







大数据分析按照模型是否在线学习可以分为离线学习(Offline Learning))和在线学习(Online Learning)两大方式,对应的数据处理模式分别为批处理(Batch Mode)分析和流处理(Streaming)分析。在实际应用中,存在连续不断的海量、高速的流数据,这些场景下,数据通常无法全部保存,只能在通过系统时进行一次性分析处理,流数据分析平台可以发挥重要作用。Spark Streaming采用基于RDD的mini-batch模式处理数据,适合于这种场景,现实中被广泛使用。相比离线学习模型,在线学习模型需要同时考虑学习的精度和效率的问题,实现往往更具挑战性。华为诺亚方舟实验室开源了业界第一个基于Spark Streaming的算法引擎StreamDM,结合了流处理算法的在线增量更新和批处理算法的高可并发性,并实现了常用的在线学习的分类、聚类等算法。本文将详细介绍StreamDM的框架、API和算法,并通过具体的例子介绍如何使用StreamDM来实现大规模流数据分析。
Spark生态圈缺乏一个支持在线学习的流分析算法引擎
Spark是一个基于RDD(Resilient Distributed Datasets)的分布式计算框架,充分利用内存进行多次迭代计算,与Hadoop相比,性能有了很大提升。Spark Streaming是建立在Spark上的准实时计算框架,它接收数据流,并将数据划分为小的batch,不断的输出每一个batch的结果。Spark Streaming的处理对象是DStream,一个时间片对应一个RDD的不间断数据流。
MLlib是Spark的机器学习算法库,提供了常用机器学习算法的实现,包括聚类、分类、回归、序列分析、协同过滤等。当前MLlib中的大部分算法都是基于Batch Mode进行分析的算法,需要先通过数据进行训练,再使用训练完的模型进行预测,无法实时地增量地训练模型。
StreamDM设计了一套数据流分析的在线机器学习流程框架。并实现了主流的基于流式处理的分类(Naïve Bayes、Hoeffding Tree)、聚类(CluStream、StreamKM++)和组合型算法(bagging)等,为Spark生态圈提供了一个支持在线学习的流分析算法引擎。
StreamDM的体系架构和任务流程
StreamDM的执行流程如下:
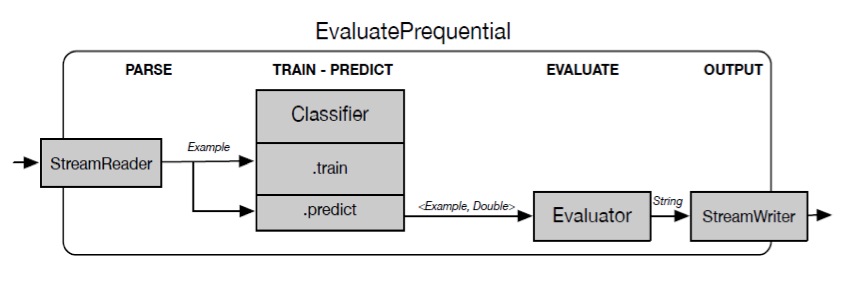
以Classifier流程为例,首先EvaluatePrequential通过StreamReader从外部(文件或者Socket端口)获取数据,生成一个Dstream,Classifier可以通过label的数据来训练模型,同时可以使用增量更新的模型来预测结果。预测的结果通过Evaluator统计精度,最后由StreamWriter输出到文件或者终端。
StreamDM的主要相关接口和作用如下表所示:
| 接口 | 作用 |
|---|---|
| StreamReader | 获取并解析Exmaple,生成DStream |
| Learner | 获取DStream的数据,训练Model |
| Model | 算法模型 |
| Evaluator | 对预测结果进行评估 |
| StreamWriter | 输出预测结果 |
StreamDM的关键特性和优点
StreamDM是第一个在Spark Streaming上支持在线学习的流式数据挖掘算法库,结合了流式数据挖掘算法的增量更新和批处理数据挖掘算法的高可并发性功能。它具有以下几个优点:
易用性
StreamDM的算法调用,可以从命令行通过设置参数的方式直接调用,不需要编译。
./spark.sh "EvaluatePrequential -l (SGDLearner -l 0.01 -p .001 -o LogisticLoss -r ZeroRegularizer) –s (FileReader –k 100 –d 60 –f ../data/mydata)" 1> ../log 2>../result上面的例子中,-l对应的为所用的算法,这里调用了SGD算法;SGDLearner后面跟着SGD算法的参数,-1对应学习参数(Learning parameter),-p对应正则化参数(Regularization parameter),-o 对应损失函数(Loss function parameter),可以是LogisticLoss,Squaredloss,HingeLoss或者PerceptronLoss,-r对应正则方法(Regularizer parameter),可以是ZeroRegularizer, L1Regularizer或者L2Regularizer;-s对应数据的来源,例子中通过从文件mydata读取数据生成DStream,周期为60秒,每一个RDD包含100个数据;1>将log重定向到log文件,2>将结果重定向到result文件。每个算法都有相应的的参数说明,可以参考相应的API文档。
易扩展性
StreamDM定义了一套完整的输入输出接口,定义了分类、聚类等算法的接口,开发人员可以很容易开发出自己的算法。
举例来说,如果用户需要实现一个特定的分类算法,只需要继承Classifier,并实现相关的四个函数:通过数据的信息在init函数中初始化模型,train函数来训练模型,predict函数返回预测的结果,getModel函数则返回训练的模型。
支持丰富的高级算法
StreamDM提供了流式的决策树Hoeffding Tree,流式的聚类算法CluStream和StreamKM++,以及Bagging的框架。接下来介绍下其中的两种算法。
-
Hoeffding算法是一种决策树算法,它从数据流中增量式的生成一棵决策树,对数据流的每个元素仅处理一次。Hoeffding Tree利用Hoeffding bound来决定结点分裂所需的最小样本个数。有充分的证据表明,对同一数据,Hoeffding 树算法生成的决策树与批处理学习算法(如C4.5、CART等)生成的决策树是一致的。
-
CluStream是C.C.Aggarwal等人在2003年提出的经典数据流聚类框架。它引入了簇和时间帧结构两个主要概念,将流聚类分为了在线部分(微聚类)和离线部分(宏聚类)。在线部分实时处理新到达的数据,周期性的存储统计结果;离线部分利用这些统计结果结合用户的输入得到聚类结果。
完整性好
StreamDM没有第三方的插件依赖和版权问题。比如MLlib使用了线性代数包Breeze,Breeze依赖于netlib-java来做数值计算的优化,而netlib-java并不是基于Apache Licence。
欢迎大家下载使用StreamDM,更多的信息请参考StreamDM在Github上的网址:https://github.com/huawei-noah/streamDM/















 510
510

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









