









首先说下观点:
你估计policy或者value-function的时候,需要用到一些样本,这些样本也是需要采用某种策略(可能固定、可能完全随机、也可能隔一段时间调整一次)生成的。那么,判断on-policy和off-policy的关键在于,你所估计的policy或者value-function 和 你生成样本时所采用的policy 是不是一样。如果一样,那就是on-policy的,否则是off-policy的。
off-policy的Q-learning、on-policy的sarsa
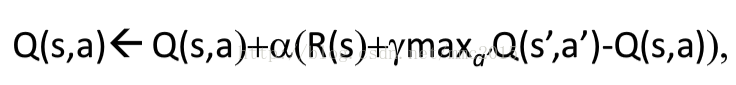
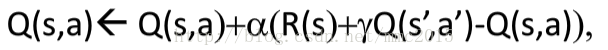
q-learning每次只需要执行一次动作得到(s,a,r,s')就可以更新一次;因为a'永远是最优的那个action,因此你估计的策略应该是最优的,即Q_π*(s,a)。而你生成样本时用的策略则不一定是最优的,因此是off-policy。
sarsa必须执行两次动作得到(s,a,r,s',a')才可以更新一次;而且a'是在特定π的指导下执行的动作,因此估计出来的Q(s,a)是在该π之下的Q-value,即Q_π(s,a)。样本生成用的π和估计的π是同一个,因此是on-policy。
另一方面,如果sarsa每次的a'都选择最优的,即特定的π是一个greedy的π,那么sarsa和q-learning学到的Q-value就是一致的(但是两者的性质仍然不同)。
所以说,基于experience replay的方法基本上都是off-policy的。

之后跟组里的同学讨论,组里的同学说下面这句话【所以说,基于experience replay的方法基本上都是off-policy的。】中的【基本上】可以去掉。换句话说,他认为基于replay buffer的方法都是off-policy的。但实际上,我们考虑on-policy的sarsa,假如他产生了一堆的五元组(s,a,r,s',a'),我们放到了buffer中,如果我们一直用这些buffer中的五元组更新Q_π(s,a)呢?只会使Q_π(s,a)得值越来越精确(在这个过程中,由Q_π(s,a)推导出来的policy可能早就收敛到了π,然而Q值会不断接近最优的Q*),那么是不是一个使用了replay buffer,但是仍然是on-policy的例子呢?














 3633
3633











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









