







1. 前言
本文主要是记录常用的排序算法
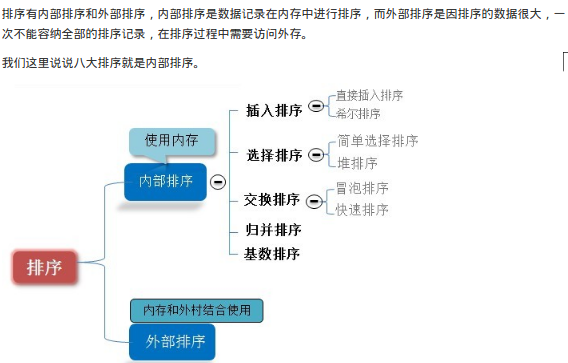
2. 各排序算法时间复杂度
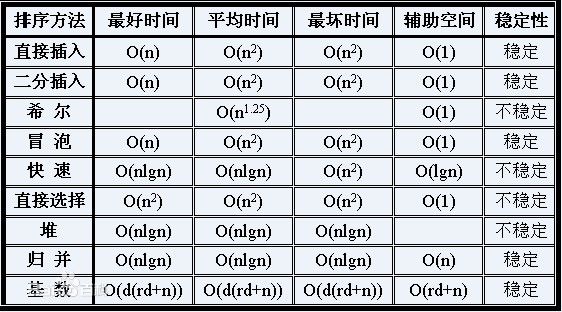
注:排序的稳定性是指如果在排序的序列中,存在前后相同的两个元素的话,排序前 和排序后他们的相对位置不发生变化
3.交换排序
3.1快速排序
快速排序的思想可以由以下描述:

接下来只要对下标0~i-1和下标 i+1~n-1做同样的操作即可,代码如下
void swap(int *a, int *b){
int temp = *a;
*a = *b;
*b = temp;
}
/*输入为:整型数组;素组有效开始索引;有效结束索引
*/
void Qsotr(int *arr, int idxI, int idxJ)
{
if (arr == NULL || idxJ < 1) return;
int key = arr[idxI];
int i = idxI;
int j = idxJ;
while (i != j){
do{
if (arr[j]< key){
swap(arr[i], arr[j]);
break;
}
else{
--j;
}
}while(i != j);
while (i != j){
if (arr[i]> key){
swap(arr[i], arr[j]);
break;
}
else{
++i;
}
}
}
if (i - 1 > 0){
Qsotr(arr, 0, i - 1);
}
if (j + 1 < idxJ){
Qsotr(arr, j + 1, idxJ);
}
}快排的时间复杂度是O(n*log2n),如果数组有序,则快排退化至冒泡排序,时间复杂度为O(n^2),一个改进是对数组最左、最右以及中间这3个数作比较,取中间值放在最右边作为key值。
3.2 冒泡排序
冒泡排序通过两两比较的方式,一次循环比较即可把最大的值或最小的值放至最右边
/*
冒泡排序即可以通过两两比较将小的数从下标0到 len-1上升
也可以把大的数从下标0到 len-1 上升
*/
void swap(int *a, int *b)
{
int temp = *a;
*a = *b;
*b = temp;
}
void BubbleSort(int *arr, int len)
{
if (arr == NULL||len<2) return;
for (int i = len - 1; i > 0; --i){
for (int j = 0; j < i; ++j){ // 一次for 循环可把最大数放至最右端,
//故最右边不用比较
if (arr[j] > arr[j + 1]){ //大的数传到右边
swap(arr[j],arr[j + 1]);
}
}
}
}
/*改进: * 每一轮循环开始前设置标志位,如果本轮循环没有交换任何元素, *则说明所有元素已经有序,可以提前结束排序 */
void BubbleSortImpro(int *arr, int len)
{
bool flag = true;
for (int i=len-1;i>0; --i){
for (int j = 0;j<i; ++j){ // 一次for 循环可把最大数放至最右端,
//故最右边不用比较
if (arr[j]>arr[j + 1]){ //大的数传到右边
swap(arr[j], arr[j + 1]);
flag = false;
}
}
if (flag) break;
}
}
4.1 直接插入排序
直接插入排序原理可由这张表表示

void DirectInsertSort(int *arr, int len)
{
for (int i = 1; i < len; ++i){
if (arr[i] < arr[i - 1]){ //只有第i个数小于第i-1个数,才可能将i插入于 i-1 之前
int move = arr[i];
int j = i;
while (move<arr[j - 1] && j>0){
arr[j] = arr[j - 1];
--j;
}
if (i != j){
arr[j] = move;
}
}
}
} 下图可以形象地看出希尔排序的思想,即以一定量的增量选择将数组分隔为多组,之后作直接插入排序,一般的初次取序列的一半为增量,以后每次减半,直到增量为1。
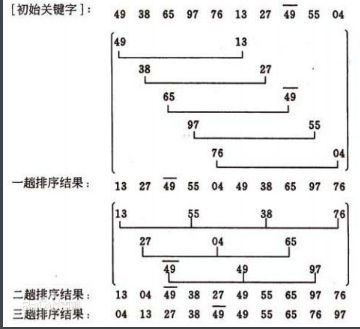
void oneSort(int *arr, int len, int d) //一趟排序
{
for (int i = 0; i < d; ++i){
int k = i + d;
while (k < len){
int j = k - d;
int key = arr[k];
while (key < arr[j] && j >= i){
arr[j + d] = arr[j];
j = j - d;
}
arr[j + d] = key;
k += d;
}
}
}
void ShellSort(int *arr, int len)
{
int d = len;
while (d != 1)
{
d = d / 2; //每次取一半,增量选择为[5, 2 , 1]
oneSort(arr, len, d);
}
}
5 基数排序/ 木桶排序
基数排序又称为木桶排序,基数排序适合整数或者特定格式的浮点数,以下为木桶排序的思想



自己写的代码,for循环有点多,效率有些低
int getBs(int *arr, int len)
{
int maxVal = arr[0];
for (int i = 1; i < len; ++i){
maxVal = arr[i] > maxVal ? arr[i] : maxVal;
}
int count = 1;
while (maxVal / 10 != 0){
count++;
maxVal = maxVal / 10;
}
return count;
}
//返回整数 val 第 idxBit 位的数字
int getBitsIdx(int x, int maxBsNum, int idxBit)
{
if (idxBit == 1){ //各位数
return x % 10;
}
else if (idxBit == maxBsNum){
return x / int(std::pow(10, maxBsNum - 1));
}
else{
return (x / int(std::pow(10, maxBsNum - 1))) % 10;
}
}
void RdixSort(int *a, int len)
{
if (len <= 1) return;
int maxBsNum = getBs(a, len);
int *temp = new int[len];
for (int i = 1; i <= maxBsNum; ++i){
int m = 0;
for (int j = 0; j < 10; ++j){
for (int k = 0; k < len; ++k){
if (getBitsIdx(a[k], maxBsNum, i) == j){
temp[m++] = a[k];
}
}
}
memcpy(a, temp, sizeof(int)*len);
}
delete temp;
}可以看看百度百科上的,比较巧妙的统计0~9这10只桶子的频率,之后转换为temp中的各只桶子所含数的位置,逆序将各只桶子的数存入tempint maxbit(int data[], int n) //辅助函数,求数据的最大位数
{
int d = 1; //保存最大的位数
int p = 10;
for (int i = 0; i < n; ++i)
{
while (data[i] >= p)
{
p *= 10;
++d;
}
}
return d;
}
void RdixSort(int data[], int n) //基数排序
{
int d = maxbit(data, n);
int *tmp = new int[n];
int *count = new int[10]; //计数器
int i, j, k;
int radix = 1;
for (i = 1; i <= d; i++) //进行d次排序
{
for (j = 0; j < 10; j++)
count[j] = 0; //每次分配前清空计数器
for (j = 0; j < n; j++)
{
k = (data[j] / radix) % 10; //统计每个桶中的记录数
count[k]++;
}
for (j = 1; j < 10; j++)
count[j] = count[j - 1] + count[j]; //将tmp中的位置依次分配给每个桶
for (j = n - 1; j >= 0; j--) //将所有桶中记录依次收集到tmp中
{
k = (data[j] / radix) % 10;
tmp[count[k] - 1] = data[j];
count[k]--;
}
for (j = 0; j < n; j++) //将临时数组的内容复制到data中
data[j] = tmp[j];
radix = radix * 10;
}
delete[]tmp;
delete[]count;
}
6.1 简单选择排序
简单选择排序思想很简单,它的工作原理是每一次从待排序的数据元素中选出最小(或最大)的一个元素,存放在序列的起始位置,直到全部待排序的数据元素排完
void SelectSort(int *arr, int len)
{
for (int i = 0; i < len-1; ++i){ //最后一个的时候就不用找了
int minVal = arr[i]; // 取最小(最大也可以 )
int idx = i;
for (int j = i + 1; j<len; ++j){
if (arr[j] < minVal){
minVal = arr[j];
idx = j;
}
}
if (arr[i]!= minVal){
arr[idx] = arr[i];
arr[i] = minVal;
}
}
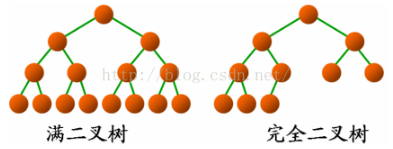
} 堆是一种数据结构,首先其是一种完全二叉树。
完全二叉树指的是在最后一层上只缺少右边的若干结点,其余各层节点数达到最大的一种树形结构,如下所示:
令完全二叉树的一个节点为i ( i < n ),当二叉树满足以下公式之一时,其为堆,共有2种堆,满足公式1,则为大跟堆,满足公式2,则为小跟堆

在堆排序中定义一种下沉调整节点的操作,与大跟堆为例,即某节点会不断与其子节点中较大的一个作交换。对序列中节点0,1,2,..., [n/2]-1,作下沉调整即可将完全二叉树调整为大跟堆,其次将节点0与节点n-1作交换,这时最小的值已经被保存到序列末尾了,这时就要对前n-1个节点中的第0个节点作下沉,又可以调整为堆,之后不断重复直到n个值为有序。代码如下:
// 将nodeIdx处的节点不断与字节点中较大的一个作交换,即相当于往较大的子节点不断"下沉"
void adjustNode(int* arr, int nodeIdx, int adjustlen)
{
int idx = nodeIdx;
int subIdx = 2 * nodeIdx + 1; //nodeIdx的左子节点
while (subIdx < adjustlen){
//右子节点存在且右子节点大于左子节点
if (subIdx + 1< adjustlen && arr[subIdx + 1] > arr[subIdx]){
subIdx++; //subIdx为右子节点位置
}
// 子节点较大的一个与节点作比较,如果大于则交换
if (arr[subIdx] > arr[idx]){
int temp = arr[subIdx];
arr[subIdx] = arr[idx];
arr[idx] = temp;
}
//传递到下一层
idx = subIdx;
subIdx = 2 * idx + 1;
}
}
void HeapSort(int* arr, int len)
{
//首先要把数组调整成堆,这里以大顶堆的形式
//只需对前半数节点作调整即可实现大跟堆
for (int i = (len / 2 - 1); i >= 0; --i){
adjustNode(arr, i, len);
}
//迭代找出0~i 范围的最大值,保存至末尾
for (int i = len-1; i >0; --i){
int temp = arr[i];
arr[i] = arr[0];
arr[0] = temp;
adjustNode(arr, 0, i); //将第0个节点下沉下来
}
}归并排序是采用分治法实现排序的,下图即为归并排序思想

先实现个非递归版本吧
以下为百度百科上归并排序的思路,大括号看成一个batch,一个batch中有两个集合。

void Merge2(int *arr, int a, int b, int length, int n)
{
int right;
//判断第2个集合的结束指针下标是否大于n-1了,
//相当于判断第2个集合是否完整
if (b + length - 1 > n - 1) right = n - b;
else{
right = length;
}
int * temp = new int[length + right];
int i = 0, j = 0;
while (i <= length - 1 && j <= right - 1){
if (arr[a + i] <= arr[b + j]){
temp[i + j] = arr[a + i];
++i;
}
else{
temp[i + j] = arr[b + j];
++j;
}
}
if (j == right){
memcpy(temp + i + j, arr + a + i, (length - i) * sizeof(int));
}
else if (i == length){
memcpy(temp + i + j, arr + b + j, (right - j) * sizeof(int));
}
memcpy(arr + a, temp, (right + length) *sizeof(int)); //在a的地址插入
delete[] temp; //数组的话要[]
}
void MergeSort(int *arr, int len)
{
int step = 1;
//步长从1到2、4、8 ......不断增加
// 以2×step作为1个batch的长度,step则可以看成是batch里两个集合的完整长度
//排序思路如下:
//首先一个batch通常含有2个集合,batch以2,4,8,.... 的形式不断向前跳跃
//
//最外层的step必须小于整个序列长度,如果大于等于的话,说明就算以0开始,第一个集合的结束下标就大于
//等于arrLen,则这个序列不存在2个集合了
while (step <len){
// i+step实际就为batch里后个集合的开始指针,这个开始指针至少应该小于等于序列最后下标,这样说明
// 这个batch里才能有两个集合
for (int i = 0; i + step <= len-1; i += 2 * step){ //batch大小是2*step
// 下标i为第一个集合的起点指针,i+step为第2个集合的起点指针
//指针包含在内的集合长度为step,该函数首先要调整好第2个集合的长度
//一开始默认为step,当第2个集合的最后一个元素,其位置可表示为 b+step-1,
//如果这个位置小于等于arrLen-1,说明当前这个集合完整,如果大于,说明集合里有元素
//是缺的,把集合长度由step改成(n-b)
Merge2(arr, i, i + step, step, len);
}
step *= 2;
}
}未完待续......














 374
374











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









