




EXT4源码分析之“文件写入”原理,详细的介绍文件写入的核心流程,并对EXT4中关于文件写入的关键函数进行了分析。
0.前言
今天我们梳理的主要内容是:当对一个文件写入一些内容时,底层到底是怎样处理的?
由此,我们进行了大量的源码跟踪和分析,由于内核的调用链路实在太长,这里只分析一些关键函数,至于更加深入和底层的调用,会在后续源码其它部分的时候有所体现。
1.文件写入概览
先从用户的角度出发,大概看看,用户写入了一个文件,底层发生了哪些事情,由于内容有点多,建议图片放大查看。
注:图片只包含几个主要函数和分支,还有一些分支(如DAX)或者更加深入的函数调用,在此省略。
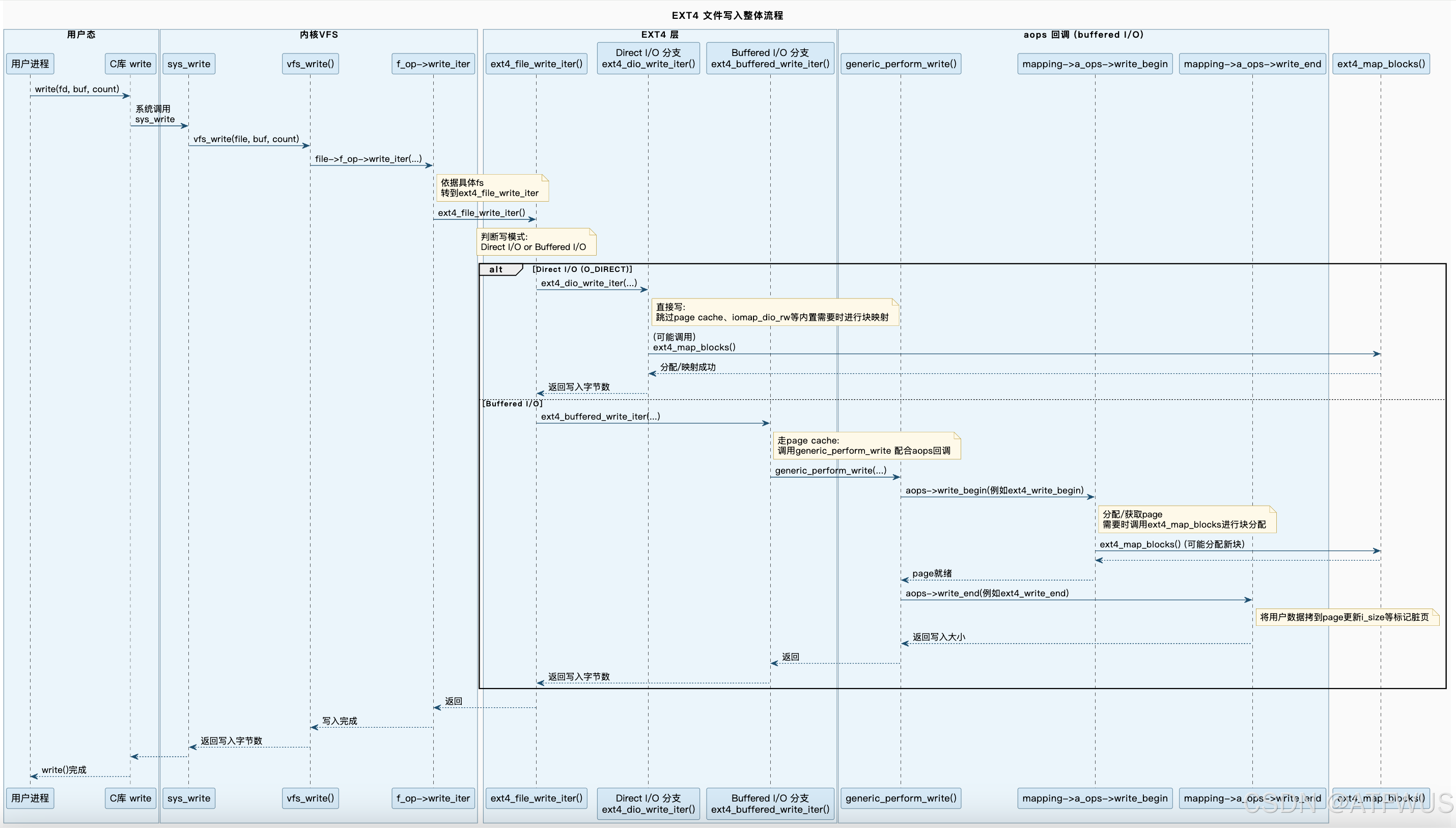
接下来将会分析文件写入的关键流程和过程中遇见的一些常见设计。
1.1 关键流程
- 用户进程层
用户进程通过 C 库函数(例如write())向文件写入数据,最终触发系统调用sys_write。 - VFS 层
•sys_write→vfs_write:VFS 根据file->f_op->write_iter找到对应文件系统的写入回调并调用。
• 此处可以兼容不同文件系统,ext4/xfs/btrfs 都通过 write_iter 方式对接 VFS。 - EXT4 层:选择缓冲写 or 直接写
在ext4_file_write_iter()内,会根据 IOCB_DIRECT 标志判断是 Direct I/O 还是 Buffered I/O,并分两条路径:
• Direct I/O (ext4_dio_write_iter):不使用 Page Cache,直接对块设备 I/O(常通过 iomap_dio_rw() 等)。
• Buffered I/O (ext4_buffered_write_iter):走页缓存流程,需要将数据先写入 Page Cache,然后由内核异步(或在 fsync 时)写回磁盘。 - 缓冲写主要流程
•ext4_buffered_write_iter()调用内核通用函数generic_perform_write()。
• 该函数会调用mapping->a_ops->write_begin()(在 EXT4 中就是ext4_write_begin())。
• 分配或查找对应 Page;
• 若文件需要分配新的块(逻辑块号 → 物理块号),则调用ext4_map_blocks()。
• 如果启用 journaling,会在这里申请或切换 journal handle。
• 填充完 Page Cache 后,会调用aops->write_end()(在 EXT4 中就是ext4_write_end())来完成写入收尾(更新文件大小、标记脏页等)。
• 最后返回写入的字节数给用户进程。 - 直接写主要流程
•ext4_dio_write_iter()一般通过iomap_dio_rw()或ext4_map_blocks(),直接将用户缓冲区数据写到磁盘物理块。
• 需要考虑对齐问题、写入完成后若有 unwritten extents,需要转换成 written extents 等。
• 一旦完成,返回写入的字节数,不会像 buffered write 一样在 page cache 中保留数据。 - 在
ext4_map_blocks中进行实际块分配
• 无论是缓冲或直接写,如果逻辑块尚未分配物理块,就需要在ext4_map_blocks()中搜索或分配新块(更新位图、extents/索引块、inode 元数据等),并做必要的日志记录(通过 JBD2 保证一致性)。 - 返回
最终ext4_file_write_iter()把实际写入的字节数返回到 VFS →sys_write()→ 用户态。这就是文件写的完成点。
1.2 直接写与缓存写
在 Linux 上,用户对文件的读写默认会走 页缓存(buffered I/O),也就是所谓的“缓存读写”。不过在某些场景下,为了性能或特殊需求,用户可能会使用 Direct I/O(直接 I/O)的方式来绕过页缓存,直接与磁盘进行数据交互。下面分几个问题来说明:
1.2.1 通常文件读写为何是缓存写
通常情况下,用户态在对文件执行 read() / write() 调用时,如果没有使用特殊标志(比如 O_DIRECT),或者没有进行 mmap+DAX 之类的特殊配置,那么内核就会走 “缓冲 I/O” 的通用路径。也就是:
- 数据先被复制到内核的 页缓存 中,
- 到脏页(dirty page)达到一定阈值或显式调用 fsync() 等时,再统一写回磁盘。
使用缓存写有这些好处:
- 缓存命中:当同一数据块被多次读写时,可以提升性能,避免频繁的磁盘 I/O;
- 批量写回:可以根据写回策略合并写,减少随机 I/O,提高吞吐量。
- 读写对齐:内核页缓存帮忙对齐到块边界,用户不用关心对齐问题。
1.2.2 什么时候会走直接写(Direct I/O)
所谓直接写(Direct I/O,往往指 O_DIRECT),是用户在调用 open() 打开文件时,指定了 O_DIRECT 标志;或者在某些文件系统(如 ext4、xfs)上再加上特定的 mount 参数(例如 ext4 的 nobh、或者 xfs 的特性)才能生效。
还有一些场景也是类似的“绕过页缓存”模式,例如:
- DAX (Direct Access) 模式:如果底层是支持持久化内存(如 pmem)的文件系统,并以 DAX 模式挂载,那么读写就不会走传统页缓存,而是直接映射到设备地址。
- 内核中的异步 I/O (AIO) + O_DIRECT
- 某些块设备文件或字符设备文件 本身也不走页缓存。
1.2.3 Direct I/O 与 缓冲 I/O 的关键差异
缓冲 I/O(buffered I/O):
- 据先拷贝到 page cache,再标记脏页,后续由内核的 pdflush / kworker / writeback 线程写入磁盘。
- 对应用程序而言,写操作可能很快就返回,因为只要数据写进内核的 page cache 就算写成功了(除非你调用 fsync() / fdatasync() 才会等数据真正落盘)。
- 不需要对齐到磁盘块大小,可以随意写入任意大小和地址
直接 I/O(Direct I/O):
- 绕过 page cache,用户态缓冲区的数据直接与磁盘进行 DMA 传输(内核中间还会有少量缓冲,但不会留在 page cache 里)。
- 常要求对齐到文件系统 / 磁盘的块大小或更高要求(很多文件系统或设备驱动要求 512 字节 / 4 KB 对齐)。不对齐的情况下往往会退回到缓冲写或出错。
- 写调用完成时,数据往往已(或即将)被直接推送到设备,减少了两次拷贝(用户态→page cache,再 page cache→设备)。
Direct I/O 优点:
- 避免双拷贝,提高大文件顺序读写性能;
- 内核不再缓存大量数据,能节约系统内存;
- 适合数据库这类对缓存管理有自己策略的应用,它们希望自行控制读写缓冲、避免操作系统的二次缓存。
Direct I/O 缺点:
- 需要调用方自己保证读写缓冲区与文件系统块对齐;
- 小块或随机 I/O 时性能未必更好,甚至更差;
- 用户态必须自己负责缓存一致性。
因此,应用通常默认使用缓冲 I/O;只有在特定场景(例如数据库、数据仓库、大文件顺序读写、希望用户态自己管理缓存)时才会启用 O_DIRECT。
1.3 DAX(Direct Access)
DAX(Direct Access) 是一种允许应用程序直接访问非易失性内存(如持久内存)的技术,无需通过页缓存。这种方法可以显著减少延迟和 CPU 资源的使用,因为它避免了传统文件系统路径中的数据复制和缓存步骤。
1.3.1 什么时候会使用DAX
- 持久内存设备:当系统配备了支持持久内存(如 Intel Optane DC 持久内存)的硬件时,可以使用 DAX 来充分利用其低延迟和高带宽特性。
- 高性能应用:对于需要高吞吐量和低延迟的数据访问,如数据库系统、关键任务应用等,DAX 可以显著提升性能。
- 大数据处理:在大规模数据分析和处理场景中,DAX 可以减少 I/O 开销,加快数据访问速度。
1.3.2 怎么使用DAX
首先确保硬件支持(确保系统硬件支持持久内存,并已正确配置)、文件系统支持(使用支持 DAX 的文件系统,如 ext4(启用 DAX 选项)或 XFS),在挂载文件系统时,使用 dax 选项。例如:
mount -o dax /dev/sda /mnt/dax
1.4 aops设计
在 Linux 文件系统中,address_space_operations(aops) 是一个非常核心的概念。它和我们在阅读 ext4 源码时常见的 inode_operations、file_operations 一样,都是内核 VFS(虚拟文件系统)层面定义的一种“接口表”。它用来描述 “文件与页缓存(page cache)之间如何交互”,尤其是在做 缓冲读写(buffered I/O)时,aops 中的一些回调函数会被调用。
1.4.1 aops定位
在内核中,每个文件(准确说是 inode 对应的 address_space,即 inode->i_mapping)都会关联一个 address_space_operations 结构,通过它定义如何进行:
- 缓冲读(readpage、readahead)
- 缓冲写(write_begin、write_end)
- 写页回收(writepage、writepages)
- 截断或无效化页缓存(invalidatepage)
- 以及可能的其它操作,如 direct_IO、launder_page 等等
为什么需要 aops?
因为 VFS 提供了一个通用的“页缓存读写”框架,但具体的底层实现可能因文件系统不同而不同。例如:
- xt4 可能需要在写入时分配块或更新 extents;
- xfs、btrfs 也有自己的元数据管理;
- 网络文件系统 (NFS, CIFS) 则需要远程交互。
因此 VFS 会在恰当的时候回调“aops->xxx()”,让具体文件系统实现自己的逻辑。
与 file_operations / inode_operations 的区别:
file_operations:描述“对文件”的操作,如 read_iter, write_iter, ioctl, open, release 等。inode_operations:描述“对 inode / 目录项”的操作,如 create, mkdir, link, unlink 等。address_space_operations:主要跟“页缓存中的页面读写、写回、截断、同步”等相关。
换句话说,当我们走 buffered I/O 流程,VFS 需要去操作页缓存的页面(分配、写脏、回写、销毁等),就会通过 address_space_operations 来调用各文件系统的实现。
1.4.2 aops 中的关键方法及典型流程
在内核中 struct address_space_operations 定义的大致如下(只摘常见的):
struct address_space_operations {
int (*readpage)(struct file *, struct page *);
int (*writepage)(struct page *, struct writeback_control *);
int (*write_begin)(struct file *, struct address_space *,
loff_t pos, unsigned len, unsigned flags,
struct page **pagep, void **fsdata);
int (*write_end)(struct file *, struct address_space *,
loff_t pos, unsigned len, unsigned copied,
struct page *page, void *fsdata);
int (*invalidatepage)(struct page *, unsigned int, unsigned int);
...
};
在ext4中的实现如下:
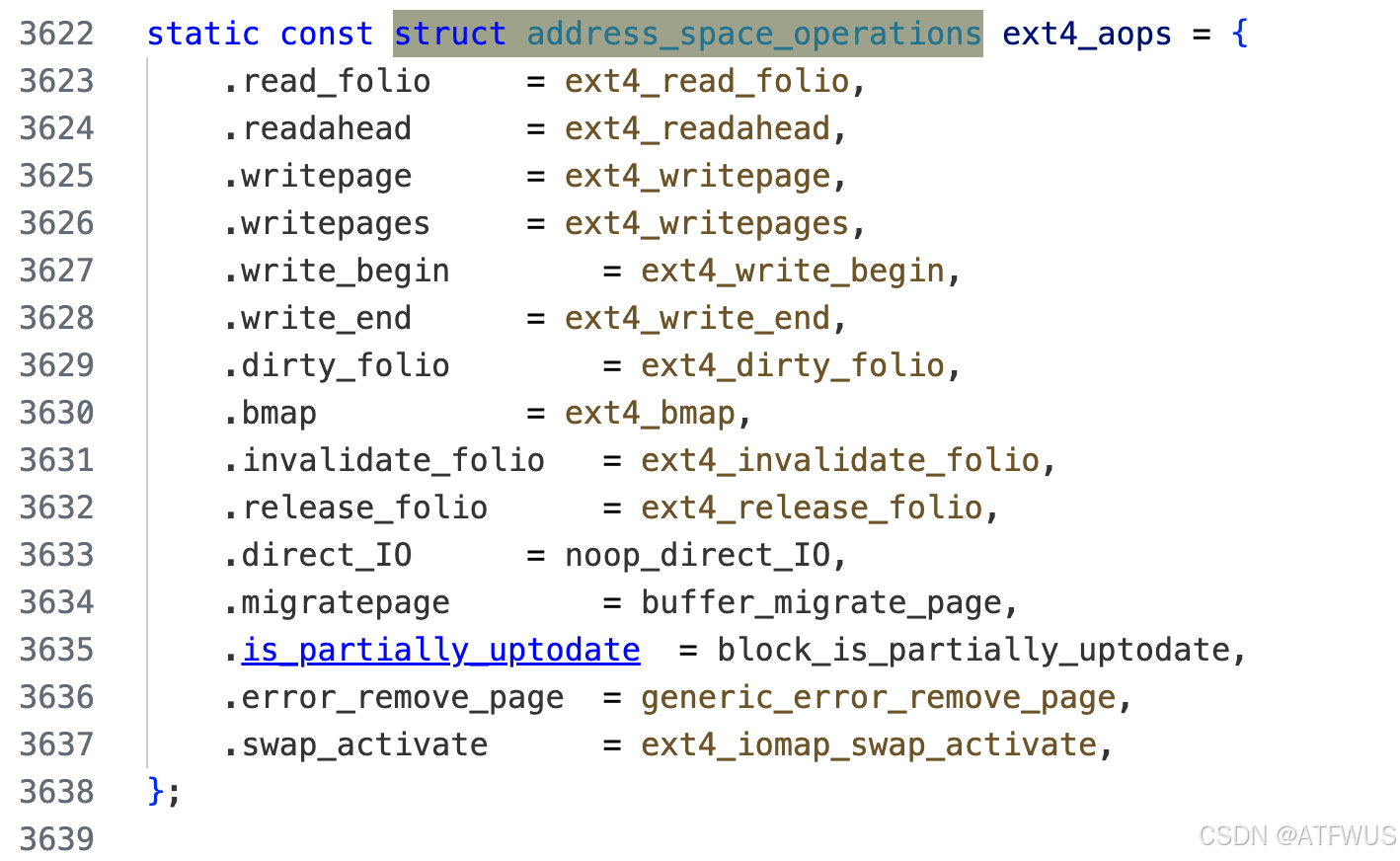
readpage: 当 VFS 需要读数据到内存页(页缓存)时,会调用此函数填充。write_begin/write_end: 当 buffered I/O 写操作到达通用的“写入页缓存”流程时,会先调用 write_begin 做准备(如分配块、映射块),然后复制数据到 page,最后在 write_end 中做收尾(标记脏页、更新 inode 大小等)。writepage: 当内核要回写(writeback)脏页时,会调用此函数把脏数据写回磁盘或远程文件系统。
1.4.3 以写入为例看aops如何配合
当我们调用 write(fd, buf, size) 而且是“非直写”(非 Direct I/O),则会走到内核 generic_perform_write() 等函数里,流程如下:
- VFS 在
generic_perform_write()or__generic_file_write_iter()中,需要把数据写到 page cache:
• 调用mapping->a_ops->write_begin(...)获得对应的 page。
•write_begin里,ext4 等文件系统会检查需要写到哪个逻辑块(lblk),是否已经分配物理块,没有就分配;然后把 page 拉到内存,准备写入。 - 内核把用户数据 copy 到这个 page 缓存中。
- 写完后,内核调用
mapping->a_ops->write_end(...):
•write_end中,ext4 会根据拷贝的长度来更新文件大小 (i_size),设置 page 脏标记,触发后续回写等。 - 最后当回写线程(或
fsync())真的把数据从 page cache 写到磁盘时,还会用到aops->writepage()(或者 iomap-based 回写等方式)。
所以,write_begin 和 write_end 是 buffered write 中的关键。ext4 就在这里面进行块分配 (ext4_map_blocks())、更新元数据,以及完成对 page 的脏写标记。
1.5 iomap设计
iomap 是 Linux 内核中用于统一和简化文件系统 I/O 操作的机制。它通过将文件的逻辑块映射到物理存储位置,提供了一种抽象层,使得不同类型的存储设备(如传统块设备和持久内存)能够以一致的方式进行访问。
其工作流程如下:
- I/O 请求接收:文件系统接收到来自用户空间的 I/O 请求,如读写操作。
- 逻辑地址解析:通过 iomap,将文件的逻辑地址转换为物理存储位置,确定数据所在的具体存储区域。
- 执行 I/O 操作:根据映射结果,直接在内存和存储设备之间进行数据传输,或通过页缓存进行间接传输。
- 更新元数据:完成数据传输后,更新文件的元数据,如文件大小、修改时间等。
- 释放资源:清理和释放在 I/O 操作中使用的资源,确保系统资源的有效利用。
2.源码分析
接下来分析,在EXT4中,文件写入的几个关键函数的源码。
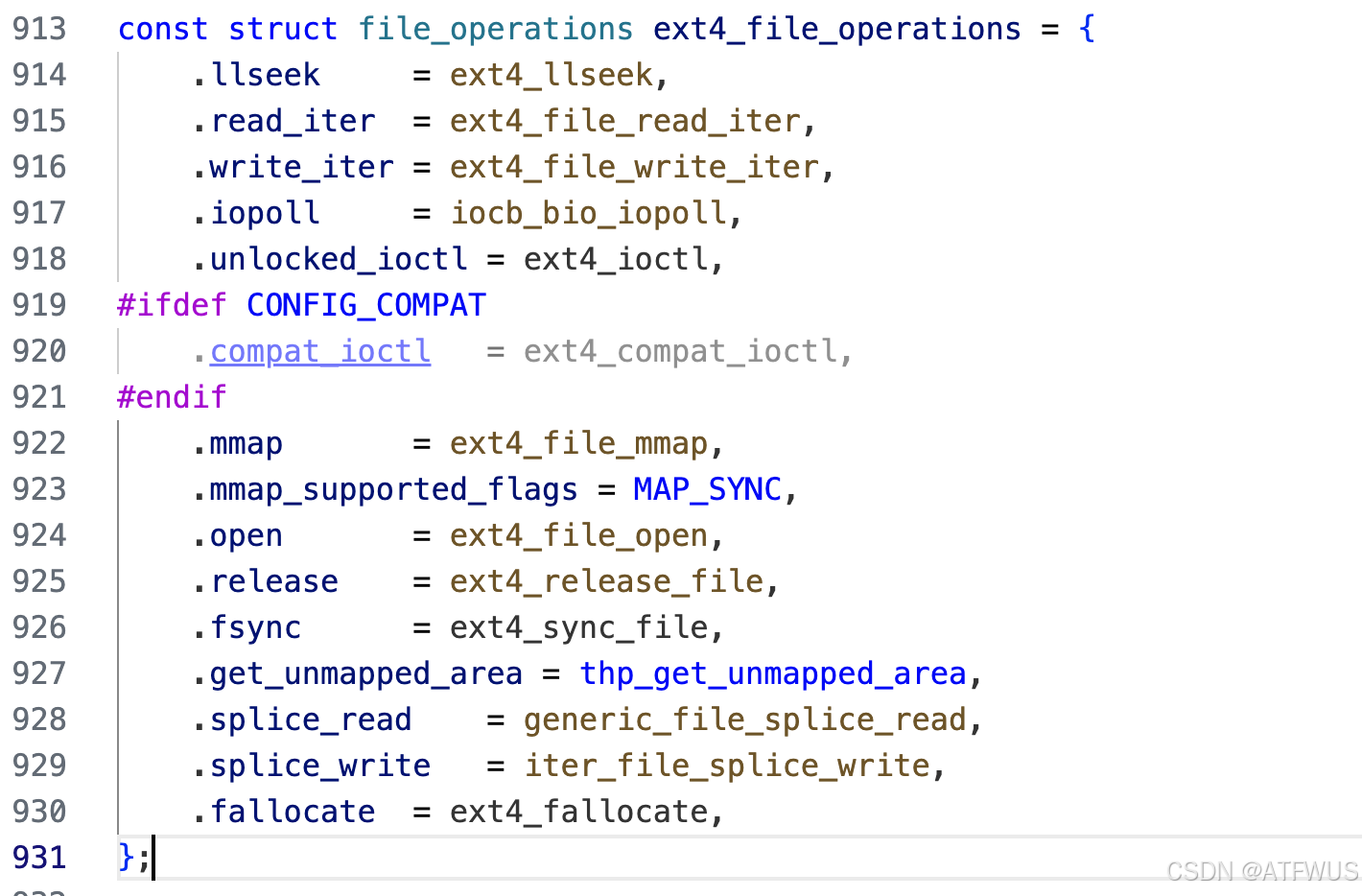
入口位于fs/ext4/fs.c中的ext4_file_write_iter函数,可以在ext4_file_operations看到是write_iter的一个实现:
2.1 入口函数ext4_file_write_iter
/*
* ext4_file_write_iter - 根据 IO 标志决定走 Direct I/O 或者 Buffered I/O
*
* 参数:
* @iocb: 包含了文件、读写位置、标志等的 IO 控制块
* @from: 指向用户态数据缓冲的迭代器
*
* 返回值:
* 成功时返回写入的字节数,出错时返回负值错误码
*
* 主要流程:
* 1) 检查文件系统是否已被强制关闭(ext4_forced_shutdown),若是则返回 -EIO。
* 2) 如果启用了 DAX (IS_DAX(inode)),则调用 ext4_dax_write_iter() 进行 DAX 路径写入。
* 3) 如果带有 IOCB_DIRECT 标志,则走 ext4_dio_write_iter() 进行 Direct I/O。
* 4) 否则,走 ext4_buffered_write_iter() 进行缓存写。
*/
static ssize_t
ext4_file_write_iter(struct kiocb *iocb, struct iov_iter *from)
{
struct inode *inode = file_inode(iocb->ki_filp);
// 检查文件系统是否被强制关闭
if (unlikely(ext4_forced_shutdown(EXT4_SB(inode->i_sb))))
return -EIO;
#ifdef CONFIG_FS_DAX
// 如果是 DAX 文件,调用 DAX 写入函数
if (IS_DAX(inode))
return ext4_dax_write_iter(iocb, from);
#endif
// 如果请求包含 IOCB_DIRECT 标志,使用直接 IO 写入
if (iocb->ki_flags & IOCB_DIRECT)
return ext4_dio_write_iter(iocb, from);
else
// 否则,使用缓冲 IO 写入
return ext4_buffered_write_iter(iocb, from);
}
入口函数的主要流程:根据文件系统和 IO 标志做选择
- DAX(直接访问存储):若文件启用 DAX,走 ext4_dax_write_iter(),直接访问持久化存储。
- Direct I/O:IOCB_DIRECT 标志时走 ext4_dio_write_iter(),绕过 page cache。
- Buffered I/O:否则走 ext4_buffered_write_iter(),使用 page cache 缓冲写入。
2.2 DAX关键函数ext4_dax_write_iter
2.2.1 主体流程
static ssize_t
ext4_dax_write_iter(struct kiocb *iocb, struct iov_iter *from)
{
ssize_t ret;
size_t count;
loff_t offset;
handle_t *handle;
bool extend = false;
struct inode *inode = file_inode(iocb->ki_filp);
// 如果设置了非阻塞标志,尝试获取 inode 的锁
if (iocb->ki_flags & IOCB_NOWAIT) {
if (!inode_trylock(inode))
return -EAGAIN; // 获取锁失败,返回 -EAGAIN
} else {
inode_lock(inode); // 阻塞方式获取 inode 锁
}
// 执行通用写入检查,确保写入操作的合法性
ret = ext4_write_checks(iocb, from);
if (ret <= 0)
goto out; // 检查失败,跳转到释放锁的部分
offset = iocb->ki_pos; // 获取当前写入位置
count = iov_iter_count(from); // 获取写入数据的字节数
// 如果写入超出了当前磁盘大小,需要扩展 inode 的磁盘大小
if (offset + count > EXT4_I(inode)->i_disksize) {
// 启动 journal 事务
handle = ext4_journal_start(inode, EXT4_HT_INODE, 2);
if (IS_ERR(handle)) {
ret = PTR_ERR(handle);
goto out; // 启动事务失败,跳转到释放锁的部分
}
// 将 inode 添加到 orphan 列表,以防止在写入过程中发生崩溃
ret = ext4_orphan_add(handle, inode);
if (ret) {
ext4_journal_stop(handle); // 停止 journal 事务
goto out; // 添加失败,跳转到释放锁的部分
}
extend = true; // 标记需要扩展 inode
ext4_journal_stop(handle); // 停止 journal 事务
}
// 执行 DAX 直接 I/O 读写操作
ret = dax_iomap_rw(iocb, from, &ext4_iomap_ops);
// 如果需要扩展 inode,处理 inode 的扩展
if (extend)
ret = ext4_handle_inode_extension(inode, offset, ret, count);
out:
inode_unlock(inode); // 释放 inode 锁
if (ret > 0)
ret = generic_write_sync(iocb, ret); // 同步写入操作
return ret; // 返回写入结果
}
其主要流程就是做一些前置检查,然后调用dax_iomap_rw做真正的写操作。
为什么代码中使用条件编译处理这部分代码?
因为并非所有系统都配备了支持DAX的硬件(如持久内存)。通过条件编译,可以根据编译时配置(如内核配置选项 CONFIG_FS_DAX)决定是否包含DAX支持。对于不需要DAX功能的系统,排除相关代码可以减少内核的大小和复杂度,优化系统资源。
2.2.2 关键函数dax_iomap_rw
关键函数dax_iomap_rw位于fs/dax.c中,其源码如下:
/**
* dax_iomap_rw - 对 DAX 文件执行 I/O 操作
* @iocb: 此次 I/O 操作的控制块
* @iter: 描述 I/O 操作的地址范围
* @ops: 文件系统传递的 iomap 操作结构
*
* 此函数用于对直接映射的持久内存执行读写操作。调用者需要负责
* 读写排他性以及在 I/O 区域内驱逐任何页缓存页面。
*/
ssize_t
dax_iomap_rw(struct kiocb *iocb, struct iov_iter *iter,
const struct iomap_ops *ops)
{
// 初始化 iomap_iter 结构,用于遍历 I/O 范围
struct iomap_iter iomi = {
.inode = iocb->ki_filp->f_mapping->host, // 获取关联的 inode
.pos = iocb->ki_pos, // 当前 I/O 位置
.len = iov_iter_count(iter), // I/O 操作的总长度
.flags = IOMAP_DAX, // 标记为 DAX 操作
};
loff_t done = 0; // 已完成的字节数
int ret;
// 判断当前 I/O 操作是读还是写
if (iov_iter_rw(iter) == WRITE) {
// 确保当前持有 inode 的写锁
lockdep_assert_held_write(&iomi.inode->i_rwsem);
iomi.flags |= IOMAP_WRITE; // 设置标志为写操作
} else {
// 确保当前持有 inode 的读锁
lockdep_assert_held(&iomi.inode->i_rwsem);
}
// 如果 I/O 控制块设置了非阻塞标志,则设置 IOMAP_NOWAIT
if (iocb->ki_flags & IOCB_NOWAIT)
iomi.flags |= IOMAP_NOWAIT;
// 遍历 I/O 范围,执行相应的 I/O 操作
while ((ret = iomap_iter(&iomi, ops)) > 0)
iomi.processed = dax_iomap_iter(&iomi, iter); // 执行具体的 DAX I/O
// 计算已完成的字节数
done = iomi.pos - iocb->ki_pos;
iocb->ki_pos = iomi.pos; // 更新控制块中的位置
// 如果有字节已完成,则返回已完成的字节数;否则返回错误码
return done ? done : ret;
}
dax_iomap_rw 函数的主要流程:
- 初始化 iomap_iter 结构:
• inode:获取与当前文件描述符关联的 inode。
• pos:设置 I/O 操作的起始位置。
• len:设置此次 I/O 操作的总长度。
• flags:标记此次操作为 DAX 操作(IOMAP_DAX)。 - 锁定检查和标志设置:
• 写操作:
• 确保调用者已持有 inode 的写锁(i_rwsem)。
• 设置 IOMAP_WRITE 标志,表示此次为写操作。
• 读操作:
• 确保调用者已持有 inode 的读锁。
• 非阻塞操作:
• 如果 iocb 中设置了 IOCB_NOWAIT 标志,则设置 IOMAP_NOWAIT,表示此次操作为非阻塞。 - 遍历和执行 I/O 操作:
• 使用 iomap_iter 函数遍历 I/O 范围,获取当前遍历到的 iomap 结构。
• 对于每一个 iomap 区域,调用dax_iomap_iter函数执行具体的 DAX 读写操作,并更新已处理的字节数。 - 更新控制块和返回结果:
• 计算此次 I/O 操作中已完成的字节数。
• 更新 iocb 中的当前 I/O 位置。
• 如果有字节已完成,则返回已完成的字节数;否则返回错误码。
其调用的核心函数是dax_iomap_iter,其源码如下:
/**
* dax_iomap_iter - 执行 DAX 直接 I/O 操作的迭代函数
* @iomi: 描述此次 I/O 操作的 iomap_iter 结构
* @iter: 描述此次 I/O 操作的 iov_iter 结构
*
* 此函数用于在 DAX(Direct Access)模式下执行文件的读写操作。它直接
* 访问持久内存设备,绕过传统的页缓存机制,以提高 I/O 性能。
*
* 返回值:
* 成功时返回已处理的字节数,失败时返回相应的错误码。
*/
static loff_t dax_iomap_iter(const struct iomap_iter *iomi,
struct iov_iter *iter)
{
const struct iomap *iomap = &iomi->iomap; // 获取当前 I/O 操作对应的 iomap 结构
loff_t length = iomap_length(iomi); // 获取此次 I/O 操作的长度
loff_t pos = iomi->pos; // 获取此次 I/O 操作的起始位置
struct dax_device *dax_dev = iomap->dax_dev; // 获取关联的 DAX 设备
loff_t end = pos + length, done = 0; // 计算 I/O 操作的结束位置,并初始化已完成的字节数
ssize_t ret = 0; // 初始化返回值
size_t xfer; // 本次传输的字节数
int id; // DAX 读锁的标识
// 判断此次 I/O 操作的类型是读还是写
if (iov_iter_rw(iter) == READ) {
end = min(end, i_size_read(iomi->inode)); // 确保结束位置不超过文件大小
if (pos >= end)
return 0; // 如果起始位置已超过文件大小,返回 0
// 如果当前 iomap 类型是 HOLE(空洞)或 UNWRITTEN(未写入),则返回零填充的数据
if (iomap->type == IOMAP_HOLE || iomap->type == IOMAP_UNWRITTEN)
return iov_iter_zero(min(length, end - pos), iter);
}
// 如果当前 iomap 类型不是 MAPPED(已映射),则触发警告并返回错误
if (WARN_ON_ONCE(iomap->type != IOMAP_MAPPED))
return -EIO;
/*
* 如果此次写操作需要为当前区域分配新的块,并且该区域在页表中已经映射了一个空洞页面,
* 则需要撤销这些映射,以确保通过 write(2) 写入的数据在 mmap 中是可见的。
*/
if (iomap->flags & IOMAP_F_NEW) {
invalidate_inode_pages2_range(iomi->inode->i_mapping,
pos >> PAGE_SHIFT,
(end - 1) >> PAGE_SHIFT);
}
// 获取 DAX 读锁,确保在访问 DAX 设备时的同步性
id = dax_read_lock();
while (pos < end) {
unsigned offset = pos & (PAGE_SIZE - 1); // 计算当前页面的偏移量
const size_t size = ALIGN(length + offset, PAGE_SIZE); // 计算本次传输的大小,按页面对齐
pgoff_t pgoff = dax_iomap_pgoff(iomap, pos); // 计算当前页面的页偏移
ssize_t map_len; // 当前映射的长度
bool recovery = false; // 标记是否需要进行恢复写操作
void *kaddr; // 内核地址指针
// 检查当前进程是否有致命信号待处理,如果有则中断操作
if (fatal_signal_pending(current)) {
ret = -EINTR; // 返回被中断的错误码
break;
}
// 尝试进行 DAX 直接访问
map_len = dax_direct_access(dax_dev, pgoff, PHYS_PFN(size),
DAX_ACCESS, &kaddr, NULL);
if (map_len == -EIO && iov_iter_rw(iter) == WRITE) {
// 如果直接访问失败且是写操作,尝试恢复写操作
map_len = dax_direct_access(dax_dev, pgoff,
PHYS_PFN(size), DAX_RECOVERY_WRITE,
&kaddr, NULL);
if (map_len > 0)
recovery = true; // 标记需要恢复写操作
}
if (map_len < 0) {
ret = map_len; // 记录错误码
break; // 中断循环
}
map_len = PFN_PHYS(map_len); // 将页帧数转换为物理地址长度
kaddr += offset; // 调整内核地址指针到正确的偏移位置
map_len -= offset; // 调整传输长度,确保不超出页面边界
if (map_len > end - pos)
map_len = end - pos; // 确保不超出 I/O 操作的结束位置
// 根据是否需要恢复写操作,选择相应的传输函数
if (recovery)
xfer = dax_recovery_write(dax_dev, pgoff, kaddr,
map_len, iter);
else if (iov_iter_rw(iter) == WRITE)
xfer = dax_copy_from_iter(dax_dev, pgoff, kaddr,
map_len, iter);
else
xfer = dax_copy_to_iter(dax_dev, pgoff, kaddr,
map_len, iter);
pos += xfer; // 更新当前传输的位置
length -= xfer; // 更新剩余传输的长度
done += xfer; // 累加已完成的字节数
if (xfer == 0)
ret = -EFAULT; // 如果本次传输未完成,设置错误码
if (xfer < map_len)
break; // 如果本次传输未完成,退出循环
}
dax_read_unlock(id); // 释放 DAX 读锁
return done ? done : ret; // 返回已完成的字节数或错误码
}
dax_iomap_iter 函数的主要流程:
1.初始化和参数解析:
- 从传入的
iomap_iter结构中提取当前的 iomap 信息,包括 I/O 操作的长度、起始位置以及关联的 DAX 设备。 - 计算此次 I/O 操作的结束位置,并初始化已完成的字节数 (done) 和返回值 (ret)。
2.处理读操作的特殊情况:
- 如果当前操作是读取,首先确保读取范围不超过文件的实际大小。
- 如果读取的位置在文件的末尾或当前映射类型为 IOMAP_HOLE(空洞)或 IOMAP_UNWRITTEN(未写入),则直接返回零填充的数据,而无需进行实际的数据复制操作。
3.验证映射类型:
- 确保当前的 iomap 类型为 IOMAP_MAPPED(已映射)。如果不是,则触发警告并返回错误。
4.处理新的写入映射:
- 如果此次写操作需要为当前区域分配新的块,并且该区域在页表中已经映射了一个空洞页面,则需要撤销这些映射,以确保通过
write(2)写入的数据在 mmap 中是可见的。
5.获取 DAX 读锁:
- 调用
dax_read_lock()获取 DAX 读锁,确保在访问 DAX 设备时的同步性,防止其他操作同时修改 DAX 映射。
- 执行 I/O 操作的主循环:
- 计算当前页面的偏移和传输大小。
- 计算当前页面的偏移量 (offset) 和本次传输的大小 (size),确保传输按页面对齐。
- 检查是否有致命信号。
- 如果当前进程有致命信号待处理(如被用户中断),则中断操作并返回错误码 -EINTR。
- 尝试进行 DAX 直接访问。
- 调用 dax_direct_access() 尝试直接访问 DAX 设备的物理地址。如果访问失败且是写操作,则尝试恢复写操作 (DAX_RECOVERY_WRITE)。
- 如果恢复写操作成功,设置 recovery 标志。
• 处理访问结果:如果直接访问返回错误码,则记录错误码并中断循环。调整内核地址指针 (kaddr) 和传输长度 (map_len),确保不超出页面边界或 I/O 操作的结束位置。
- 执行数据传输:
- 根据是否需要恢复写操作,选择相应的传输函数。
- 如果需要恢复写操作,调用 dax_recovery_write() 进行恢复写入。
- 如果是写操作,调用 dax_copy_from_iter() 从用户空间复制数据到 DAX 设备。
- 如果是读操作,调用 dax_copy_to_iter() 从 DAX 设备复制数据到用户空间。
- 根据是否需要恢复写操作,选择相应的传输函数。
- 更新传输状态:
- 更新当前传输的位置 (pos)、剩余传输的长度 (length) 以及已完成的字节数 (done)。
- 如果本次传输未完成(xfer == 0),则设置错误码 -EFAULT。
- 如果本次传输未完成且传输长度小于预期,则退出循环。
7.释放 DAX 读锁:
- 调用 dax_read_unlock() 释放之前获取的 DAX 读锁,允许其他操作访问 DAX 设备。
8.返回结果:
- 如果有字节已完成传输,则返回已完成的字节数;否则,返回相应的错误码。
至于更加深入的一些dax函数,这里不再做分析(篇幅过长,这里已经能看到dax的一些核心流程了)。
2.3 直接写关键函数ext4_dio_write_iter
2.3.1 主体流程
/**
* ext4_dio_write_iter - ext4 直接 IO 写入迭代函数
* @iocb: 指向 IO 控制块的指针
* @from: 指向数据源的迭代器
*
* 该函数处理直接 IO (Direct I/O) 写入操作。主要步骤包括:
* 1. 尝试获取共享或独占的 inode 锁,具体取决于 IO 的对齐情况和是否需要扩展文件大小。
* 2. 检查写入操作是否支持直接 IO,如果不支持则回退到缓冲 IO。
* 3. 进行写入前的检查,包括文件是否可写、是否需要扩展文件等。
* 4. 调用 iomap_dio_rw 进行实际的数据写入。
* 5. 处理写入后的操作,如更新文件大小、处理延迟分配等。
*
* 返回值:
* 成功时返回写入的字节数,失败时返回负错误码。
*/
static ssize_t ext4_dio_write_iter(struct kiocb *iocb, struct iov_iter *from)
{
ssize_t ret;
handle_t *handle;
struct inode *inode = file_inode(iocb->ki_filp);
loff_t offset = iocb->ki_pos;
size_t count = iov_iter_count(from);
const struct iomap_ops *iomap_ops = &ext4_iomap_ops;
bool extend = false, unaligned_io = false;
bool ilock_shared = true;
// 检查是否为未对齐的 IO,如果是则需要独占锁
if (ext4_unaligned_io(inode, from, offset)) {
unaligned_io = true;
ilock_shared = false;
}
// 快速检查是否需要扩展文件大小
if (offset + count > i_size_read(inode))
ilock_shared = false;
// 根据 IOCB_NOWAIT 标志尝试非阻塞地获取锁
if (iocb->ki_flags & IOCB_NOWAIT) {
if (ilock_shared) {
if (!inode_trylock_shared(inode))
return -EAGAIN;
} else {
if (!inode_trylock(inode))
return -EAGAIN;
}
} else {
// 阻塞地获取共享或独占锁
if (ilock_shared)
inode_lock_shared(inode);
else
inode_lock(inode);
}
// 检查 inode 是否支持直接 IO,如果不支持则回退到缓冲 IO
if (!ext4_dio_supported(iocb, from)) {
if (ilock_shared)
inode_unlock_shared(inode);
else
inode_unlock(inode);
return ext4_buffered_write_iter(iocb, from);
}
// 进行写入前的检查,确定是否需要扩展文件
ret = ext4_dio_write_checks(iocb, from, &ilock_shared, &extend);
if (ret <= 0)
return ret;
// 如果需要阻塞且设置了 IOCB_NOWAIT,则返回 -EAGAIN
if ((iocb->ki_flags & IOCB_NOWAIT) && (unaligned_io || extend)) {
ret = -EAGAIN;
goto out;
}
offset = iocb->ki_pos;
count = ret;
// 对于未对齐的 IO,确保没有其他未对齐的 IO 在进行
if (unaligned_io)
inode_dio_wait(inode);
// 如果需要扩展文件,添加到 orphan 列表以防止系统崩溃导致数据丢失
if (extend) {
handle = ext4_journal_start(inode, EXT4_HT_INODE, 2);
if (IS_ERR(handle)) {
ret = PTR_ERR(handle);
goto out;
}
ret = ext4_orphan_add(handle, inode);
if (ret) {
ext4_journal_stop(handle);
goto out;
}
ext4_journal_stop(handle);
}
// 如果是覆盖写入,使用覆盖写入的 iomap 操作
if (ilock_shared)
iomap_ops = &ext4_iomap_overwrite_ops;
// 执行实际的数据写入
ret = iomap_dio_rw(iocb, from, iomap_ops, &ext4_dio_write_ops,
(unaligned_io || extend) ? IOMAP_DIO_FORCE_WAIT : 0,
NULL, 0);
if (ret == -ENOTBLK)
ret = 0;
// 处理文件扩展后的操作,如更新文件大小
if (extend)
ret = ext4_handle_inode_extension(inode, offset, ret, count);
out:
// 释放锁
if (ilock_shared)
inode_unlock_shared(inode);
else
inode_unlock(inode);
// 如果写入部分失败,尝试使用缓冲 IO 进行剩余写入
if (ret >= 0 && iov_iter_count(from)) {
ssize_t err;
loff_t endbyte;
offset = iocb->ki_pos;
err = ext4_buffered_write_iter(iocb, from);
if (err < 0)
return err;
// 确保页面缓存中的数据被写入磁盘并失效,以保持直接 IO 的语义
ret += err;
endbyte = offset + err - 1;
err = filemap_write_and_wait_range(iocb->ki_filp->f_mapping,
offset, endbyte);
if (!err)
invalidate_mapping_pages(iocb->ki_filp->f_mapping,
offset >> PAGE_SHIFT,
endbyte >> PAGE_SHIFT);
}
return ret;
}
核心是调用iomap_dio_rw进行实际的数据写入。
2.3.2 关键函数 iomap_dio_rw
iomap_dio_rw位于fs/iomap/direct-io.c中,其源码如下:
ssize_t
iomap_dio_rw(struct kiocb *iocb, struct iov_iter *iter,
const struct iomap_ops *ops, const struct iomap_dio_ops *dops,
unsigned int dio_flags, void *private, size_t done_before)
{
struct iomap_dio *dio;
dio = __iomap_dio_rw(iocb, iter, ops, dops, dio_flags, private,
done_before);
if (IS_ERR_OR_NULL(dio))
return PTR_ERR_OR_ZERO(dio);
return iomap_dio_complete(dio);
}
核心是调用__iomap_dio_rw函数,其源码如下:
/**
* iomap_dio_rw() 始终完成 O_[D]SYNC 写入,无论 I/O 是否作为 AIO 发起。
* 这使我们能够优化纯数据写入,使用 REQ_FUA 而不需要 generic_write_sync()
* 在写入后发起 REQ_FLUSH。这有点复杂,因为这里的单个请求可以映射为多个不连续的 I/O,
* 而且仅有一部分发起的 I/O 可能是纯数据写入。在这种情况下,我们仍然需要进行完整的数据同步完成。
*
* 当页面错误被禁用且 @dio_flags 包含 IOMAP_DIO_PARTIAL 时,
* __iomap_dio_rw 在准备传输后,如果遇到 @iter 中的非驻留页面,可以返回部分结果。
* 在这种情况下,非驻留页面可以被错误处理,并且请求会在 @done_before 设置为之前传输的字节数后恢复。
* 请求随后将以正确传输的总字节数完成;这对于异步完成部分请求是必需的。
*
* 返回 -ENOTBLK 如果写入的页面无效化失败。调用者需要在这种情况下回退到缓冲 I/O。
*/
struct iomap_dio *
__iomap_dio_rw(struct kiocb *iocb, struct iov_iter *iter,
const struct iomap_ops *ops, const struct iomap_dio_ops *dops,
unsigned int dio_flags, void *private, size_t done_before)
{
struct address_space *mapping = iocb->ki_filp->f_mapping; // 获取文件的地址空间
struct inode *inode = file_inode(iocb->ki_filp); // 获取文件对应的 inode
struct iomap_iter iomi = {
.inode = inode, // 设置 inode
.pos = iocb->ki_pos, // 设置 I/O 起始位置
.len = iov_iter_count(iter), // 设置 I/O 长度
.flags = IOMAP_DIRECT, // 设置标志为直接 I/O
.private = private, // 设定私有数据
};
loff_t end = iomi.pos + iomi.len - 1; // 计算 I/O 操作的结束位置
loff_t ret = 0; // 初始化返回值
bool wait_for_completion =
is_sync_kiocb(iocb) || (dio_flags & IOMAP_DIO_FORCE_WAIT); // 判断是否需要等待完成
struct blk_plug plug; // 初始化块插件,用于批量提交 I/O
struct iomap_dio *dio;
if (!iomi.len)
return NULL; // 如果 I/O 长度为 0,直接返回
dio = kmalloc(sizeof(*dio), GFP_KERNEL); // 分配 iomap_dio 结构体
if (!dio)
return ERR_PTR(-ENOMEM); // 分配失败,返回内存不足错误
// 初始化 iomap_dio 结构体
dio->iocb = iocb;
atomic_set(&dio->ref, 1);
dio->size = 0;
dio->i_size = i_size_read(inode);
dio->dops = dops;
dio->error = 0;
dio->flags = 0;
dio->done_before = done_before;
dio->submit.iter = iter;
dio->submit.waiter = current;
dio->submit.poll_bio = NULL;
if (iov_iter_rw(iter) == READ) { // 处理读操作
if (iomi.pos >= dio->i_size)
goto out_free_dio; // 如果读取位置超出文件大小,释放 dio 并返回
if (iocb->ki_flags & IOCB_NOWAIT) { // 如果设置了非阻塞标志
if (filemap_range_needs_writeback(mapping, iomi.pos, end)) {
ret = -EAGAIN;
goto out_free_dio; // 如果需要回写,返回资源暂时不可用错误
}
iomi.flags |= IOMAP_NOWAIT; // 设置 IOMAP_NOWAIT 标志
}
if (iter_is_iovec(iter))
dio->flags |= IOMAP_DIO_DIRTY; // 如果是 iovec 迭代器,设置 DIRTY 标志
} else { // 处理写操作
iomi.flags |= IOMAP_WRITE; // 设置写操作标志
dio->flags |= IOMAP_DIO_WRITE; // 设置写入标志
if (iocb->ki_flags & IOCB_NOWAIT) { // 如果设置了非阻塞标志
if (filemap_range_has_page(mapping, iomi.pos, end)) {
ret = -EAGAIN;
goto out_free_dio; // 如果范围内有页面,返回资源暂时不可用错误
}
iomi.flags |= IOMAP_NOWAIT; // 设置 IOMAP_NOWAIT 标志
}
// 对于数据同步或同步写入,设置同步完成标志
if (iocb->ki_flags & IOCB_DSYNC)
dio->flags |= IOMAP_DIO_NEED_SYNC;
/*
* 对于仅数据同步的写入,我们乐观地尝试使用 FUA(强制单元访问)进行此 I/O。
* 任何非 FUA 写入都会清除此标志,因此我们在完成之前知道是否需要缓存刷新。
*/
if ((iocb->ki_flags & (IOCB_DSYNC | IOCB_SYNC)) == IOCB_DSYNC)
dio->flags |= IOMAP_DIO_WRITE_FUA;
}
if (dio_flags & IOMAP_DIO_OVERWRITE_ONLY) { // 处理仅覆盖标志
ret = -EAGAIN;
if (iomi.pos >= dio->i_size ||
iomi.pos + iomi.len > dio->i_size)
goto out_free_dio; // 如果覆盖范围超出文件大小,释放 dio 并返回
iomi.flags |= IOMAP_OVERWRITE_ONLY; // 设置仅覆盖标志
}
// 等待并写回指定范围内的页面
ret = filemap_write_and_wait_range(mapping, iomi.pos, end);
if (ret)
goto out_free_dio; // 如果等待失败,释放 dio 并返回
if (iov_iter_rw(iter) == WRITE) { // 如果是写操作
/*
* 尝试无效化写入范围内的缓存页面。
* 如果无效化失败,调用者需要回退到缓冲 I/O。
*/
if (invalidate_inode_pages2_range(mapping,
iomi.pos >> PAGE_SHIFT, end >> PAGE_SHIFT)) {
trace_iomap_dio_invalidate_fail(inode, iomi.pos, iomi.len);
ret = -ENOTBLK; // 设置错误码为 -ENOTBLK
goto out_free_dio; // 释放 dio 并返回
}
if (!wait_for_completion && !inode->i_sb->s_dio_done_wq) {
ret = sb_init_dio_done_wq(inode->i_sb);
if (ret < 0)
goto out_free_dio; // 如果初始化工作队列失败,释放 dio 并返回
}
}
inode_dio_begin(inode); // 开始直接 I/O 操作
blk_start_plug(&plug); // 启动块插件,批量提交 I/O
while ((ret = iomap_iter(&iomi, ops)) > 0) { // 遍历 I/O 范围
iomi.processed = iomap_dio_iter(&iomi, dio); // 执行 DIO 迭代操作
/*
* 我们只能为单个 bio I/O 轮询。
*/
iocb->ki_flags &= ~IOCB_HIPRI; // 清除高优先级标志
}
blk_finish_plug(&plug); // 结束块插件,提交所有积累的 I/O
/*
* 只报告已读取到 i_size 的数据。
* 恢复迭代器到对应的状态,因为某些调用者(如 splice 代码)依赖于此。
*/
if (iov_iter_rw(iter) == READ && iomi.pos >= dio->i_size)
iov_iter_revert(iter, iomi.pos - dio->i_size);
if (ret == -EFAULT && dio->size && (dio_flags & IOMAP_DIO_PARTIAL)) {
if (!(iocb->ki_flags & IOCB_NOWAIT))
wait_for_completion = true;
ret = 0;
}
/* 特殊错误码,表示回退到缓冲 I/O */
if (ret == -ENOTBLK) {
wait_for_completion = true;
ret = 0;
}
if (ret < 0)
iomap_dio_set_error(dio, ret); // 设置错误码
/*
* 如果我们发起的所有写入都是 FUA,则无需在 I/O 完成时刷新缓存。
* 对于这种情况,清除同步标志。
*/
if (dio->flags & IOMAP_DIO_WRITE_FUA)
dio->flags &= ~IOMAP_DIO_NEED_SYNC;
WRITE_ONCE(iocb->private, dio->submit.poll_bio); // 设置 I/O 控制块的私有数据
/*
* 即将放弃我们的额外提交引用,这可能是 dio 的最后一个引用。
* 有三种不同的方式可以继续:
*
* (a) 如果这是最后一个引用,我们总是自己完成并释放 dio。
* (b) 如果这不是最后一个引用,并且我们服务于异步 iocb,
* 我们绝不能在减引用后触摸 dio,I/O 完成处理程序将完成并释放它。
* (c) 如果这不是最后一个引用,但我们服务于同步 iocb,
* I/O 完成处理程序将在释放最后一个引用时唤醒我们,
* 我们将在被 I/O 完成处理程序唤醒后完成并释放它。
*/
dio->wait_for_completion = wait_for_completion;
if (!atomic_dec_and_test(&dio->ref)) {
if (!wait_for_completion)
return ERR_PTR(-EIOCBQUEUED); // 返回排队错误
for (;;) {
set_current_state(TASK_UNINTERRUPTIBLE); // 设置任务状态为不可中断
if (!READ_ONCE(dio->submit.waiter))
break; // 如果不再等待,跳出循环
blk_io_schedule(); // 调度块 I/O
}
__set_current_state(TASK_RUNNING); // 设置任务状态为运行
}
return dio; // 返回 dio 结构体
out_free_dio:
kfree(dio); // 释放 dio 结构体
if (ret)
return ERR_PTR(ret); // 如果有错误,返回错误码
return NULL; // 否则返回 NULL
}
__iomap_dio_rw 函数的主要流程
1.初始化和参数解析:
- 获取文件地址空间和 inode:通过 iocb 获取文件的地址空间 mapping 和对应的 inode。
- 设置 iomap_iter 结构体:初始化
iomap_iter结构体 iomi,包括设置文件的起始位置、I/O 长度、标志等。 - 计算 I/O 操作的结束位置:通过起始位置和长度计算出 I/O 操作的结束位置 end。
2.分配和初始化 iomap_dio 结构体:
- 内存分配:使用 kmalloc 分配一个
iomap_dio结构体。 - 初始化字段:设置 iocb、引用计数、已完成的字节数、文件大小、操作函数指针等。
- 设置提交信息:初始化提交部分,包括 iter、等待任务和轮询 bio。
3.处理读写操作的特定逻辑:
- 读操作:
- 检查读取位置:如果读取位置超出文件大小,释放 dio 并返回。
- 非阻塞处理:如果设置了非阻塞标志且范围内需要回写,返回 -EAGAIN 错误;否则设置 IOMAP_NOWAIT 标志。
- 设置 DIRTY 标志:如果是 iovec 迭代器,设置 IOMAP_DIO_DIRTY 标志。
- 写操作:
- 设置写操作标志:包括 IOMAP_WRITE 和 IOMAP_DIO_WRITE。
- 非阻塞处理:如果设置了非阻塞标志且范围内有页面,返回 -EAGAIN 错误;否则设置 IOMAP_NOWAIT 标志。
- 设置同步标志:根据 IOCB_DSYNC 和 IOCB_SYNC 标志,设置 IOMAP_DIO_NEED_SYNC 和 IOMAP_DIO_WRITE_FUA。
4.处理仅覆盖标志:
- 检查覆盖范围:如果设置了 IOMAP_DIO_OVERWRITE_ONLY 标志,检查覆盖范围是否在文件大小内,否则返回 -EAGAIN 错误。
- 设置覆盖标志:如果覆盖范围有效,设置 IOMAP_OVERWRITE_ONLY 标志。
5.等待并写回页面:
- 写回范围内的页面:调用
filemap_write_and_wait_range等待并写回指定范围内的页面。 - 错误处理:如果写回失败,释放 dio 并返回。
6.处理写操作的缓存无效化:
- 无效化缓存页面:对于写操作,尝试无效化写入范围内的缓存页面。
- 错误处理:如果无效化失败,记录错误并返回 -ENOTBLK 错误。
- 初始化直接 I/O 操作:
- 开始直接 I/O:调用 inode_dio_begin 标记 inode 正在进行直接 I/O 操作。
8.批量提交 I/O 操作:
- 启动块插件:调用
blk_start_plug启动块插件,批量提交 I/O 请求以提高性能。 - 遍历和处理 I/O 范围:
- 遍历 I/O 范围:使用
iomap_iter遍历 I/O 范围,并调用iomap_dio_iter处理每个迭代。 - 清除高优先级标志:在每次迭代后清除 IOCB_HIPRI 标志,确保后续 I/O 请求的优先级正确。
- 结束块插件:调用
blk_finish_plug结束块插件,提交所有积累的 I/O 请求。
9.处理读取超出文件大小的情况:
- 恢复迭代器状态:如果是读操作且读取位置超出文件大小,调用
iov_iter_revert恢复迭代器到正确的状态。
10.处理部分 I/O 和特殊错误码:
- 处理部分 I/O:如果遇到 -EFAULT 错误且设置了 IOMAP_DIO_PARTIAL 标志,调整等待完成标志并清除错误码。
- 处理 -ENOTBLK 错误:将其视为需要等待完成并清除错误码。
11.设置错误码和同步标志:
- 设置错误码:如果存在错误,调用
iomap_dio_set_error设置错误码。 - 处理 FUA 标志:如果所有写入操作都是 FUA,清除同步标志 IOMAP_DIO_NEED_SYNC。
12.设置 I/O 控制块的私有数据:
- 设置私有数据:将
dio->submit.poll_bio设置到iocb->private,用于后续处理。
13.处理引用计数和完成等待:
- 减少引用计数:调用
atomic_dec_and_test减少dio->ref的引用计数。 - 处理不同情况:
- 如果是最后一个引用:
- 同步等待:如果需要等待完成,进入不可中断状态并等待 I/O 完成。
- 异步处理:如果不需要等待完成,返回排队错误 -EIOCBQUEUED。
- 返回 dio 结构体:如果不需要等待完成,直接返回 dio 结构体指针。
- 如果是最后一个引用:
14.错误处理和资源释放:
- 释放 dio 结构体:在遇到错误时,释放 dio 并根据情况返回错误码或 NULL。
其核心在于调用iomap_dio_iter函数进行实际的写入,这里不在对其进行解析。(直接写不是本文的重点)
2.4 缓存写关键函数ext4_buffered_write_iter(重点)
2.4.1 主体流程
/**
* ext4_buffered_write_iter - 执行 ext4 文件系统的缓冲写入操作
* @iocb: IO 状态结构体,包含文件、偏移量等信息
* @from: 包含要写入数据的 iov_iter 结构体
*
* 该函数负责处理 ext4 文件系统中的缓冲写入操作。它执行基本的检查,锁定 inode,
* 调用通用的写入处理函数,并在写入完成后进行同步。
*
* 返回值:
* - 成功时,返回写入的字节数
* - 失败时,返回负错误码
*/
static ssize_t ext4_buffered_write_iter(struct kiocb *iocb, struct iov_iter *from)
{
ssize_t ret;
struct inode *inode = file_inode(iocb->ki_filp); // 获取文件对应的 inode
// 检查是否设置了非阻塞写入标志,如果设置则不支持,返回 -EOPNOTSUPP
if (iocb->ki_flags & IOCB_NOWAIT)
return -EOPNOTSUPP;
inode_lock(inode); // 锁定 inode,防止并发修改
// 执行写入前的检查,如权限、文件状态等
ret = ext4_write_checks(iocb, from);
if (ret <= 0)
goto out; // 如果检查失败或没有数据需要写入,跳转到解锁并返回
current->backing_dev_info = inode_to_bdi(inode); // 设置当前进程的 backing_dev_info,关联到 inode 的设备信息
// 调用通用的写入处理函数,执行实际的数据写入
ret = generic_perform_write(iocb, from);
current->backing_dev_info = NULL; // 清除 backing_dev_info
out:
inode_unlock(inode); // 解锁 inode
// 如果写入成功,更新文件偏移量并进行同步
if (likely(ret > 0)) {
iocb->ki_pos += ret; // 更新写入后的文件偏移量
ret = generic_write_sync(iocb, ret); // 进行同步操作,如 fsync
}
return ret; // 返回写入的字节数或错误码
}
主要流程:
- 获取 Inode:
• 通过file_inode(iocb->ki_filp)获取与文件描述符关联的 inode 结构体,代表文件的元数据。 - 检查非阻塞写入标志:
• 如果iocb->ki_flags中设置了 IOCB_NOWAIT 标志,表示不支持非阻塞写入操作,函数立即返回 -EOPNOTSUPP 错误码。 - 锁定 Inode:
• 调用inode_lock(inode)锁定 inode,确保在写入过程中不会有其他进程或线程修改文件的元数据或内容。 - 执行写入前的检查:
• 调用ext4_write_checks(iocb, from)进行一系列检查,如权限验证、文件系统状态、文件是否可写等。
• 如果检查失败或没有数据需要写入(ret <= 0),则跳转到解锁并返回相应的错误码或状态。 - 设置 Backing Device 信息:
• 将当前进程的 backing_dev_info 设置为与 inode 关联的设备信息,这对于内存管理和 I/O 操作的优化有帮助。 - 执行实际的数据写入:
• 调用generic_perform_write(iocb, from),这是一个通用的写入处理函数,负责将数据从用户空间复制到内核空间的页缓存,并进行必要的同步操作。
• 写入完成后,清除当前进程的 backing_dev_info。 - 解锁 Inode:
• 调用inode_unlock(inode)释放之前锁定的 inode,允许其他进程或线程访问和修改文件。 - 更新文件偏移量并同步:
• 如果写入成功(ret > 0),则更新iocb->ki_pos,即文件的当前写入偏移量。
• 调用generic_write_sync(iocb, ret)进行同步操作,确保数据已经被持久化到存储设备。 - 返回结果:
• 函数最终返回写入的字节数 ret,如果发生错误,则返回相应的负错误码。
其核心在于调用generic_perform_write进行实际的数据写入。
2.4.2 关键函数generic_perform_write
/**
* generic_perform_write - 执行通用的写入操作
* @iocb: IO 状态结构体,包含文件、偏移量等信息
* @i: iov_iter 结构体,包含要写入的数据
*
* 该函数负责处理通用的文件写入操作。它遍历数据缓冲区,将数据复制到页缓存中的相应页,
* 并处理写入过程中的各种情况,如错误处理、写入同步等。
*
* 返回值:
* - 成功时,返回写入的字节数
* - 失败时,返回负错误码
*/
ssize_t generic_perform_write(struct kiocb *iocb, struct iov_iter *i)
{
struct file *file = iocb->ki_filp; // 获取文件指针
loff_t pos = iocb->ki_pos; // 获取当前写入位置
struct address_space *mapping = file->f_mapping; // 获取文件的地址空间
const struct address_space_operations *a_ops = mapping->a_ops; // 获取地址空间操作函数指针
long status = 0; // 状态变量,用于存储操作结果
ssize_t written = 0; // 累计写入的字节数
size_t write_len; // 当前写入的字节数
pgoff_t end; // 写入结束的页索引
// 计算写入范围的结束页索引
write_len = iov_iter_count(iov_iter);
end = (pos + write_len - 1) >> PAGE_SHIFT;
do {
struct page *page; // 当前操作的页
unsigned long offset; // 当前页中的偏移量
unsigned long bytes; // 当前页中要写入的字节数
size_t copied; // 从用户空间复制的数据字节数
void *fsdata; // 文件系统私有数据
// 计算当前页中的偏移量和可写入的字节数
offset = (pos & (PAGE_SIZE - 1));
bytes = min_t(unsigned long, PAGE_SIZE - offset, iov_iter_count(iov_iter));
again:
/*
* 检查是否有足够的数据可供写入。
* 如果用户空间的数据不足以填满当前页,返回 -EFAULT 错误。
*/
if (unlikely(fault_in_iov_iter_readable(i, bytes) == bytes)) {
status = -EFAULT;
break;
}
// 检查当前进程是否有致命信号待处理,如果有,则中断写入操作
if (fatal_signal_pending(current)) {
status = -EINTR;
break;
}
// 调用地址空间操作中的 write_begin 函数,准备写入数据
status = a_ops->write_begin(file, mapping, pos, bytes, &page, &fsdata);
if (unlikely(status < 0))
break;
// 如果地址空间支持可写映射,则刷新数据缓存以避免数据不一致
if (mapping_writably_mapped(mapping))
flush_dcache_page(page);
// 从用户空间复制数据到页缓存的当前页
copied = copy_page_from_iter_atomic(page, offset, bytes, iov_iter);
// 再次刷新数据缓存,确保数据已正确写入
flush_dcache_page(page);
// 调用地址空间操作中的 write_end 函数,完成写入操作
status = a_ops->write_end(file, mapping, pos, bytes, copied, page, fsdata);
if (unlikely(status != copied)) {
// 如果实际写入的字节数与预期不符,调整 iov_iter 的位置
iov_iter_revert(i, copied - max(status, 0L));
if (unlikely(status < 0))
break;
}
cond_resched(); // 允许调度,避免长时间占用 CPU
// 如果复制的字节数为 0,则可能遇到内存问题或其他异常情况,重新尝试
if (unlikely(status == 0)) {
/*
* 一次短复制导致 write_end() 拒绝整个写入操作。
* 可能是内存损坏、与 munmap 的竞争,或严重的内存压力。
*/
if (copied)
bytes = copied;
goto again;
}
pos += status; // 更新写入位置
written += status; // 累加写入的字节数
// 根据写入的数据量平衡脏页
balance_dirty_pages_ratelimited(mapping);
} while (iov_iter_count(iov_iter)); // 当还有数据需要写入时,继续循环
return written ? written : status; // 返回总写入的字节数或错误码
}
主要流程:
1.获取相关结构体和变量初始化:
- 通过 iocb->ki_filp 获取指向 file 结构体的指针。
- 获取当前的写入位置 pos。
- 获取文件的地址空间 mapping 和对应的地址空间操作函数指针 a_ops。
- 初始化状态变量 status 和写入计数器 written。
2.计算写入范围的结束页索引:
- 根据当前写入位置 pos 和总写入长度 write_len 计算写入操作覆盖的最后一个页索引 end。
3.循环处理每一页的写入操作:
- 计算当前页的偏移量和可写入字节数:
- 通过 pos & (PAGE_SIZE - 1) 计算当前页中的偏移量 offset。
- 通过 min_t 计算当前页中实际可写入的字节数 bytes,确保不超过页的边界和剩余的写入数据。
- 检查数据可读性:
- 调用 fault_in_iov_iter_readable(i, bytes) 检查用户空间的数据是否足够写入当前页。
- 如果数据不足,设置状态为 -EFAULT 并中断写入操作。
- 检查致命信号:
- 调用 fatal_signal_pending(current) 检查当前进程是否有致命信号待处理。
- 如果有,设置状态为 -EINTR 并中断写入操作。
- 调用 write_begin 函数:
- 通过地址空间操作函数 a_ops->write_begin 准备写入操作,获取对应的页 page 和文件系统私有数据 fsdata。
- 如果 write_begin 返回错误,设置状态并中断写入操作。
- 刷新数据缓存(如果支持可写映射):
- 如果地址空间支持可写映射(mapping_writably_mapped(mapping)),则调用 flush_dcache_page(page) 刷新数据缓存,确保数据一致性。
- 从用户空间复制数据到页缓存:
- 调用 copy_page_from_iter_atomic(page, offset, bytes, iov_iter) 从用户空间复制数据到页缓存的当前页,返回实际复制的字节数 copied。
- 再次刷新数据缓存:
- 再次调用 flush_dcache_page(page) 确保数据已正确写入页缓存。
- 调用 write_end 函数:
- 通过地址空间操作函数 a_ops->write_end 完成写入操作,传入写入位置、写入长度、实际复制的字节数、页 page 和私有数据 fsdata。
- write_end 函数可能会返回实际写入的字节数 status,如果与预期不符,调整 iov_iter 的位置。
- 处理短写入情况:
- 如果实际写入的字节数 status 小于预期的字节数 copied,则重新尝试写入剩余的数据。
- 允许调度:
- 调用 cond_resched() 允许内核调度其他进程,避免长时间占用 CPU 导致系统不响应。
- 处理写入成功的情况:
- 更新写入位置 pos 和累计写入的字节数 written。
- 调用 balance_dirty_pages_ratelimited(mapping) 根据写入的数据量平衡脏页,优化内存管理。
4.循环结束条件:
- 当 iov_iter_count(iov_iter) 为 0,表示所有数据已写入,或遇到错误时,退出循环。
5.返回结果:
- 如果有数据成功写入,返回累计写入的字节数 written。
- 如果没有成功写入任何数据,返回相应的错误码 status。
其关键在于地址空间操作(aops)的回调函数write_begin和write_begin,我们详细分析下载ext4中这两个函数的实现。
2.4.3 EXT4中的write_begin
EXT4中对write_begin的实现位于fs/ext4/inode.c中, 该回调函数由具体的文件系统实现,用于准备写入操作,如锁定页、分配新页、处理文件系统特定的元数据等。
/*
* ext4_write_begin() - 在执行写操作时,用于准备一页(page),并进行块映射或分配等必要步骤。
*
* 函数原型:
* static int ext4_write_begin(struct file *file, struct address_space *mapping,
* loff_t pos, unsigned len,
* struct page **pagep, void **fsdata)
*
* 参数含义:
* - file:对应打开的 file 结构(可能为空,某些内核流程调用时不一定有具体 file)。
* - mapping:地址空间对象,代表文件在 page cache 中的映射。
* - pos:本次写操作在文件中的偏移。
* - len:本次写操作的长度(字节数)。
* - pagep:返回时会把拿到的 page 指针保存在此处。
* - fsdata:针对文件系统的额外数据(一般很少用到,此处可忽略)。
*
* 返回值:
* - 0 表示成功;
* - 负值表示出错,比如 -ENOSPC、-ENOMEM 等。
*/
static int ext4_write_begin(struct file *file, struct address_space *mapping,
loff_t pos, unsigned len,
struct page **pagep, void **fsdata)
{
/* 1. 取得当前文件的 inode */
struct inode *inode = mapping->host;
int ret, needed_blocks;
handle_t *handle; // ext4 日志(journal)句柄
int retries = 0;
struct page *page;
pgoff_t index;
unsigned from, to;
/*
* 如果文件系统处于强制关闭 (forced shutdown) 状态,任何写入都需要拒绝。
* unlikely() 是内核优化宏,暗示这种情况很少发生。
*/
if (unlikely(ext4_forced_shutdown(EXT4_SB(inode->i_sb))))
return -EIO;
/* 打印跟踪信息(可在 ftrace 或内核日志中观察),便于调试。*/
trace_ext4_write_begin(inode, pos, len);
/*
* 2. 计算需要的元数据块数 (needed_blocks)
*
* 其中 ext4_writepage_trans_blocks(inode) 会计算写一个 page 可能需要的事务块数,
* 再加 1 是为了防止如果写失败,需要把 inode 加入 orphan list(孤儿列表)时
* 也要预留足够的日志块。这样在一次事务 (transaction) 中就能完成所有必要操作。
*/
needed_blocks = ext4_writepage_trans_blocks(inode) + 1;
/*
* 计算本次要操作的 page 信息:
* index = pos >> PAGE_SHIFT; // 哪个 page
* from = pos & (PAGE_SIZE - 1); // page 内偏移
* to = from + len; // page 内写区域结束位置
*/
index = pos >> PAGE_SHIFT;
from = pos & (PAGE_SIZE - 1);
to = from + len;
/*
* 3. 如果 inode 标记了 EXT4_STATE_MAY_INLINE_DATA,
* 说明这个文件可能使用了 inline data(即小文件直接存在 inode 中)。
*
* - 调用 ext4_try_to_write_inline_data() 尝试先写到 inline data 中去。
* - 如果 ret == 1, 表示写成功并且完成;则直接返回 0(表示成功,且不需要后续流程)。
* - 如果写 inline data 失败(ret < 0),返回错误给上层。
* - 如果写不下(inline data 不够),则继续使用常规块写流程。
*/
if (ext4_test_inode_state(inode, EXT4_STATE_MAY_INLINE_DATA)) {
ret = ext4_try_to_write_inline_data(mapping, inode, pos, len,
pagep);
if (ret < 0)
return ret;
if (ret == 1)
return 0; // 说明已成功写入 inline data
}
/*
* 4. 先获取 / 分配 page(grab_cache_page_write_begin)
*
* 这里提早 grab page 的原因是,如果系统正处于内存压力或该 page 正在回写,
* 这一步可能会耗时较长。提前抓取 page 可以减少在 journal handle 打开后再等待的时间,
* 同时也允许使用 GFP_NOFS 之外的更灵活的内存分配策略。
*/
retry_grab:
page = grab_cache_page_write_begin(mapping, index);
if (!page)
return -ENOMEM;
/*
* 刚拿到 page 时,会自动上锁,下面 unlock_page() 一下是为了后面做 journal_start,
* 避免长时间持有 page lock + journal handle。
*/
unlock_page(page);
/*
* 5. 启动一个 ext4 日志事务 (journal transaction)
* handle = ext4_journal_start(inode, EXT4_HT_WRITE_PAGE, needed_blocks);
* - EXT4_HT_WRITE_PAGE 表示我们在做写页操作
* - needed_blocks 刚才计算的日志块上限
*
* 如果启动失败,比如内存不足、磁盘出错,则释放 page 并返回错误。
*/
retry_journal:
handle = ext4_journal_start(inode, EXT4_HT_WRITE_PAGE, needed_blocks);
if (IS_ERR(handle)) {
put_page(page);
return PTR_ERR(handle);
}
/*
* 6. 重新上锁该 page(在 grab_cache_page_write_begin() 的 page 已被 unlock)
* 并检查是否有人在此期间把该 page truncate 或移动了。
*/
lock_page(page);
if (page->mapping != mapping) {
/*
* 如果 page->mapping 已经发生变化,说明 page 被移除或换成别的了,
* 只能再次释放并重试 grab page。
*/
unlock_page(page);
put_page(page);
ext4_journal_stop(handle);
goto retry_grab;
}
/*
* 如果在 unlock_page() 期间,后台开始写回该 page(写回前会 wait_for_stable_page()),
* 需要在这里等待写回完成,确保我们写的和写回不会冲突。
*/
wait_for_stable_page(page);
/*
* 7. 实际的块映射 / 分配操作
*
* 根据是否启用 dioread_nolock,以及是否加密等配置,调用不同的函数:
* - ext4_block_write_begin() // 有加密配置时
* - __block_write_begin() // 否则
*
* 并传入的 get_block 回调函数要么是 ext4_get_block_unwritten,要么是 ext4_get_block。
* 这些函数最终会在需要分配块时,调用到 ext4_map_blocks() 进行实际的块分配或块映射。
*/
#ifdef CONFIG_FS_ENCRYPTION
if (ext4_should_dioread_nolock(inode))
ret = ext4_block_write_begin(page, pos, len,
ext4_get_block_unwritten);
else
ret = ext4_block_write_begin(page, pos, len,
ext4_get_block);
#else
if (ext4_should_dioread_nolock(inode))
ret = __block_write_begin(page, pos, len,
ext4_get_block_unwritten);
else
ret = __block_write_begin(page, pos, len, ext4_get_block);
#endif
/*
* 8. 如果文件系统处于 data=journal 模式,需要给每个 buffer_head
* 做一次 get_write_access,以便把 data 也纳入 ext4 的日志管理。
*
* 如果 ret == 0,才会进行 ext4_walk_page_buffers() 来做 journal 访问权限声明。
*/
if (!ret && ext4_should_journal_data(inode)) {
ret = ext4_walk_page_buffers(handle, inode,
page_buffers(page), from, to, NULL,
do_journal_get_write_access);
}
/*
* 9. 错误处理
*
* 如果上面发生错误 ret != 0,说明在块映射 / 分配 或 journal 访问阶段出了问题。
* - 如果这次写会导致文件大小变更(pos+len > i_size),则先把 inode 加入 orphan,
* 再尝试 truncate 回滚已经分配的多余块,最后把 inode 从 orphan 中删除。
*/
if (ret) {
bool extended = (pos + len > inode->i_size) &&
!ext4_verity_in_progress(inode);
unlock_page(page);
if (extended && ext4_can_truncate(inode))
ext4_orphan_add(handle, inode);
ext4_journal_stop(handle);
if (extended) {
ext4_truncate_failed_write(inode);
if (inode->i_nlink)
ext4_orphan_del(NULL, inode);
}
/*
* -ENOSPC 的情况,如果检查后发现仍有希望再次尝试分配(ext4_should_retry_alloc),
* 就 goto retry_journal 再来一次;否则返回错误。
*/
if (ret == -ENOSPC &&
ext4_should_retry_alloc(inode->i_sb, &retries))
goto retry_journal;
put_page(page);
return ret;
}
/*
* 10. 一切顺利时,把分配好的 page 地址返回给上层处理,以便接下来在 page 中
* 拷贝数据到 page cache。这个函数本身到这里就算成功完成了“写前准备”。
*/
*pagep = page;
return ret;
}
2.4.4 EXT4中的write_end
write_end该回调函数由具体的文件系统实现,用于完成写入操作,如解锁页、更新页状态、处理错误等。
/*
* 我们需要获取 generic_commit_write 给出的新的 inode 大小
* `file` 可以为 NULL - 例如,当从 page_symlink() 调用时。
*
* ext4 从不在 inode->i_mapping->private_list 上放置缓冲区。元数据
* 缓冲区由内部管理。
*/
static int ext4_write_end(struct file *file,
struct address_space *mapping,
loff_t pos, unsigned len, unsigned copied,
struct page *page, void *fsdata)
{
handle_t *handle = ext4_journal_current_handle(); // 获取当前的日志句柄
struct inode *inode = mapping->host; // 获取 inode
loff_t old_size = inode->i_size; // 记录写入前的文件大小
int ret = 0, ret2;
int i_size_changed = 0; // 标记文件大小是否改变
bool verity = ext4_verity_in_progress(inode); // 检查是否进行 Verity 校验
trace_ext4_write_end(inode, pos, len, copied); // 跟踪日志
// 如果 inode 有内联数据,调用对应的处理函数
if (ext4_has_inline_data(inode))
return ext4_write_inline_data_end(inode, pos, len, copied, page);
// 调用通用的块写入结束函数,处理实际的数据复制
copied = block_write_end(file, mapping, pos, len, copied, page, fsdata);
/*
* 在持有页面锁的情况下更新 i_size:
* 页面写出可能会覆盖 i_size 之后的部分。
* 需要确保在继续之前,i_size 已正确更新。
*/
if (!verity)
i_size_changed = ext4_update_inode_size(inode, pos + copied);
unlock_page(page); // 解锁页面
put_page(page); // 释放页面引用
// 如果文件大小有改变,更新页面缓存的文件大小
if (old_size < pos && !verity)
pagecache_isize_extended(inode, old_size, pos);
/*
* 如果 i_size 改变,标记 inode 为脏,以便日志系统知道需要同步更新
*/
if (i_size_changed)
ret = ext4_mark_inode_dirty(handle, inode);
/*
* 如果写入的位置超出了文件当前大小,并且 inode 可以被截断,
* 则将 inode 添加到 orphan 列表,以便在事务提交前进行截断操作
*/
if (pos + len > inode->i_size && !verity && ext4_can_truncate(inode))
ext4_orphan_add(handle, inode);
// 停止当前的日志事务
ret2 = ext4_journal_stop(handle);
if (!ret)
ret = ret2;
/*
* 如果写入超出了文件大小,且不是 Verity 校验过程中,
* 则处理写入失败的截断操作
*/
if (pos + len > inode->i_size && !verity) {
ext4_truncate_failed_write(inode); // 处理写入失败的截断
/*
* 如果截断失败,可能 inode 仍在 orphan 列表中,
* 需要将其从 orphan 列表中移除
*/
if (inode->i_nlink)
ext4_orphan_del(NULL, inode);
}
return ret ? ret : copied; // 返回错误码或实际复制的字节数
}
3.总结
在上述文件写入的分析中,做源码分析的时候非常痛苦,因为调用链太长、有很多回调机制、很多引用传参等等,但是深入跟完一些函数,还是能从中看到一些内核设计的精髓。
以下简单列举几点:
- 模块化与抽象化。Ext4 通过抽象的接口(如 address_space_operations 和 get_block 回调)与内核的内存管理和缓冲机制进行交互。
- 高效的内存与 I/O 管理。利用页缓存(Page Cache)和缓冲头(buffer_head)机制,实现数据在用户空间与存储设备之间的高效传输,减少不必要的磁盘访问,提高性能。
- 事务与日志机制。通过 journaling(日志记录)确保数据一致性和持久性,避免因系统崩溃或中断导致的数据损坏,体现了内核在数据完整性保障方面的设计。
- 并发控制与同步。采用 inode 锁定、页面锁定等同步机制,确保多线程和多进程环境下的数据一致性与系统稳定性,有效防止竞争条件和数据竞态。
- 延迟分配与扩展块管理。通过延迟分配(Delayed Allocation)和基于范围的块分配(Extent-based Allocation),优化了磁盘空间的利用率和写入性能,减少碎片,提高文件系统的整体效率。
- 错误处理与恢复机制。在写入过程中,设计了详尽的错误检测与处理逻辑,确保在发生错误时能够安全回滚或记录必要信息。
- 与内核其他子系统的集成。Ext4 与内核的内存管理、I/O 子系统、配额管理等紧密集成,展示了内核各模块之间协同工作的典范。
- 扩展性与灵活性。通过支持内联数据、加密、快速符号链接等特性,Ext4 展现了文件系统设计的灵活性,能够适应多样化的应用需求和硬件环境。
4.参考
内核源代码:
- https://github.com/torvalds/linux/blob/v5.19/fs/ext4/file.c
- https://github.com/torvalds/linux/blob/v5.19/fs/ext4/inode.c
- https://github.com/torvalds/linux/blob/v5.19/fs/buffer.c
- https://github.com/torvalds/linux/blob/v5.19/mm/filemap.c
- https://github.com/torvalds/linux/blob/v5.19/fs/iomap/direct-io.c
ATFWUS 2025-01-02



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











