM结构化生成
引用链接
[1] SGLang 提供的 deployment 方案: https://github.com/sgl-project/sglang/tree/main/benchmark/deepseek_v3
[2] deepseek-v3 论文 sec2.1.1 : https://arxiv.org/html/2412.19437v1#S2
[3] Yixin Dong: https://github.com/ubospica


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









