








论文链接:https://arxiv.org/pdf/2412.01064
github链接:https://deepbrainai-research.github.io/float/
亮点直击
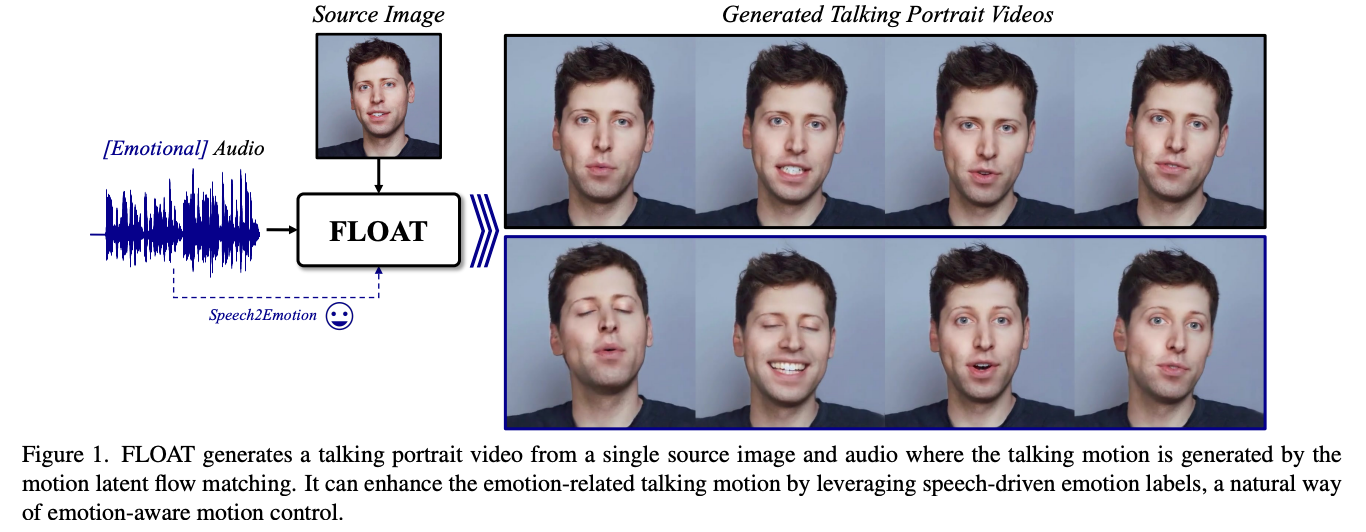
FLOAT,这是一种基于流匹配的音频驱动说话者头像生成模型,利用了学习的运动隐空间,比基于像素的隐空间更高效和有效。
引入了一种简单而有效的基于Transformer的流向量场预测器,用于时间一致的运动隐空间采样,这也使得语音驱动的情感控制成为可能。
大量实验表明,与基于扩散和非扩散的方法相比,FLOAT达到了最先进的性能。
总结速览
解决的问题
-
在基于扩散的生成模型中,迭代采样导致时间一致的视频生成困难。
-
如何实现快速采样以提高生成效率。
-
如何在音频驱动的头像图像动画中自然地融入情感和表现力丰富的动作。
提出的方案
-
将生成建模从基于像素的隐空间转移到学习的运动隐空间,以实现更高效的时间一致运动设计。
-
引入基于Transformer的向量场预测器,具有简单而有效的逐帧条件机制。
应用的技术
-
流匹配生成模型,用于优化运动隐空间的学习。
-
Transformer模型,用于预测流向量场,实现时间一致的运动采样。
-
逐帧条件机制,确保时间一致性并支持语音驱动的情感控制。
达到的效果
-
在视觉质量上,生成的头像更加逼真,表现力更丰富。
-
在运动保真度上,动作更加自然流畅。
-
在效率上,相较于基于扩散和非扩散的方法,FLOAT具有更高的采样速度和生成效率。
-
支持语音驱动的情感增强,能够自然地融入表现力丰富的动作。
方法:音频驱动的说话头像的流程匹配
在下图2中提供了FLOAT的概述。给定源图像 和一个长度为 的驱动音频信号 ,我们的方法生成一个包含 帧的视频,该视频具有与音频同步的说话头像动作,包括语言和非语言动作。我们的方法包括两个阶段。首先,我们预训练一个运动自动编码器,为说话头像提供具有表现力和平滑的运动隐空间。接下来,我们采用流匹配方法,使用基于Transformer的向量场预测器生成一系列运动隐空间变量,并将其解码为说话头像视频。得益于简单而强大的向量场架构,我们还可以将语音驱动的情感作为驱动条件纳入,从而实现情感感知的说话头像生成。
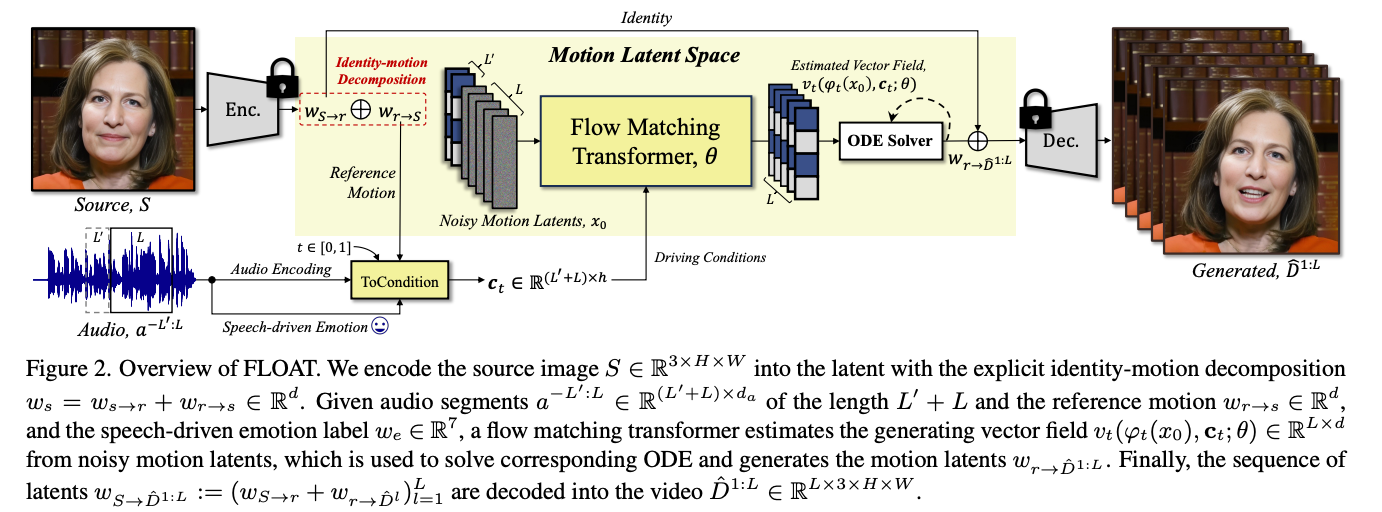
运动隐空间自动编码器
近期的说话头像方法利用了Stable Diffusion (SD) 的VAE,因为其具有丰富的基于像素的语义隐空间。然而,当应用于视频生成任务时,这些方法常常难以生成时间一致的帧 [8, 29, 76, 89, 101]。因此,第一个目标是为逼真的说话头像获得良好的运动隐空间,能够捕捉全局(例如头
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









