






实战2 爬取京东
1.
2.设计架构:
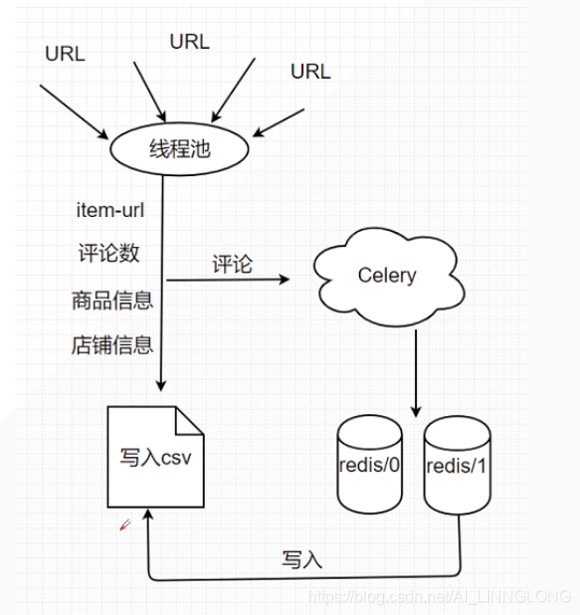
每个商品只有100页,
用线程池处理,不需要分区
对于耗费时间的评论获取使用Celery分布式获取
Celery使用redis中间件和存储
结果写入cs
3.写代码
3.0首先我们打开redis服务:
 3.1headers与模块包
3.1headers与模块包
需要用到的模块
import requests
from bs4 import BeautifulSoup
import re,json,csv
import threadpool
from urllib import parse
headers:
因为京东不需要登录就可以预览,所以headers里面只需要user-agent就够了
我这里是:
headers={'user-agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/69.0.3947.100 Safari/537.36'}
3.2分析url:
https://search.jd.com/Search?keyword=python&enc=utf-8&qrst=1&rt=1&stop=1&vt=2&wq=python&page=1&s=1&click=0
https://search.jd.com/Search?keyword=python&enc=utf-8&qrst=1&rt=1&stop=1&vt=2&wq=python&page=3&s=53&click=0
https://search.jd.com/Search?keyword=python&enc=utf-8&qrst=1&rt=1&stop=1&vt=2&wq=python&page=5&s=103&click=0
https://search.jd.com/Search?keyword=python&enc=utf-8&qrst=1&rt=1&stop=1&vt=2&wq=python&page=199&s=5916&click=0
Keyword和wq是关键词,Page是以2为间隔的页码,其余的删除后依然可以正常访问
(可以在fiddler里面get获取主要的关键词)
我们只需要爬取100页信息,再加上详情页并不需要分区,直接上多线程
代码:
if __name__ == '__main__':
urls=[]
for i in range(1,200,2):
url="https://search.jd.com/Search?keyword={}&wq={}&page={}".format(KEYWORD,KEYWORD,i)
urls.append(([url,],None))
pool=threadpool.ThreadPool(50)
reque=threadpool.makeRequests(get_index,urls)
for i in reque:
pool.putRequest(r)
pool.wait()
3.3获取商品链接
每个书:
书的链接:
输出:
/
/item.jd.com/12078837472.html
//item.jd.com/29767362475.html
//item.jd.com/59877437638.html
//item.jd.com/32916598812.html
//item.jd.com/49907844022.html
//item.jd.com/45701719377.html
//item.jd.com/52136708338.html
//item.jd.com/55505503148.html
//item.jd.com/52818072234.html
//item.jd.com/65371112520.html
//item.jd.com/49842088229.html
//item.jd.com/31293994256.html
//item.jd.com/49995223799.html
//item.jd.com/59507188164.html
//item.jd.com/54792602555.html
//item.jd.com/44159974823.html
//item.jd.com/50861274258.html
//item.jd.com/63838250016.html
//item.jd.com/53723058126.html
//item.jd.com/54141656861.html
//item.jd.com/29943892195.html
//item.jd.com/58400526276.html
//item.jd.com/30897463332.html
//item.jd.com/59587466797.html
//item.jd.com/46160387544.html
//item.jd.com/59796641853.html
//item.jd.com/11896401.html
//item.jd.com/48234134921.html
//item.jd.com/40347535627.html
//item.jd.com/10599758.html
这是不规范的URL
我们需要使用parse包转化为合适的URL(利用urljoin方法加上前面的主站即可)
完善代码如下:
import requests
from bs4 import BeautifulSoup
import re,json,csv
import threadpool
from urllib import parse
KEYWORD="python"
headers={'user-agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/69.0.3947.100 Safari/537.36'}
base="https://item.jd.com/"
#一开始的请求页面
def get_index(url):
session=requests.session()
session.headers=headers
html=session.get(url)
soup=BeautifulSoup(html.text,"lxml")
items=soup.select('li.gl-item')
for item in items:
inner_url=item.select('.gl-i-wrap div.p-img a')[0].get('href')
new_inner_url=parse.urljoin(base,inner_url)
#print(inner_url)
if __name__ == '__main__':
urls=[]
for i in range(1,200,2):
url="https://search.jd.com/Search?keyword={}&wq={}&page={}".format(KEYWORD,KEYWORD,i)
urls.append(([url,],None))
pool=threadpool.ThreadPool(50)
reque=threadpool.makeRequests(get_index,urls)
for i in reque:
pool.putRequest(i)
pool.wait()
3.3获取评论数
def get_ index lists (htm1) :
html. encoding=' utf8'
soup=BeautifulSoup (html. text,' 1xm1' )
lis=soup. find_ al1( li' z,attrs={' 'class" : g1-item })
for li in lis:
number=li. find(' div zattrs={" class : p-commit" }). strong
print (number)
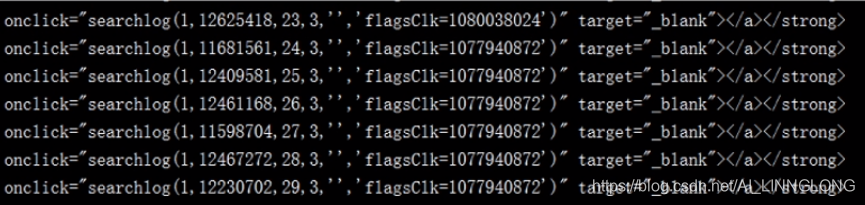
可以看到我们的输出,明显是JavaScript的语法
这是无法在页面上捕捉的从采集到的信息
使用JS渲染,我们需要到网络里寻找接口
查找接口:
我们发现存在一个productComments接口
里边存在json格式的数据

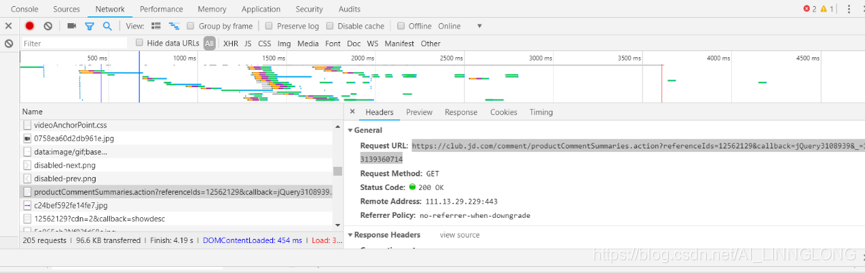
https://club.jd.com/comment/productCommentSummaries.action?referenceIds=12562129&callback=jQuery3108939&_=1583139360714
看这里的referenceIds=12562129,
我们发现只要在URL中传递一个referenceld字段就可以
找到对应的评论数
而这个ID正是每-一个商品URL里边自带的ID
我们可以写一个函数利用正则表达式获取这个id:
def get_id(url):
id=re.compile('\d+')
res=id.findall(url)
return res[0]
单独写成函数是为了方便日后更改
我们在测试test.py解析这个网址页面,:
import requests
url='https://club.jd.com/comment/productCommentSummaries.action?referenceIds=12562129&callback=jQuery3108939&_=1583139360714'
html=requests.get(url)
print(html.text)
输出:
jQuery3108939({"CommentsCount":[{"SkuId":12562129,"ProductId":12562129,"ShowCount":579,"ShowCountStr":"500+","CommentCountStr":"2.3万+","CommentCount":23806,"AverageScore":5,"DefaultGoodCountStr":"1.9万+","DefaultGoodCount":19164,"GoodCountStr":"9700+","GoodCount":9747,"AfterCount":45,"OneYear":0,"AfterCountStr":"40+","VideoCount":27,"VideoCountStr":"20+","GoodRate":0.99,"GoodRateShow":99,"GoodRateStyle":148,"GeneralCountStr":"30+","GeneralCount":35,"GeneralRate":0.0030,"GeneralRateShow":0,"GeneralRateStyle":0,"PoorCountStr":"30+","PoorCount":38,"SensitiveBook":0,"PoorRate":0.0070,"PoorRateShow":1,"PoorRateStyle":2}]});
可以看到,这虽然是个json,但是却多了我们不需要的json内容格式(加粗部分),所以如果你用json方法是解析不了的,会报错,这就需要我们利用一些手段去除多余的部分,你可以利用正则表达式,也可利用下面的方法:
我们需要截取json,二次解析
import requests
import json
url='https://club.jd.com/comment/productCommentSummaries.action?referenceIds=12562129&callback=jQuery3108939&_=1583139360714'
html=requests.get(url)
#print(html.text)
#print(html.json())
comment=html.text
start=comment.find('{"CommentsCount"')
end=comment.find('"PoorRateStyle":2}]}')+len('"PoorRateStyle":2}]}')
Content = json.loads(comment[start:end])['CommentsCount']
print(Content)
print(Content[0]["ShowCountStr"])
把不属于JSON的部分截断选取json括号里边的内容
确定start和end后截取使用json库进行解析
输出:
[{'SkuId': 12562129, 'ProductId': 12562129, 'ShowCount': 579, 'ShowCountStr': '500+', 'CommentCountStr': '2.3万+', 'CommentCount': 23806, 'AverageScore': 5, 'DefaultGoodCountStr': '1.9万+', 'DefaultGoodCount': 19164, 'GoodCountStr': '9700+', 'GoodCount': 9747, 'AfterCount': 45, 'OneYear': 0, 'AfterCountStr': '40+', 'VideoCount': 27, 'VideoCountStr': '20+', 'GoodRate': 0.99, 'GoodRateShow': 99, 'GoodRateStyle': 148, 'GeneralCountStr': '30+', 'GeneralCount': 35, 'GeneralRate': 0.003, 'GeneralRateShow': 0, 'GeneralRateStyle': 0, 'PoorCountStr': '30+', 'PoorCount': 38, 'SensitiveBook': 0, 'PoorRate': 0.007, 'PoorRateShow': 1, 'PoorRateStyle': 2}]
500+
在main.py内定义函数以获取评论数
def get_comm_num(url):
item_id=get_id(url)
comm_url="https://club.jd.com/comment/productCommentSummaries.action?referenceIds={}&callback=jQuery3108939&_=1583139360714".format(item_id)
comment=session.get(comm_url,headers=headers).text
start=comment.find('{"CommentsCount"')
end=comment.find('"PoorRateStyle":2}]}')+len('"PoorRateStyle":2}]}')
try:
content = json.loads(comment[start:end])['CommentsCount']
except:
return 0
comm_num=content[0]["ShowCountStr"]
return comm_num
3.4获取页面信息
包括价格,id,评分

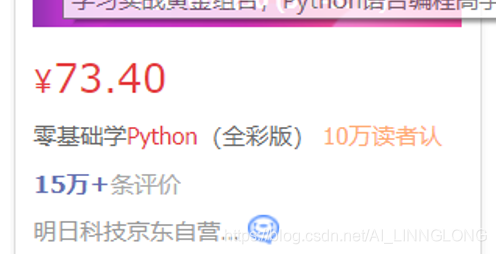
这些比较简单就不再一一赘述,当然注意第一个图,整好符合python的字典格式,可以利用字典存储。
3.5分布式获取评论
评论也使用JS渲染,无法直接获取,我们需要寻找接口
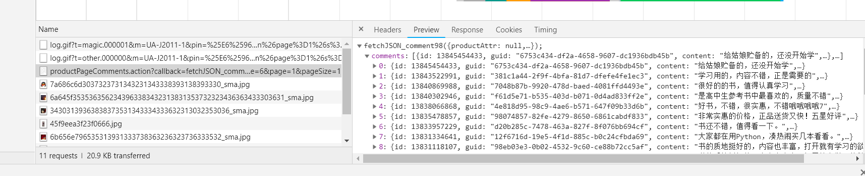
JSON不规范依然需要我们二次解析
重复上一次的步骤截取规范的json。用josn包解析
但如果你访问这个页面,服务器返回空,
这时候是服务器采用了防盗链的技术我们加refer就好了
再有需要注意的是,京东评论最多有99页,并且每个物品的评价数量不固定,也就是说我们没有一个固定的页数,这就是很厉害的反爬机制,我们可以利用comm-num/10来定义这个页数。
我们当然可以直接写一个函数来完成这个操作,但是我们这里评论的获取非常耗费时间
有的商品评论长达99页,至少访问99次接口才能返回数据
因此这里使用Celery分布式,把耗费时间的操作交给celery,
参考:https://www.cnblogs.com/cwp-bg/p/8759638.html
我们只需要不断提交任务即可
编写getComm.py:
from celery import Celery
import requests,re,json
app=Celery("tasks",
backend="redis://127.0.0.1:6379/2",
broker="redis://127.0.0.1:6379/1")
headers={"User-Agent": "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/69.0.3947.100 Safari/537.36"}
def get_id(url):
id=re.compile('\d+')
res=id.findall(url)
return res[0]
@app.task
def get_comm(url,comm_num):
good_comments=""
item_id = get_id(url)
pages=comm_num//10
if pages>99:
pages=99
for page in range(0,pages):
comment_url='https://club.jd.com/comment/productPageComments.action?callback=fetchJSON_comment98&productId={}&score=0&sortType=6&page={}&pageSize=10&isShadowSku=0&rid=0&fold=1'.format(item_id,page)
headers["Referer"] = url
json_decoder = requests.get(comment_url,headers=headers).text
try:
if json_decoder:
start=json_decoder.find('productAttr')
end=json_decoder.find('}]}')+len('}]}')
content=json.loads(s=json_decoder[start:end])
comments=content["comments"]
for c in comments:
comm=c["content"]
good_comments+="{} |".format(comm)
except Exception as e:
pass
return item_id,good_comments
运行方式:
Celery -A getComm Worke -P eventlet -c 20 -l info
一个进程 文件名 运行工作者 以eventlet运行 20个线程 定义顶级正常
最后celery异步运行返回 ltem_ ld和评论的字符串
3.6Main.py最终代码:
import requests
from bs4 import BeautifulSoup
import re,json,csv
import threadpool
from urllib import parse
KEYWORD="python"
headers={'user-agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/69.0.3947.100 Safari/537.36'}
base="https://item.jd.com/"
id_comm_dict=[]
session = requests.session() #建立会话利用session长链接
session.headers = headers
def get_id(url):
id=re.compile('\d+')
res=id.findall(url)
return res[0]
#一开始的请求页面
def get_index(url):
session=requests.session()
session.headers=headers
html=session.get(url)
soup=BeautifulSoup(html.text,"lxml")
items=soup.select('li.gl-item')
for item in items:
inner_url=item.select('.gl-i-wrap div.p-img a')[0].get('href')
new_inner_url=parse.urljoin(base,inner_url)
#print(inner_url)
item_id=get_id(new_inner_url)
#评论数
comm_num=get_comm_num(new_inner_url)
#print(comm_num)
#获取评论内容
if comm_num>0:
id_comm_dict[item_id]=get_Comm.delay(new_inner_url,comm_num)
print(id_comm_dict)
#店铺内部信息
shop_info_data=get_shop_info(new_inner_url)
print(shop_info_data)
#价格
price=item.select("div.p-price strong i")[0].text
shop_info_data["price"]=price
shop_info_data["comm_num"]=comm_num
shop_info_data["item_id"]=item_id
#print(shop_info_data)
write_csv(shop_info_data)
head=['item_id', 'comm_num',"shop_name","shop_evaluation","logistics","sale_server","shop_brand","price",]
def write_csv(row):
with open("shop.csv","a+",encoding="utf-8") as f:
csv_writer=csv.DictWriter(f,head)
csv_writer.writerow(row)
#获取店铺信息
def get_shop_info(url):
shop_data={}
html=requests.get(url,headers=headers)
soup=BeautifulSoup(html.text,"lxml")
try:
shop_name=soup.select("div.mt h3 a")[0].text
except:
shop_name="京东"
shop_score=soup.select(".score-part span.score-detail em")
try:
shop_evaluation=shop_score[0].text
logistics=shop_score[1].text
sale_server=shop_score[2].text
except:
shop_evaluation=None
logistics=None
sale_server=None
shop_info=soup.select("div.p-parameter ul")
shop_brand=shop_info[0].select("ul li a")[0].text
try:
shop_other=shop_info[1].select("li")
for s in shop_other:
data=s.text.split(":")
key=data[0]
value=data[1]
shop_data[key]=value
except:
pass
shop_data["shop_name"]=shop_name
shop_data["shop_evaluation"]=shop_evaluation
shop_data["logistics"]=logistics
shop_data["sale_server"]=sale_server
shop_data["shop_brand"]=shop_brand
return shop_data
#获取评论数量
def get_comm_num(url):
item_id=get_id(url)
comm_url="https://club.jd.com/comment/productCommentSummaries.action?referenceIds={}&callback=jQuery3108939&_=1583139360714".format(item_id)
comment=session.get(comm_url,headers=headers).text
start=comment.find('{"CommentsCount"')
end=comment.find('"PoorRateStyle":2}]}')+len('"PoorRateStyle":2}]}')
try:
content = json.loads(comment[start:end])['CommentsCount']
except:
return 0
comm_num=content[0]["CommentCount"]
#print(comm_num)
return int(comm_num)
if __name__ == '__main__':
urls=[]
for i in range(1,200,2):
url="https://search.jd.com/Search?keyword={}&wq={}&page={}".format(KEYWORD,KEYWORD,i)
urls.append(([url,],None))
pool=threadpool.ThreadPool(50)
reque=threadpool.makeRequests(get_index,urls)
for i in reque:
pool.putRequest(i)
pool.wait()
3.7获取评论数据
我们把backend存储在了redis的2号数据库里,迭代里边的键,获取结果即可
import redis
import json
def write_csv(row):
with open(shop.txt,"a+",encoding="utf8") as f:
f.write(str(row)+"\n")
r=redis.Redis(host="127.0.0.1",port=6379,db=2)
keys=r.keys()
for key in keys:
res=r.get(key)
res=json.loads(res.decode("utf-8"))
result=res.get("result")
write_csv("result")














 5844
5844











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









