




Mysql SQL语句查询的执行顺序
目录
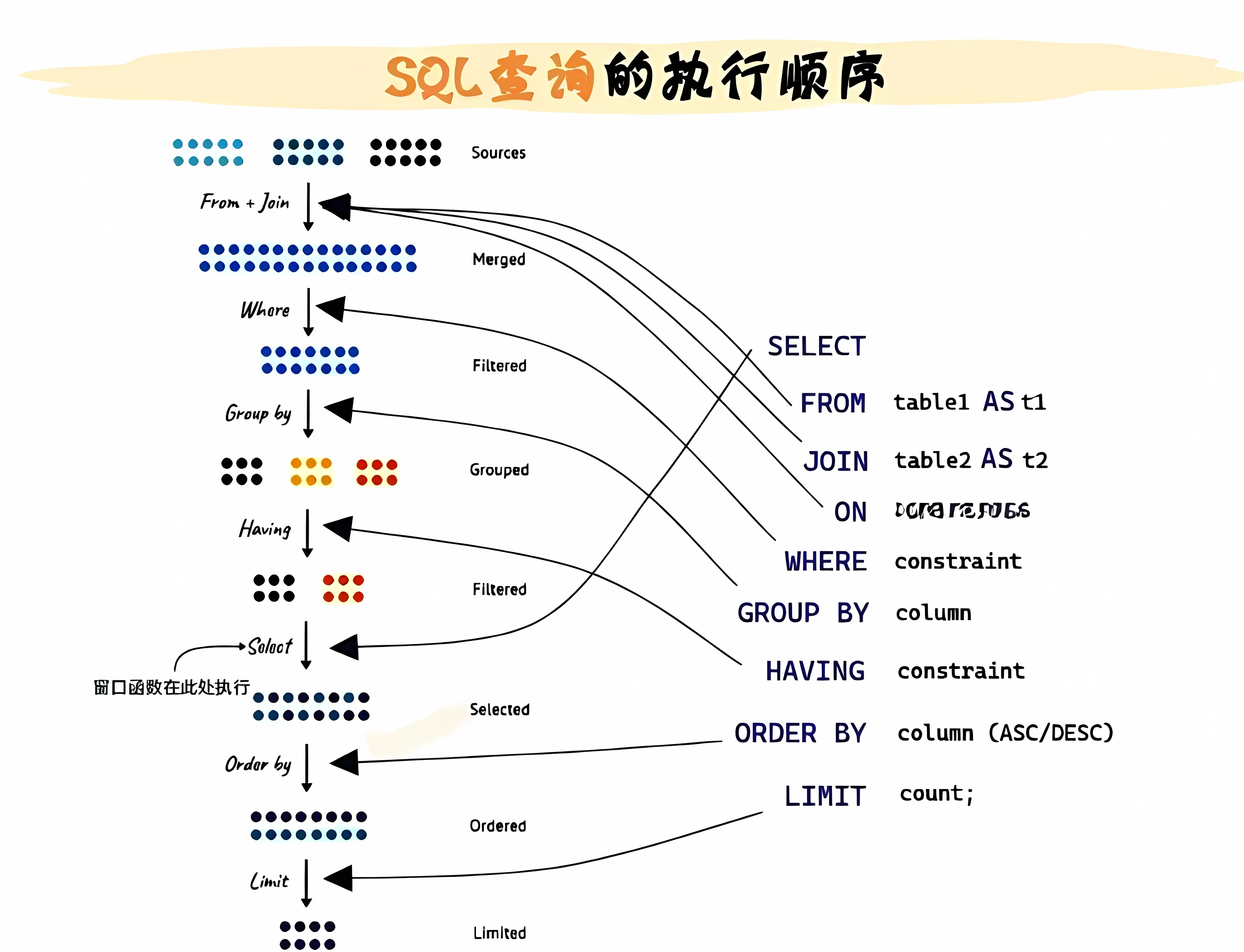
一、执行顺序图
二、详细解释
书写顺序
SELECT -> DISTINCT -> FROM -> JOIN -> ON -> WHERE -> GROUP BY -> HAVING -> ORDER BY -> LIMIT
执行顺序
FROM -> JOIN -> ON -> WHERE -> GROUP BY -> HAVING -> SELECT -> DISTINCT -> ORDER BY -> LIMIT
执行顺序解释:
1. 搭建数据基础 (FROM、JOIN、ON)
1.1. FROM-JOIN:执行FROM子句,取前两个表做笛卡尔乘积,生成虚拟表。
什么是笛卡儿积?
当两张表进行连接查询,没有任何条件限制的时候,最终查询结果条数,是两张表条数的乘积,这种现象被称为:笛卡尔积现象
1.2. 将1.1中生成的虚拟表的各个行,按照ON表达式进行过滤,仅保留符合的数据行生成新的虚拟表
1.3. 将1.2中生成的虚拟表按照LEFT JOIN、RIGHT JOIN或者OUTER JOIN关键字继续做笛卡尔乘积,生成新的虚拟表
具体过程是
LEFT JOIN 把左表记为基础保留表,缺失的数据使用外部行的方式向虚拟表中进行插入,右表部分为NULL,生成新的虚拟表
RIGHT JOIN 把右表记为基础保留表,缺失的数据使用外部行的方式向虚拟表中进行插入,左表部分为NULL,生成新的虚拟表
OUTER JOIN 同时保留两表全部记录,两表未匹配部分为NULL,生成新的虚拟表
1.4. 超过两表关联的情况下,将1.3中新生成的虚拟表和第三个表计算笛卡尔乘积,生成虚拟表,重复1.1-1.3的步骤,最终得到一个最终虚拟表
2. 数据预处理 (where、group by、聚合函数、having)
2.1. 应用where筛选器,对步骤1生成的最终虚拟表应用where筛选器,进行数据过滤,生成新的虚拟表
2.2. 按照group by后的列中值一样的归为一组,得到新的虚拟表
2.3. 将2.2中一组组的数据执行聚合函数,生成新的虚拟表
其实到这里,我们就不难理解为什么不能用[计算表达式]或者[别名]进行分组,因为分组时[计算表达式]或者[别名]都还没有被处理执行
2.4. 通过having后的表达式筛选已分组后的数据,生成新的虚拟表
3. 字段选取与加工 (select、distinct、窗口函数)
3.1. 处理select子句,保留select后边定义的列,生成新的虚拟表
3.2. 应用distinct子句,移除相同的行,生成新的虚拟表
事实上如果应用了group by子句那么distinct是多余的
因为分组的时候是将列中唯一的值分成一组,同时只为每一组返回一行记录,那么所有的记录都将是不相同的
4. 整理结果 (order by、limit)
4.1. 应用order by子句,此时返回的一个游标,而不是虚拟表
正因为返回值是游标,那么使用order by 子句查询不能应用于表表达式,排序是很需要成本的,除非你必须要排序,否则最好不要指定order by,在这一步中是第一个也是唯一一个可以使用select列表中别名的步骤

















 3061
3061

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









