




 介绍了一种名为预排序遍历树算法的高效方法,用于处理树状数据结构,避免了递归查询,提高了数据库操作效率。
介绍了一种名为预排序遍历树算法的高效方法,用于处理树状数据结构,避免了递归查询,提高了数据库操作效率。
无限分类是我们开发中非常常见的应用,像论坛的的版块,CMS的类别,应用的地方特别多。
我们最常见最简单的方法就是在MySql里ID ,parentID,name。其优点是简单,结构简单;缺点是效率不高,因为每一次递归都要查询数据库,几百条数据时就不是很快了!
存储树是一种常见的问题,多种解决方案。主要有两种方法:邻接表的模型,并修改树前序遍历算法。
我们将探讨这两种方法的节能等级的数据。我会使用树从一个虚构的网上食品商店作为一个例子。这食品商店组织其食品类,通过颜色和类型。这棵树看起来像这样:
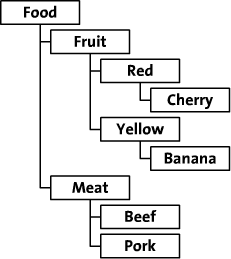
下面我们将用另外一种方法,这就是预排序遍历树算法(modified preorder tree traversal algorithm)
这种方法大家可能接触的比较少,初次使用也不像上面的方法容易理解,但是由于这种方法不使用递归查询算法,有更高的查询效率。
我们首先将多级数据按照下面的方式画在纸上,在根节点Food的左侧写上 1 然后沿着这个树继续向下 在 Fruit 的左侧写上 2 然后继续前进,沿着整个树的边缘给每一个节点都标上左侧和右侧的数字。最后一个数字是标在Food 右侧的 18。 在下面的这张图中你可以看到整个标好了数字的多级结构。(没有看懂?用你的手指指着数字从1数到18就明白怎么回事了。还不明白,再数一遍,注意移动你的手指)。
这些数字标明了各个节点之间的关系,"Red"的号是3和6,它是 "Food" 1-18 的子孙节点。 同样,我们可以看到 所有左值大于2和右值小于11的节点 都是"Fruit" 2-11 的子孙节点
如图所示:
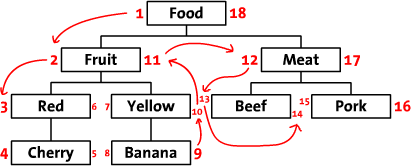
这样整个树状结构可以通过左右值来存储到数据库中。继续之前,我们看一看下面整理过的数据表。
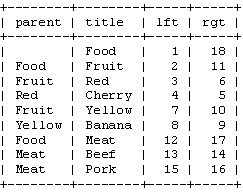
注意:由于"left"和"right"在 SQL中有特殊的意义,所以我们需要用"lft"和"rgt"来表示左右字段。 另外这种结构中不再需要"parent"字段来表示树状结构。也就是 说下面这样的表结构就足够了。
SELECT * FROM tree WHERE lft BETWEEN 2 AND 11;
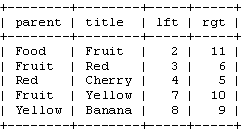
看到了吧,只要一个查询就可以得到所有这些节点。为了能够像上面的递归函数那样显示整个树状结构,我们还需要对这样的查询进行排序。用节点的左值进行排序:
SELECT * FROM tree WHERE lft BETWEEN 2 AND 11 ORDER BY lft ASC;
那么某个节点到底有多少子孙节点呢?很简单,子孙总数=(右值-左值-1)/2
descendants = (right – left - 1) / 2 ,如果不是很清楚这个公式,那就去翻下书,我们在上数据结构写的很清楚!
添加同一层次的节点的方法如下:
 LOCK
TABLE
nested_category WRITE;
SELECT
@myRight
:
=
rgt
FROM
nested_category
WHERE
name
=
'
Cherry
'
;
UPDATE
nested_category
SET
rgt
=
rgt
+
2
WHERE
rgt
>
@myRight
;
UPDATE
nested_category
SET
lft
=
lft
+
2
WHERE
lft
>
@myRight
;
INSERT
INTO
nested_category(name, lft, rgt)
VALUES
(
'
Strawberry
'
,
@myRight
+
1
,
@myRight
+
2
);UNLOCK TABLES;
LOCK
TABLE
nested_category WRITE;
SELECT
@myRight
:
=
rgt
FROM
nested_category
WHERE
name
=
'
Cherry
'
;
UPDATE
nested_category
SET
rgt
=
rgt
+
2
WHERE
rgt
>
@myRight
;
UPDATE
nested_category
SET
lft
=
lft
+
2
WHERE
lft
>
@myRight
;
INSERT
INTO
nested_category(name, lft, rgt)
VALUES
(
'
Strawberry
'
,
@myRight
+
1
,
@myRight
+
2
);UNLOCK TABLES;
添加树的子节点的方法如下:
LOCK
TABLE
nested_category WRITE;
SELECT
@myLeft
:
=
lft
FROM
nested_category
WHERE
name
=
'
Beef
'
;
UPDATE
nested_category
SET
rgt
=
rgt
+
2
WHERE
rgt
>
@myLeft
;
UPDATE
nested_category
SET
lft
=
lft
+
2
WHERE
lft
>
@myLeft
;
INSERT
INTO
nested_category(name, lft, rgt)
VALUES
(
'
charqui
'
,
@myLeft
+
1
,
@myLeft
+
2
);UNLOCK TABLES;
每次插入节点之后都可以用以下SQL进行查看验证:
SELECT
CONCAT( REPEAT(
'
'
, (
COUNT
(parent.name)
-
1
) ), node.name)
AS
name
FROM
nested_category
AS
node,nested_category
AS
parent
WHERE
node.lft
BETWEEN
parent.lft
AND
parent.rgt
GROUP
BY
node.name
ORDER
BY
node.lft;
删除节点的方法,稍微有点麻烦是有个中间变量,如下:
LOCK
TABLE
nested_category WRITE;
SELECT
@myLeft
:
=
lft,
@myRight
:
=
rgt,
@myWidth
:
=
rgt
-
lft
+
1
FROM
nested_category
WHERE
name
=
'
Cherry
'
;
DELETE
FROM
nested_category
WHERE
lft
BETWEEN
@myLeft
AND
@myRight
;
UPDATE
nested_category
SET
rgt
=
rgt
-
@myWidth
WHERE
rgt
>
@myRight
;
UPDATE
nested_category
SET
lft
=
lft
-
@myWidth
WHERE
lft
>
@myRight
;UNLOCK TABLES;
这种方式就是有点难的理解,但是适合数据量很大规模使用,查看所有的结构只需要两条SQL语句就可以了,在添加节点和删除节点的时候略显麻烦,不过相对于效率来说还是值得的,这次发现让我发现了数据库结构真的很有用,但是我在学校学的树基本上都忘记了,这次遇到这个问题才应用到项目中!
参考文章:
http://dev.mysql.com/tech-resources/articles/hierarchical-data.html
http://www.sitepoint.com/article/hierarchical-data-database/3/

















 1881
1881

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









