







 本文介绍了如何利用大数据技术开发一个餐饮消费可视化系统,通过机器学习进行情感分析,结合TF-IDF和交叉验证优化模型。项目涵盖了数据收集、清洗、分析(如情感极性判断)以及数据可视化(如时间与空间关联分析)的全过程,旨在为餐饮企业决策提供支持。
本文介绍了如何利用大数据技术开发一个餐饮消费可视化系统,通过机器学习进行情感分析,结合TF-IDF和交叉验证优化模型。项目涵盖了数据收集、清洗、分析(如情感极性判断)以及数据可视化(如时间与空间关联分析)的全过程,旨在为餐饮企业决策提供支持。
目录
前言
📅大四是整个大学期间最忙碌的时光,一边要忙着备考或实习为毕业后面临的就业升学做准备,一边要为毕业设计耗费大量精力。近几年各个学校要求的毕设项目越来越难,有不少课题是研究生级别难度的,对本科同学来说是充满挑战。为帮助大家顺利通过和节省时间与精力投入到更重要的就业和考试中去,学长分享优质的选题经验和毕设项目与技术思路。
🚀对毕设有任何疑问都可以问学长哦!
大家好,这里是海浪学长大数据毕设专题,本次分享的课题是
🎯基于大数据的餐饮消费可视化系统
项目背景
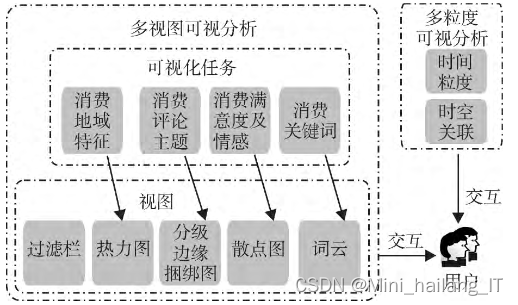
随着餐饮行业的快速发展,餐饮消费数据呈现出爆炸性增长。这些数据中蕴含着丰富的信息,对于了解消费者喜好、市场趋势、菜品优化等方面具有重要意义。因此,建立一个基于大数据的餐饮消费可视化系统,旨在通过数据挖掘和分析,为餐饮企业提供决策支持。本课题将有助于提升餐饮企业的竞争力,并为其他行业的可视化数据分析提供借鉴。
设计思路
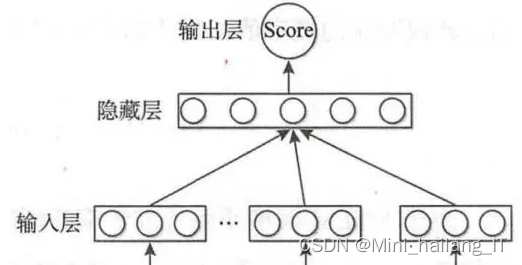
在评论情感分析中应用机器学习算法的方法,包括支持向量机、多项式朴素贝叶斯和伯努利贝叶斯三种算法。首先进行人工标注,然后进行分词和去停用词处理,接着采用TF-IDF向量化,最后通过十次十折交叉验证训练模型,并使用召回率和准确率计算F值作为分类效果评判标准。最终选择效果最好的模型用于判别情感极性。
随机选取一定数量的评论,并由人工对它们的情感极性进行标注,其中积极情感标注为1,消极情感标注为-1。为了保证分类器的效果,标注的积极和消极情感数量需要保持一致。由于餐饮订购网站评论文本具有较强的领域性,我们使用PYNLPIR分词工具进行分词,并加入用户字典以提高分词的准确性。此外,通过停用词库去掉停用词,可以降低特征维度,提高模型的分类效果。
data = pd.read_csv('reviews.csv')
data['tokens'] = data['review'].apply(lambda x: nlpir.cut(x, to_hownet=True, to_syn=True))
data['tokens'] = data['tokens'].apply(lambda x: [word for word in x if word not in stop_words])
labels = []
for i in range(len(data)):
if i % 2 == 0:
labels.append(1) # 积极情感标注为1
else:
labels.append(-1) # 消极情感标注为-1
data['label'] = labels
X_train, X_test, y_train, y_test = train_test_split(data['tokens'], data['label'], test_size=0.2)
vectorizer = TfidfVectorizer()
X_train = vectorizer.fit_transform(X_train)
X_test = vectorizer.transform(X_test)
classifier = LogisticRegression()
classifier.fit(X_train, y_train)
y_pred = classifier.predict(X_test)
accuracy = accuracy_score(y_test, y_pred)
print("Accuracy:", accuracy)将文本数据转化为数值向量,即文本向量化。这里我们采用scikit-learn库提供的TF-IDF接口构建向量空间模型。TF-IDF是一种常用的文本向量化方法,它通过计算词语在文档中的出现频率和逆文档频率来衡量词语的重要性。 TF-IDF的核心思想是,一个词在特定文档中的重要性与其在该文档中的出现频率成正比,与其在所有文档集合中的普遍性成反比。TF-IDF向量化方法将文本数据转化为数值向量,使得计算机可以更容易地进行数学运算和数据分析。
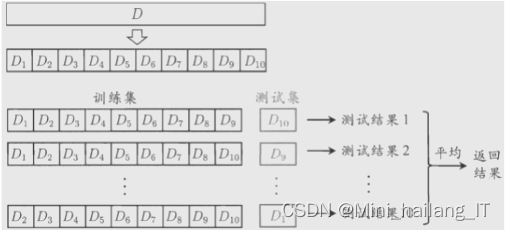
采用十次十折交叉验证方法分别训练三种模型。十折交叉验证是一种常用的评估机器学习模型性能的验证方法。它将数据集分成十份,轮流将其中9份作为训练数据,1份作为测试数据,进行试验。每次试验都会得出相应的正确率(或差错率)。10次的结果的正确率(或差错率)的平均值作为对算法精度的估计。这种方法的优势在于能够减少评估过程中的偏差,因为每次试验使用的训练和测试数据都是不同的。此外,十折交叉验证还可以用于估计模型的泛化能力,因为它通过在不同的数据子集上测试模型来模拟了模型的泛化性能。
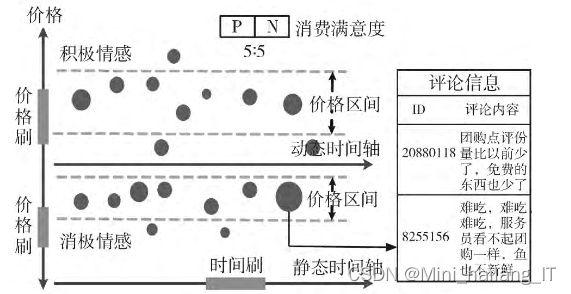
情感分析图通过散点图的方式展示不同商铺在不同时间、不同价格的情感变化。用户可筛选时间和商铺类型,查看具体情感和数量。消费满意度由积极和消极情感比例计算得出。异常情感可快速定位,便于判断消费者选择和价格区间及情感与价格的关系。该图用于舆情监控,帮助用户更好地理解消费者情感变化。
对团购网站评论数据进行了主题提取和关键词提取,以识别消费行为特征。在可视分析阶段,采用分级边缘捆绑图和标签云展示主题词和关键词,并设计了基于时空维度的多粒度过滤方法,对同一属性在不同粒度下反映出的特有规律或特征进行分析,为消费者行为分析提供依据。
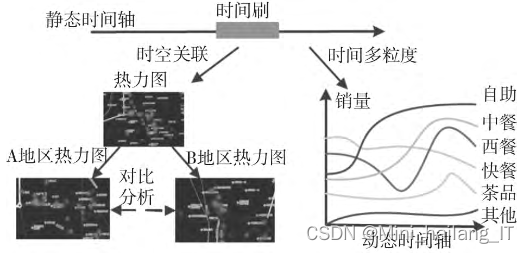
多粒度时空关联分析旨在探究时间和地域对城市餐饮消费行为的影响。在时空关联分析中,用户可以选择不同的时间粒度,并使用热力图在地图上显示选定时间粒度下的商铺销量分布。通过对比不同时间粒度下不同地区的销量,可以深入了解消费行为的时空特征。多粒度时空关联分析具有灵活的时间选择和直观的数据可视化优势,能够深入探究消费行为的时空特征。然而,它可能无法有效检测特定情况,存在主观性,且在处理大规模数据时性能受限,需要在使用中注意其局限性。
df['date'] = pd.to_datetime(df['date'])
df.set_index('date', inplace=True)
# 创建一个按日期分组的DataFrame,以便我们可以对每天的数据进行操作
df_daily = df.groupby(pd.Grouper(freq='D')).sum()
# 创建一个按月分组的DataFrame
df_monthly = df.groupby(pd.Grouper(freq='M')).sum()
# 使用matplotlib进行数据可视化
plt.figure(figsize=(10,6))
# 画出每日数据
plt.subplot(211)
plt.plot(df_daily.index, df_daily['your_column'])
plt.title('Daily Data')
plt.xlabel('Date')
plt.ylabel('Value')
# 画出每月数据
plt.subplot(212)
plt.plot(df_monthly.index, df_monthly['your_column'])
plt.title('Monthly Data')
plt.xlabel('Date')
plt.ylabel('Value')
plt.tight_layout() # 自动调整子图间距,使其看起来更整齐。
plt.show() # 显示图形。由于现有的餐饮消费数据集无法满足本课题的需求,我决定自制一个全新的数据集。首先,从各大餐饮平台和商家收集消费数据,确保数据的全面性和实时性。其次,对收集到的数据进行清洗和预处理,包括去重、异常值处理、数据格式统一等操作。然后,将数据按照特定的结构存储在数据库中,以便后续的数据分析和可视化。最后,通过实际应用和测试,不断优化数据集的质量和效果,确保其能够为餐饮企业的决策提供有力支持。

import requests
from bs4 import BeautifulSoup
url = 'http://www.example.com/restaurants'
response = requests.get(url)
soup = BeautifulSoup(response.text, 'html.parser')
restaurants = soup.find_all('div', class_='restaurant')
for restaurant in restaurants:
name = restaurant.find('h1').text
address = restaurant.find('p', class_='address').text
phone = restaurant.find('p', class_='phone').text
website = restaurant.find('a', href=True)['href'] if restaurant.find('a', href=True) else None
print(name, address, phone, website)海浪学长项目示例:

 更多帮助
更多帮助
















 2944
2944

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









