







 本文深入介绍了硬盘存储器的工作原理,包括磁头、磁道、柱面、扇区和簇等基本概念,以及磁盘容量计算方式。磁盘读写涉及寻道时间、旋转延迟和数据传输时间。MBR、磁盘调度算法如FCFS、SSFT、SCAN和CSCAN也被提及。此外,文章讨论了如何通过提前读和延迟写优化磁盘IO,以及根据局部性原理优化数据物理分布。最后,文章提到了SSD优化的相关内容。
本文深入介绍了硬盘存储器的工作原理,包括磁头、磁道、柱面、扇区和簇等基本概念,以及磁盘容量计算方式。磁盘读写涉及寻道时间、旋转延迟和数据传输时间。MBR、磁盘调度算法如FCFS、SSFT、SCAN和CSCAN也被提及。此外,文章讨论了如何通过提前读和延迟写优化磁盘IO,以及根据局部性原理优化数据物理分布。最后,文章提到了SSD优化的相关内容。
本篇参考自: https://zhuanlan.zhihu.com/p/89505052 https://blog.csdn.net/li_wen01/article/details/80221182
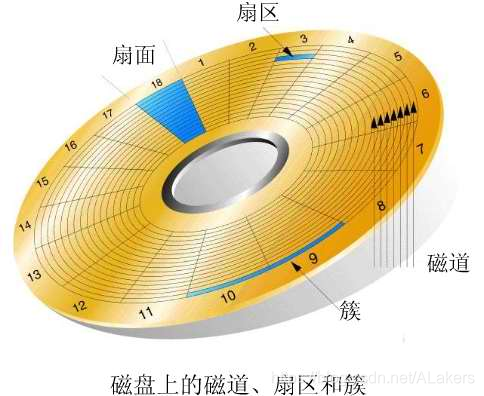
磁盘存储器原理介绍:
为了了解磁盘的运行原理,先上一些图来展示机械硬盘的构造和运行状态
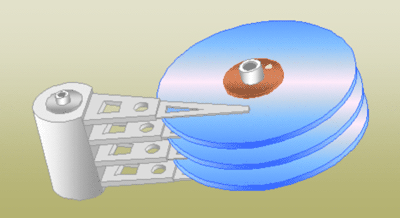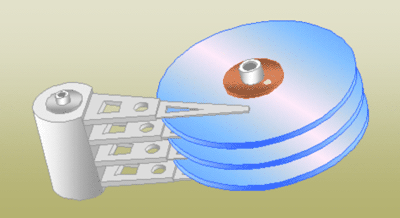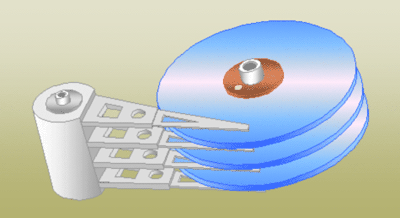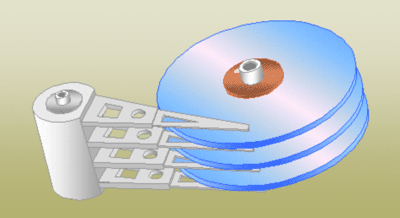
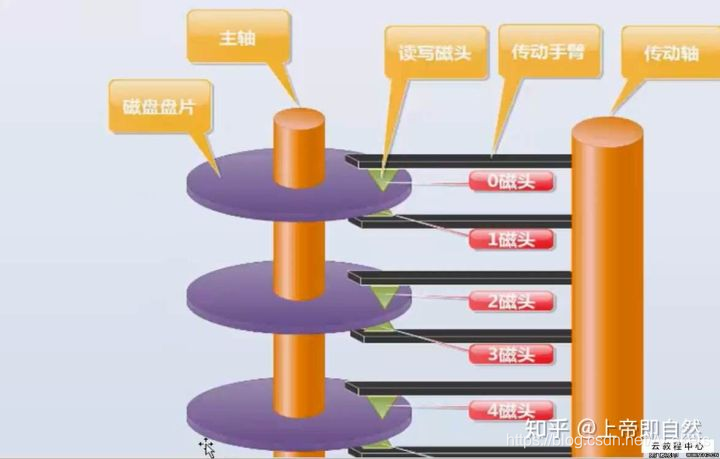

可以看见,硬盘拆开后,里面存在多张磁盘和多个读写磁头,加入一张磁盘有8张磁盘,就会有16个盘面和16个读写磁头了,所有的盘面构成了磁盘组合。
磁盘组合由一个或多个圆盘组成,他们围绕一根中心主轴旋转,圆盘的上下表面涂抹了一层磁性材料,二进制位被存储在这些磁性材料上。其中,0和1在磁材料中表现位不同的模式。
基本概念介绍:
-
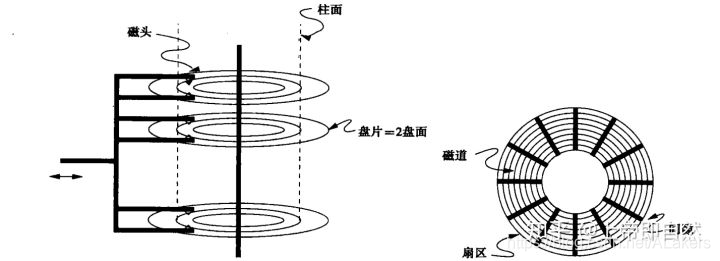
磁头(head):每一个有效盘面都有一个对应的读写磁头,作用就是将存储在硬盘盘片上的磁信息转化为电信号向外传输,工作原理则是利用特殊材料的电阻值会随着磁场变化的原理来读写盘片上的数据。磁头是用线圈缠绕在磁芯上制成的。硬盘在工作时,磁头通过感应旋转的盘片上磁场的变化来读取数据;通过改变盘片上的磁场来写入数据。为避免磁头和盘片的磨损,在工作状态时,磁头悬浮在高速转动的盘片上方,而不与盘片直接接触,只有在电源关闭之后,磁头会自动回到在盘片上的固定位置(称为着陆区,此处盘片并不存储数据,是盘片的起始位置)。
-
磁道(track):磁道是单个盘面上的同心圆,当磁盘旋转时,磁头若保持在一个位置上,则每个磁头都会在磁盘表面划出一个圆形轨迹,这些圆形轨迹就叫做磁道,一个盘面上的磁道可以有成千上万个。相邻磁道之间并不是紧挨着的,这是因为磁化单元相隔太近时磁性会产生相互影响,同时也为磁头的读写带来困难。
-
柱面(cylinder):在有多个盘片构成的盘组中,由不同盘片的面,但处于同一半径圆的多个磁道组成的一个圆柱面。
-
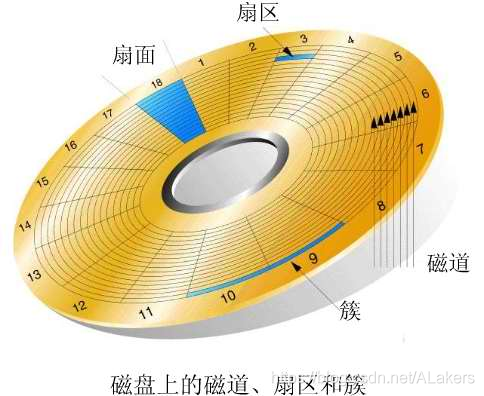
扇区(sector):磁盘上的每个磁道被等分为若干个弧段,这些弧段便是硬盘的扇区(Sector)。硬盘的第一个扇区,叫做引导扇区。扇区是被间隙(gap)分割的圆的片段,间隙未被磁化成0或者1。注意,扇区是读写磁盘最基本的单位,如果一个扇区因为某种原因被破坏,那么整个扇区的数据都会受影响。
-
簇(Cluster):将物理相邻的若干个扇区称为了一个簇。操作系统读写磁盘的基本单位是扇区,而文件系统的基本单位是簇(Cluster)。在Windows下,随便找个几字节的文件,在其上面点击鼠标右键选择属性,看看实际大小与占用空间两项内容,如大小:15 字节 (15 字节), 占用空间:4.00 KB (4,096 字节)。这里的占用空间就是你机器分区的簇大小,因为再小的文件都会占用空间,逻辑基本单位是4K,所以都会占用4K。 簇一般有这几类大小 4K,8K,16K,32K,64K等。簇越大存储性能越好,但空间浪费严重。簇越小性能相对越低,但空间利用率高。NTFS格式的文件系统簇的大小为4K。
-
磁盘容量的计算:硬盘容量=盘面数×柱面数×扇区数×512字节(byte)
硬盘中的数据:
信息存储在硬盘里,硬盘是由很多的盘片组成,通过盘片表面的磁性物质来存储数据。 把盘片放在显微镜下放大,可以看到盘片表面是凹凸不平的,凸起的地方被磁化,代表数字 1,凹的地方没有被磁化,代表数字 0,因此硬盘可以通过二进制的形式来存储表示文字、图片等的信息。 所有的盘片都固定在一个旋转轴上,这个轴即盘片主轴,所有的盘片之间是绝对平行的,在每个盘片的盘面上都有一个磁头,磁头与盘片之间的距离比头发丝的直径还小。 所有的磁头连在一个磁头控制器上,由磁头控制器负责各个磁头的运动,磁头可沿盘片的半径方向移动,实际上是斜切运动,每个磁头同一时刻必须是同轴的,即从正上方往下看,所有磁头任何时候都是重叠的。 由于技术的发展,目前已经有多磁头独立技术了,在此不考虑此种情况。 盘片以每分钟数千转到上万转的速度在高速运转,这样磁头就能对盘片上的指定位置进行数据的读写操作。 由于硬盘是高精密设备,尘埃是其大敌,所以必须完全密封。磁盘的读写原理:
系统将文件存储到磁盘上时,按柱面、磁头、扇区的方式进行,即最先是第1磁道的第一磁头下的所有扇区,然后是同一柱面的下一个磁头…… 一个柱面存储满后就推进到下一个柱面,直到把文件内容全部写入磁盘。 系统也以相同的顺序读出数据,读出数据时通过告诉磁盘控制器要读出扇区所在柱面号、磁头号和扇区号(物理地址的三个组成部分)进行。磁盘的读取响应时间:
当需要从磁盘读取数据的时候,系统会将数据的逻辑地址传递个磁盘,磁盘的控制电路按照寻址逻辑将逻辑地址翻译成物理地址,即确定要读的数据在哪个磁道,哪个扇区。 首先必须找到柱面,即磁头需要移动对准相应磁道,这个过程叫做寻道。
然后目标扇区旋转到磁头下,即磁盘旋转将目标扇区旋转到磁头下。
寻道(时间):磁头移动定位到指定磁道所需要的时间,寻道时间越短,I/O操作越快,目前磁盘的平均寻道时间一般在3-15ms,一般都在10ms左右。
旋转延迟(时间):盘片旋转将请求数据所在扇区移至读写磁头下方所需要的时间,旋转延迟取决于磁盘转速。普通硬盘一般都是7200rpm,慢的5400rpm。
数据传输(时间):数据在磁盘与内存之间的实际传输所需要的时间。
MBR:
MBR,它是存在于硬盘的0柱面,0磁头,1扇区里,占512字节的空间。这512字节里包含了主引导程序Bootloader和磁盘分区表DPT。其中Bootloader占446字节,分区表占64字节,一个分区要占用16字节,64字节的分区表只能被划分4个分区,这也就是目前我们的硬盘最多只能支持4个分区记录的原因: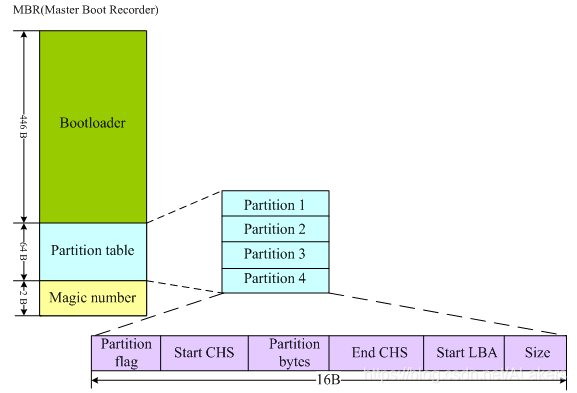
磁盘读写数据所花费的时间:
在了解了硬盘的基本原理之后,不难推算出,磁盘上数据读取和写入所花费的时间可以分为三个部分:-
寻道时间:所谓寻道时间,其实就是磁臂移动到指定磁道所需要的时间,这部分时间又可以分为两部分,寻道时间=启动磁臂的时间+常数*所需移动的磁道数,其中常数和驱动器的的硬件相关,启动磁臂的时间也和驱动器的硬件相关
-
旋转延迟:旋转延迟指的是把扇区移动到磁头下面的时间。这个时间和驱动器的转数有关,我们通常所说的7200转的硬盘的转就是这个。平均旋转延迟=1/(2转数每秒),比如7200转的硬盘的平均旋转延迟等于1/2120≈4.17ms,旋转延迟只和硬件有关。
-
传输时间:传输时间指的是从磁盘读出或将数据写入磁盘的时间。这个时间等于:所需要读写的字节数/每秒转速*每扇区的字节数。
磁盘调度算法:
通过上面硬盘读写数据所分的三部分时间不难看出,大部分参数是和硬件相关的,操作系统无力优化。只有所需移动的磁道数是可以通过操作系统来进行控制的,所以减少所需移动的磁道数是减少整个硬盘的读写时间的唯一办法。因为操作系统内可能会有很多进程需要调用磁盘进行读写,因此合理的安排磁头的移动以减少寻道时间就是磁盘调度算法的目的所在,几种常见的磁盘调度算法如下。
-
先来先服务算法(FCFS):这种算法将对磁盘的IO请求进行排队,按照先后顺序依次调度磁头。这种算法的特点是简单,合理,但没有减少寻道时间
-
最短寻道时间算法(SSFT):这种算法优先执行所需读写的磁道离当前磁头最近的请求。这保证了平均寻道时间的最短,但缺点显而易见:离当前磁头比较远的寻道请求有可能一直得不到执行,这也就是所谓的“饥饿现象”。
-
扫描算法(SCAN):这种算法在磁头的移动方向上选择离当前磁头所在磁道最近的请求作为下一次服务对象,这种改进有效避免了饥饿现象,并且减少了寻道时间。但缺点依然存在,那就是不利于最远一端的磁道访问请求。
-
循环扫描算法(CSCAN):也就是俗称的电梯算法,这种算法是对最短寻道时间算法的改进。这种算法就像电梯一样,只能从1楼上到15楼,然后再从15楼下到1楼。这种算法的磁头调度也是如此,磁头只能从最里磁道到磁盘最外层磁道。然后再由最外层磁道移动到最里层磁道,磁头是单向移动的,在此基础上,才执行和最短寻道时间算法一样的,离当前磁头最近的寻道请求。这种算法改善了SCAN算法,消除了对两端磁道请求的不公平。
其它优化手段以及SQL Server是如何利用这些手段:
除去上面通过磁盘调度算法来减少寻道时间之外。还有一些其它的手段同样可以利用,在开始之前,我首先想讲一下局部性原理。
-
局部性原理:所谓的局部性原理分为时间和空间上的。由于程序是顺序执行的,因此当前数据段附近的数据有可能在接下来的时间被访问到。这就是所谓的空间局部性。而程序中还存在着循环,因此当前被访问的数据有可能在短时间内被再次访问,这就是所谓的时间局部性原理。因此在了解了局部性原理之后,我们可以通过以下几个手段来减少磁盘的IO。
-
提前读(Read-Ahead):提前读也被称为预读。根据磁盘原理我们不难看出,在磁盘读取数据的过程中,真正读取数据的时间只占了很小一部分,而大部分时间花在了旋转延迟和寻道时间上,因此根据空间局部性原理,SQL Server每次读取数据的时间不仅仅读取所需要的数据,还将所请求数据附近的数据进行读取。这在SQL Server中被称为预读。SQL Server通过预读可以有效的减少IO请求。
-
延迟写(Delayed write):同样,根据时间局部性原理,最近被访问的数据有可能再次被访问,因此当数据更改之后不马上写回磁盘,而是继续放在内存中,以备接下来的请求读取或者修改,是减少磁盘IO的另一个有效手段,在SQL Server中,实现延迟写是buffer pool,当一个修改请求被commit之后,并不会立刻写回磁盘,而是将修改的页标记为“脏”,然后根据某种机制通过checkpoint或lazy writer写回磁盘,关于checkpoint和lazy writer的原理,可以参考我之前的文章:浅谈SQL Server中的事务日志(二)—-事务日志在修改数据时的角色。
-
优化物理分布:根据磁盘原理不难看出,如果所请求的数据在磁盘物理磁道之间是连续的,那么会减少磁头的移动距离,从而减少了寻道时间。因此相关的数据放在连续的物理空间上会减少寻道时间。SQL Server中,通过聚集索引使得数据根据主键在物理磁盘上连续,从而减少了寻道时间。
写在最后:
有些数据库对SSD是做了一定的优化的,有兴趣的小伙伴可以去了解一些SSD的原理

















 2万+
2万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









