







一、简介
现有 ELK 平台由 Filebeat, Logstash, ElasticSearch, Kibana 构成,主要提供应用日志数据的采集、转发、存储、查询、告警等功能。该文适合已经搭建好 ELK 平台的读者,搭建 ELK 或具体启动配置请查看其它文档。接入日志数据大致需要配置其中三个组件 Filebeat, Logstash, Kibana,如果只是简单采集及查看日志数据,则按照现有的日志格式打日志数据及按模版配置即可,以下是详细配置过程。
二、Filebeat 设置 ./filebeat/filebeat.xml
filebeat 主要设置日志数据的存放路径,以及日志标志等,在现有的配置上,增加一个 prospectors 指定日志数据目录和该日志标志即可,配置如下。
-
paths:
- /data/logs/scheduler/*.log
input_type: log
document_type: scheduler-log
tail_files: true
input_type:指定文件输入类型,设为 log 即可;
document_type:指定 es 输出document 的 type 字段,也用来给日志分类,建议与索引名保持一致;
tail_files:设置为 true,表示从文件尾监控文件新增内容,并把新增的每一行作为一个事件依次发送。设置为 false,则从文件开始处重新发送所有内容;
三、Logstash 设置 ./logstash/conf.d
logstash 主要设置日志数据的内容字段匹配及告警、转发等,接受 filebeat 发送过来的事件,用 grok 表达式对数据进行字段匹配。logstash 的 input 以及 output 已经配置好,所以只需配置 filter,如果需要告警则再配置 output。在./logstash/conf.d 目录(该目录由 logstash.xml 文件的 path.config 参数指定)下新增配置文件,例如 scheduler.conf 。启动 logstash 时携带 --auto-reload 参数,则 logstash 会监听配置目录下的所有文件,如有配置文件改动,自动重启并组成一个配置文件。所以请注意,一个配置文件语法错误会影响到整个 logstash 的执行。
3.1 filter 配置
filter{
if [type] == "scheduler-log" {
#保证多行合并
multiline {
pattern => "^(%{TIMESTAMP_ISO8601}|%{MONTHDAY}\s%{MONTH}\s%{YEAR}\s%{TIME})"
negate => true
what => "previous"
}
#删掉多余的字段,增加必须的index 字段
mutate{
add_field => { "[@metadata][index]" => "scheduler-log" }
remove_field => [ "offset", "input_type", "host", "class" ]
}
grok {
match => { "message" => "^%{TIMESTAMP_ISO8601:[@metadata][timestamp]}\s+\[%{GREEDYDATA:thread}\]\s+%{LOGLEVEL:level}\s+%{GREEDYDATA:class}\s+-\s+%{GREEDYDATA:msg}" }
}
date {
match => [ "[@metadata][timestamp]", "YYYY-MM-dd HH:mm:ss" ]
}
mutate{
remove_field => ["logtime"]
replace => { "[@metadata][index]" => "scheduler-log" }
}
#统计日志数量,主要是对错误日志进行统计告警, meter字段区分不同 type 和 level
metrics {
meter => [ "%{type}_%{level}" ]
add_tag => "metric"
clear_interval => 600
flush_interval => 600
ignore_older_than => 600
add_field => { "type" => "scheduler-log" }
}
}
}首先是 filter 组件的标志,花括号内是主要的配置内容。使用 type 字段分类出日志数据,该字段对应 filebeat 中的 document_type 字段。filter 花括号里面只能使用 filter 的插件,可安装自己开发或者官方未默认安装的插件,具体可以查看官方文档(https://www.elastic.co/guide/en/logstash/current/filter-plugins.html)。
multiline 插件:主要对日志数据进行整合,会以 pattern 字段内 grok 表达式匹配到的内容作为一个日志数据的开头。例如,filebeat 发送三个事件过来,数据如下
2017-06-13 09:35:32,553 [IPC Server handler 6 on 9124] INFO c.m.d.s.s.JobAfterFinishService - 197 worker-6727 PartitionManager fail error.
java.lang.RuntimeException: There is too many failures.
2017-06-13 10:59:31,837 [IPC Server handler 9 on 9124] INFO c.m.d.s.s.JobAfterFinishService - CRON349 执行结束!taskType[1] dbType[null] 执行完毕时间:2017-06-13 10:59:30, 执行结果:2
由于某一条日志数据中带有换行符,使得 filebeat 获取两行数据并发送两个事件。使用 multiline 插件,what 设置为 previous 时,当匹配到字符串的时候,logstash 会等待一段时间,如果有数据过来且不能被 grok 表达式匹配到,则并入上一条数据中。如上面三条数据,1、2会合并一起。如果 what 设置为 next 则 2、3会合并一起。等待的时间由 auto_flush_interval 设置,单位秒。logstash 5.2 以上可能取消了该插件,可以通过离线安装,详细查看。
mutate 插件主要对日志进行简单清理,添加或去掉一些字段;
grok 插件主要是匹配识别出日志数据并解析成字段,grok 表达式校对可查看(http://grokdebug.herokuapp.com/)。例如上文配置文件
^%{TIMESTAMP_ISO8601:[@metadata][timestamp]}\s+\[%{GREEDYDATA:thread}\]\s+%{LOGLEVEL:level}\s+%{GREEDYDATA:class}\s+-\s+%{GREEDYDATA:msg}
2017-06-13 11:34:21,893 [IPC Server handler 7 on 9124] INFO c.m.d.s.s.JobAfterFinishService - CRON658 执行结束!taskType[1] dbType[null] 执行完毕时间:2017-06-13 11:34:21, 执行结果:2该日志由 Java 程序使用 logback 输出,使用 encoder 格式如下
<pattern>%d{ISO8601} [%t] %-5p %c{2} - %m%n</pattern>即只要输出日志符合该 encoder 格式,则可以直接使用该 grok 表达式会匹配出 timestamp 、thread、level、class、msg 这几个字段,并将整行数据赋值给 message 字段。在 kibana 可以看到如下图
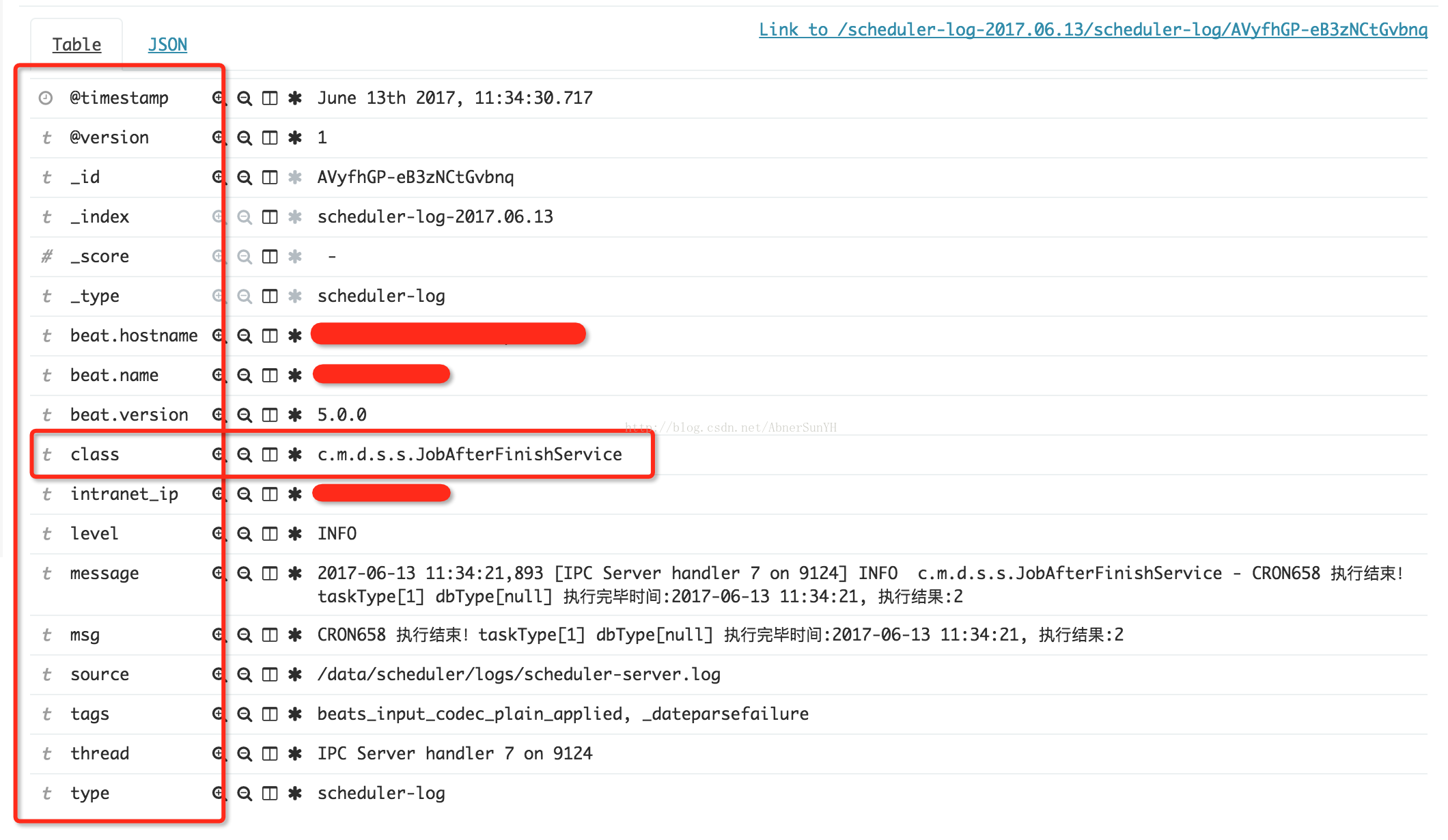
metrics 插件主要用于日志数量统计,例如上文配置文件,统计不同 level 的日志数量。每过 flush_interval 秒触发一次事件,每过 clear_interval 秒清空统计数量。
3.2 output 组件配置(如果没有使用 metrics 统计日志,可省略该配置)
output {
if "metric" in [tags] {
if [scheduler-log_ERROR][count] and [scheduler-log_ERROR][count] > 5 {
#TODO something
}
}
}[tags] 字段由 metrics 插件中的 add_tag 设置,根据 meter 设置的字段名取出 [count] 数量,大于某个数则执行 if 内的语句,if 内可执行调用告警接口或者转发数据等等。
最后将 filter 和 output 配置内容放于一个文件(例:scheduler.conf)即可。
如果使用了 metric 插件,且不想将 metric 统计的数据发送到 es 集群,则在发送到 es 集群的 output 中增加 if 条件。./logstash/conf.d 目录下获取 filebeat 发送到 es 集群的配置文件 beats_to_es.conf 如下
input {
beats {
port => 5044
ssl => true
ssl_certificate => "/etc/logstash/logcollect.crt"
ssl_key => "/etc/logstash/logcollect.key"
ssl_verify_mode => "none"
}
}
output {
#只发送 filebeat 传过来的数据到 es 集群
if "beats_input_codec_plain_applied" in [tags] {
elasticsearch {
hosts => ["http://192.168.1.1:9200","http://192.168.1.2:9200","http://192.168.1.3:9200"]
#每天生成一个索引
index => "%{[@metadata][index]}-%{+YYYY.MM.dd}"
document_type => "%{[@metadata][type]}"
}
}
}四、Kibana 配置
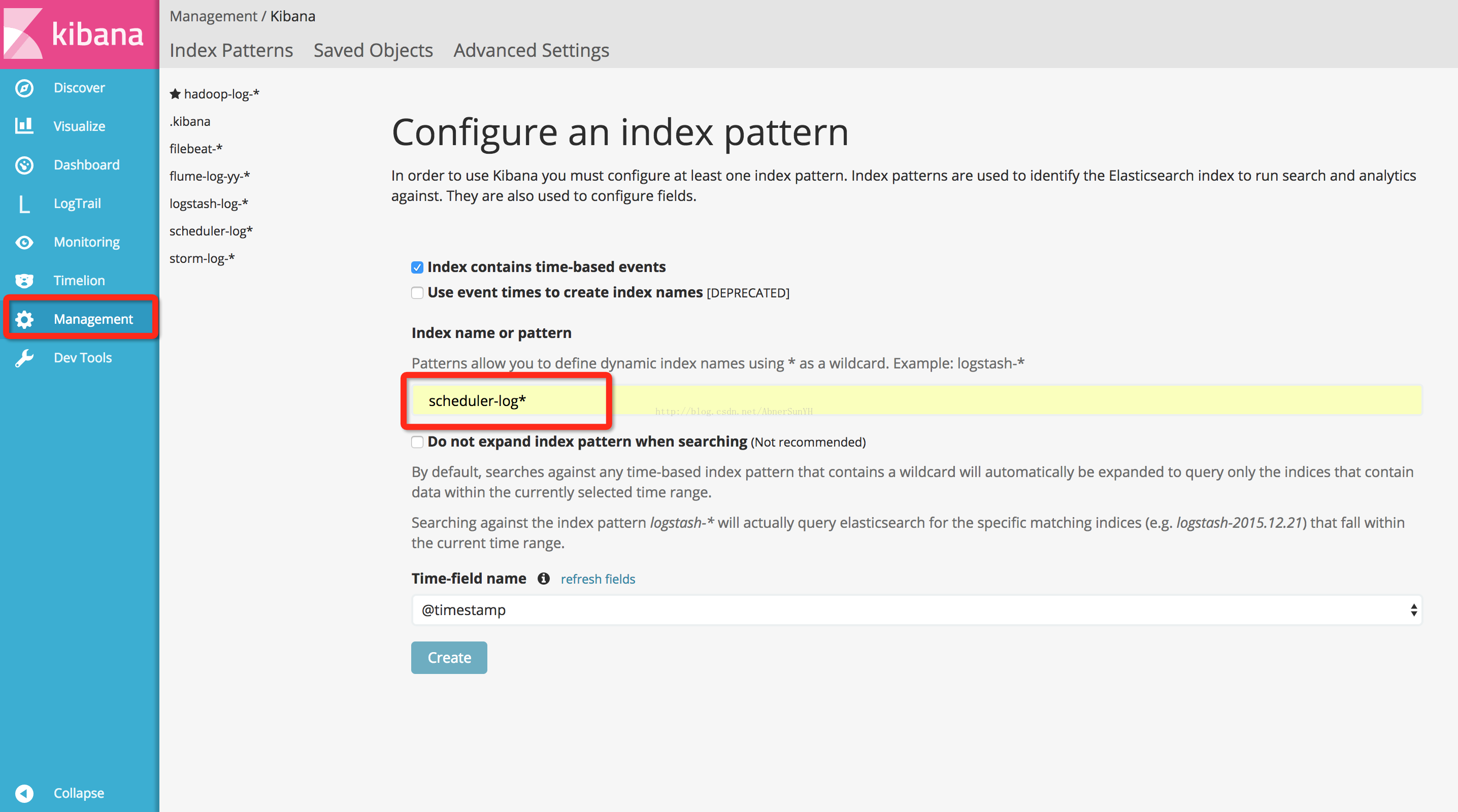
当日志数据正确从 filebeat 采集到 logstash 再到 es 集群后,这时还需要在 Kibana 上配置索引:『Management』-> 『Index Patterns』-> 『add new』。在 Index name 输入框,填写索引名称及星号通配符。索引名称和 logstash 配置 filter 中的 [@metadata][index] 字段一致,也应该与 filebeat 中的 type 一致。索引名称后面加星号通配符,是因为 logstash 配置 output 到 es 集群时,会按天切分索引(详细见 3.2 中的 beats_to_es.conf 配置文件),方便管理数据。
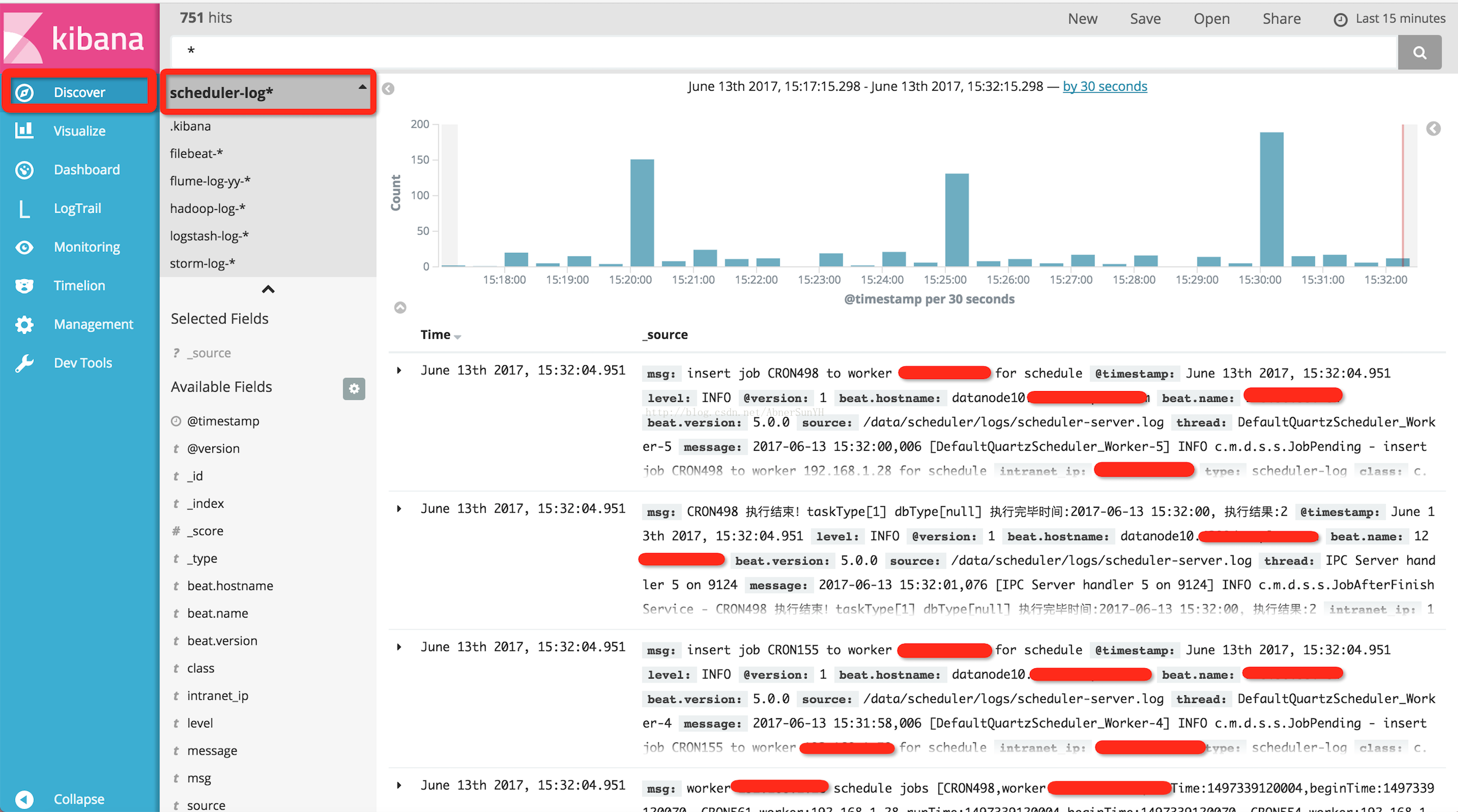
添加索引后,即可在 Discover 页面上查看,在搜索框可以简单的输入关键字进行搜索,也可以直接输入正则表达式进行匹配搜索。
更多 ELK 使用详情,请查看官方文档
https://www.elastic.co/guide/index.html














 715
715











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









